










手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。 本文将会对LeNet这个网络结构进行详细的讲解,并记录下自己的学习内容,作为自己日常的复习笔记。在学习过程中,我参阅了网上众多大佬的博文,将会在本博文的最后以参考文献的形式列出来。对此对所有的网上大佬表示感谢。
一、LeNet简介
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个Feature Map是通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。
1.1卷积层的原理
卷积原因的详细知识点,可以参阅:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
torch.nn.Conv2d()的参数解释如下:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros',
device=None, dtype=None)
参数说明:
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
kernel_size (int or tuple) – Size of the convolving kernel
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0
padding_mode (string, optional) – ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If True, adds a learnable bias to the output. Default: True
in_channels:输入特征矩阵的深度。如输入一张RGB彩色图像,那in_channels=3
out_channels:输入特征矩阵的深度。也等于卷积核的个数,使用n个卷积核输出的特征矩阵深度就是n
kernel_size:卷积核的尺寸。可以是int类型,如3 代表卷积核的height=width=3,也可以是tuple类型如(3, 5)代表卷积核的height=3,width=5
stride:卷积核的步长。默认为1,和kernel_size一样输入可以是int型,也可以是tuple类型
padding:补零操作,默认为0。可以为int型如1即补一圈0,如果输入为tuple型如(2, 1) 代表在上下补2行,左右补1列。
经过卷积后的输出大小计算为下:

1.2下采样层
self.pool1 = nn.MaxPool2d(2, 2)
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0,
dilation=1, return_indices=False, ceil_mode=False)
kernel_size – the size of the window to take a max over
stride – the stride of the window. Default value is kernel_size
padding – implicit zero padding to be added on both sides
dilation – a parameter that controls the stride of elements in the window
return_indices – if True, will return the max indices along with the outputs. Useful for torch.nn.MaxUnpool2d later
ceil_mode – when True, will use ceil instead of floor to compute the output shape
经过池化后的输出大小计算为下:

1.3 LeNet网络结构的详细讲解
卷积神经网络流行之前,我们做分类时常用的是“两段论”,即先用各种特征提取方法,如HOG、SIFT等,再连接分类器,如SVM、贝叶斯分类器等。这种方法工作量大,且最终效果并不好(一部分原因在于 不同特征提取方法和不同分类器的结合,效果无法预测)。而CNN采用的是端到端(end to end)的方法,将特征提取和分类方法全部由计算机自动计算,一方面减少了我们探寻特征提取和分类器的工作,另一方面也会使得分类效果更好。
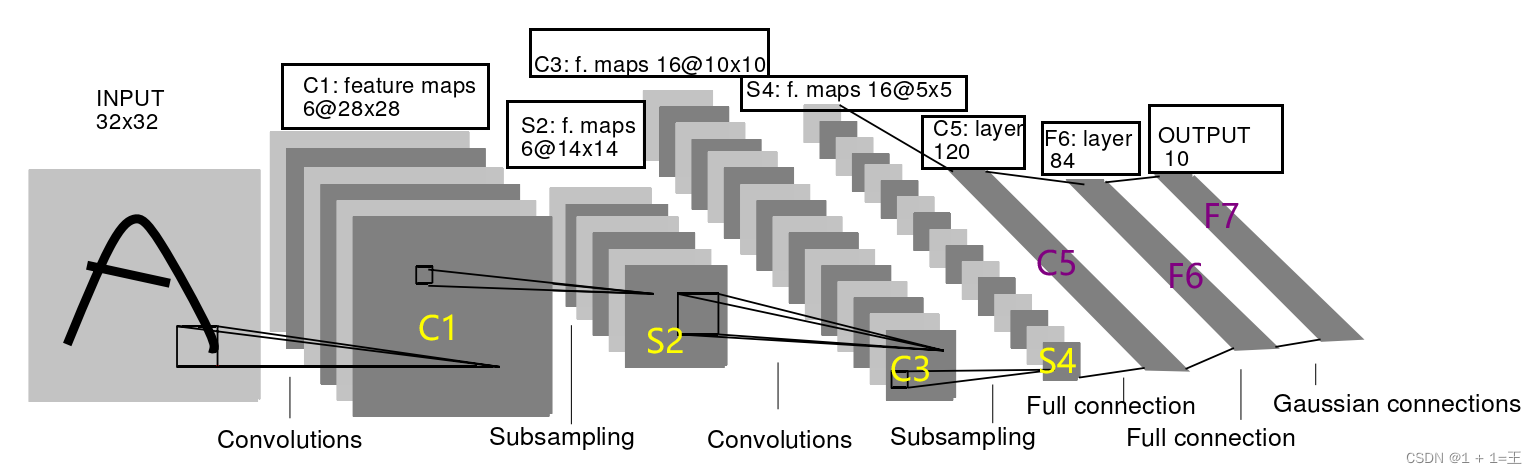
LeNet5由7层CNN(不包含输入层)组成,上图中输入的原始图像大小是32×32像素,卷积层用Ci表示,子采样层(pooling,池化)用Si表示,全连接层用Fi表示。下面逐层介绍其作用和示意图上方的数字含义。

LeNet模型的网络结构代码:
class LeNet(nn.Module): # 继承于nn.Module这个父类
def __init__(self): # 初始化网络结构
super(LeNet, self).__init__() # 多继承需用到super函数
self.conv1 = nn.Conv2d(3, 16, 5) #16代表输出的通道数,可以根据实际的情况进行调整
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5) #这里的16和前面的那个16需要对应。
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 正向传播过程
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x(1)输入:网络输入为32*32的单通道图像,我们利用LeNet-5分类时应resize图像为32*32.
(2)第一层:卷积层(C1层):卷积层的目的是提取图像特征,神经网络结构中较前的卷积层主要提取图像的细节特征,较后的卷积层主要提取图像的全局特征。对输入的单通道32*32图像用16个不同的5*5卷积核(也称为滤波器)从左到右,从上到下进行卷积操作.最后结果为16个特征图(feature map,有几个卷积核就有几个对应的特征图),每个特征图大小为28*28(因为输入为32*32,卷积核为5*5,步长(stride)为1,且没有进行补边(padding)操作,所以输出大小为(32-5+1)*(32-5+1)=28*28).
(具体的计算方式,看上文所示)
C1是一个卷积层,卷积核大小为5,输入大小为3X32X32,输出特征图大小为16X28X28。
self.conv1 = nn.Conv2d(3, 16, 5)

(3)第二层:池化层(pooling层,也称为下采样层(subsampling),S2层):下采样层主要降低数据维度。这一层在16个输入特征图做2*2 池化,步长为2(没有重叠池化),所以输出为16个14*14的特征图。具体池化过程为在输入特征图中2*2的范围将四个输入值相加,然后乘以一个权重,然后加上一个偏置,最后经过sigmoid激活函数输出。
S2是一个池化层,kernel_size为2,stride为2,输入大小为16X28X28,输出特征图大小为16X14X14。
self.pool1 = nn.MaxPool2d(2, 2)
(4)第三层:卷积层(C3层):这一层输出为32个10*10的特征图。首先采用的卷积核仍然是5*5,所以输出的特征图大小为(14-5+1)*(14-5+1)=10*10.那么,上一层的16个特征图和这一层的32个特征图是如何连接的呢?
C3是一个卷积层,卷积核大小为5,输入大小为16X14X14,输出特征图大小为32X10X10。
self.conv2 = nn.Conv2d(16, 32, 5)
(5)第四层:池化层(S4层):这一层输入为32个10*10的特征图,经过2*2的池化后输出为16个5*5的特征图。具体池化过程同S2层。
S4是一个池化层,kernel_size为2,stride为2,输入大小为32X10X10,输出特征图大小为32X5X5。
self.pool2 = nn.MaxPool2d(2, 2)
(6)第五层:卷积层(C5层):这一层输入为32个5*5的特征图,经过5*5的卷积核操作后,输出为120个1*1的特征图((5-5+1)*(5-5+1)=1*1)。
C5是一个卷积层,卷积核大小为5,输入大小为32X5X5,输出特征图大小为120X1X1。
此处用全连接层代替
self.fc1 = nn.Linear(32*5*5, 120)
(7)第六层:全连接层(Full connection,F6层):这一层输入为120个1*1的特征图,即120*1维向量,输出为84个1*1的特征图,即84*1维向量,连接方式为全连接,即F6层的每一个神经元都与C5层的每一个神经元连接。输出为输入和权重卷积后加上偏置,在经过sigmoid激活函数后得到。
F6是一个全连接层,输入大小为120,输出特征图大小为84。
self.fc2 = nn.Linear(120, 84)
(8)第七层:全连接层(F7层,输出层):输入为84*1维向量,输出为10*1维向量(10个分类结果,LeNet-5最早应用于手写体数字识别,所以为10个类别)。这一层采用的是径向基函数(RBF)的网络连接方式。
F7是一个全连接层,输入大小为84,输出特征图大小为10(表示有10种类别)。
self.fc3 = nn.Linear(84, 10)
如今看来,LeNet-5很简单,但其设计的卷积层、下采样层、全连接层等在深度学习的发展中有着里程碑式的意义。LeCun在其论文中总结如下:
Convolutional networks combine three architectural ideas to ensure some degree of shift, scale, and distortion invariance: 1) local receptive fields; 2) shared weights (or weight replication); and 3) spatial or temporal subsampling.
卷积网络有三个设计意图以确保一定程度的偏移、缩放和翻转不变:1)局部感受野 2)共享权值 3)空间或时间下采样
为了更加直观的查看模型的网络结构,我们可以采用如下的方式将网络结构导出。
具体可查看博文:pytorch快速上手-----netron查看神经网络结构图_欲游山河十万里的博客-CSDN博客
torch.onnx.export()是一个用于将PyTorch模型导出为ONNX模型的函数。它的参数含义如下:
model: 要导出的PyTorch模型。args: 模型的输入参数。这应该是一个元组,其中包含模型的输入张量。f: 导出的ONNX模型的文件路径。export_params: 是否将模型参数导出为ONNX模型的常量。如果为True,则会将模型参数转换为常量,并将其存储在导出的ONNX模型中。如果为False,则不会将参数导出为常量,而是在运行时加载它们。opset_version: 导出的ONNX模型使用的ONNX规范版本号。默认为10。do_constant_folding: 是否在导出过程中进行常量折叠。如果为True,则会在导出过程中尝试将计算图中的常量合并为单个常量节点。如果为False,则不会进行常量折叠。input_names: 导出的ONNX模型中输入张量的名称。默认为["input"]。output_names: 导出的ONNX模型中输出张量的名称。默认为["output"]。dynamic_axes: 导出的ONNX模型中动态维度的名称和位置。默认为None。verbose: 控制是否打印导出过程中的详细信息。如果为True,则会打印详细信息,否则不会打印。这些参数可以帮助我们控制导出过程的各个方面,以便我们能够生成我们需要的ONNX模型。
二、LeNet代码实现
2.1 model.py
# 使用torch.nn包来构建神经网络.
import torch.nn
import torch.nn as nn
import torch.nn.functional as F
import onnx.version_converter
class LeNet(nn.Module): # 继承于nn.Module这个父类
def __init__(self): # 初始化网络结构
super(LeNet, self).__init__() # 多继承需用到super函数
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 正向传播过程
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
data = torch.randn(10,3,32,32)#N-Cin-Hin-Win
net = LeNet()
# 导出
torch.onnx.export(
net,
data,
'LeNetModel.onnx',
export_params=True,
opset_version=10,
)
# 增加维度信息
model_file = 'LeNetModel.onnx'
onnx_model = onnx.load(model_file)
onnx.save(onnx.shape_inference.infer_shapes(onnx_model), model_file)2.2 train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录
train=True, # 表示是数据集中的训练集
download=True, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集
batch_size=50, # 每批训练的样本数
shuffle=False, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
net = LeNet()
net.to(device) # 将网络分配到指定的device中
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5):
net.train()
running_loss = 0.0
time_start = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
loss.backward()
optimizer.step()
running_loss += loss.item()
if step % 1000 == 999:
net.eval()
with torch.no_grad():
outputs = net(val_image.to(device)) # 将test_image分配到指定的device中
predict_y = torch.max(outputs, dim=1)[1]
accuracy = (predict_y == val_label.to(device)).sum().item() / val_label.size(0) # 将test_label分配到指定的device中
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 1000, accuracy))
print('%f s' % (time.perf_counter() - time_start))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
2.2.1代码解答
transform = transforms.Compose的参数
transforms.Compose是 PyTorch 中的一个类,用于将多个图像变换(transform)组合成一个变换序列。它接受一个列表(list)作为参数,每个列表元素都是一个变换操作(transform)。
transforms.Compose的参数是由多个变换操作组成的列表,每个变换操作都是 PyTorch 中transforms模块中的一个类,常见的变换操作包括:
transforms.Resize(size):调整图像大小transforms.CenterCrop(size):中心裁剪transforms.RandomCrop(size, padding=None):随机裁剪transforms.RandomHorizontalFlip():随机水平翻转transforms.ToTensor():将图像转换为 Tensortransforms.Normalize(mean, std):标准化图像
举个例子,如果要将图像先调整为大小为 224X224,然后将其转换为 Tensor,最后进行标准化处理,可以这样写:
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
其中,
Resize将图像调整为大小为 224X224,ToTensor将图像转换为 Tensor,Normalize对图像进行标准化处理。注意,这里的mean和std是根据 ImageNet 数据集计算得到的。在实际使用中,需要根据具体的数据集计算出相应的mean和std。
transforms.Normalize参数确定
在PyTorch中,
transforms.Normalize用于对图像进行归一化操作,使其在各个通道上的均值为0、标准差为1,从而加快模型的训练收敛和提高模型的泛化能力。transforms.Normalize的参数取决于训练集的均值和标准差,一般可以通过以下方式计算:
- 对训练集的每个通道分别计算均值和标准差,例如对于3通道的RGB图像,可以分别计算三个通道的均值和标准差,得到一个形状为(3,)的均值向量和标准差向量。
- 将计算得到的均值和标准差作为
transforms.Normalize的参数传入,例如transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])。
可以用以下的代码实现计算机
import torch
from torchvision import datasets, transforms
train_transforms = transforms.Compose([ transforms.ToTensor(),])
train_dataset = datasets.ImageFolder('path/to/train', transform=train_transforms)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
# 计算均值和标准差
mean = 0.
std = 0.
nb_samples = 0.
for data, _ in train_loader:
batch_samples = data.size(0)
data = data.view(batch_samples, data.size(1), -1)
mean += data.mean(2).sum(0)
std += data.std(2).sum(0)
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
print('mean:', mean)
print('std:', std)
net.train()的作用
在深度学习中,神经网络的训练是指通过反向传播算法来优化网络中的参数,以最小化损失函数并提高模型的预测准确性。在PyTorch中,
net.train()是一个方法,用于设置神经网络处于训练模式。当调用
net.train()方法时,PyTorch会启用一些特性,例如Dropout和Batch Normalization,在训练期间对输入数据进行处理,以增强网络的泛化能力和稳健性。此外,这也会告诉PyTorch在反向传播时计算梯度,以便更新模型的参数。需要注意的是,在测试或评估阶段,应该使用
net.eval()方法,以便禁用这些特性并确保网络处于评估模式。
net.eval()的作用
在深度学习中,神经网络的测试或评估是指使用已训练好的模型对新数据进行预测,以评估模型的性能和准确性。在PyTorch中,
net.eval()是一个方法,用于设置神经网络处于评估模式。当调用
net.eval()方法时,PyTorch会禁用一些特性,例如Dropout和Batch Normalization,以确保网络对输入数据的处理是稳定和确定性的。此外,这也会告诉PyTorch不要计算梯度,以避免浪费计算资源。需要注意的是,在训练阶段,应该使用
net.train()方法,以便启用这些特性并确保网络处于训练模式。
2.3 predict.py
# 导入包
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
# 数据预处理
transform = transforms.Compose(
[transforms.Resize((32, 32)), # 首先需resize成跟训练集图像一样的大小
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入要测试的图像(自己找的,不在数据集中),放在源文件目录下
im = Image.open('img.png')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # 对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]
# 实例化网络,加载训练好的模型参数
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
# 预测
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net.eval()
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].data.numpy()
print(classes[int(predict)])2.4 modelView.py
# 使用netron进行模型可视化
import netron
# 模型的路径
modelPath = "LeNetModel.onnx"
# 启动模型
netron.start(modelPath)三、使用LeNet模型进行项目训练
3.1训练手写数字识别
手写数字识别是一个非常简单的练习,但是对于我这个新手来说依然充满着挑战。下面我们具体的实现一下手写数字识别的相关项目。
首先手写数字的训练图片采用的是28X28的。所以根据实际的需要,模型结构中的输入和输出需要进行调整。具体如下所示。
class LeNetDemo1(nn.Module):# 继承于nn.Module这个父类
def __init__(self):
super(LeNetDemo1, self).__init__()
self.conv = nn.Sequential(#input (N,1,28,28)
nn.Conv2d(1, 6, 5), #output(N,6,24,24)第一层卷积
nn.ReLU(),
nn.MaxPool2d(2, 2), #output(N,6,12,12)第二层池化
nn.Conv2d(6, 16, 5), #output(N,16,8,8)第三层卷积
nn.ReLU(),
nn.MaxPool2d(2, 2) #output(N,16,4,4) 第四层池化
)
self.fc = nn.Sequential(
nn.Linear(16 * 4 * 4, 120),#output(N,120) 第五层全连接
nn.ReLU(),
nn.Linear(120, 84),#output(N,84) 第六层全连接
nn.ReLU(),
nn.Linear(84, 10)#output(N,10) 第七层全连接
)
def forward(self, img): # 这里定义前向传播的方法,为什么没有定义反向传播的方法呢?这其实就涉及到torch.autograd模块了,
#img = img.unsqueeze(1)# (batch_size, 1, 28, 28)
feature = self.conv(img)
# 把120张大小为1的图像当成一个长度为120的一维tensor?
# .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。
# 第一个参数-1是说这个参数由另一个参数确定, 比如矩阵在元素总数一定的情况下,确定列数就能确定行数。
# 那么为什么这里只关心列数不关心行数呢,因为马上就要进入全连接层了,而全连接层说白了就是矩阵乘法,
# 你会发现第一个全连接层的首参数是16*5*5,所以要保证能够相乘,在矩阵乘法之前就要把x调到正确的size
# 更多的Tensor方法参考Tensor: http://pytorch.org/docs/0.3.0/tensors.html
output = self.fc(feature.view(img.shape[0], -1))
return output然后是训练部分的代码,如下所示。
#对模型的训练过程进行代码注释
import torch
import torchvision
import torch.nn as nn
from model import LeNet, LeNetDemo1
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
# Compose将多个步骤组合在一起
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((28,28)),
transforms.Normalize((0.1307), (0.3081))
])
# 导入60000张训练图片
train_set = torchvision.datasets.MNIST(root='./data', # 数据集存放目录
train=True, # 表示是数据集中的训练集
download=True, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集
batch_size=100, # 每批训练的样本数
shuffle=False, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=1000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
net = LeNetDemo1()#导入模型网络
net.to(device) # 将网络分配到指定的device中
loss_function = nn.CrossEntropyLoss()#定义损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001)#定义优化器,nets.parameters()是指网络中的参数,lr是学习率
#画图用的变量
train_loss = []#训练集的损失集合
train_acc= []#训练集的准确率集合
test_acc = []#测试集的准确率集合
epochs=4#训练的轮数
for epoch in range(epochs):#训练的轮数
net.train()#训练模式
running_loss = 0.0#训练集的损失
time_start = time.perf_counter()#计时开始
for step, data in enumerate(train_loader, start=0):#step是训练集的批次,data是训练集的数据
inputs, labels = data#inputs是训练集的图片,labels是训练集的标签
#print(f"labels.size(0)的值是{labels.size(0)}")
#print(f"step的值是{step}")
optimizer.zero_grad()#梯度清零
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
loss.backward()#反向传播
optimizer.step()#更新参数
running_loss += loss.item()#训练集的损失
y_hat= net(inputs.to(device))
train_accuary=(y_hat.argmax(dim=1) == labels.to(device)).sum().item()/labels.size(0)#训练集的准确率
if step % 100 == 99:
with torch.no_grad():#不计算梯度
net.eval()#验证模式
outputs = net(val_image.to(device)) # 将test_image分配到指定的device中
predict_y = torch.max(outputs, dim=1)[1]#取出最大值的索引
accuracy = (predict_y == val_label.to(device)).sum().item() / val_label.size(0) # 将test_label分配到指定的device中
print('[%d, %5d] train_loss: %.3f train_acc:%.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss/100,train_accuary, accuracy))
if step+1==600:
train_loss.append(running_loss/100)
test_acc.append(accuracy)
train_acc.append(train_accuary)#训练过程中的准确率
print('%f s' % (time.perf_counter() - time_start))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
print(len(train_loss),len(test_acc),len(train_acc))
#绘制图形
index=[i for i in range(1,epochs+1)]
plt.plot(index,train_loss,'g',label="train_loss")
plt.plot(index,train_acc,'b',label="train_acc")
plt.plot(index,test_acc,'m',label="test_acc")
plt.xlabel("epoch")
plt.legend()
plt.pause(0.01) # 暂停0.01秒for step, data in enumerate(train_loader, start=0)的作用
这是一行Python代码,用于在训练神经网络时从训练数据集中加载批次数据。
train_loader是一个PyTorch的DataLoader对象,用于迭代训练数据集中的批次数据。 enumerate(train_loader, start=0) 是Python内置函数enumerate()的调用,它会返回一个迭代器,该迭代器会生成一个由(index, data) 元组组成的序列,其中index表示当前批次数据的索引(从0开始),data表示当前批次数据本身。 for step, data in enumerate(train_loader,start=0) 是一个for循环,用于遍历enumerate()生成的迭代器中的每一个(index, data)元组。 在每一次迭代中,step会被设置为当前批次数据的索引,data会被设置为当前批次数据本身。 这样,我们就可以对每一个批次数据进行处理或训练了。
第一次使用时要将download设置为True才会自动去下载数据集 val_set = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform) val_loader = torch.utils.data.DataLoader(val_set, batch_size=1000, shuffle=False, num_workers=0)的作用这段代码使用了 PyTorch 中 torchvision.datasets 模块中的 MNIST 数据集。MNIST 是一个手写数字数据集,包含了许多手写数字图片及其对应的标签。 这里使用了 MNIST 中的验证集,即测试集。参数 train=False 表示加载测试集,download=True 表示如果本地没有下载过该数据集, 将自动下载到指定的 root 目录下。transform 是对数据集进行预处理的方法, 这里使用了一个名为 transform 的变量,可能是事先定义好的数据处理操作,比如将数据转换成 Tensor 格式并进行归一化等操作。 之后,将 val_set 传给了一个 DataLoader, 用于分批次读取数据。参数 batch_size=1000 表示每次读取的数据批次大小为 1000,shuffle=False 表示不打乱数据集顺序,num_workers=0 表示使用主线程读取数据集。
# 导入50000张训练图片 train_set = torchvision.datasets.MNIST(root='./data', # 数据集存放目录 train=True, # 表示是数据集中的训练集 download=True, # 第一次运行时为True,下载数据集,下载完成后改为False transform=transform) # 预处理过程 # 加载训练集,实际过程需要分批次(batch)训练 train_loader = torch.utils.data.DataLoader(train_set, # 导入的训练集 batch_size=28, # 每批训练的样本数 shuffle=False, # 是否打乱训练集 num_workers=0) # 使用线程数,在windows下设置为0这段代码是用来加载 MNIST 数据集的训练集。MNIST 数据集是一个手写数字图像数据集, 共有 60000 张训练图片和 10000 张测试图片,每张图片都是 28x28 的灰度图像。 torchvision.datasets.MNIST() 函数会返回一个 MNIST 对象, 该对象代表 MNIST 数据集中的训练集或测试集。其中的参数 root 是数据集存放的目录, train 表示是否加载训练集,download 表示是否下载数据集,transform 是对每张图片进行的预处理操作。 在这里,我们使用了一个叫做 transform 的对象对图片进行预处理。 torch.utils.data.DataLoader() 函数用于将数据集分批次读入。 其中的参数 train_set 是我们加载的训练集对象,batch_size 表示每批次训练的样本数, shuffle 表示是否打乱训练集,num_workers 表示使用的线程数。在这里,我们将每批次的样本数设为 28,不 打乱训练集,线程数设为 0(在 Windows 系统下需要这样设置)。
训练10轮之后的结果如下


从训练结果来看,这个训练的结果还是比较不错,现在我们就开始用自己写的数字图片然后进行预测。
预测代码的实现。
from PIL import Image, ImageOps
import torchvision.transforms as transforms
import torch
from model import LeNet, LeNetDemo1
if __name__ == '__main__':
# 实例化模型
model = LeNetDemo1()
# 损失函数
# 加载模型的参数
model.load_state_dict(torch.load("Lenet.pth"))
# 切换为测试状态
model.eval()
img_path = "data/draw.jpg"
# 转换图片
image = Image.open(img_path).convert('L')
image = ImageOps.invert(image)
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize([0.1307], [0.3081])
])
image = transform(image)
#image = image.unsqueeze(0)
# transforms.ToPILImage()(image.squeeze(0)).save(img_path)
with torch.no_grad():
output = model(image)
# print(output.squeeze(0))
prediction = output.argmax(dim=1, keepdim=True)
print("预测结果:", prediction.item())
为了更好的实现界面的美观划,我借用了一些界面设计进行项目的展示,具体如图所示。

写在了最后
本次的源代码我将会放置在casn的资源中,但是请不要下载这个资源,资源我将会设置文件压缩密码,请不要下载资源。由于本人的水平暂时有限,所以代码存在的一定的问题。暂时不做开源处理。计划后期个人水平提升之后会进行项目开源,敬请期待,感谢。
源码地址:https://download.csdn.net/download/qq_41221411/87614467
参考文献
经典CNN之:LeNet介绍_Sheldon_King的博客-CSDN博客
卷积神经网络(CNN)LeNet-5详解_分辨率为32的图像如何卷积_王阿宅-自定义的博客-CSDN博客
CNN经典网络(1)---LeNet(模型搭建+训练+预测+可视化)_balabalaba5的博客-CSDN博客
卷积神经网络模型之——LeNet网络_3层卷积神经网络_Bryant327的博客-CSDN博客
Pytorch学习(四)—— Lenet模型训练_HelloWorldQAQ。的博客-CSDN博客
LeNet无需调参即可提高精准度并且降低损失,超过AlexNet_lenet 调参_小刘研CV的博客-CSDN博客
Python四行代码实现的猜数字小游戏,基于thinker,带GUI界面_程序员柳的博客-CSDN博客
















 3603
3603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











