









1. 如果想消费已经被消费过的数据,如何实现?
consumer是底层采用的是一个阻塞队列,只要一有producer生产数据,那consumer就会将数据消费。当然这里会产生一个很严重的问题,如果你重启一消费者程序,那你连一条数据都抓不到,但是log文件中明明可以看到所有数据都好好的存在。换句话说,一旦你消费过这些数据,那你就无法再次用同一个groupid消费同一组数据了。
原因:消费者消费了数据并不从队列中移除,只是记录了offset偏移量。同一个consumergroup的所有consumer合起来消费一个topic,并且他们每次消费的时候都会保存一个offset参数在zookeeper的root上。如果此时某个consumer挂了或者新增一个consumer进程,将会触发kafka的负载均衡,暂时性的重启所有consumer,重新分配哪个consumer去消费哪个partition,然后再继续通过保存在zookeeper上的offset参数继续读取数据。注意:offset保存的是consumer组消费的消息偏移。
要消费同一组数据,你可以
- 采用不同的group。
- 通过一些配置,就可以将线上生产的数据同步到镜像中去,然后再由特定的集群区处理大批量的数据。
2.如何自定义去消费已经消费过的数据?
Conosumer.properties配置文件中有两个重要参数
auto.commit.enable:如果为true,则consumer的消费偏移offset会被记录到zookeeper。下次consumer启动时会从此位置继续消费。
auto.offset.reset 该参数只接受两个常量largest和Smallest,分别表示将当前offset指到日志文件的最开始位置和最近的位置。
如果进一步想控制时间,则需要调用SimpleConsumer,自己去设置相关参数。比较重要的参数是 kafka.api.OffsetRequest.EarliestTime()和kafka.api.OffsetRequest.LatestTime()分别表示从日志(数据)的开始位置读取和只读取最新日志。
如何使用SimpleConsumer
首先,你必须知道读哪个topic的哪个partition
然后,找到负责该partition的broker leader,从而找到存有该partition副本的那个broker
再者,自己去写request并fetch数据
最终,还要注意需要识别和处理brokerleader的改变
3、kafka partition和consumer数目关系
- 如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数 。
- 如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀 。最好partiton数目是consumer数目的整数倍,所以partition数目很重要,比如取24,就很容易设定consumer数目 。
- 如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
- 增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
4、kafka topic 副本问题
Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。
- 如何分配副本:
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。 - Kafka分配Replica的算法如下:
将所有Broker(假设共n个Broker)和待分配的Partition排序
将第i个Partition分配到第(imod n)个Broker上
将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
5、kafka如何设置生存周期与清理数据
日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表,把保存时间超过阀值的文件直接删除(根据文件的创建时间).清理参数在server.properties文件中:
6、zookeeper如何管理kafka
- Producer端使用zookeeper用来"发现"broker列表,以及和Topic下每个partition leader建立socket连接并发送消息.
- Broker端使用zookeeper用来注册broker信息,以及监测partition leader存活性.
- Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息.
7、kafkadirect是什么? 为什么要用这个,有什么优点?和其他的有什么区别。
1)Direct的方式是会直接操作kafka底层的元数据信息,这样如果计算失败了,可以把数据重新读一下,重新处理。即数据一定会被处理。拉数据,是RDD在执行的时候直接去拉数据。
2)由于直接操作的是kafka,kafka就相当于你底层的文件系统。这个时候能保证严格的事务一致性,即一定会被处理,而且只会被处理一次。而Receiver的方式则不能保证,因为Receiver和ZK中的数据可能不同步,Spark Streaming可能会重复消费数据,这个调优可以解决,但显然没有Direct方便。而Direct api直接是操作kafka的,spark streaming自己负责追踪消费这个数据的偏移量或者offset,并且自己保存到checkpoint,所以它的数据一定是同步的,一定不会被重复。即使重启也不会重复,因为checkpoint了,但是程序升级的时候,不能读取原先的checkpoint,面对升级checkpoint无效这个问题,怎么解决呢?升级的时候读取我指定的备份就可以了,即手动的指定checkpoint也是可以的,这就再次完美的确保了事务性,有且仅有一次的事务机制。那么怎么手动checkpoint呢?构建SparkStreaming的时候,有getorCreate这个api,它就会获取checkpoint的内容,具体指定下这个checkpoint在哪就好了。而如果从checkpoint恢复后,如果数据累积太多处理不过来,怎么办?1限速2增强机器的处理能力3放到数据缓冲池中。
3)由于底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka中特定范围(offset范围)中的数据。这个时候,Direct Api访问kafka带来的一个显而易见的性能上的好处就是,如果你要读取多个partition,Spark也会创建RDD的partition,这个时候RDD的partition和kafka的partition是一致的。而Receiver的方式,这2个partition是没任何关系的。这个优势是你的RDD,其实本质上讲在底层读取kafka的时候,kafka的partition就相当于原先hdfs上的一个block。这就符合了数据本地性。RDD和kafka数据都在这边。所以读数据的地方,处理数据的地方和驱动数据处理的程序都在同样的机器上,这样就可以极大的提高性能。不足之处是由于RDD和kafka的patition是一对一的,想提高并行度就会比较麻烦。提高并行度还是repartition,即重新分区,因为产生shuffle,很耗时。这个问题,以后也许新版本可以自由配置比例,不是一对一。因为提高并行度,可以更好的利用集群的计算资源,这是很有意义的。
4)不需要开启wal机制,从数据零丢失的角度来看,极大的提升了效率,还至少能节省一倍的磁盘空间。从kafka获取数据,比从hdfs获取数据,因为zero copy的方式,速度肯定更快。
8 Spark-Streaming获取kafka数据的两种方式,并简要介绍他们的优缺点?
Receiver方式;当一个任务从driver发送到executor执行的时候,这时候,将数据拉取到executor中做操作,但是如果数据太大的话,这时候不能全放在内存中,receiver通过WAL,设置了本地存储,他会存放本地,保证数据不丢失,然后使用Kafka高级API通过zk来维护偏移量,保证数据的衔接性,其实可以说,receiver数据在zk获取的,这种方式效率低,而且极易容易出现数据丢失
Direct 方式; 他使用Kafka底层Api 并且消费者直接连接kafka的分区上,因为createDirectStream创建的DirectKafkaInputDStream每个batch所对应的RDD的分区与kafka分区一一对应,但是需要自己维护偏移量,迭代计算,即用即取即丢,不会给内存造成太大的压力,这样效率很高
9 kafka在高并发的情况下,如何避免消息丢失和消息重复?
消息丢失解决方案:
首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置acks=all,即需要相应的所有处于ISR的分区都确认收到该消息后,才算发送成功
消息重复解决方案:
消息可以使用唯一id标识
生产者(ack=all 代表至少成功发送一次)
消费者 (offset手动提交,业务逻辑成功处理后,提交offset)
落表(主键或者唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到Redis或者mongdb中,先查询是否存在,若存在则不处理;若不存在,先插入Redis或Mongdb,再进行业务逻辑处理)
10 kafka怎么保证数据消费一次且仅消费一次
幂等producer:保证发送单个分区的消息只会发送一次,不会出现重复消息
事务(transaction):保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚
流处理EOS:流处理本质上可看成是“读取-处理-写入”的管道。此EOS保证整个过程的操作是原子性。注意,这只适用于Kafka Streams
11 kafka保证数据一致性和可靠性
数据一致性保证
一致性定义:若某条消息对client可见,那么即使Leader挂了,在新Leader上数据依然可以被读到
HW-HighWaterMark: client可以从Leader读到的最大msg offset,即对外可见的最大offset, HW=max(replica.offset)
对于Leader新收到的msg,client不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被client消费,这样就保证了如果Leader fail,该消息仍然可以从新选举的Leader中获取。
对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
数据可靠性保证
当Producer向Leader发送数据时,可以通过acks参数设置数据可靠性的级别
0: 不论写入是否成功,server不需要给Producer发送Response,如果发生异常,server会终止连接,触发Producer更新meta数据;
1: Leader写入成功后即发送Response,此种情况如果Leader fail,会丢失数据
-1: 等待所有ISR接收到消息后再给Producer发送Response,这是最强保证
12 kafka到spark streaming怎么保证数据完整性,怎么保证数据不重复消费?
保证数据不丢失(at-least)
spark RDD内部机制可以保证数据at-least语义。
Receiver方式
开启WAL(预写日志),将从kafka中接受到的数据写入到日志文件中,所有数据从失败中可恢复。
Direct方式
依靠checkpoint机制来保证。
保证数据不重复(exactly-once)
要保证数据不重复,即Exactly once语义。
- 幂等操作:重复执行不会产生问题,不需要做额外的工作即可保证数据不重复。
- 业务代码添加事务操作
就是说针对每个partition的数据,产生一个uniqueId,只有这个partition的所有数据被完全消费,则算成功,否则算失效,要回滚。下次重复执行这个uniqueId时,如果已经被执行成功,则skip掉。
13 kafka的消费者高阶和低阶API有什么区别
kafka 提供了两套 consumer API:The high-level Consumer API和 The SimpleConsumer API
其中 high-level consumer API 提供了一个从 kafka 消费数据的高层抽象,而 SimpleConsumer API 则需要开发人员更多地关注细节。
The high-level consumer API
high-level consumer API 提供了 consumer group 的语义,一个消息只能被 group 内的一个 consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
使用 high-level consumer API 可以是多线程的应用,应当注意:
如果消费线程大于 patition 数量,则有些线程将收不到消息
如果 patition 数量大于线程数,则有些线程多收到多个 patition 的消息
如果一个线程消费多个 patition,则无法保证你收到的消息的顺序,而一个 patition 内的消息是有序的
The SimpleConsumer API
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
多次读取一个消息
只消费一个 patition 中的部分消息
使用事务来保证一个消息仅被消费一次但是使用此 API 时,partition、offset、broker、leader 等对你不再透明,需要自己去管理。你需要做大量的额外工作:
必须在应用程序中跟踪 offset,从而确定下一条应该消费哪条消息
应用程序需要通过程序获知每个 Partition 的 leader 是谁
需要处理 leader 的变更
14 kafka的exactly-once
幂等producer:保证发送单个分区的消息只会发送一次,不会出现重复消息
事务(transaction):保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚
流处理EOS:流处理本质上可看成是“读取-处理-写入”的管道。此EOS保证整个过程的操作是原子性。注意,这只适用于Kafka Streams
15 如何保证从Kafka获取数据不丢失?
1.生产者数据的不丢失
kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到。
2.消费者数据的不丢失
通过offset commit 来保证数据的不丢失,kafka自己记录了每次消费的offset数值,下次继续消费的时候,接着上次的offset进行消费即可。
16 spark实时作业宕掉,kafka指定的topic数据堆积怎么办?
应对措施:
①spark.streaming.concurrentJobs=10:提高Job并发数,从源码中可以察觉到,这个参数其实是指定了一个线程池的核心线程数而已,没有指定时,默认为1。
②spark.streaming.kafka.maxRatePerPartition=2000:设置每秒每个分区最大获取日志数,控制处理数据量,保证数据均匀处理。
③spark.streaming.kafka.maxRetries=50:获取topic分区leaders及其最新offsets时,调大重试次数。
④在应用级别配置重试
spark.yarn.maxAppAttempts=5
#尝试失败有效间隔时间设置
spark.yarn.am.attemptFailuresValidityInterval=1h
此处需要【注意】:
spark.yarn.maxAppAttempts值不能超过hadoop集群中yarn.resourcemanager.am.max-attempts
另外的解决思路
在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 OOM 问题而出现失败的情况。
而在 Spark 1.5 版本之前,为了解决这个问题,对于 Receiver-based 数据接收器,我们可以通过配置 spark.streaming.receiver.maxRate 参数来限制每个 receiver 每秒最大可以接收的记录的数据;对于 Direct Approach 的数据接收,我们可以通过配置 spark.streaming.kafka.maxRatePerPartition 参数来限制每次作业中每个 Kafka 分区最多读取的记录条数。这种方法虽然可以通过限制接收速率,来适配当前的处理能力,但这种方式存在以下几个问题:
• 我们需要事先估计好集群的处理速度以及消息数据的产生速度;
• 这两种方式需要人工参与,修改完相关参数之后,我们需要手动重启 Spark Streaming 应用程序;
• 如果当前集群的处理能力高于我们配置的 maxRate,而且 producer 产生的数据高于 maxRate,这会导致集群资源利用率低下,而且也会导致数据不能够及时处理。
在 Spark 启用反压机制很简单,只需要将 spark.streaming.backpressure.enabled 设置为 true 即可,这个参数的默认值为 false。反压机制还涉及以下几个参数,包括文档中没有列出来的:
• spark.streaming.backpressure.initialRate: 启用反压机制时每个接收器接收第一批数据的初始最大速率。默认值没有设置。
• spark.streaming.backpressure.rateEstimator:速率估算器类,默认值为 pid ,目前 Spark 只支持这个,大家可以根据自己的需要实现。
• spark.streaming.backpressure.pid.proportional:用于响应错误的权重(最后批次和当前批次之间的更改)。默认值为1,只能设置成非负值。weight for response to “error” (change between last batch and this batch)
• spark.streaming.backpressure.pid.integral:错误积累的响应权重,具有抑制作用(有效阻尼)。默认值为 0.2 ,只能设置成非负值。weight for the response to the accumulation of error. This has a dampening effect.
• spark.streaming.backpressure.pid.derived:对错误趋势的响应权重。 这可能会引起 batch size 的波动,可以帮助快速增加/减少容量。默认值为0,只能设置成非负值。weight for the response to the trend in error. This can cause arbitrary/noise-induced fluctuations in batch size, but can also help react quickly to increased/reduced capacity.
• spark.streaming.backpressure.pid.minRate:可以估算的最低费率是多少。默认值为 100,只能设置成非负值。
17 produce向kafka中发送数据产生的offset 怎么算(给你传入几条大小的消息 求offset是多少) 什么是offset
offset是consumer position,Topic的每个Partition都有各自的offset.
消费者需要自己保留一个offset,从kafka 获取消息时,只拉去当前offset 以后的消息。Kafka 的scala/java 版的client 已经实现了这部分的逻辑,将offset 保存到zookeeper 上
1) auto.offset.reset
如果Kafka没有开启Consumer,只有Producer生产了数据到Kafka中,此后开启Consumer。在这种场景下,将auto.offset.reset设置为largest,那么Consumer会读取不到之前Produce的消息,只有新Produce的消息才会被Consumer消费
2) auto.commit.enable(例如true,表示offset自动提交到Zookeeper)
3) auto.commit.interval.ms(例如60000,每隔1分钟offset提交到Zookeeper)
4) offsets.storage
Select where offsets should be stored (zookeeper or kafka).默认是Zookeeper
5) 基于offset的重复读
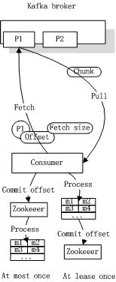
6) Kafka的可靠性保证(消息消费和Offset提交的时机决定了At most once和At least once语义)
Kafka默认实现了At least once语义















 1979
1979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









