







在本教程中,我们将重点介绍TDNN分类器 ( xvector ) 和一个名为ECAPA-TDNN 的最新模型,该模型在说话人验证和分类方面表现出令人印象深刻的性能。
数据:
训练将使用一个名为mini-librispeech的小型开源数据集完成,该数据集仅包含几个小时的训练数据。
代码:
在本教程中,我们将参考speechbrain/templates/speaker_id.
需要准备三个步骤:
-
准备数据。此步骤的目标是创建数据清单文件(CSV 或 JSON 格式)。数据清单文件告诉 SpeechBrain 在哪里可以找到语音数据及其相应的话语级别分类(例如,说话者 ID)。在本教程中,数据清单文件由mini_librispeech_prepare.py创建。
-
训练分类器。此时,我们已准备好训练我们的分类器。要基于 TDNN + statistical pooling (xvectors) 训练说话者 id 分类器,请运行以下命令:
cd speechbrain/templates/speaker_id/
python train.py train.yaml稍后,我们将描述如何插入另一个称为强调通道注意力、传播和聚合模型 (ECAPA) 的模型,该模型在说话人识别任务中提供了令人印象深刻的性能。
3.使用分类器(推理):训练完成后,我们可以使用分类器进行推理。一个名为的类EncoderClassifier旨在使推理更容易。我们还设计了一个类,SpeakerRecognition用于简化说话人验证任务的推理。
我们现在将提供所有这些步骤的详细说明。
第 1 步:准备数据
数据准备的目标是创建数据清单文件。这些文件告诉 SpeechBrain 在哪里可以找到音频数据及其相应的话语级别分类。它们是以流行的 CSV 和 JSON 格式编写的文本文件。
数据清单文件
让我们来看看 JSON 格式的数据清单文件是怎样的:
{
"163-122947-0045": {
"wav": "{data_root}/LibriSpeech/train-clean-5/163/122947/163-122947-0045.flac",
"length": 14.335,
"spk_id": "163"
},
"7312-92432-0025": {
"wav": "{data_root}/LibriSpeech/train-clean-5/7312/92432/7312-92432-0025.flac",
"length": 12.01,
"spk_id": "7312"
},
"7859-102519-0036": {
"wav": "{data_root}/LibriSpeech/train-clean-5/7859/102519/7859-102519-0036.flac",
"length": 11.965,
"spk_id": "7859"
},
}如您所见,我们有一个层次结构,其中第一个key是口语句子的唯一标识符。然后,我们指定所处理任务所需的所有字段。举例来说,我们报告的讲话记录的路径,其长度在几秒钟内(如果我们想创建迷你批次前的句子排序需要),以及说话人识别说话人在给定的记录。
实际上,您可以在此处指定您需要的所有条目(语言 ID、情感注释等)。但是,这些条目的名称与实验脚本(例如 train.py)期望的名称之间必须匹配。我们稍后会详细说明这一点。
您可能已经注意到,我们定义了一个名为 的特殊变量data_root。这允许用户从命令行(或从 yaml 超参数文件)动态更改数据文件夹。
准备脚本
每个数据集都以不同的方式格式化。解析您自己的数据集并创建 JSON 或 CSV 文件的脚本是您应该编写的。大多数时候,这非常简单。
例如,对于 mini-librispeech 数据集,我们编写了一个名为mini_librispeech_prepare.py 的简单数据准备脚本。
此功能会自动下载数据(在这种情况下是公开可用的)。我们搜索所有音频文件,并在读取它们时创建带有 Speaker-id 注释的 JSON 文件。
您可以将此脚本用作在目标数据集上进行自定义准备的良好基础。如您所见,我们创建了三个单独的数据清单文件来管理训练、验证和测试阶段。
在本地复制您的数据
在 HPC 集群中使用 Speechbrain(或任何其他工具包)时,一个好的做法是将数据集压缩到单个文件中,然后将数据复制(和解压缩)到计算节点的本地文件夹中。这将使代码更快,因为数据不是从共享文件系统中提取的,而是从本地文件系统中提取的。此外,大量读取操作不会损害共享文件系统的性能。我们强烈建议用户遵循这种方法(在 Google Colab 中这是不可能的)。
第 2 步:训练分类器
我们现在展示如何使用 SpeechBrain训练话语级分类器。建议执行特征计算/归一化,使用编码器处理特征,并在其上应用分类器。数据增强也用于提高系统性能。
训练说话者 ID 模型
我们将训练用于 x 向量的基于 TDNN 的模型。在卷积层的顶部使用统计池将可变长度的句子转换为固定长度的嵌入。
在嵌入的顶部,使用一个简单的全连接分类器来预测给定句子中的 N 个说话者中的哪一个是活跃的。
要训练此模型,请运行以下代码:
%cd /content/speechbrain/templates/speaker_id
!python train.py train.yaml --number_of_epochs=15 #--device='cpu'正如您从打印中看到的,验证和训练损失在第一个 epoch 中都在快速下降。然后,我们基本上看到了一些小的改进和性能波动。
在训练结束时,验证误差应该为零(或非常接近于零)。
本教程中提出的任务非常简单,因为我们只需对 mini-librispeech 数据集的 28 个说话者进行分类。以本教程为例,说明如何设置开发语音分类器所需的所有组件。如果您想查看有关流行说话人识别数据集的示例,请参阅我们的 voxceleb 食谱
在深入代码之前,让我们看看在指定的output_folder.
-
train_log.txt:包含在每个时期计算的统计数据(例如,train_loss、valid_loss)。 -
log.txt: 是一个更详细的记录器,包含每个基本操作的时间戳。 -
env.log:显示与其对应版本一起使用的所有依赖项(对于可复制性很有用)。 -
train.py,hyperparams.yaml: 是实验文件的副本以及相应的超参数(用于可复制性)。 -
save: 是我们存储学习模型的地方。
在save文件夹中,您可以找到包含训练期间保存的检查点的子文件夹(格式为CKPT+data+time)。通常,您会在此处找到两个检查点:最好的(即最旧的)和最新的(即最近的)。如果您只找到一个检查点,则意味着最后一个 epoch 也是最好的。
在每个检查点内,我们存储恢复训练所需的所有信息(例如,模型、优化器、调度器、纪元计数器等)。嵌入模型的参数在embedding_model.ckpt文件中报告,而分类器的参数在classifier.ckpt. 这只是一种二进制格式,可以使用torch.load.
save 文件夹也包含标签编码器( label_encoder.txt),它将每个 ID 条目映射到它们相应的索引。
'163' => 0
'7312' => 1
'7859' => 2
'19' => 3
'1737' => 4
'6272' => 5
'1970' => 6
'2416' => 7
'118' => 8
'6848' => 9
'4680' => 10
'460' => 11
'3664' => 12
'3242' => 13
'1898' => 14
'7367' => 15
'1088' => 16
'3947' => 17
'3526' => 18
'1867' => 19
'8629' => 20
'332' => 21
'4640' => 22
'2136' => 23
'669' => 24
'5789' => 25
'32' => 26
'226' => 27
================
'starting_index' => 0像往常一样,我们使用一个实验文件train.py和一个名为train.yaml.
超参数
yaml 文件包含实现所需分类器所需的所有模块和超参数。 您可以在此处查看完整的 train.yaml 文件。
在第一部分中,我们指定了一些基本设置,例如seed和输出文件夹的路径:
# Seed needs to be set at top of yaml, before objects with parameters are made
seed: 1986
__set_seed: !!python/object/apply:torch.manual_seed [!ref <seed>]
# If you plan to train a system on an HPC cluster with a big dataset,
# we strongly suggest doing the following:
# 1- Compress the dataset in a single tar or zip file.
# 2- Copy your dataset locally (i.e., the local disk of the computing node).
# 3- Uncompress the dataset in the local folder.
# 4- Set data_folder with the local path.
# Reading data from the local disk of the compute node (e.g. $SLURM_TMPDIR with SLURM-based clusters) is very important.
# It allows you to read the data much faster without slowing down the shared filesystem.
data_folder: ./data
output_folder: !ref ./results/speaker_id/<seed>
save_folder: !ref <output_folder>/save
train_log: !ref <output_folder>/train_log.txt然后我们指定用于训练、验证和测试的数据清单文件的路径:
# Path where data manifest files will be stored
# The data manifest files are created by the data preparation script.
train_annotation: train.json
valid_annotation: valid.json
test_annotation: test.json从实验文件 ( )调用数据准备脚本 ( mini_librispeech_prepare.py )时,将自动创建这些文件train.py。
接下来,我们设置train_logger并声明error_stats将收集分类错误率统计信息的对象:
# The train logger writes training statistics to a file, as well as stdout.
train_logger: !new:speechbrain.utils.train_logger.FileTrainLogger
save_file: !ref <train_log>
error_stats: !name:speechbrain.utils.metric_stats.MetricStats
metric: !name:speechbrain.nnet.losses.classification_error
reduction: batch我们现在可以指定一些训练超参数,例如 epoch 数、批量大小、学习率、epoch 数和嵌入维度。
ckpt_interval_minutes: 15 # save checkpoint every N min
# Feature parameters
n_mels: 23
# Training Parameters
sample_rate: 16000
number_of_epochs: 35
batch_size: 16
lr_start: 0.001
lr_final: 0.0001
n_classes: 28 # In this case, we have 28 speakers
emb_dim: 512 # dimensionality of the embeddings
dataloader_options:
batch_size: !ref <batch_size>该变量ckpt_interval_minutes可用于在训练时期内每 N 分钟保存一次检查点。在某些情况下,一个 epoch 可能需要几个小时,定期保存检查点是一种良好且安全的做法。这个基于小数据集的简单教程并不真正需要此功能。
我们现在可以定义训练模型所需的最重要的模块:
# Added noise and reverb come from OpenRIR dataset, automatically
# downloaded and prepared with this Environmental Corruption class.
env_corrupt: !new:speechbrain.lobes.augment.EnvCorrupt
openrir_folder: !ref <data_folder>
babble_prob: 0.0
reverb_prob: 0.0
noise_prob: 1.0
noise_snr_low: 0
noise_snr_high: 15
# Adds speech change + time and frequency dropouts (time-domain implementation)
# # A small speed change help to improve the performance of speaker-id as well.
augmentation: !new:speechbrain.lobes.augment.TimeDomainSpecAugment
sample_rate: !ref <sample_rate>
speeds: [95, 100, 105]
# Feature extraction
compute_features: !new:speechbrain.lobes.features.Fbank
n_mels: !ref <n_mels>
# Mean and std normalization of the input features
mean_var_norm: !new:speechbrain.processing.features.InputNormalization
norm_type: sentence
std_norm: False
# To design a custom model, either just edit the simple CustomModel
# class that's listed here, or replace this `!new` call with a line
# pointing to a different file you've defined.
embedding_model: !new:custom_model.Xvector
in_channels: !ref <n_mels>
activation: !name:torch.nn.LeakyReLU
tdnn_blocks: 5
tdnn_channels: [512, 512, 512, 512, 1500]
tdnn_kernel_sizes: [5, 3, 3, 1, 1]
tdnn_dilations: [1, 2, 3, 1, 1]
lin_neurons: !ref <emb_dim>
classifier: !new:custom_model.Classifier
input_shape: [null, null, !ref <emb_dim>]
activation: !name:torch.nn.LeakyReLU
lin_blocks: 1
lin_neurons: !ref <emb_dim>
out_neurons: !ref <n_classes>
# The first object passed to the Brain class is this "Epoch Counter"
# which is saved by the Checkpointer so that training can be resumed
# if it gets interrupted at any point.
epoch_counter: !new:speechbrain.utils.epoch_loop.EpochCounter
limit: !ref <number_of_epochs>
# Objects in "modules" dict will have their parameters moved to the correct
# device, as well as having train()/eval() called on them by the Brain class.
modules:
compute_features: !ref <compute_features>
env_corrupt: !ref <env_corrupt>
augmentation: !ref <augmentation>
embedding_model: !ref <embedding_model>
classifier: !ref <classifier>
mean_var_norm: !ref <mean_var_norm>增强部分基于env_corrupt(增加噪音和混响)和augmentation(增加时间/频率丢失和速度变化)。有关这些模块的更多信息,请查看有关环境破坏的教程和有关语音增强的教程。
我们用优化器、学习率调度器和检查点的声明来总结超参数规范:
# This optimizer will be constructed by the Brain class after all parameters
# are moved to the correct device. Then it will be added to the checkpointer.
opt_class: !name:torch.optim.Adam
lr: !ref <lr_start>
# This function manages learning rate annealing over the epochs.
# We here use the simple lr annealing method that linearly decreases
# the lr from the initial value to the final one.
lr_annealing: !new:speechbrain.nnet.schedulers.LinearScheduler
initial_value: !ref <lr_start>
final_value: !ref <lr_final>
epoch_count: !ref <number_of_epochs>
# This object is used for saving the state of training both so that it
# can be resumed if it gets interrupted, and also so that the best checkpoint
# can be later loaded for evaluation or inference.
checkpointer: !new:speechbrain.utils.checkpoints.Checkpointer
checkpoints_dir: !ref <save_folder>
recoverables:
embedding_model: !ref <embedding_model>
classifier: !ref <classifier>
normalizer: !ref <mean_var_norm>
counter: !ref <epoch_counter>在这种情况下,我们使用 Adam 作为优化器,并在 15 个 epoch 中线性学习率衰减。
现在让我们将最佳模型保存到一个单独的文件夹中(对后面解释的推理部分很有用):
# Create folder for best model
!mkdir /content/best_model/
# Copy label encoder
!cp results/speaker_id/1986/save/label_encoder.txt /content/best_model/
# Copy best model
!cp "`ls -td results/speaker_id/1986/save/CKPT* | tail -1`"/* /content/best_model/实验文件
现在让我们看看如何使用 yaml 文件中声明的对象、函数和超参数train.py来实现分类器。
让我们从主要的开始train.py:
# Recipe begins!
if __name__ == "__main__":
# Reading command line arguments.
hparams_file, run_opts, overrides = sb.parse_arguments(sys.argv[1:])
# Initialize ddp (useful only for multi-GPU DDP training).
sb.utils.distributed.ddp_init_group(run_opts)
# Load hyperparameters file with command-line overrides.
with open(hparams_file) as fin:
hparams = load_hyperpyyaml(fin, overrides)
# Create experiment directory
sb.create_experiment_directory(
experiment_directory=hparams["output_folder"],
hyperparams_to_save=hparams_file,
overrides=overrides,
)
# Data preparation, to be run on only one process.
sb.utils.distributed.run_on_main(
prepare_mini_librispeech,
kwargs={
"data_folder": hparams["data_folder"],
"save_json_train": hparams["train_annotation"],
"save_json_valid": hparams["valid_annotation"],
"save_json_test": hparams["test_annotation"],
"split_ratio": [80, 10, 10],
},
)我们在这里做一些初步的操作,比如解析命令行,初始化分布式数据并行(如果使用多个GPU需要),创建输出文件夹,读取yaml文件。
使用 读取 yaml 文件后load_hyperpyyaml,超参数文件中声明的所有对象都将被初始化并以字典形式提供(以及 yaml 文件中报告的其他函数和参数)。举例来说,我们将有hparams['embedding_model'],hparams['classifier'],hparams['batch_size'],等。
我们还运行prepare_mini_librispeech创建数据清单文件的数据准备脚本。它被包裹是sb.utils.distributed.run_on_main因为此操作将清单文件写入磁盘,即使在多 GPU DDP 场景中,这也必须在单个进程上完成。有关如何使用多个 GPU 的更多信息,请查看本教程。
数据-IO管道
然后我们调用一个特殊的函数来创建用于训练、验证和测试的数据集对象。
# Create dataset objects "train", "valid", and "test".
datasets = dataio_prep(hparams)让我们仔细看看。
def dataio_prep(hparams):
"""This function prepares the datasets to be used in the brain class.
It also defines the data processing pipeline through user-defined functions.
We expect `prepare_mini_librispeech` to have been called before this,
so that the `train.json`, `valid.json`, and `valid.json` manifest files
are available.
Arguments
---------
hparams : dict
This dictionary is loaded from the `train.yaml` file, and it includes
all the hyperparameters needed for dataset construction and loading.
Returns
-------
datasets : dict
Contains two keys, "train" and "valid" that correspond
to the appropriate DynamicItemDataset object.
"""
# Initialization of the label encoder. The label encoder assignes to each
# of the observed label a unique index (e.g, 'spk01': 0, 'spk02': 1, ..)
label_encoder = sb.dataio.encoder.CategoricalEncoder()
# Define audio pipeline
@sb.utils.data_pipeline.takes("wav")
@sb.utils.data_pipeline.provides("sig")
def audio_pipeline(wav):
"""Load the signal, and pass it and its length to the corruption class.
This is done on the CPU in the `collate_fn`."""
sig = sb.dataio.dataio.read_audio(wav)
return sig
# Define label pipeline:
@sb.utils.data_pipeline.takes("spk_id")
@sb.utils.data_pipeline.provides("spk_id", "spk_id_encoded")
def label_pipeline(spk_id):
yield spk_id
spk_id_encoded = label_encoder.encode_label_torch(spk_id)
yield spk_id_encoded
# Define datasets. We also connect the dataset with the data processing
# functions defined above.
datasets = {}
hparams["dataloader_options"]["shuffle"] = False
for dataset in ["train", "valid", "test"]:
datasets[dataset] = sb.dataio.dataset.DynamicItemDataset.from_json(
json_path=hparams[f"{dataset}_annotation"],
replacements={"data_root": hparams["data_folder"]},
dynamic_items=[audio_pipeline, label_pipeline],
output_keys=["id", "sig", "spk_id_encoded"],
)
# Load or compute the label encoder (with multi-GPU DDP support)
# Please, take a look into the lab_enc_file to see the label to index
# mappinng.
lab_enc_file = os.path.join(hparams["save_folder"], "label_encoder.txt")
label_encoder.load_or_create(
path=lab_enc_file,
from_didatasets=[datasets["train"]],
output_key="spk_id",
)
return datasets第一部分只是CategoricalEncoder将用于将分类标签转换为其相应索引的声明。
然后您可以注意到我们公开了音频和标签处理功能。
在audio_pipeline需要将音频信号(路径wav),并读取它。它返回一个包含阅读语音句子的张量。此函数的输入条目(即wav)必须与数据清单文件中的相应键具有相同的名称:
{
"163-122947-0045": {
"wav": "{data_root}/LibriSpeech/train-clean-5/163/122947/163-122947-0045.flac",
"length": 14.335,
"spk_id": "163"
},
}类似地,我们定义了另一个label_pipeline用于处理话语级别标签的函数,并将它们置于定义的模型可用的格式中。该函数读取spk_id JSON 文件中定义的字符串,并使用分类编码器对其进行编码。
然后我们创建DynamicItemDataset并将其与上面定义的处理函数连接起来。我们定义要公开的所需输出键。这些键将在批处理变量中的大脑类中可用,如下所示:
- batch.id
- 批处理文件
- batch.spk_id_encoded
该函数的最后一部分专用于标签编码器的初始化。标签编码器接收训练数据集的输入,并为所有建立的spk_id条目分配不同的索引。这些索引将对应于分类器的输出索引。
定义完数据集后,main函数就可以进行大脑类的初始化和使用了:
# Initialize the Brain object to prepare for mask training.
spk_id_brain = SpkIdBrain(
modules=hparams["modules"],
opt_class=hparams["opt_class"],
hparams=hparams,
run_opts=run_opts,
checkpointer=hparams["checkpointer"],
)
# The `fit()` method iterates the training loop, calling the methods
# necessary to update the parameters of the model. Since all objects
# with changing state are managed by the Checkpointer, training can be
# stopped at any point, and will be resumed on next call.
spk_id_brain.fit(
epoch_counter=spk_id_brain.hparams.epoch_counter,
train_set=datasets["train"],
valid_set=datasets["valid"],
train_loader_kwargs=hparams["dataloader_options"],
valid_loader_kwargs=hparams["dataloader_options"],
)
# Load the best checkpoint for evaluation
test_stats = spk_id_brain.evaluate(
test_set=datasets["test"],
min_key="error",
test_loader_kwargs=hparams["dataloader_options"],
)该fit方法执行训练,而测试则执行evaluate。训练和验证数据加载器在 fit 方法的输入中给出,而测试数据集则输入到评估方法中。
现在让我们来看看大脑类中定义的最重要的方法。
前向计算
让我们从forward函数开始,它定义了将输入音频转换为输出预测所需的所有计算。
def compute_forward(self, batch, stage):
"""Runs all the computation of that transforms the input into the
output probabilities over the N classes.
Arguments
---------
batch : PaddedBatch
This batch object contains all the relevant tensors for computation.
stage : sb.Stage
One of sb.Stage.TRAIN, sb.Stage.VALID, or sb.Stage.TEST.
Returns
-------
predictions : Tensor
Tensor that contains the posterior probabilities over the N classes.
"""
# We first move the batch to the appropriate device.
batch = batch.to(self.device)
# Compute features, embeddings, and predictions
feats, lens = self.prepare_features(batch.sig, stage)
embeddings = self.modules.embedding_model(feats, lens)
predictions = self.modules.classifier(embeddings)
return predictions在这种情况下,计算链非常简单。我们只是将批次放在正确的设备上并计算声学特征。然后我们使用输出固定大小张量的 TDNN 编码器处理特征。后者输入一个分类器,该分类器输出 N 个类别(在本例中为 28 个说话者)的后验概率。在 prepare_features 方法中添加了数据增强:
def prepare_features(self, wavs, stage):
"""Prepare the features for computation, including augmentation.
Arguments
---------
wavs : tuple
Input signals (tensor) and their relative lengths (tensor).
stage : sb.Stage
The current stage of training.
"""
wavs, lens = wavs
# Add augmentation if specified. In this version of augmentation, we
# concatenate the original and the augment batches in a single bigger
# batch. This is more memory-demanding, but helps to improve the
# performance. Change it if you run OOM.
if stage == sb.Stage.TRAIN:
if hasattr(self.modules, "env_corrupt"):
wavs_noise = self.modules.env_corrupt(wavs, lens)
wavs = torch.cat([wavs, wavs_noise], dim=0)
lens = torch.cat([lens, lens])
if hasattr(self.hparams, "augmentation"):
wavs = self.hparams.augmentation(wavs, lens)
# Feature extraction and normalization
feats = self.modules.compute_features(wavs)
feats = self.modules.mean_var_norm(feats, lens)
return feats, lens特别是,当在 yaml 文件中声明环境损坏时,我们在同一批次中连接信号的干净版本和增强版本。
这种方法使批量大小(以及所需的 GPU 内存)加倍,但它实现了非常强大的正则化器。在同一批次中同时具有信号的干净版本和噪声版本会迫使梯度指向参数空间的方向,该方向对信号失真具有鲁棒性。
计算目标
现在让我们来看看compute_objectives接受输入目标、预测和估计损失函数的方法:
def compute_objectives(self, predictions, batch, stage):
"""Computes the loss given the predicted and targeted outputs.
Arguments
---------
predictions : tensor
The output tensor from `compute_forward`.
batch : PaddedBatch
This batch object contains all the relevant tensors for computation.
stage : sb.Stage
One of sb.Stage.TRAIN, sb.Stage.VALID, or sb.Stage.TEST.
Returns
-------
loss : torch.Tensor
A one-element tensor used for backpropagating the gradient.
"""
_, lens = batch.sig
spkid, _ = batch.spk_id_encoded
# Concatenate labels (due to data augmentation)
if stage == sb.Stage.TRAIN and hasattr(self.modules, "env_corrupt"):
spkid = torch.cat([spkid, spkid], dim=0)
lens = torch.cat([lens, lens])
# Compute the cost function
loss = sb.nnet.losses.nll_loss(predictions, spkid, lens)
# Append this batch of losses to the loss metric for easy
self.loss_metric.append(
batch.id, predictions, spkid, lens, reduction="batch"
)
# Compute classification error at test time
if stage != sb.Stage.TRAIN:
self.error_metrics.append(batch.id, predictions, spkid, lens)
return loss输入中的预测是在前向方法中计算的。通过将这些预测与目标标签进行比较来评估成本函数。这是通过负对数似然 (NLL) 损失完成的。
其他方法
除了这两个重要的函数之外,我们还有一些大脑类使用的其他方法。在on_state_starts被称为在每个时代的开始,它是用来设置统计跟踪。在on_stage_end一个被称为在每个阶段结束时(例如,在每个训练时期的结束)和主要以统计管理的护理,学习率退火,和检查点。有关大脑类的更详细说明,请查看本教程。有关检查点的更多信息,请查看此处
第 3 步:推理
此时,我们可以使用经过训练的分类器对新数据进行预测。Speechbrain 提供了一些类(请看这里),例如EncoderClassifier可以使推理更容易的类。该类还可用于在编码器的输出中提取一些嵌入。
让我们首先看看我们如何使用它来加载我们最好的 xvector 模型(在 Voxceleb 上训练并存储在 HuggingFace 上)来计算一些嵌入并执行说话人分类:
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(source="speechbrain/spkrec-xvect-voxceleb")
signal, fs =torchaudio.load('/content/speechbrain/samples/audio_samples/example1.wav')
# Compute speaker embeddings
embeddings = classifier.encode_batch(signal)
# Perform classification
output_probs, score, index, text_lab = classifier.classify_batch(signal)
# Posterior log probabilities
print(output_probs)
# Score (i.e, max log posteriors)
print(score)
# Index of the predicted speaker
print(index)
# Text label of the predicted speaker
print(text_lab)
对于那些对说话人验证感兴趣的人,我们还创建了一个名为 的推理接口SpeakerRecognition:
from speechbrain.pretrained import SpeakerRecognition
verification = SpeakerRecognition.from_hparams(source="speechbrain/spkrec-ecapa-voxceleb", savedir="pretrained_models/spkrec-ecapa-voxceleb")
file1 = '/content/speechbrain/samples/audio_samples/example1.wav'
file2 = '/content/speechbrain/samples/audio_samples/example2.flac'
score, prediction = verification.verify_files(file1, file2)
print(score)
print(prediction) # True = same speaker, False=Different speakers但是,这如何与我们之前训练的自定义分类器一起工作?
此时,您可以使用一些选项。有关所有这些的完整概述,请查看本教程。
我们在这里只展示了如何使用EncoderClassifier我们刚刚训练的模型上的现有数据。
在您的模型上使用 EncoderClassifier 接口
该EncoderClassidier类需要预先训练模型,并进行推理就可以用下面的方法:
- encode_batch:将编码器应用于输入批次并返回一些编码嵌入。
- category_batch:执行完整的分类步骤并以文本格式返回分类器的输出概率、最佳分数、最佳类别的索引及其标签(参见上面的示例)。
要将此接口与之前训练的模型一起使用,我们必须创建一个推理 yaml文件,该文件与用于训练的用途略有不同。主要区别如下:
- 您只能删除训练所需的所有超参数和对象。您可以只保留与模型定义相关的部分。
- 您必须分配一个
Categorical encoder允许您将索引转换为文本标签的对象。 - 您必须使用预训练器将您的模型与其相应的文件相关联。
推理 yaml 文件如下所示:
%%writefile /content/best_model/hparams_inference.yaml
# #################################
# Basic inference parameters for speaker-id. We have first a network that
# computes some embeddings. On the top of that, we employ a classifier.
#
# Author:
# * Mirco Ravanelli 2021
# #################################
# pretrain folders:
pretrained_path: /content/best_model/
# Model parameters
n_mels: 23
sample_rate: 16000
n_classes: 28 # In this case, we have 28 speakers
emb_dim: 512 # dimensionality of the embeddings
# Feature extraction
compute_features: !new:speechbrain.lobes.features.Fbank
n_mels: !ref <n_mels>
# Mean and std normalization of the input features
mean_var_norm: !new:speechbrain.processing.features.InputNormalization
norm_type: sentence
std_norm: False
# To design a custom model, either just edit the simple CustomModel
# class that's listed here, or replace this `!new` call with a line
# pointing to a different file you've defined.
embedding_model: !new:custom_model.Xvector
in_channels: !ref <n_mels>
activation: !name:torch.nn.LeakyReLU
tdnn_blocks: 5
tdnn_channels: [512, 512, 512, 512, 1500]
tdnn_kernel_sizes: [5, 3, 3, 1, 1]
tdnn_dilations: [1, 2, 3, 1, 1]
lin_neurons: !ref <emb_dim>
classifier: !new:custom_model.Classifier
input_shape: [null, null, !ref <emb_dim>]
activation: !name:torch.nn.LeakyReLU
lin_blocks: 1
lin_neurons: !ref <emb_dim>
out_neurons: !ref <n_classes>
label_encoder: !new:speechbrain.dataio.encoder.CategoricalEncoder
# Objects in "modules" dict will have their parameters moved to the correct
# device, as well as having train()/eval() called on them by the Brain class.
modules:
compute_features: !ref <compute_features>
embedding_model: !ref <embedding_model>
classifier: !ref <classifier>
mean_var_norm: !ref <mean_var_norm>
pretrainer: !new:speechbrain.utils.parameter_transfer.Pretrainer
loadables:
embedding_model: !ref <embedding_model>
classifier: !ref <classifier>
label_encoder: !ref <label_encoder>
paths:
embedding_model: !ref <pretrained_path>/embedding_model.ckpt
classifier: !ref <pretrained_path>/classifier.ckpt
label_encoder: !ref <pretrained_path>/label_encoder.txt
如您所见,我们这里只有模型定义(没有优化器、检查点等)。yaml 文件的最后一部分管理预训练,我们将模型对象与其在训练时创建的预训练文件绑定在一起。
现在让我们对EncoderClassifier类进行推理:
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(source="/content/best_model/", hparams_file='hparams_inference.yaml', savedir="/content/best_model/")
# Perform classification
audio_file = 'data/LibriSpeech/train-clean-5/5789/70653/5789-70653-0036.flac'
signal, fs = torchaudio.load(audio_file) # test_speaker: 5789
output_probs, score, index, text_lab = classifier.classify_batch(signal)
print('Target: 5789, Predicted: ' + text_lab[0])
# Another speaker
audio_file = 'data/LibriSpeech/train-clean-5/460/172359/460-172359-0012.flac'
signal, fs =torchaudio.load(audio_file) # test_speaker: 460
output_probs, score, index, text_lab = classifier.classify_batch(signal)
print('Target: 460, Predicted: ' + text_lab[0])
# And if you want to extract embeddings...
embeddings = classifier.encode_batch(signal)
该EncoderClassifier接口假定您的模型具有在 yaml 文件中指定的以下模块:
- compute_features:管理从原始音频信号中提取的特征
- mean_var_norm:执行特征归一化
- embedding_model:将特征转换为固定大小的嵌入。
- 分类器:对嵌入顶部的 N 个类执行最终分类。
如果您的模型无法以这种方式构建,您可以随时自定义EncoderClassifier界面以满足您的需求。 请查看本教程以获取更多信息。
扩展到不同的任务
在一般情况下,您可能有自己的数据和分类任务,并且希望使用自己的模型。让我们对如何自定义您的食谱多加评论。
建议:从一个有效的配方开始(就像用于这个模板的那个),并且只做定制它所需的最小修改。逐步测试您的模型。确保您的模型可以在由几个句子组成的小数据集上过度拟合。如果它没有过拟合,则您的模型中可能存在错误。
用你的数据训练你的任务
如果我必须在我的数据上解决另一个话语级别的分类任务,例如language-id、情感识别、声音分类、关键字识别,该怎么办?
您所要做的就是:
- 使用任务所需的注释更改 JSON。
- 更改数据管道
train.py以符合新注释。
更改 JSON
本教程需要这样的 JSON 文件:
{
"163-122947-0045": {
"wav": "{data_root}/LibriSpeech/train-clean-5/163/122947/163-122947-0045.flac",
"length": 14.335,
"spk_id": "163"
},
"7312-92432-0025": {
"wav": "{data_root}/LibriSpeech/train-clean-5/7312/92432/7312-92432-0025.flac",
"length": 12.01,
"spk_id": "7312"
},
"7859-102519-0036": {
"wav": "{data_root}/LibriSpeech/train-clean-5/7859/102519/7859-102519-0036.flac",
"length": 11.965,
"spk_id": "7859"
},
}但是,您可以在此处添加所需的所有条目。例如,如果您想解决一个语言 ID 任务,JSON 文件应如下所示:
{
"sentence001": {
"wav": "{data_root}/your_path/your_file1.wav",
"length": 10.335,
"lang_id": "Italian"
},
{
"sentence002": {
"wav": "{data_root}/your_path/your_file2.wav",
"length": 12.335,
"lang_id": "French"
},
}如果你想解决一个情绪识别任务,它看起来像这样:
{
"sentence001": {
"wav": "{data_root}/your_path/your_file1.wav",
"length": 10.335,
"emotion": "Happy"
},
{
"sentence002": {
"wav": "{data_root}/your_path/your_file2.wav",
"length": 12.335,
"emotion": "Sad"
},
} 要创建数据清单文件,您必须解析数据集并为每个句子创建具有唯一 ID、音频信号路径 (wav)、语音句子长度(以秒为单位)和注释的JSON 文件你要的那个。
更改 train.py
唯一要记住的是 JSON 文件中的名称条目必须与数据加载器在train.py. 例如,如果你在 JSON 中定义了一个情绪键,你应该在 dataio 管道中拥有这样的train.py东西:
# Define label pipeline:
@sb.utils.data_pipeline.takes("emotion")
@sb.utils.data_pipeline.provides("emotion", "emotion_encoded")
def label_pipeline(emotion):
yield emotion
emotion_encoded = label_encoder.encode_label_torch(emotion)
yield emotion_encoded基本上,您必须spk_id用emotion代码中任何地方的条目替换条目。就这样!
用你自己的模型训练
在某些时候,您可能拥有自己的模型,并且希望将其插入语音识别管道中。例如,您可能想用不同的东西替换我们的 xvector 编码器。
为此,您必须创建自己的类并在其中指定神经网络的计算列表。您可以查看Speechbrain.lobes.models 中已经存在的模型。如果您的模型是一个简单的计算管道,您可以使用顺序容器。如果模型是一个更复杂的计算链,您可以将其创建为 的实例torch.nn.Module并在那里定义__init__和forward方法,如here。
一旦你定义了你的模型,你只需要在 yaml 文件中声明它并在 train.py
重要提示:
插入新模型时,您必须再次调整系统最重要的超参数(例如,学习率、批量大小和架构参数)以使其正常运行。
ECAPA-TDNN模型
我们发现对说话人识别特别有效的一种模型是此处实现的 ECAPA-TDNN 。
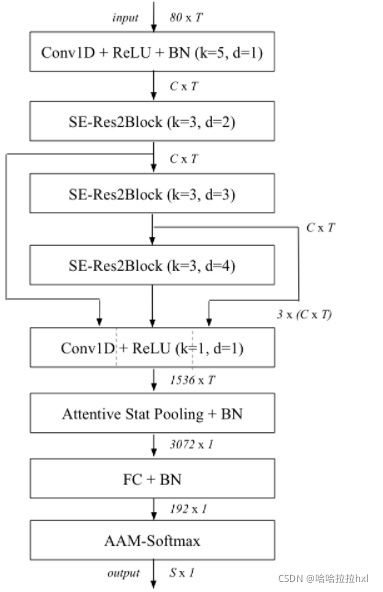
如图所示,ECAPA-TDNN 架构基于流行的 x 向量拓扑结构,它引入了多项增强功能以创建更强大的扬声器嵌入。
池化层使用依赖于通道和上下文的注意力机制,它允许网络关注每个通道的不同帧。一维SqueezeExcitation (SE) 块重新调整中间帧级特征图的通道,以在局部操作的卷积块中插入全局上下文信息。接下来,一维Res2 块的集成提高了性能,同时通过以分层方式使用分组卷积来减少总参数数。
最后,多层特征聚合 (MFA)通过将最终帧级特征图与前几层的中间特征图连接起来,在统计池化之前合并补充信息。
通过优化训练语料库中说话人身份的AAMsoftmax损失来训练网络。与细粒度分类和验证问题中的常规 softmax 损失相比,AAM-softmax 是一个强大的增强。它直接优化说话人嵌入之间的余弦距离。
事实证明,该模型在说话人验证和说话人分类方面效果非常好。我们发现它在其他话语级分类任务中非常有效,例如语言 ID、情感识别和关键字识别。
结论
在本教程中,我们展示了如何使用 SpeechBrain 从头开始创建话语级分类器。提议的系统包含开发最先进系统的所有基本要素(即数据增强、特征提取、编码、统计池、分类器等)
我们仅使用一个小数据集描述了所有步骤。在实际情况下,您必须使用更多数据进行训练(例如参见我们的Voxceleb 食谱)。














 2438
2438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









