







准备工作
在本次实践开始之前,你必须确保你已经做了以下两件事:
- 注册百度开发者账号,并创建了一个语音识别应用,而且成功获取了Access Token(工程里将会用到);
- 建立一个基于你自己的STM32平台的RT-Thread工程,它必须具备Finsh控制台,文件系统,网络功能(不明白的参见RT-Thread文档中心,网络功能推荐使用AT组件+ESP8266,因为这是最简单快捷的方法)。
如果上面说的准备事项没有问题,那么请继续往下看:
这次我们将先跳过录音功能,而使用事先准备好的音频文件进行语音识别并控制板载RGB灯(上一篇的5,6点),所以你还需要准备一些音频文件,比如“红灯开”,“蓝灯关”。。。我是用手机录的音频,然后使用ffmpeg工具将音频转为百度语音官方认为最适合的16k采样率pcm文件,最后将这些音频文件放进sd卡中,我们的文件系统也是挂载在sd卡上的。
动手实践
本次工程会用到RT-Thread的两个软件包:webclient和CJSON软件包,你需要使用ENV工具将这两个软件包添加进工程里。
好了,开始写代码:
#include <rtthread.h>
#include <bd_speech_rcg.h>
#include <sys/socket.h> //网络功能需要的头文件
#include <webclient.h> //webclient软件包头文件
#include <dfs_posix.h> //文件系统需要的头文件
#include <cJSON.h> //CJSON软件包头文件
/* 使用外设需要的头文件 */
#include <rtdevice.h>
#include <board.h>
/* 获取RGB灯对应的引脚编号 */
#define PIN_LED_R GET_PIN(E, 7)
#define PIN_LED_G GET_PIN(E, 8)
#define PIN_LED_B GET_PIN(E, 9)
#define RES_BUFFER_SIZE 4096 //数据接收数组大小
#define HEADER_BUFFER_SIZE 2048 //最大支持的头部长度
/* URL */
#define POST_FILE_URL "http://vop.baidu.com/server_api?dev_pid=1536&cuid=lxzzzzzxl&token=25.9119f50a60602866be9288f1f14a1059.315360000.1884092937.282335-15525116"
/* 头部数据(必需) */
char *form_data = "audio/pcm;rate=16000";
/* 预定义的命令 */
char *cmd1 = "打开红灯";
char *cmd2 = "关闭红灯";
char *cmd3 = "打开蓝灯";
char *cmd4 = "关闭蓝灯";
char *cmd5 = "打开绿灯";
char *cmd6 = "关闭绿灯";
/************************************************
函数名称 : bd
功 能 : 将音频文件发送到百度语音服务器,并接收响应数据
参 数 : 音频文件名(注意在文件系统中的位置,默认根目录)
返 回 值 : void
作 者 : rtthread;霹雳大乌龙
*************************************************/
void bd(int argc, char **argv)
{
char *filename = NULL;
unsigned char *buffer = RT_NULL;
int content_length = -1, bytes_read = 0;
int content_pos = 0;
int ret = 0;
/* 判断命令是否合法 */
if(argc != 2)
{
rt_kprintf("bd <filename>\r\n");
return;
}
/* 获取音频文件名 */
filename = argv[1];
/* 以只读方式打开音频文件 */
int fd = open(filename, O_RDONLY, 0);
if(fd < 0)
{
rt_kprintf("open %d fail!\r\n", filename);
goto __exit;
}
/* 获取音频文件大小 */
size_t length = lseek(fd, 0, SEEK_END);
lseek(fd, 0, SEEK_SET);
/* 创建响应数据接收数据 */
buffer = (unsigned char *) web_malloc(RES_BUFFER_SIZE);
if(buffer == RT_NULL)
{
rt_kprintf("no memory for receive response buffer.\n");
ret = -RT_ENOMEM;
goto __exit;
}
/* 创建会话 */
struct webclient_session *session = webclient_session_create(HEADER_BUFFER_SIZE);
if(session == RT_NULL)
{
ret = -RT_ENOMEM;
goto __exit;
}
/* 拼接头部数据 */
webclient_header_fields_add(session, "Content-Length: %d\r\n", length);
webclient_header_fields_add(session, "Content-Type: %s\r\n", form_data);
/* 发送POST请求 */
int rc = webclient_post(session, POST_FILE_URL, NULL);
if(rc < 0)
{
rt_kprintf("webclient post data error!\n");
goto __exit;
}else if (rc == 0)
{
rt_kprintf("webclient connected and send header msg!\n");
}else
{
rt_kprintf("rc code: %d!\n", rc);
}
while(1)
{
rt_memset(buffer, 0, RES_BUFFER_SIZE);
length = read(fd, buffer, RES_BUFFER_SIZE);
if(length <= 0)
{
break;
}
ret = webclient_write(session, buffer, length);
if(ret < 0)
{
rt_kprintf("webclient write error!\r\n");
break;
}
rt_thread_mdelay(100);
}
close(fd);
rt_kprintf("Upload voice data successfully\r\n");
if(webclient_handle_response(session) != 200)
{
rt_kprintf("get handle resposne error!");
goto __exit;
}
/* 获取接收的响应数据长度 */
content_length = webclient_content_length_get(session);
rt_thread_delay(100);
do
{
bytes_read = webclient_read(session, buffer, 1024);
if (bytes_read <= 0)
{
break;
}
for(int index = 0; index < bytes_read; index++)
{
rt_kprintf("%c", buffer[index]);
}
content_pos += bytes_read;
}while(content_pos < content_length);
/* 解析json数据 */
bd_data_parse(buffer);
__exit:
if(fd >= 0)
close(fd);
if(session != NULL)
webclient_close(session);
if(buffer != NULL)
web_free(buffer);
return;
}
/* 导出为命令形式 */
MSH_CMD_EXPORT(bd, webclient post file);
/************************************************
函数名称 : bd_data_parse
功 能 : 解析json数据,并作出响应动作
参 数 : data ------ 百度语音服务返回的数据(json格式)
返 回 值 : void
作 者 : RT-Thread;霹雳大乌龙
*************************************************/
void bd_data_parse(uint8_t *data)
{
cJSON *root = RT_NULL, *object = RT_NULL, *item =RT_NULL;
root = cJSON_Parse((const char *)data);
if (!root)
{
rt_kprintf("No memory for cJSON root!\n");
return;
}
object = cJSON_GetObjectItem(root, "result");
item = object->child;
rt_kprintf("\nresult :%s \r\n", item->valuestring);
rt_pin_mode(PIN_LED_R, PIN_MODE_OUTPUT);
rt_pin_mode(PIN_LED_G, PIN_MODE_OUTPUT);
rt_pin_mode(PIN_LED_B, PIN_MODE_OUTPUT);
rt_pin_write(PIN_LED_R,1);
rt_pin_write(PIN_LED_G,1);
rt_pin_write(PIN_LED_B,1);
if(strstr((char*)data, cmd1) != NULL)
{
/* 打开红灯 */
rt_pin_write(PIN_LED_R,0);
}
if(strstr((char*)data, cmd2) != NULL)
{
/* 关闭红灯 */
rt_pin_write(PIN_LED_R,1);
}
if(strstr((char*)data, cmd3) != NULL)
{
/* 打开蓝灯 */
rt_pin_write(PIN_LED_B,0);
}
if(strstr((char*)data, cmd4) != NULL)
{
/* 关闭蓝灯 */
rt_pin_write(PIN_LED_B,1);
}
if(strstr((char*)data, cmd5) != NULL)
{
/* 打开绿灯 */
rt_pin_write(PIN_LED_G,0);
}
if(strstr((char*)data, cmd6) != NULL)
{
/* 关闭绿灯 */
rt_pin_write(PIN_LED_G,1);
}
if (root != RT_NULL)
cJSON_Delete(root);
}
只需以上的代码,你就可以实现百度语音识别以及控制相应外设了。下面看看实际效果:
我使用的潘多拉开发板板载了stlink(且其为我们提供了一个虚拟串口),用usb数据线将开发板和电脑连接起来,将代码烧写进开发板后,我们利用这个虚拟串口,使用Xshell一类的终端软件,就可以看到如下的开机画面:

这便是RT-Thread提供的Finsh控制台组件,使用这个组件,我们可以方便地观察程序的运行状态,以命令行的形式调试运行程序,从图中我们可以看到,我们需要的文件系统和网络功能都已经初始化成功。
使用ls命令看看:

欸~,这便是我事先准备好的音频文件。
在上面的代码中,我们可以看到有这样一句:
MSH_CMD_EXPORT(bd, webclient post file);
通过这行代码,我们就可以在Finsh控制台里使用bd这个命令,这个命令就是将音频文件发送到百度语音服务器,试试看:
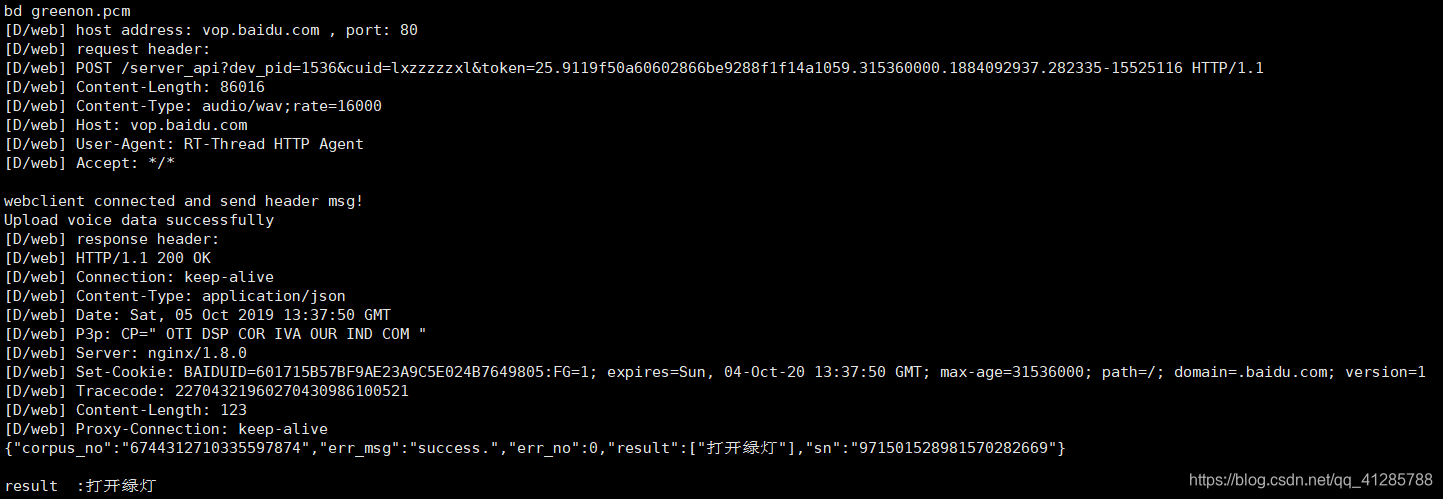
看,我使用bd命令将greenon.pcm发送到百度语音服务器,正确识别出结果:“打开绿灯”;于此同时,rgb灯也亮起了绿色

尝试其他音频文件,效果完美!!!
好了,本次分享也就到这了,觉得不错的帮忙转发点个在看哦~














 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









