







一、HDFS REST HTTP API
1. HDFS常见的客户端
1)Shell Command
命令类似于Linux的shell对文件的操作,如ls、mkdir、rm等。
命令格式: hadoop fs <args> hdfs dfs <args>

2)Java API
HDFS Java API也是大数据开发中常用的HDFS操作方式。
核心类: FileSystem Configuration
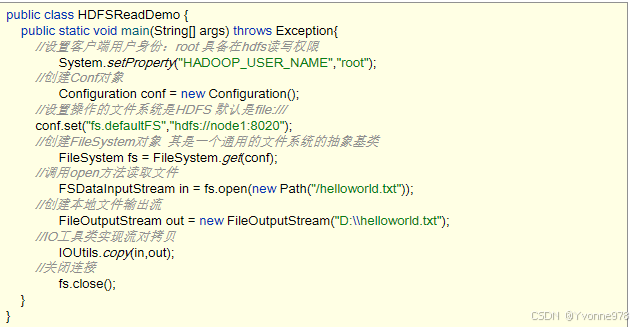
思考:如果Hadoop集群外的一台主机作为客户端访问HDFS,在没有Hadoop和Java环境的情况下,如何操作访问呢?
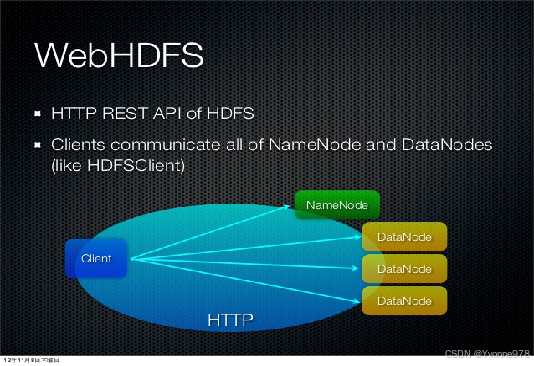
3)基于RESTful的HDFS API--WebHDFS
WebHDFS概述
- WebHDFS 提供了访问HDFS的RESTful接口,内置组件,默认开启。
- WebHDFS 使得集群外的客户端可以不用安装HADOOP和JAVA环境就可以对HDFS进行访问,且客户端不受语言限制。
- WebHDFS 是HortonWorks开发的,后捐给了Apache。
- 当客户端请求某文件时,WebHDFS会将其重定向到该资源所在的datanode。
WebHDFS使用
- 经常使用的HDFS Web UI,其文件浏览功能底层就是基于WebHDFS来操作HDFS实现的。
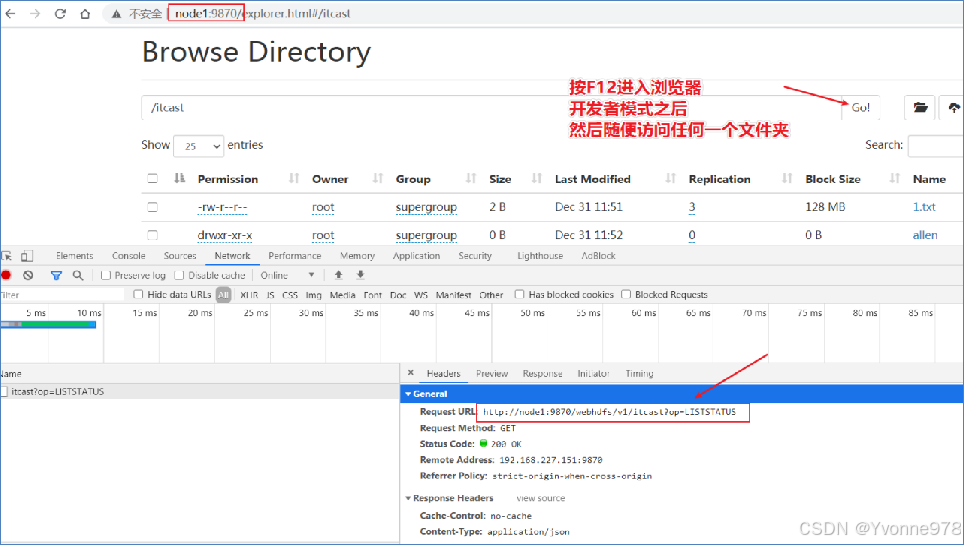
FileSystem URIs vs HTTP URLs
- WebHDFS的文件系统schema为webhdfs://。URL格式为: webhdfs://<HOST>:<HTTP_PORT>/<PATH> 效果相当于 hdfs://<HOST>:<RPC_PORT>/<PATH>
- 在RESTful风格的API中,相应的HTTP URL格式: http://<HOST>:<HTTP_PORT>/webhdfs/v1/<PATH>?op=...
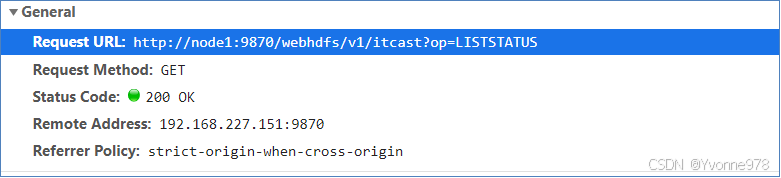
HTTP RESTful API参数
官方参数说明: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/WebHDFS.html#Open_and_Read_a_File
基于HTTP RESTful API操作演示
- 提前安装好Postman测试工具。也可以直接在浏览器地址栏中输入测试。
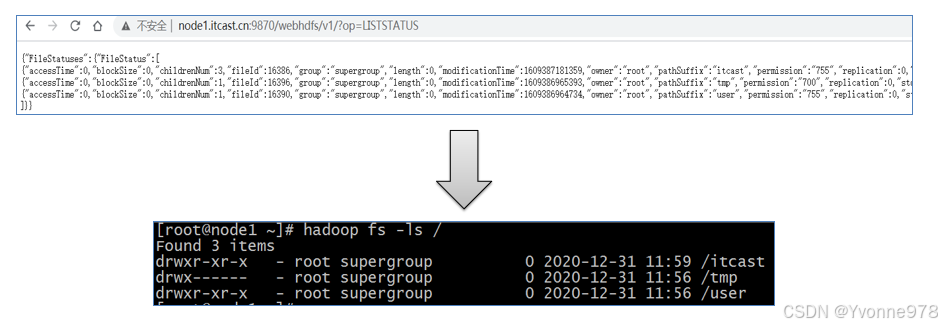
- 请求URL:http://node1.itcast.cn:9870/webhdfs/v1/?op=LISTSTATUS
- 该操作表示要查看根目录下的所有文件以及目录,相当于 hadoop fs -ls /
- 读取指定文件内容。 http://node1.itcast.cn:9870/webhdfs/v1/itcast/wordcount/in/word.txt?op=OPEN&noredirect=false 其中noredirect参数用于指定是否重定向到一个datanode,在该节点可以读取文件数据。当noredirect=true时,相当于不需要重定向,然后就会返回文件所在的节点地址,如下图:

4)基于REST的代理服务-HttpFS
HttpFS概述
- HttpFS 是一个提供RESTful 接口的网关的服务器,该网关支持所有HDFS文件系统操作。
- 对于文件CURD的操作全部提交给HttpFS服务进行中转,然后由HttpFS去跟HDFS集群交互。
- HttpFS是一个独立于HDFS的服务,若使用需要手动安装。
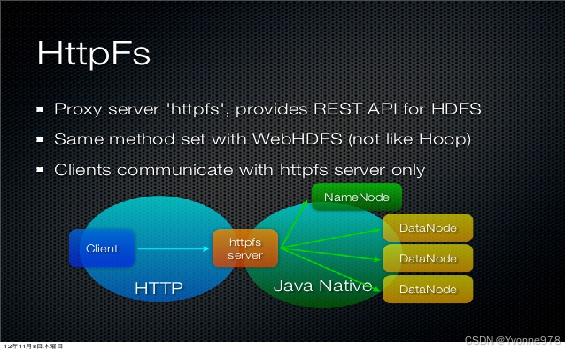
HttpFS工作原理
- HttpFS本身是Java Web应用程序。使用内置的Jetty服务器对外提供服务。
- HttpFS是一个独立于HDFS的服务。本质上是一个代理服务。
- HttpFS API的底层通过是映射到HDFS的HTTP RESTful API调用实现的。
- HttpFS默认端口号为14000。
HttpFS配置--Step1
- 配置允许通过代理访问的主机节点、用户所属组。(core-site.xml)
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
- 表示root用户可以在任意host主机节点上代表任意group组的用户。
- *表示所有。
HttpFS配置--Step2
- 同步配置文件到集群中其他节点,并重启HDFS集群。
cd /export/server/hadoop-3.1.4/etc/hadoop
scp core-site.xml node2:/export/server/hadoop-3.1.4/etc/hadoop/
scp core-site.xml node3:/export/server/hadoop-3.1.4/etc/hadoop/
HttpFS配置--Step3
- 启动HttpFS服务
hdfs --daemon start httpfs
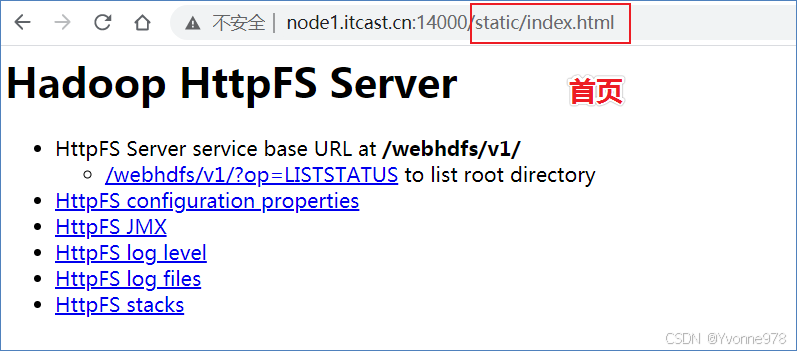
 HttpFS默认服务
HttpFS默认服务

HttpFS访问指定用户身份
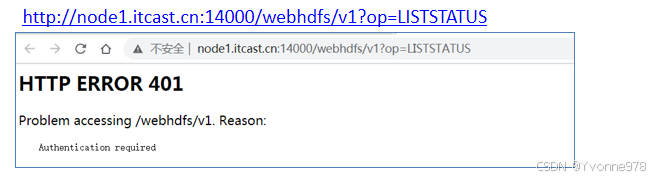
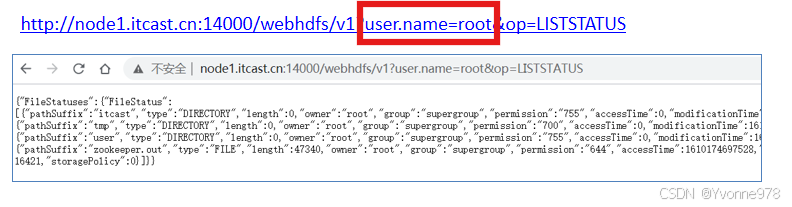
5)WebHDFS和HttpFS之间区别

- 使用内置的WebHDFS REST API操作访问
http://node1.yifeng.cn:9870/webhdfs/v1/?op=LISTSTATUS
端口由dfs.namenode.http-address指定。默认值9870。
- 使用HttpFS web Server 服务操作访问
http://node1.yifeng.cn:14000/webhdfs/v1?user.name=root&op=LISTSTATUS
端口:14000
二、Hadoop常见文件存储格式
1. 传统文件系统常见文件存储格式
常见的文件格式有很多种,例如:JPEG文件用来存储图片、MP3文件用来存储音乐、DOC文件用来存储WORD文档。

思考:
- Hadoop乃至大数据业务通常处理什么类型数据?
- 文本数据?视频数据?图片数据?
- 文本类型的数据是否只有txt类型?
hdfs可以上传下载任何类型的文件,但是大数据一般处理的都是文本类型的数据。但是文本类型的数据不只有txt类型。
2. BigData File Viewer工具
- 一个跨平台(Windows,MAC,Linux)桌面应用程序,用于查看常见的大数据二进制格式,例如Parquet,ORC,AVRO等。支持本地文件系统,HDFS,AWS S3等。
- github地址:https://github.com/Eugene-Mark/bigdata-file-viewer
BigData File Viewer工具功能清单
- 打开并查看本地目录中的Parquet,ORC和AVRO,HDFS,AWS S3等
- 将二进制格式的数据转换为文本格式的数据,例如CSV 支持复杂的数据类型,例如数组,映射,结构等
- 支持Windows,MAC和Linux等多种平台
- 代码可扩展以涉及其他数据格式
BigData File Viewer用法
- 从官网发布页面下载可运行的jar或自己从源代码进行构建。
- 调用 java -jar BigdataFileViewer-1.2.1-SNAPSHOT-jar-with-dependencies.jar运行(在此jar包所在目录打开cmd窗口,)
- 通过“文件”->“打开”打开二进制格式的文件
- 通过“文件”->“另存为”->“ CSV”转换为CSV文件
3. 丰富的Hadoop文件存储格式
行式存储、列式存储
- 行式存储(Row-Based):同一行数据存储在一起。
- 列式存储(Column-Based):同一列数据存储在一起。
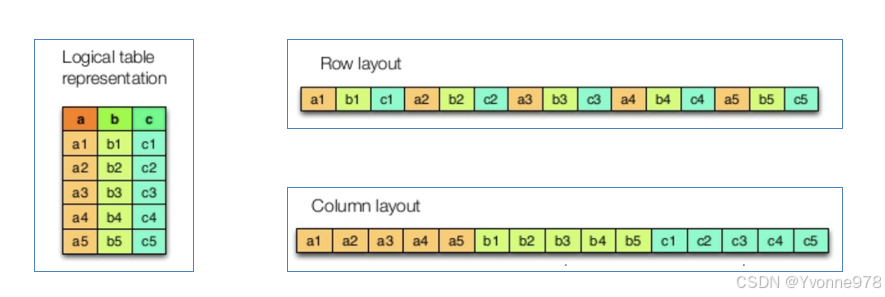
优缺点
1)行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。行适合插入、不适合查询。
2)列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。列适合查询,不适合插入。
a)Text File
- 文本格式是Hadoop生态系统内部和外部的最常见格式。通常按行存储,以回车换行符区分不同行数据。
- 最大缺点是,它不支持块级别压缩,因此在进行压缩时会带来较高的读取成本。
- 解析开销一般会比二进制格式高,尤其是XML 和JSON,它们的解析开销比Textfile还要大。
- 易读性好

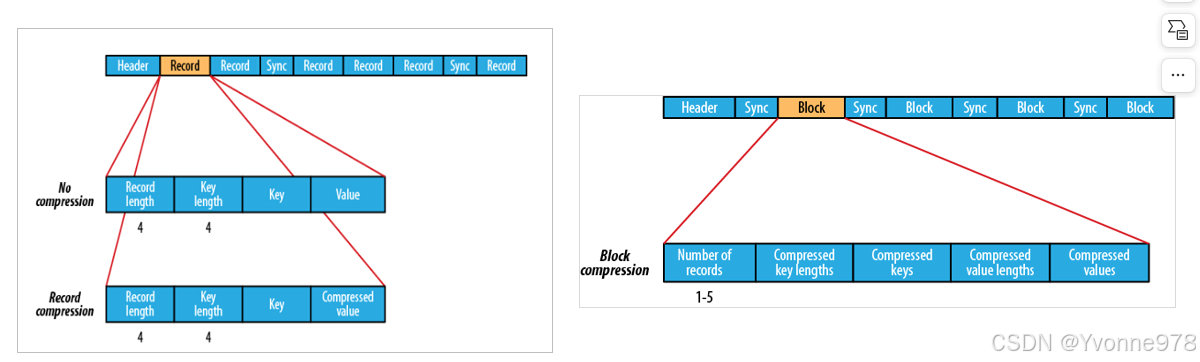
b)Sequence File
- Sequence File,每条数据记录(record)都是以key、value键值对进行序列化存储(二进制格式)。
- 序列化文件与文本文件相比更紧凑,支持record级、block块级压缩。压缩的同时支持文件切分。
- 通常把Sequence file作为中间数据存储格式。例如:将大量小文件合并放入到一个Sequence File中。
b)Sequence File--record 、block
- record就是一个kv键值对。其中数据保存在value中。
- 可以选择是否针对value进行压缩。 block就是多个record的集合。block级别压缩性能更好。
c)Avro File
- Apache Avro是与语言无关的序列化系统,由Hadoop创始人 Doug Cutting开发
- Avro是基于行的存储格式,它在每个文件中都包含JSON格式的schema定义,从而提高了互操作性并允许schema的变化(删除列、添加列)。 除了支持可切分以外,还支持块压缩。
- Avro是一种自描述格式,它将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据。
- Avro直接将一行数据序列化在一个block中.
- 适合于大量频繁写入宽表数据(字段多列多)的场景,其序列化反序列化很快。
d)RCFile
- Hive Record Columnar File(记录列文件),这种类型的文件首先将数据按行划分为行组,然后在行组内部将数据存储在列中。很适合在数仓中执行分析。且支持压缩、切分
- 但不支持schema扩展,如果要添加新的列,则必须重写文件,这会降低操作效率。
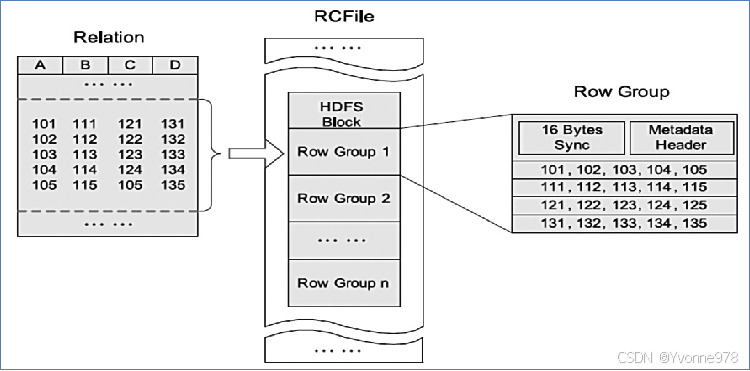
基于第二点缺点,进行了升级,就是ORC File
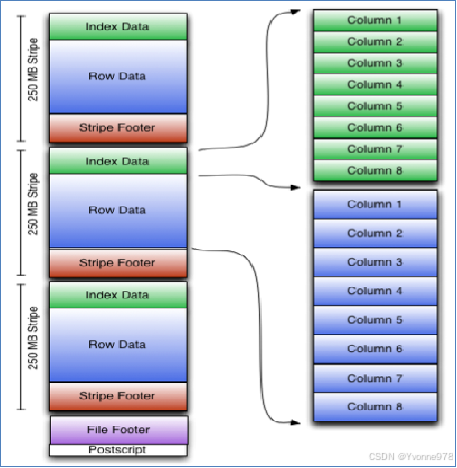
e)ORC File
- ORC File(Optimized Row Columnar)提供了比RC File更有效的文件格式。它在内部将数据划分为默认大小为250M的Stripe。每个条带均包含索引,数据和页脚。索引存储每列的最大值和最小值以及列中每一行的位置。
- 它并不是一个单纯的列式存储格式,仍然是首先根据Stripe分割整个表,在每一个Stripe内进行按列存储。
- ORC有多种文件压缩方式,并且有着很高的压缩比。文件是可切分(Split)的。
- ORC文件是以二进制方式存储的,所以是不可以直接读取。
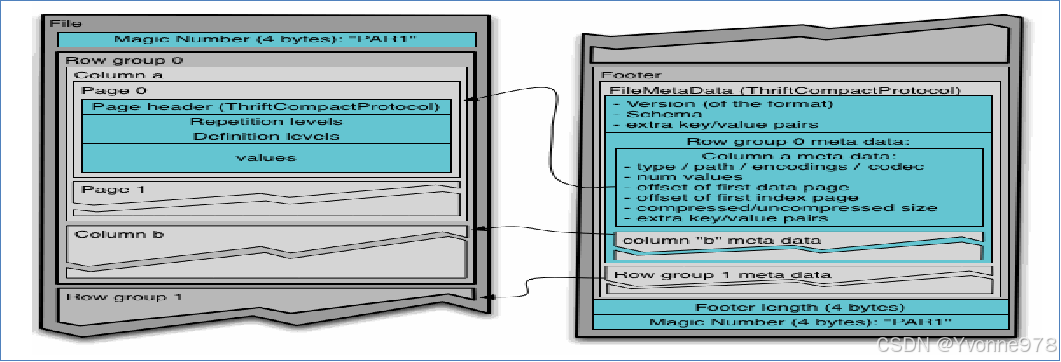
f)Parquet File
- Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
- Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。 支持块压缩。
f)Parquet File--结构
- Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
- 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
- 文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件。
总结:
- 选择文件存储格式不能只追求某一项指标性能
- 更流行的是混合存储格式:兼容行式和列式存储
- 大数据中ORC、parquet、Avro使用较多。
4. 扩展:大数据新一代存储格式Apache Arrow
- Apache Arrow是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。
- Apache Arrow在2016年2月17日作为顶级Apache项目引入。
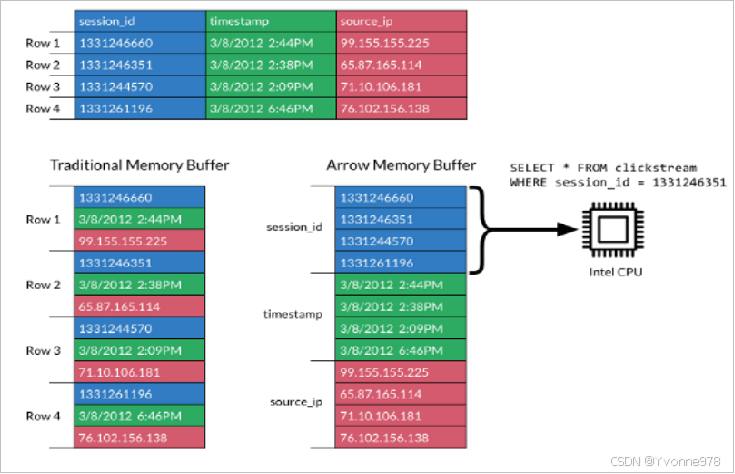
- Arrow促进了许多组件之间的通信。
- 极大的缩减了通信时候序列化、反序列化所浪费的时间。
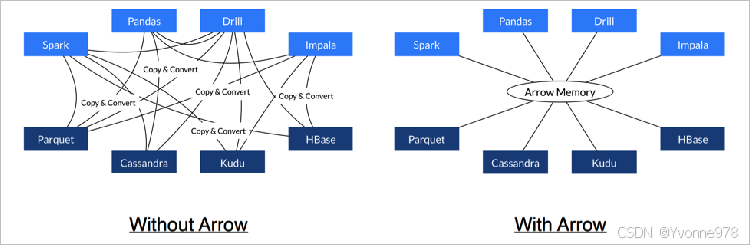
Arrow如何提升数据移动性能?
- 利用Arrow作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。 例如,Spark可以使用Python进程发送Arrow数据来执行用户定义的函数。
- 无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据。 例如,Kudu可以将Arrow数据直接发送到Impala进行分析。
- Arrow的设计针对嵌套结构化数据(例如在Impala或Spark Data框架中)的分析性能进行了优化。
三、文件压缩格式
1. 文件压缩测试体验
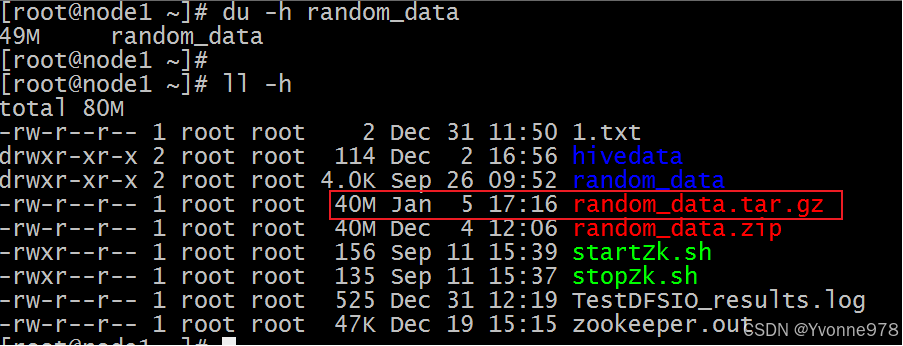
- Linux上使用gzip进行数据压缩 windows上使用zip进行数据压缩
- windows上使用zip进行数据压缩
unzip random_data.zip
du -h random_data
tar -cvzf random_data.tar.gz random_data
2. 压缩算法优劣指标
- 压缩比 原先占100份空间的东西经压缩之后变成了占20份空间,那么压缩比就是5,显然压缩比越高越好。
- 压缩/解压缩吞吐量(时间) 每秒能压缩或解压缩多少MB的数据。吞吐量也是越高越好。
- 压缩算法实现是否简单、开源
- 是否为无损压缩。恢复效果要好。
- 压缩后的文件是否支持split(切分)
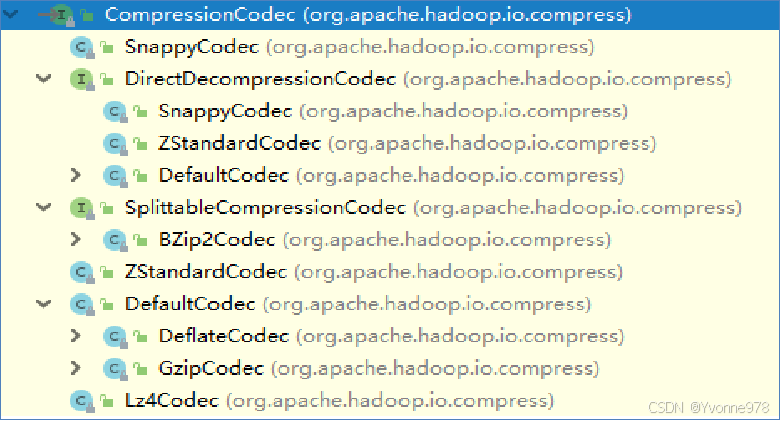
3. Hadoop支持的压缩算法
- Haodop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口。
- 所有的实现类都在org.apache.hadoop.io.compress包下。
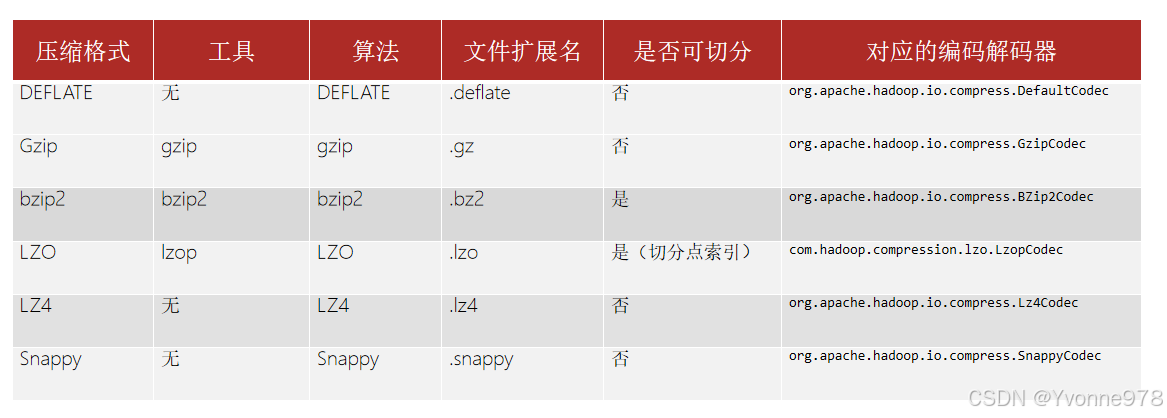
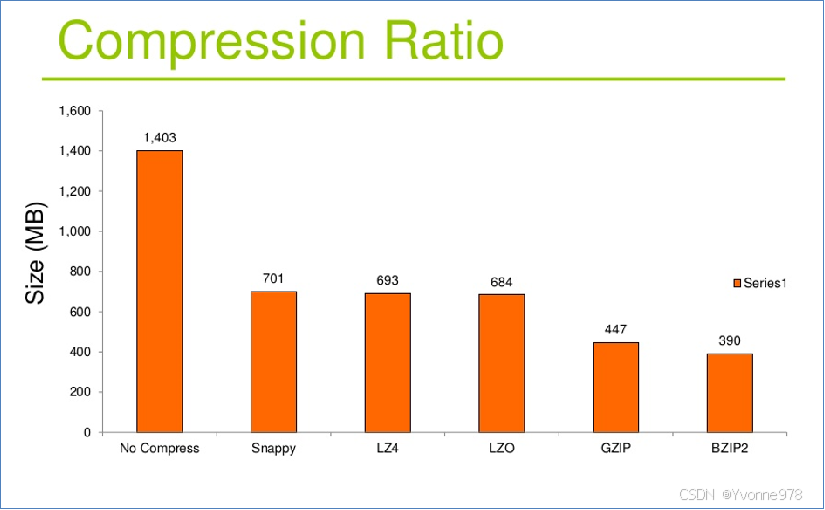
4. Hadoop支持的压缩对比
压缩比
压缩、解压缩时间
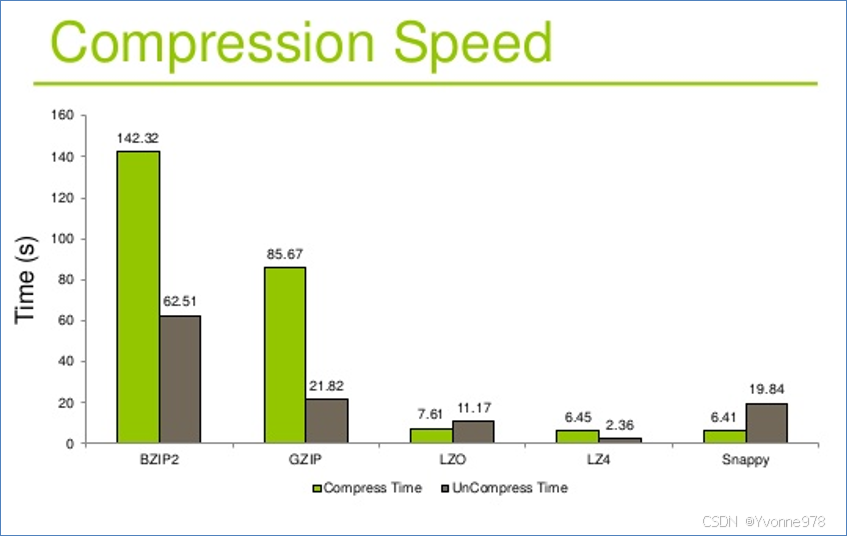
总结
- 压缩的合理使用可以提高HDFS存储效率
- 压缩解压缩意味着CPU、内存需要参与编码解码
- 选择压缩算法时不能一味追求某一指标极致。综合考虑性价比较高的。
- 文件的压缩解压需要程序或者工具的参与来对数据进行处理。大数据相关处理软件都支持直接设置。
四、HDFS异构存储和存储策略
1. HDFS异构存储类型
—冷、热、温、冻数据
通常,公司或者组织总是有相当多的历史数据占用昂贵的存储空间。典型的数据使用模式是新传入的数据被应用程序大量使用,从而该数据被标记为"热"数据。随着时间的推移,存储的数据每周被访问几次,而不是一天几次,这时认为其是"暖"数据。在接下来的几周和几个月中,数据使用率下降得更多,成为"冷"数据。如果很少使用数据,例如每年查询一次或两次,这时甚至可以根据其年龄创建第四个数据分类,并将这组很少被查询的旧数据称为"冻结数据"。
Hadoop允许将不是热数据或者活跃数据的数据分配到比较便宜的存储上,用于归档或冷存储。可以设置存储策略,将较旧的数据从昂贵的高性能存储上转移到性价比较低(较便宜)的存储设备上。
Hadoop 2.5及以上版本都支持存储策略,在该策略下,不仅可以在默认的传统磁盘上存储HDFS数据,还可以在SSD(固态硬盘)上存储数据。
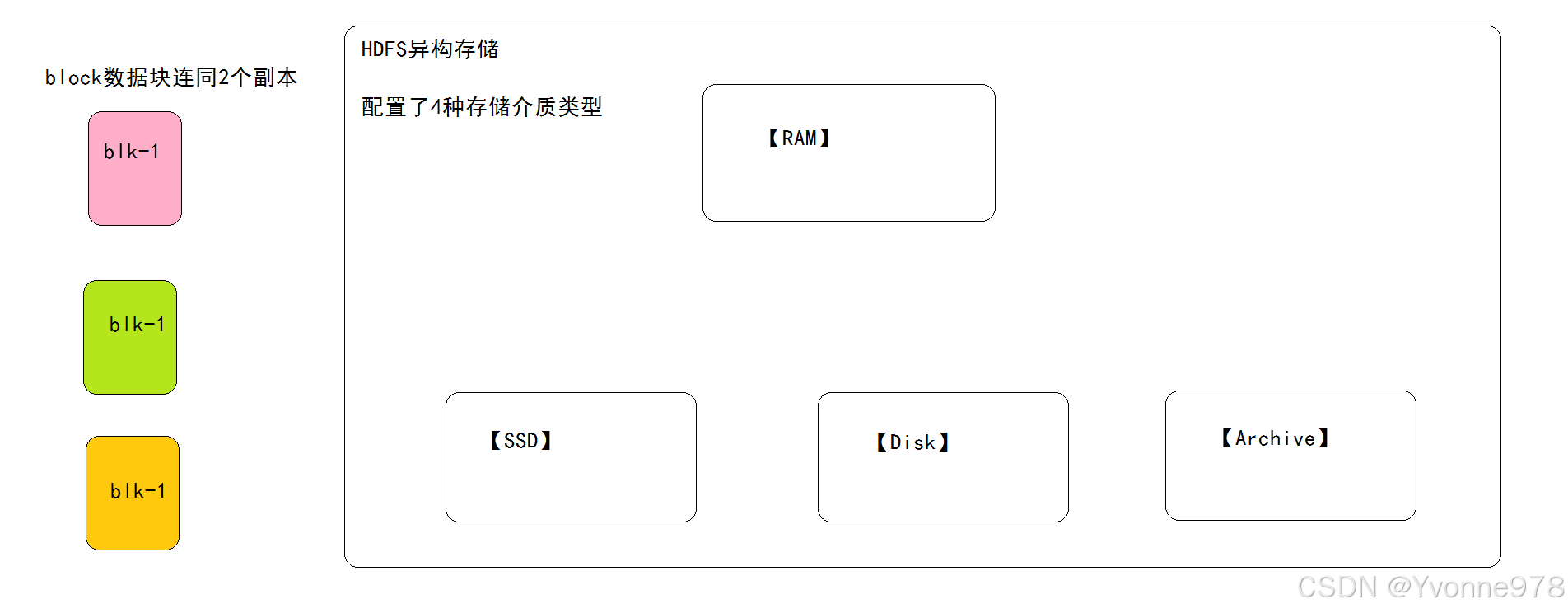
—什么是异构存储?
异构存储是Hadoop2.6.0版本出现的新特性,可以根据各个存储介质读写特性不同进行选择。 例如冷热数据的存储,对冷数据采取容量大,读写性能不高的存储介质如机械硬盘,对于热数据,可使用SSD硬盘存储。 在读写效率上性能差距大。异构特性允许我们对不同文件选择不同的存储介质进行保存,以实现机器性能的最大化。
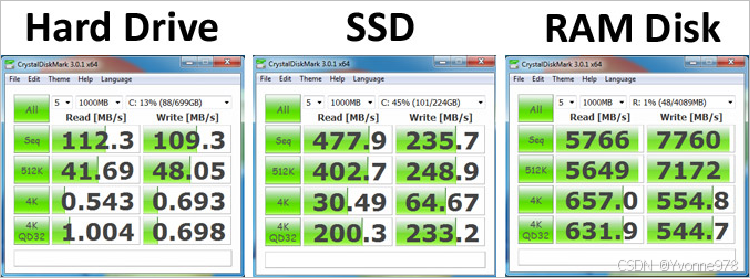
—HDFS中声明定义了4种异构存储类型
RAM_DISK(内存)
SSD(固态硬盘)
DISK(机械硬盘),默认使用。
ARCHIVE(高密度存储介质,存储档案历史数据)
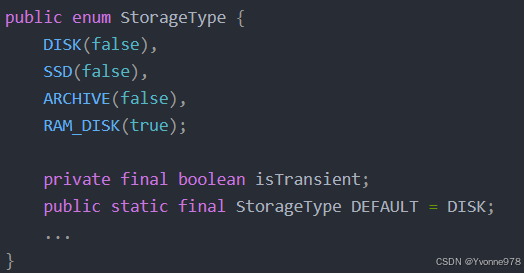
提示:其中true和false指是否使用transient, transient代表非持久化,而只有内存存储是transient
如何让HDFS知道集群中的数据存储目录是哪种类型存储介质?
配置属性时主动声明。HDFS并没有自动检测的能力。
配置参数dfs.datanode.data.dir = [SSD]file:///grid/dn/ssdO
如果目录前没有带上[SSD] [DISK] [ARCHIVE] [RAM_DISK] 这4种类型中的任何一种,则默认是DISK类型 。
2. 块存储类型选择策略
- 块存储指的是对HDFS文件的数据块副本储存。
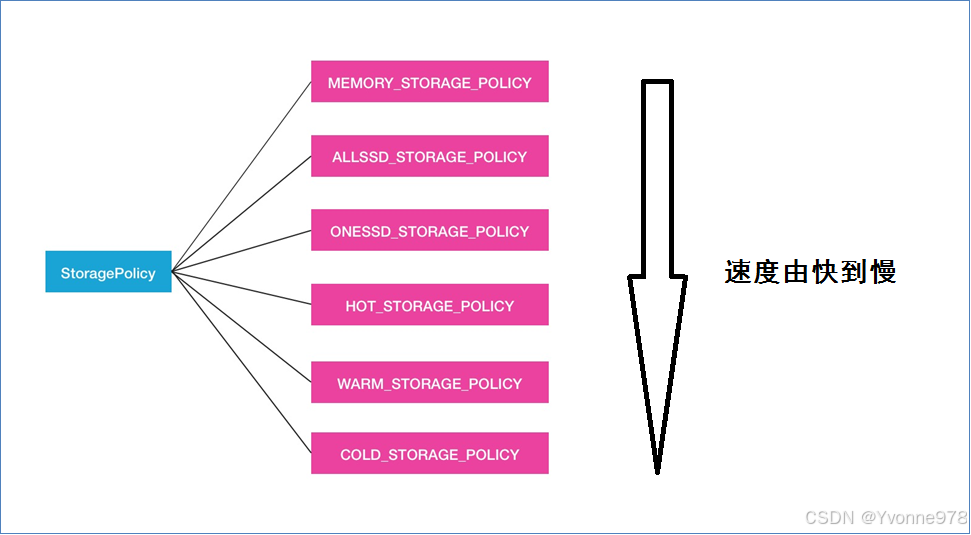
- 对于数据的存储介质,HDFS的BlockStoragePolicySuite 类内部定义了6种策略。
HOT(默认策略) COLD WARM ALL_SSD ONE_SSD LAZY_PERSIST
- 前三种根据冷热数据区分,后三种根据磁盘性质区分。
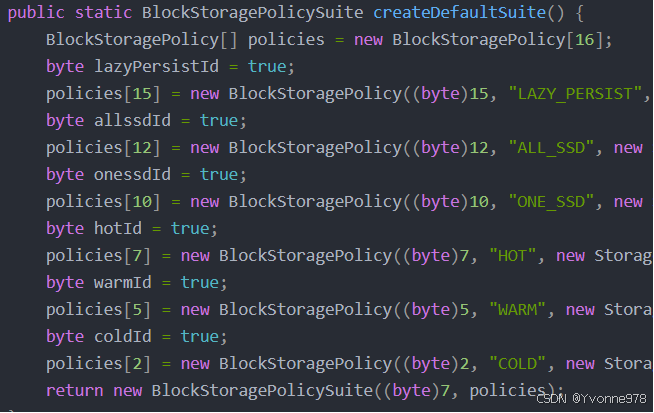
块存储类型选择策略--说明
- HOT:用于存储和计算。流行且仍用于处理的数据将保留在此策略中。所有副本都存储在DISK中。
- COLD:仅适用于计算量有限的存储。不再使用的数据或需要归档的数据从热存储移动到冷存储。所有副本都存储在ARCHIVE中。
- WARM:部分热和部分冷。热时,其某些副本存储在DISK中,其余副本存储在ARCHIVE中。
- All_SSD:将所有副本存储在SSD中。
- One_SSD:用于将副本之一存储在SSD中。其余副本存储在DISK中。
- Lazy_Persist:用于在内存中写入具有单个副本的块。首先将副本写入RAM_DISK,然后将其延迟保存在DISK中。
块存储类型选择策略--速度快慢比较
块存储类型选择策略--命令
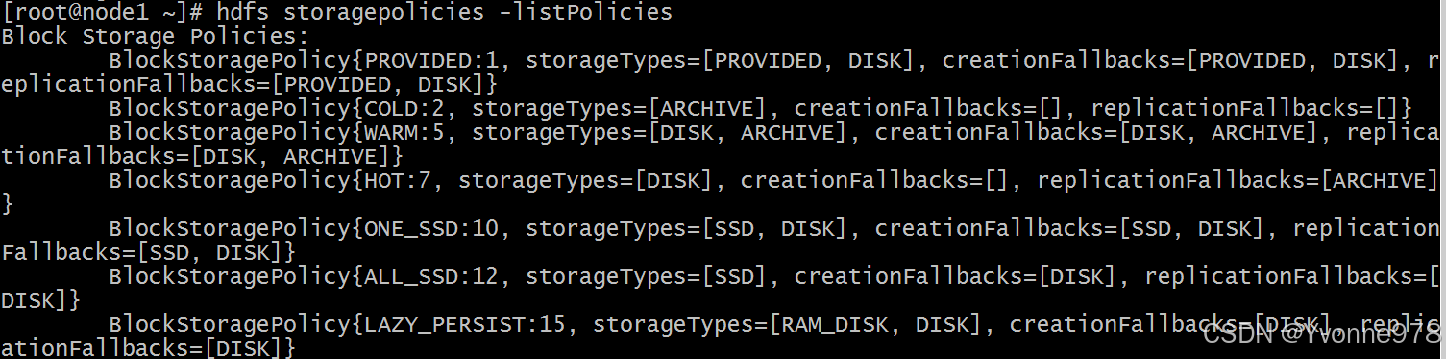
(1) 列出所有存储策略
hdfs storagepolicies -listPolicies
(2) 设置存储策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>

(3) 取消存储策略
hdfs storagepolicies -unsetStoragePolicy -path <path>
在执行unset命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略。
(4) 获取存储策略
hdfs storagepolicies -getStoragePolicy -path <path>
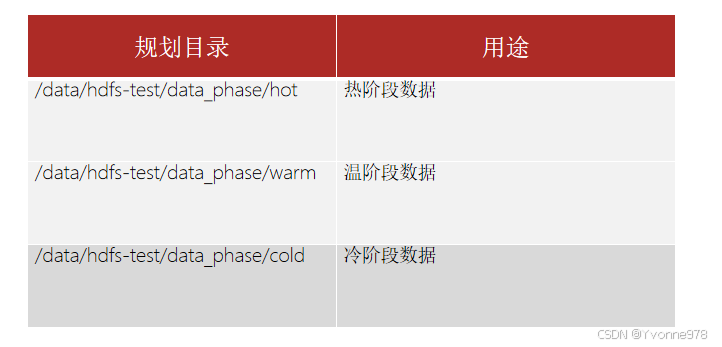
3. 案例:冷热温数据异构存储
为了更加充分的利用存储资源,我们可以将数据分为冷、热、温三个阶段来存储。具体规划如下:
Step1:配置DataNode存储目录,指定存储介质类型( hdfs-site.xml )
cd /export/server/hadoop-3.1.4/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://${hadoop.tmp.dir}/dfs/data,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/data/archive</value>
</property>
scp -r hdfs-site.xml node2:$PWD
scp -r hdfs-site.xml node3:$PWD
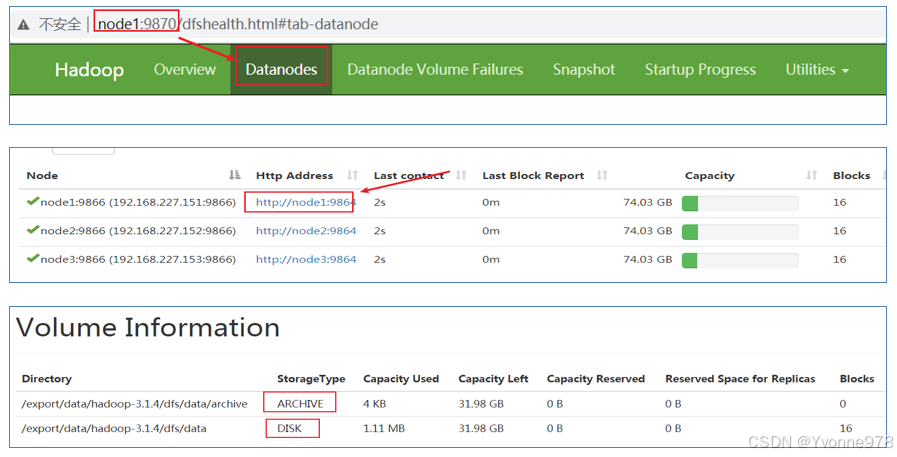
Step2:重启HDFS集群,验证配置
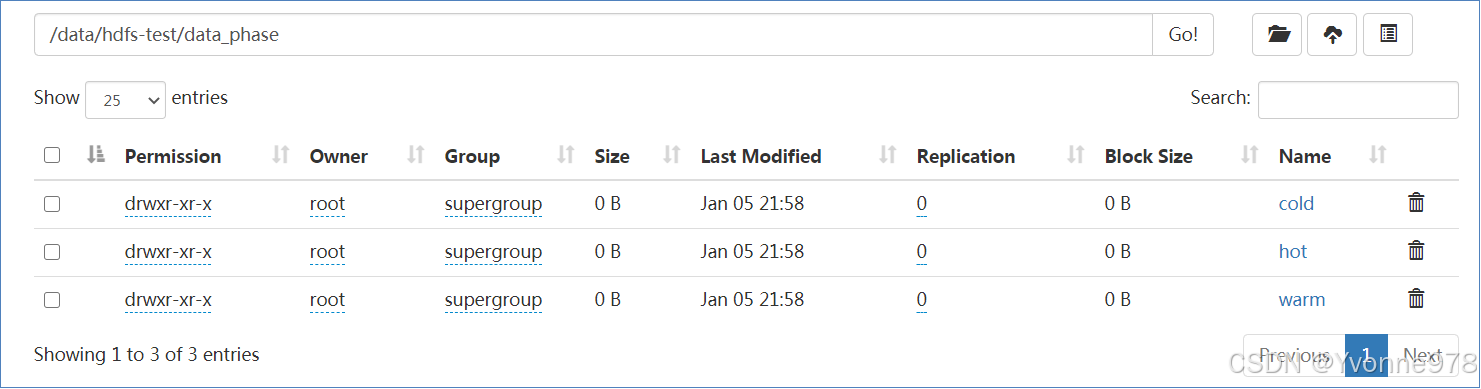
Step3:创建测试目录结构
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/cold
Step4:分别设置三个目录的存储策略
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/hot -policy HOT hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/cold -policy COLD

Step5:查看三个目录的存储策略
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold

Step6:上传文件测试异构存储
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/cold
Step7:查看不同存储策略文件的block位置
hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations


4. HDFS内存存储策略支持
1)HDFS内存存储策略支持--LAZY PERSIST介绍
- HDFS支持把数据写入由DataNode管理的堆外内存;
- DataNode异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘IO操作,这种写入称为 Lazy Persist写入。
- 该特性从Apache Hadoop 2.6.0开始支持。
2)HDFS内存存储策略支持--LAZY PERSIST执行流程
- 对目标文件目录设置 StoragePolicy 为 LAZY_PERSIST 的内存存储策略 。
- 客户端进程向 NameNode 发起创建/写文件的请求 。
- 客户端请求到具体的 DataNode 后 DataNode 会把这些数据块写入 RAM 内存中,同时启动异步线程服务将内存数据持久化写到磁盘上 。
- 内存的异步持久化存储是指数据不是马上落盘,而是懒惰的、延时地进行处理 。
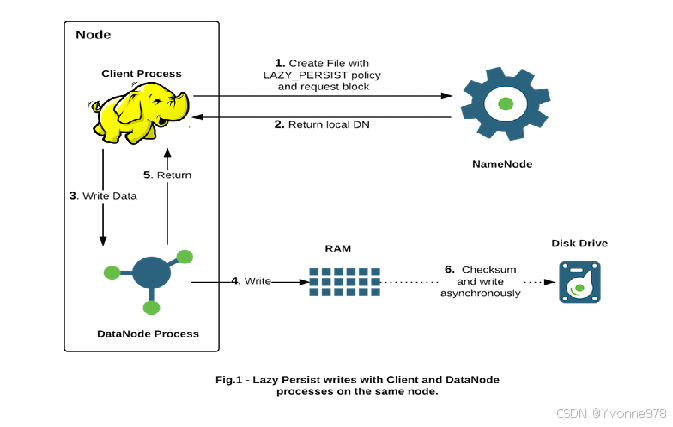
3)HDFS内存存储策略支持--LAZY PERSIST设置使用
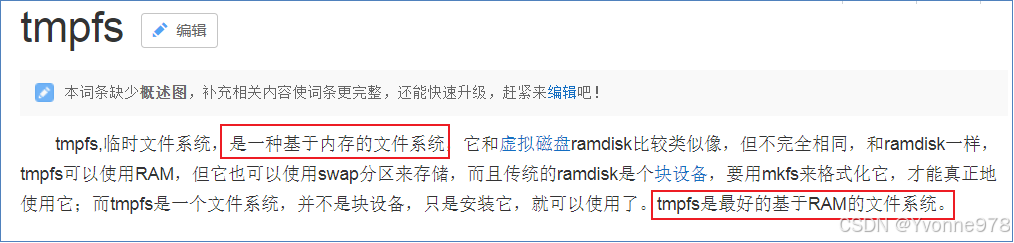
Step1:虚拟内存盘配置
mount -t tmpfs -o size=1g tmpfs /mnt/dn-tmpfs/
将tmpfs挂载到目录/mnt/dn-tmpfs/,并且限制内存使用大小为1GB 。
Step2:内存存储介质设置
将机器中已经完成好的虚拟内存盘配置到 dfs.datanode.data.dir 中,其次还要带上 RAM_DISK 标签.

Step3:参数设置优化
dfs.storage.policy.enabled
是否开启异构存储,默认true开启
dfs.datanode.max.locked.memory
用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用 内存中缓存。内存值过小会导致内存中的总的可存储的数据块变少,但如果超过 DataNode 能承受的最大内存大小的话,部分内存块会被直接移出 。
Step4:在目录上设置存储策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
五、案例:银行转账数据分层
描述:
- 银行每一天都有大量的转账、交易处理。用户每进行一笔交易或者转账,银行都需要将所有相关信息保存下来。
- 中国四大银行拥有数10亿的用户。要保存的数据量可想而知。如果说有的数据,都同等对待,为了保证使用数据的性能采用高性能存储,这将是一笔不小的资源浪费。
- 实际上,超过一定时间的数据,数据访问的频率要低得多。例如:用户查询5年前的转账记录、要比查询1年类的转账记录频率要低得多。
- 为了能够更好地利用资源,需要对数据进行分层。也就是不同时间范围的数据,放在不同的层(冷热温)中。
Step1:创建存储数据目录
hdfs dfs -mkdir -p /source/bank/transfer/log_lte1y
hdfs dfs -mkdir -p /source/bank/transfer/log_gt1y
Step2:指定存储策略
hdfs storagepolicies -setStoragePolicy -path /source/bank/transfer/log_lte1y -policy HOT hdfs storagepolicies -setStoragePolicy -path /source/bank/transfer/log_gt1y -policy COLD
Step3:上传文件测试
#一年
hdfs dfs -put /root/bank_record.csv /source/bank/transfer/log_lte1y/bank_record_2020_9.csv
#五年
hdfs dfs -put /root/bank_record.csv /source/bank/transfer/log_gt1y/bank_record_2015_9.csv
#假设现在到了2021年10年,我们可以将之前的数据移动到log_gt1y
hdfs dfs -mv /source/bank/transfer/log_lte1y/bank_record_2020_9.csv /source/bank/transfer/log_gt1y/bank_record_2020_9.csv
Step4:查看最终存储策略
hdfs storagepolicies -getStoragePolicy -path /source/bank/transfer/log_lte1y
hdfs storagepolicies -getStoragePolicy -path /source/bank/transfer/log_gt1y
hdfs fsck /source/bank/transfer/log_gt1y/bank_record_2015_9.csv -files -blocks -locations


















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









