









这篇博文介绍的内容包括:
- 网络爬虫中 selenium 的使用
- 异步请求后台与服务器的交互文件
- 实现在固定时间重复执行特定代码块
当然,有了这些技能可以完成什么任务呢?看完这篇博文的读者,一定会有意想不到的大收获,哈哈!!!
注:建议先看评论再看内容!!!
注:建议先看评论再看内容!!!
目录
一、工具
“工欲善其事必先利其器”,首先我们看看需要哪些“工具”把。
(一)selenium安装
selenium 是一个用于Web应用程序测试的工具。selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera 等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 . Net、Java、Perl 等不同语言的测试脚本。[1]
所以我们拿 selenium 来模拟用户的真实操作,就可以躲过网站的反爬啦!
selenium 可以直接可以用 pip 安装:
pip install selenium(二)浏览器驱动
作者使用的是谷歌浏览器,所以这里就只介绍 chromedriver 了。
1. 首先需要 Chrome 版本,在 Chrome 浏览器中输入 chrome://version/,得到下图1 :
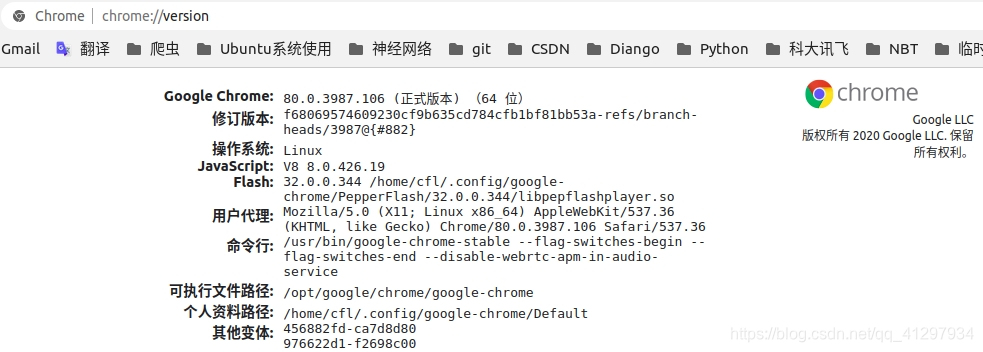
可以看到我的版本为:80.0.3987.106 (64位),操作系统为:Linux,所以下载的 chromedriver 也要相互匹配。
2. chromedriver 下载的地址是:http://chromedriver.storage.googleapis.com/index.html,找到并选择与自己版本匹配的即可,如下图2、3 :
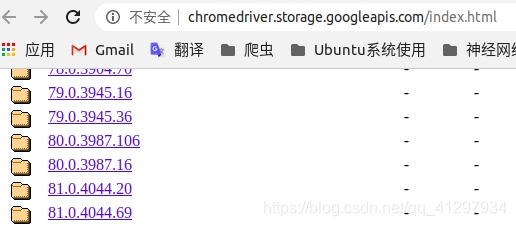
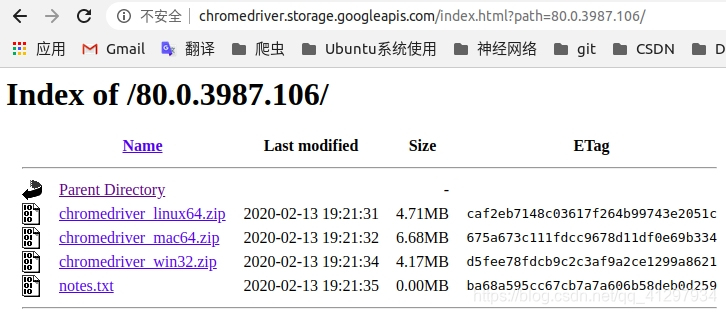
3. 把压缩包解压,解压后的 chromedriver.exe 保存到你的本地文件夹即可。
(三)其他工具
其他工具主要就是 python 的模块包啦。主要有:
from threading import Timer
import json没有的话,读者就自行 pip 把。
二、思路
我们的整体思路就是通过使用 selenium 来模拟用户点击浏览每一篇 blog 来 increase traffic,具体步骤如下:
(一)登录
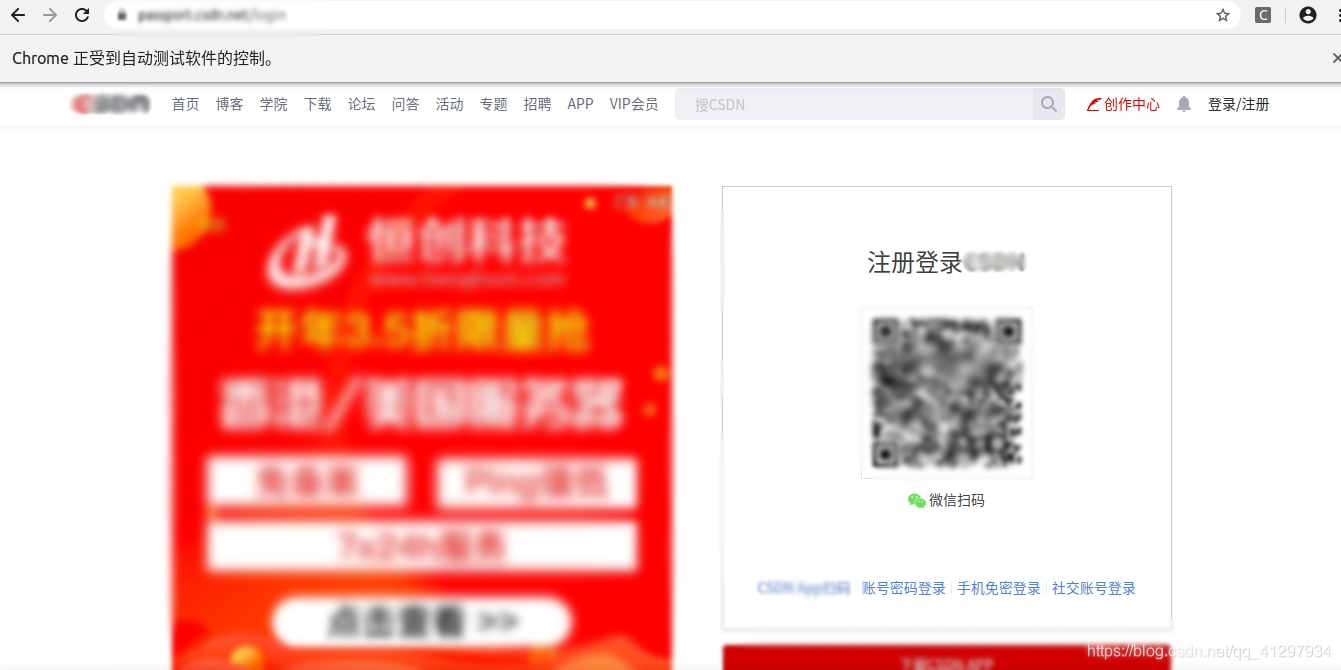
作者这里为了方便,登录过程没有写特别多的代码,方法就是: selenium 打开登录界面——>用户拿起手机微信扫码登录(哈哈,没想到吧,但是这个方法简单有效),然后其他工作就全部交给代码自己运行啦,读者就可以坐等浏览量增加(或者代码崩掉)。
相关代码如下:
# 获取chromedriver
def get_driver(executable_path, show=0):
# 创建参数设置对象
chrome_opt = Options()
# show参数决定是否显示浏览器,因为显示浏览器界面需要消耗计算机内存,所以要根据情况来定
# 0表示不显示,1表示显示
if show == 0:
# 无界面化
chrome_opt.add_argument('--headless')
# 配合上面的无界面化
chrome_opt.add_argument('--disable-gpu')
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_opt.add_experimental_option("prefs", prefs)
elif show == 1:
pass
# 设置窗口大小, 窗口大小会有影响
chrome_opt.add_argument('--window-size=1366,768')
# 使用沙盒模式运行
chrome_opt.add_argument("--no-sandbox")
# 创建Chrome对象并传入设置信息
driver = webdriver.Chrome(executable_path=executable_path, chrome_options=chrome_opt)
return driver
# chromedriver的可执行路径
executable_path = '/usr/local/bin/chromedriver/chromedriver'
# 登录url
url = 'https://passport.csdn.net/login'
# 获得driver
# 显示界面
driver = get_driver(executable_path, 1)
# 请求登录界面
driver.get(url)
# 这里等待15s是为了用户完成扫码登录过程
sleep(15)读者要提前准备好手机微信,如果手速慢的可以把时间调大一点。
注:首次登录需要手机号验证,所以建议首次运行代码将时间调大很多。
效果如下图4 :
(二)获取博客文章id
我们可以看看本篇博客的 url ,大概格式就是 https://blog.xxxx.net/qq_用户id/article/details/文章id ,所以为了遍历所有文章,那就得先获取所有用户 id(用户 id 其实就是你的 id 啦,但是我不清楚转载的文章指向是否也是自己的 id ,所以这里统一记录下来了)和文章 id 。
这里需要注意一点的是,作者在获得博客文章 id 时,找到了一个捷径,就是通过请求如下连接:https://blog-console-api.csdn.net/v1/article/list?page=1&pageSize=20,可以获得一个 json 文件,里面记录了博客文章的所有信息(如果读者想知道作者是如何找到的,可以看我的另一篇博客:https://blog.xxxx.net/qq_41297934/article/details/104463851,这篇文章会给你思路哦)。
所以我们只需要请求该 api 接口,就可以获取用户 id 和文章 id 了,代码如下:
# 请求博客列表
# page=1表示第一页的博客
driver.get('https://blog-console-api.csdn.net/v1/article/list?page=1&pageSize=20')
sleep(10)
html = driver.page_source
# 通过正则表达式来匹配json内容
html_str = re.findall(r'>(\{.+?})<', html.replace('\n', '').replace(' ', ''))[0]
# 获取博客id列表和用户名列表
article_id_list = []
username_list = []
html_dict = json.loads(html_str)
for j in html_dict['data']['list']:
article_id_list.append(j['ArticleId'])
username_list.append(j['UserName'])请求到的 json 文件会在浏览器中显示一次的,效果如下图5 :
(三)一个小小的打断
按理说我们就可以用 selenium 模拟用户来访问文章啦,但是作者亲身经历发现,即使代码没有问题的情况下,每次打开网页的时间实在太长,所以决定写一个在规定时间内强制执行程序的代码,这样只要网页被打开,不等其加载完成就将其关闭。
这里参考了别人的代码[2],该文作者的解释如下:
今天小编就为大家分享一篇Python 实现某个功能每隔一段时间被执行一次的功能方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧。
某个函数需要在每个小时的 3 分钟时候被执行一次,我希望我 15:45 启动程序,过了18 分钟在 16:03 这个函数被执行一次,下一次过 60 分钟在 17:03 再次被执行,下一次 18:03,以此类推。
以下是我基于 Timer 做的再封装实现了此功能。
代码如下:
# -*- coding: utf-8 -*-
# ==================================================
# 对 Timer 做以下再封装的目的是:当某个功能需要每隔一段时间被
# 执行一次的时候,不需要在回调函数里对 Timer 做重新安装启动
# ==================================================
__author__ = 'liujiaxing'
from threading import Timer
from datetime import datetime
class MyTimer(object):
def __init__(self, start_time, interval, callback_proc, args=None, kwargs=None):
self.__timer = None
self.__start_time = start_time
self.__interval = interval
self.__callback_pro = callback_proc
self.__args = args if args is not None else []
self.__kwargs = kwargs if kwargs is not None else {}
def exec_callback(self, args=None, kwargs=None):
self.__callback_pro(*self.__args, **self.__kwargs)
self.__timer = Timer(self.__interval, self.exec_callback)
self.__timer.start()
def start(self):
interval = self.__interval - (datetime.now().timestamp() - self.__start_time.timestamp())
print(interval)
self.__timer = Timer(interval, self.exec_callback)
self.__timer.start()
def cancel(self):
self.__timer.cancel()
self.__timer = None
class AA:
@staticmethod
def hello(name, age):
print("[%s]\thello %s: %d\n" % (datetime.now().strftime("%Y%m%d %H:%M:%S"), name, age))
if __name__ == "__main__":
aa = AA()
start = datetime.now().replace(minute=3, second=0, microsecond=0)
tmr = MyTimer(start, 60 * 60, aa.hello, ["owenliu", 18])
tmr.start()
tmr.cancel()我们需要注意的代码块为:
tmr = MyTimer( start, 60*60, aa.hello, [ "owenliu", 18 ] )def hello(name, age):
print("[%s]\thello %s: %d\n" % (datetime.now().strftime("%Y%m%d %H:%M:%S"), name, age))hello(name, age) 为回调函数,tmr = MyTimer(start, 60 * 60, aa.hello, ["owenliu", 18]) 中,传递了 4 个参数,start 为当前时间,60*60 为代码循环周期(这里为 1h ),aa.hello 为回调函数,["owenliu", 18] 为回调函数的参数。读者可以将时间改为 10 ,感受一下该代码的奇妙之处。
(四)随机访问文章
使用上面的代码,修改回调函数,就可以实现我们的功能了。
这部分代码容易理解,就直接给出代码了:
- 回调函数:circle(executable_path, username_list, article_id_list)
def circle(executable_path, username_list, article_id_list):
# 时间
print("[%s]" % (datetime.now().strftime("%Y%m%d %H:%M:%S")))
# 开始时间
start = time.time()
# 获得driver
# 不显示界面
driver = get_driver(executable_path, 0)
# 随机访问
num = randint(0, len(username_list)-1)
# sleep(randint(3, 8))
article_url = 'https://blog.csdn.net/' \
+ username_list[num] \
+ '/article/details/' \
+ article_id_list[num]
print('访问网页:%s' % article_url)
driver.get(article_url)
# 结束时间
end = time.time()
# 耗时
print('访问时间:%s' % (end-start))
print('*****' * 20)
# 关闭驱动
driver.close()- 循环代码
# 每隔10s执行一次代码
my_start = datetime.now().replace(minute=3, second=0, microsecond=0)
my_timer = MyTimer(my_start, 10, circle, [my_executable_path, my_username_list, my_article_id_list])
my_timer.start()
my_timer.cancel()三、全部代码
(一)代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import re
from random import randint
from time import sleep
import json
import time
from threading import Timer
from datetime import datetime
class MyTimer(object):
def __init__(self, start_time, interval, callback_proc, args=None, kwargs=None):
self.__timer = None
self.__start_time = start_time
self.__interval = interval
self.__callback_pro = callback_proc
self.__args = args if args is not None else []
self.__kwargs = kwargs if kwargs is not None else {}
def exec_callback(self):
self.__callback_pro(*self.__args, **self.__kwargs)
self.__timer = Timer(self.__interval, self.exec_callback)
self.__timer.start()
def start(self):
interval = self.__interval - (datetime.now().timestamp() - self.__start_time.timestamp())
self.__timer = Timer(interval, self.exec_callback)
self.__timer.start()
def cancel(self):
self.__timer.cancel()
self.__timer = None
# 获取chromedriver
def get_driver(executable_path, show=0):
# 创建参数设置对象
chrome_opt = Options()
# show参数决定是否显示浏览器,因为显示浏览器界面需要消耗计算机内存,所以要根据情况来定
# 0表示不显示,1表示显示
if show == 0:
# 无界面化
chrome_opt.add_argument('--headless')
# 配合上面的无界面化
chrome_opt.add_argument('--disable-gpu')
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_opt.add_experimental_option("prefs", prefs)
elif show == 1:
pass
# 设置窗口大小, 窗口大小会有影响
chrome_opt.add_argument('--window-size=1366,768')
# 使用沙盒模式运行
chrome_opt.add_argument("--no-sandbox")
# 创建Chrome对象并传入设置信息
driver = webdriver.Chrome(executable_path=executable_path, chrome_options=chrome_opt)
return driver
def get_username_article(executable_path, url):
# 获得driver
# 显示界面
driver = get_driver(executable_path, 1)
# 请求登录界面
driver.get(url)
# 这里等待15s是为了用户完成扫码登录过程
sleep(15)
# 请求博客列表
# page=1表示第一页的博客
driver.get('https://blog-console-api.csdn.net/v1/article/list?page=1&pageSize=20')
sleep(10)
html = driver.page_source
# 通过正则表达式来匹配json内容
html_str = re.findall(r'>(\{.+?})<', html.replace('\n', '').replace(' ', ''))[0]
# 获取博客id列表和用户名列表
article_id_list = []
username_list = []
html_dict = json.loads(html_str)
for j in html_dict['data']['list']:
article_id_list.append(j['ArticleId'])
username_list.append(j['UserName'])
# 关闭驱动
driver.close()
return username_list, article_id_list
def circle(executable_path, username_list, article_id_list):
# 时间
print("[%s]" % (datetime.now().strftime("%Y%m%d %H:%M:%S")))
# 开始时间
start = time.time()
# 获得driver
# 不显示界面
driver = get_driver(executable_path, 0)
# 随机访问
num = randint(0, len(username_list)-1)
# sleep(randint(3, 8))
article_url = 'https://blog.csdn.net/' \
+ username_list[num] \
+ '/article/details/' \
+ article_id_list[num]
print('访问网页:%s' % article_url)
driver.get(article_url)
# 结束时间
end = time.time()
# 耗时
print('访问时间:%s' % (end-start))
print('*****' * 20)
# 关闭驱动
driver.close()
if __name__ == '__main__':
# chrome驱动的可执行路径
my_executable_path = '/usr/local/bin/chromedriver/chromedriver'
# 登录url
my_url = 'https://passport.csdn.net/login'
# 获取用户名列表、文章id列表
my_username_list, my_article_id_list = get_username_article(my_executable_path, my_url)
# 每隔10s执行一次代码
my_start = datetime.now().replace(minute=3, second=0, microsecond=0)
my_timer = MyTimer(my_start, 10, circle, [my_executable_path, my_username_list, my_article_id_list])
my_timer.start()
my_timer.cancel()
(二)输出
这里给出几次访问文章的输出结果,速度还是挺快的。
[20200406 18:18:32]
访问网页:https://blog.csdn.net/qq_41297934/article/details/105104684
访问时间:8.050034999847412
****************************************************************************************************
[20200406 18:18:50]
访问网页:https://blog.csdn.net/qq_41297934/article/details/105302006
访问时间:3.8321597576141357
****************************************************************************************************
[20200406 18:19:04]
访问网页:https://blog.csdn.net/qq_41297934/article/details/104551659
访问时间:3.9448931217193604














 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









