






目录
##主要为了在学习过程中整理自己的思路,若有不对请指出,感激不尽!
机器学习中的数据处理
在处理数据时我们要注意如下几个方面:输入数据的类型,变量之间的关系,数据中存在的潜在问题(potential issues),如何对问题数据进行补救,对数据的预处理,对数据进行分类。
-
输入数据的类型
- 定性数据:无法测量出实际数据的,例如判断一个人的性别,身体情况是差,良好或者优。这种数据也叫做分类数据(categorical data)。
- 定量数据:用数字进行描述的(numerical data)。一种叫做区间数据(interval data),只能进行加减操作的,例如温度,我们可以说40度是20度+20度,但是不能说20度是20度的两倍热。另一种叫做比例数据(ratio data),可以进行任何操作,例如身高,体重,工资等。
-
定量数据的分布
-
了解数据分布情况:
集中趋势:例如均值,中位数,众数。
分散程度:例如方差,标准差(方差开根号) -
数据值位置的定义:将数据值从小到大排序
最小值minimum:minimum=Q1-1.5IQR
Q1:25%处的数值
中位数median:50%处的数值
Q3:75%处的数值
最大值maximum:minimum=Q3+1.5IQR
这些数值能看出每一段数据的变化,看他们的分散程度是大还是小。对于每一个数据集来说都有自己的这些值来判定数据。
-
数据可视化
-
箱状图box plot
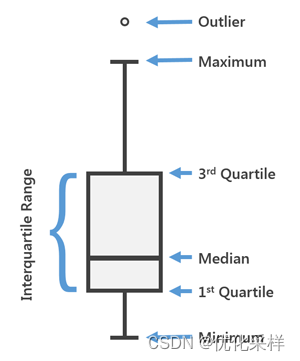
显示以上五个数值以及识别异常值。适用于比较多个组的数据分布。
Outlier是指min和max之外的值,这些值需要特别关注,对他们采取措施。
seaborn.boxplot()
#会根据x的分类画出y的box plot实例操作:利用seaborn中内置的数据集tips进行
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
tips=sns.load_dataset("tips")
print(tips.head())#查看数据的前几行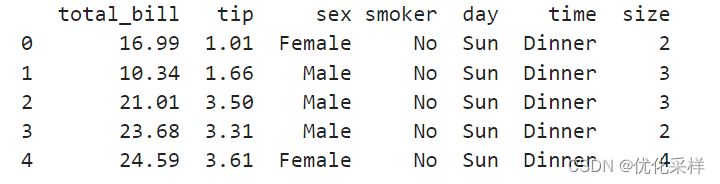
由此数据可以看出, 是用total_bill,sex,smoker,day,time,和size共同决定tip的大小。
我们先画出各个变量的box plot。
- 首先画出的是total_bill这一类自己单独的box plot
#单纯只看total_bill的box plot sns.boxplot(data=tips,y='total_bill') plt.title('box plot of total_bill') plt.ylabel('total_bill') plt.show()
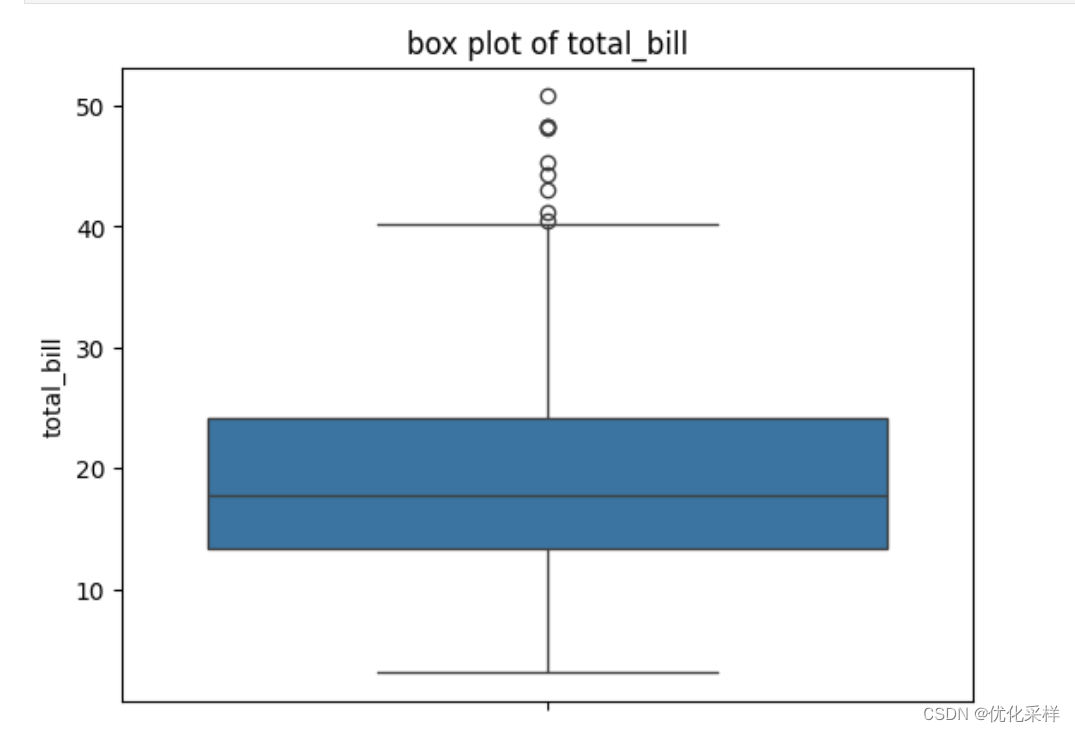
#可以找到五个值的大小,并找出outliers
Q1=tips['total_bill'].quantile(0.25)
Q3=tips['total_bill'].quantile(0.75)
IQR=Q3-Q1
minimum=Q1-1.5*IQR
maximum=Q3+1.5*IQR
outliers=tips[(tips['total_bill']<minimum) | (tips['total_bill']>maximum)]#根据布尔数组的值筛选出相应的行
#minimum:-2.8224999999999945
#maximum:40.29749999999999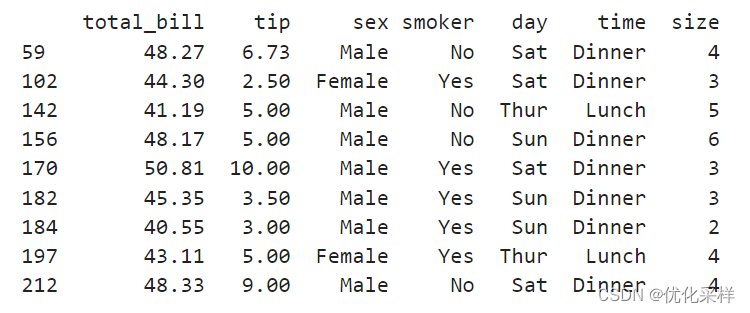
可以找出这些序号的total_bill是outliers
- 还可以根据不同的其他元素画出在该元素下的另一个元素的箱装图。下指不同天数和不同性别下,小费的不同分布情况。
fig1,axes=plt.subplots(1,2,figsize=(8,4))
sns.boxplot(data=tips,x='day',y='tip',hue='day',ax=axes[0])
axes[0].set_title('box plot of total_bill')
sns.boxplot(data=tips,x='sex',y='tip',hue='sex',ax=axes[1])
axes[1].set_title('box plot of total_bill')
plt.tight_layout()
plt.show()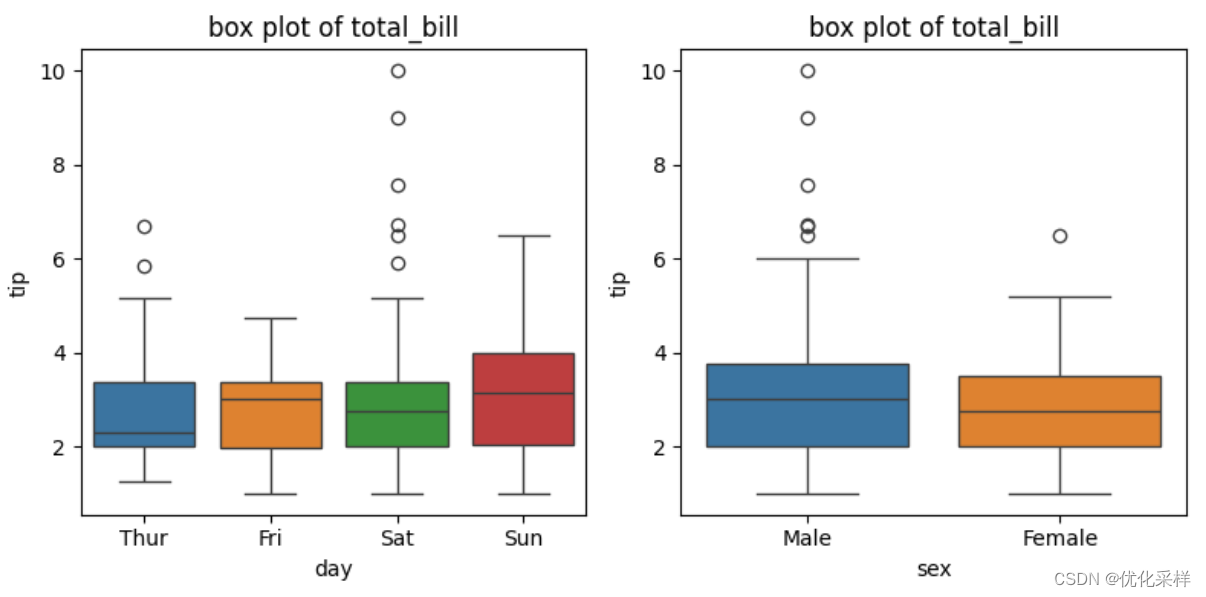
-
直方图 Histogram
直方图可以看到数据的集中趋势,分布形状,离散程度以及异常值。可以看出数据的频率分布情况。
#绘制total_bills的分布直方图
plt.figure(figsize=(4,3))
sns.histplot(data=tips,x=tips['total_bill'],kde='True')#kde是核密度估计曲线
plt.show()
总结
- 直方图:每个bar指画该范围的数据数量,数量取决于他的分布。
- 箱型图:将数据集中的数据元素分成4个数据元素数量相等的部分。
数据的质量和补救措施
数据的问题
- 数据值缺失,数据值与其他的相比相差很大
数据的补救措施
对于outliers:
- 将outliers移除:如果outliers不是很多的话,最简单的方法就是移除他们。
- 插补(Imputation):利用均值,中位数,或者众数代替。
- Capping:如果高于maximum的值,利用95%处的数。低于minimum的值,利用5%处的数。
如果有很多的outliers,我们要分别去处理他们。若是合理的值,那我们就可以不用修正。
也可以分别生成两个模型,看哪一个预测更准确
对于缺失值:
- 移除:如果缺失的比例是可以接受的,则移除该值缺失处的所有记录。
- 插补:对于有数值的数据来说,利用平均值等来代替。对于定性的数据来说,用同一属性下的其他所记录的值来补充,
- 预估:利用其它点的该属性来预估缺失值。
通过以上的方式知道了数和用工具可视化数据。在数据集中,我们需要判断特征集和标签,接下里是进行实际操作,如何在许多标签中选择出合适的标签并进行操作
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









