







是什么
Fork/Join框架是Java7开始提供的一个用于并行执行任务的框架。它主要的思想是把一个大任务分割成很多个小任务,最终汇总每个小任务得到的结果。特别适合使用于分治后递归的场景。
主要思想
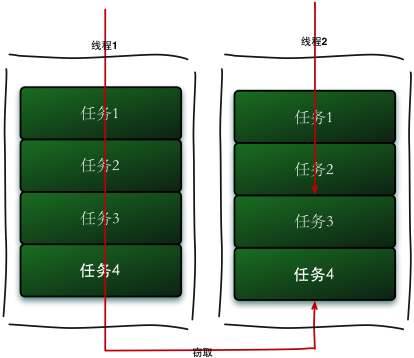
Fork/Join框架主要使用了工作窃取算法。它是指某个线程在执行完自己应该执行的任务后,为了不使分配的线程资源浪费,该线程可以去其他线程的任务队列中窃取一个任务来进行执行。由于要减少两个线程之间的竞争,窃取任务的线程要从队列尾端窃取任务,而被窃取任务的线程始终从队列头拿任务。
工作原理
Fork/Join 其实就是指由ForkJoinPool作为线程池、ForkJoinTask(通常实现其三个抽象子类)为任务、ForkJoinWorkerThread作为执行任务的具体线程实体这三者构成的任务调度机制。
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
- 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
- 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
举个栗子
public class ForkJoinDemo {
public static void main(String[] args) {
//创建分治任务线程池
ForkJoinPool fjp = new ForkJoinPool(4);
//创建分治任务
Fibonacci fib = new Fibonacci(4);
//启动分治任务
Integer result = fjp.invoke(fib);
//输出结果
System.out.println(result);
}
static class Fibonacci extends RecursiveTask<Integer>{
final int n;
public Fibonacci(int n){
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1){
return n;
}
Fibonacci f1 = new Fibonacci(n-1);
//创建⼦任务
f1.fork();
Fibonacci f2 = new Fibonacci(n-2);
//等待子任务结果,并合并结果.
return f2.compute() + f1.join();
}
}
}
一点题外话
最早看到这个知识点的时候是在看面经的时候看到了这样一道题目:一百万数据的List,只有男女两种字符串,用多线程分割成男女两个list。帖子主人说他回答的时候说用Fork/Join,就去了解了一下,因此有了这篇小笔记。
对于这个场景可以采用Fork/Join框架,分割任务时可以考虑采用二分的方式,根据cpu核数设计每个线程计算的数据量。
之前和朋友讨论这道题的时候,他问我这个场景下使用多线程会比单线程快吗?我本人对并发这方面的理解还不够深,记录一下从知乎上看到的解答:假设你拥有一台4核的机器,拿来跑一个运算4万次,每次都独立,不考虑IO,在单线程的情况下,你只用到一个核,耗时40分钟,cpu利用率25%。如果你开4个线程,每个算1万次,cpu利用率变为100%,耗时10分钟。















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









