







任务描述
本次实践使用Python来爬取百度百科中《乘风破浪的姐姐》所有选手的信息,并进行可视化分析。
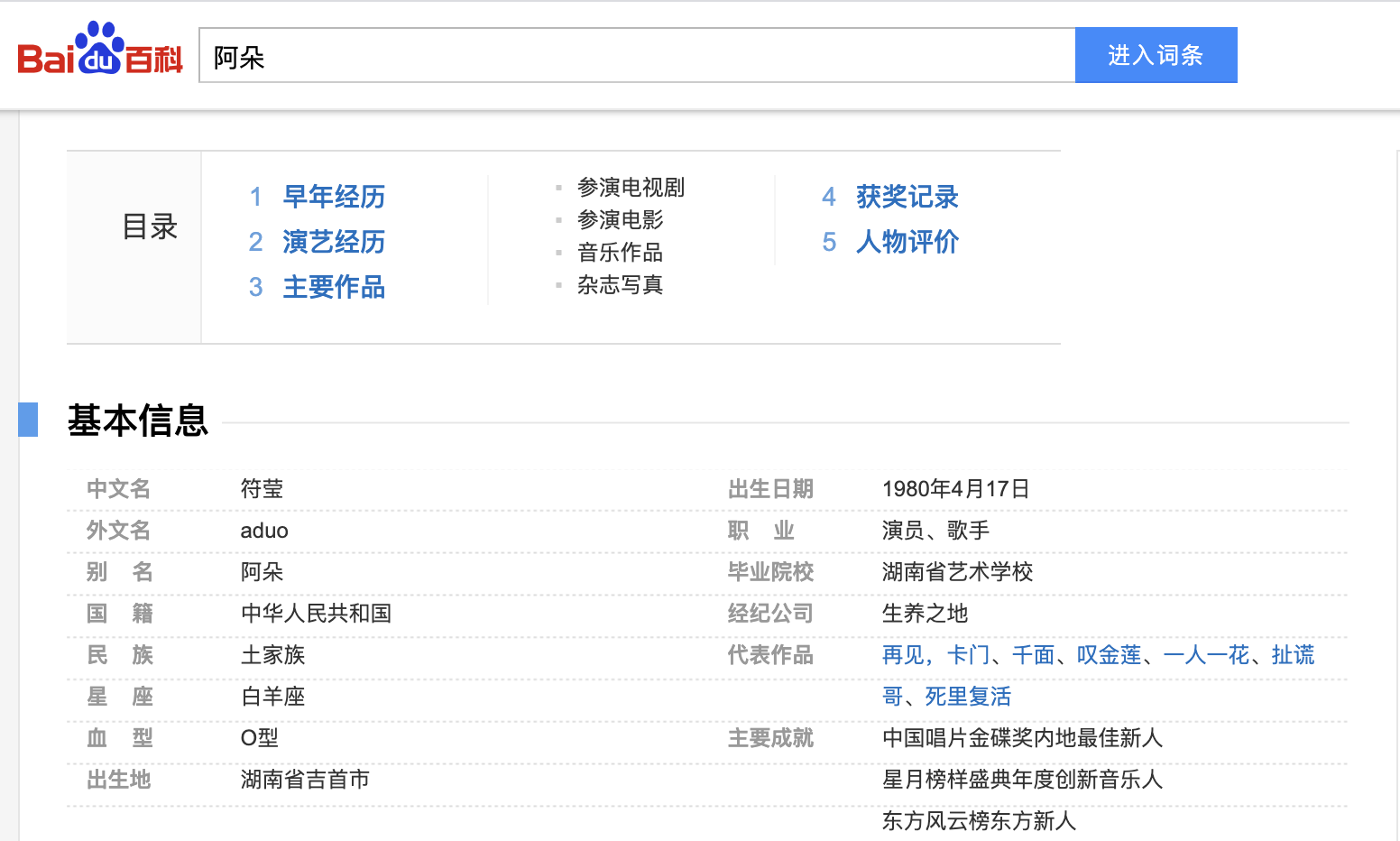
数据获取:https://baike.baidu.com/item/乘风破浪的姐姐

上网的全过程:
普通用户:
打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上。
爬虫程序:
模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
爬虫的过程:
1.发送请求(requests模块)
2.获取响应数据(服务器返回)
3.解析并提取数据(BeautifulSoup查找或者re正则)
4.保存数据
本实践中将会使用以下两个模块,首先对这两个模块简单了解以下:
request模块:
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
requests.get(url)可以发送一个http get请求,返回服务器响应内容。
<br/>
BeautifulSoup库:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
BeautifulSoup(markup, "html.parser")或者BeautifulSoup(markup, "lxml"),推荐使用lxml作为解析器,因为效率更高。
## 数据爬取
一、爬取百度百科中《乘风破浪的姐姐》中所有参赛嘉宾信息,返回页面数据
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
import sys
sys.path.append('/home/aistudio/external-libraries')
def crawl_wiki_data():
"""
爬取百度百科中《乘风破浪的姐姐》中嘉宾信息,返回html
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://baike.baidu.com/item/乘风破浪的姐姐'
try:
response = requests.get(url,headers=headers)
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串
soup = BeautifulSoup(response.text,'lxml')
#返回所有的<table>所有标签
tables = soup.find_all('table')
crawl_table_title = "按姓氏首字母排序"
for table in tables:
#对当前节点前面的标签和字符串进行查找
table_titles = table.find_previous('div')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
二、对爬取的参赛嘉宾页面数据进行解析,并保存为JSON文件
def parse_wiki_data(table_html):
'''
解析得到选手信息,包括包括选手姓名和选手个人百度百科页面链接,存JSON文件,保存到work目录下
'''
bs = BeautifulSoup(str(table_html),'lxml')
all_trs = bs.find_all('tr')
stars = []
for tr in all_trs:
all_tds = tr.find_all('td') #tr下面所有的td
for td in all_tds:
#star存储选手信息,包括选手姓名和选手个人百度百科页面链接
star = {}
if td.find('a'):
#找选手名称和选手百度百科连接
if td.find_next('a'):
star["name"]=td.find_next('a').text
star['link'] = 'https://baike.baidu.com' + td.find_next('a').get('href')
elif td.find_next('div'):
star["name"]=td.find_next('div').find('a').text
star['link'] = 'https://baike.baidu.com' + td.find_next('div').find('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/' + 'stars.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
三、爬取每个选手的百度百科页面的信息,并进行保存
def crawl_everyone_wiki_urls():
'''
爬取每个选手的百度百科图片,并保存
'''
with open('work/' + 'stars.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
#向选手个人百度百科发送一个http get请求
response = requests.get(link,headers=headers)
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象
bs = BeautifulSoup(response.text,'lxml')
#获取选手的民族、星座、血型、体重等信息
base_info_div = bs.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '民族':
star_info['nation'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '星座':
star_info['constellation'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '血型':
star_info['blood_type'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '身高':
height_str = str(dt.find_next('dd').text)
star_info['height'] = str(height_str[0:height_str.rfind('cm')]).replace("\n","")
if "".join(str(dt.text).split()) == '体重':
star_info['weight'] = str(dt.find_next('dd').text).replace("\n","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
#从个人百度百科页面中解析得到一个链接,该链接指向选手图片列表页面
if bs.select('.summary-pic a'):
pic_list_url = bs.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
#向选手图片列表页面发送http get请求
pic_list_response = requests.get(pic_list_url,headers=headers)
#对选手图片列表页面进行解析,获取所有图片链接
bs = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html=bs.select('.pic-list img ')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
#根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中
down_save_pic(name,pic_urls)
#将个人信息存储到json文件中
json_data = json.loads(str(star_infos).replace("\'","\""))
with open('work/' + 'stars_info.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
def down_save_pic(name,pic_urls):
'''
根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
'''
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
#print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
#print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
四、数据爬取主程序
import sys
sys.path.append('/home/aistudio/external-libraries')
if __name__ == '__main__':
#爬取百度百科中《乘风破浪的姐姐》中参赛选手信息,返回html
html = crawl_wiki_data()
#解析html,得到选手信息,保存为json文件
parse_wiki_data(html)
#从每个选手的百度百科页面上爬取,并保存
crawl_everyone_wiki_urls()
print("所有信息爬取完成!")
数据分析
一、绘制选手年龄分布柱状图
import numpy as np
import json
import matplotlib.font_manager as font_manager
import pandas as pd
df = pd.read_json('work/stars_info.json',dtype = {'birth_day' : str})
#print(df)
df = df[df['birth_day'].map(len) == 4]
#print(df)
grouped=df['name'].groupby(df['birth_day'])
#print(grouped)
s = grouped.count()
birth_days_list = s.index
count_list = s.values
plt.figure(figsize=(15,8))
plt.bar(range(len(count_list)), count_list,color='r',tick_label=birth_days_list,
facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('age of girls',fontsize = 24)
plt.savefig('/home/aistudio/work/bar_result01.jpg')
plt.show()
结果:

二、绘制选手体重饼状图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#绘制选手体重分布饼状图
weights = []
counts = []
for star in json_array:
if 'weight' in dict(star).keys():
weight = float(star['weight'][0:2])
weights.append(weight)
print(weights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for weight in weights:
if weight <=45:
size1 += 1
elif 45 < weight <= 50:
size2 += 1
elif 50 < weight <= 55:
size3 += 1
else:
size4 += 1
labels = '<=45kg', '45~50kg', '50~55kg', '>55kg'
sizes = [size1, size2, size3, size4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('/home/aistudio/work/pie_result01.jpg')
plt.show()
结果:

三、绘制选手身高饼状图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#绘制选手身高分布饼状图
heights = []
counts = []
for star in json_array:
if 'height' in dict(star).keys():
height = float(star['height'][0:3])
heights.append(height)
print(heights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for height in heights:
if height <= 162:
size1 += 1
elif 162 < height <= 166:
size2 += 1
elif 166 < height <= 170:
size3 += 1
else:
size4 += 1
labels = '<=162cm', '162~166cm', '166~170cm', '>170cm'
sizes = [size1, size2, size3, size4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('/home/aistudio/work/height_result.jpg')
plt.title('Height distribution',fontsize = 14)
plt.show()
结果:

四、绘制选手身高和体重的散点图,并对其相关关系进行分析
import numpy as np # 数组相关的库
import matplotlib.pyplot as plt # 绘图库
import json
from matplotlib.ticker import FormatStrFormatter
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
weights = []
heights = []
counts = []
#注意有些选手的身高和体重不一定同时都有
for star in json_array:
if 'weight' in dict(star).keys():
if 'height' in dict(star).keys():
weight = float(star['weight'][0:2])
weights.append(weight)
height = float(star['height'][0:3])
heights.append(height)
plt.scatter(heights, weights, alpha=0.6) # 绘制散点图,透明度为0.6(这样颜色浅一点,比较好看)
plt.title("figure of weights and heights")
plt.gca().yaxis.set_major_formatter(FormatStrFormatter('%d kg'))
plt.gca().xaxis.set_major_formatter(FormatStrFormatter('%d cm'))
plt.savefig('/home/aistudio/work/hw_result.jpg')
plt.show()
结果:

五、自由根据数据集对该数据集进行可视化分析
import numpy as np # 数组相关的库
import matplotlib.pyplot as plt # 绘图库
import json
from matplotlib.ticker import FormatStrFormatter
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.font_manager import FontProperties
myfont = FontProperties(fname=r"external-libraries/simhei.ttf",size=12)
%matplotlib inline
with open('work/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
weights = []
heights = []
ages = []
counts = []
nations = []
#注意有些选手的身高和体重不一定同时都有
for star in json_array:
if 'weight' in dict(star).keys():
if 'height' in dict(star).keys():
if 'birth_day' in dict(star).keys():
if 'nation' in dict(star).keys():
birth_day = star['birth_day']
if birth_day[0] == '1':
birth_day = float(star['birth_day'][0:4])
weight = float(star['weight'][0:2])
weights.append(weight)
height = float(star['height'][0:3])
heights.append(height)
age = 2020 - birth_day
ages.append(age)
nations.append(star['nation'][0:3])
#结果1
fig = plt.figure(1)
ax1 = plt.axes(projection='3d')
ax1.scatter3D(ages, weights, heights, cmap='Blues') #绘制散点图
#ax2.plot_surface(ages, weights, heights, cmap='rainbow') #绘制空间曲面
plt.savefig('work/visual_analysis_result.jpg')
plt.gca().yaxis.set_major_formatter(FormatStrFormatter('%d kg'))
plt.gca().zaxis.set_major_formatter(FormatStrFormatter('%d cm'))
plt.title("Visual Analysis Result")
#结果2
fig2 = plt.figure(2)
ax2 = plt.axes(projection='3d')
ax2.plot3D(ages, weights, heights, 'gray') #绘制空间曲线
plt.savefig('work/visual_analysis_result2.jpg')
plt.gca().yaxis.set_major_formatter(FormatStrFormatter('%d kg'))
plt.gca().zaxis.set_major_formatter(FormatStrFormatter('%d cm'))
plt.title("Visual Analysis Result2")
fig = plt.figure(3)
# ax3 = plt.axes(projection='3d')
# ax3.scatter3D(nations, weights, heights, cmap='Blues') #绘制散点图
plt.gca().yaxis.set_major_formatter(FormatStrFormatter('%d cm'))
# plt.gca().zaxis.set_major_formatter(FormatStrFormatter('%d cm'))
scale_ls = range(6)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']= False #用来正常显示负号
index_ls = ['汉族','土家族','回族','畲族','满族','傣族']#坐标字
plt.scatter(nations, heights, alpha=0.6)
plt.xticks(scale_ls, index_ls, fontproperties=myfont) ## 可以设置坐标字
plt.title('Visual Analysis Result3', fontproperties=myfont)
plt.savefig('work/visual_analysis_result3.jpg')
plt.show()
结果:



- 由可视化分析的结果1图示,可发现所选中的姐姐们的年龄主要集中在30~35岁区间,身高呈高斯正态分布(中心轴在166cm),体重集中在46到50kg的区间。
- 由可视化分析的结果2图示,可发现年龄越低,身高越高,年龄与身高呈负相关性。且在年龄相同或相近的情况下,身高越高,其体重也越高。身高、年龄和体重之间都呈一定的相关性。
- 由可视化分析的结果3图示,抽样统计发现大部分选手是为汉族,同时在数据上显示少数民族在身高上更具优势。
六、选取三位选手,并为这三位选手分别选取三张照片,以九宫格的形式可视化出来。
from PIL import Image
#将图像转化为正方形图像
def fill_image(image):
width, height = image.size
_length = width
if height < width:
_length = height
new_image = Image.new(image.mode, (_length, _length), color='white')
if width < height:
new_image.paste(image, (0, int((_length - height) / 2)))
else:
new_image.paste(image, (int((_length - width) / 2), 0))
# 调整图像为相同大小
new_image = new_image.resize((128, 128))
return new_image
pics = []
pics.append(fill_image(Image.open("work/pics/陈松伶/1.jpg")))
pics.append(fill_image(Image.open("work/pics/陈松伶/2.jpg")))
pics.append(fill_image(Image.open("work/pics/陈松伶/3.jpg")))
pics.append(fill_image(Image.open("work/pics/伊能静/1.jpg")))
pics.append(fill_image(Image.open("work/pics/伊能静/2.jpg")))
pics.append(fill_image(Image.open("work/pics/伊能静/3.jpg")))
pics.append(fill_image(Image.open("work/pics/张雨绮/1.jpg")))
pics.append(fill_image(Image.open("work/pics/张雨绮/2.jpg")))
pics.append(fill_image(Image.open("work/pics/张雨绮/3.jpg")))
IMAGE_SIZE = 128
IMAGE_ROW = 3 # 图片间隔,也就是合并成一张图后,一共有几行
IMAGE_COLUMN = 3 # 图片间隔,也就是合并成一张图后,一共有几列
#拼接一张九宫格图片
def image_compose():
to_image = Image.new('RGB', (IMAGE_COLUMN * IMAGE_SIZE, IMAGE_ROW * IMAGE_SIZE)) #创建一个新图
# 循环遍历,把每张图片按顺序粘贴到对应位置上
i = 0
for y in range(1, IMAGE_ROW + 1):
for x in range(1, IMAGE_COLUMN + 1):
from_image = pics[i]
to_image.paste(from_image, ((x - 1) * IMAGE_SIZE, (y - 1) * IMAGE_SIZE))
i = i + 1
to_image.save('work/baiSudoku.jpg')
return to_image
pic_show = image_compose()
pic_show = plt.imread('work/baiSudoku.jpg')
plt.axis('off')
plt.imshow(pic_show)
结果:















 2406
2406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









