









目录
8.2 Spring Data JPA 与 JPA和hibernate之间的关系
9.2.3 在application.yml中配置数据库和jpa的相关属性
9.3.1 编写符合Spring Data JPA规范的Dao层接口
11.1 使用Spring Data JPA中接口定义的方法进行查询
一、 ORM概述
当面向对象的软件开发中,ORM(Object-Relational Mapping)起到了关键作用。ORM允许开发者使用面向对象的方式来处理数据库,而不必直接依赖于SQL语句。通过ORM框架,开发者可以定义实体类(对象),而框架会负责将这些对象映射到数据库中的表。这样,对实体类的操作就会被翻译成对数据库的操作。
主要的ORM框架,如Hibernate、MyBatis等,提供了各种映射和配置方式,以及对数据库操作的高级抽象。这样,开发者可以更专注于业务逻辑,而不必过于关注数据库底层的细节。ORM框架通常提供以下功能:
映射:将实体类映射到数据库表,每个类对应数据库中的一张表,类的属性对应表中的字段。
CRUD操作:提供对数据库的基本操作,包括创建(Create)、读取(Read)、更新(Update)、删除(Delete)。
事务管理:提供事务支持,确保对数据库的操作是原子的,要么全部执行,要么全部回滚。
查询语言:提供高级的查询语言,允许使用面向对象的查询语法而不是直接的SQL语句。
性能优化:提供一些性能优化的功能,例如缓存机制、延迟加载等。
ORM的使用使得数据库操作更加便捷,同时也提高了代码的可维护性。
二、 Hibernate与JPA概述
2.1 Hibernate概述
Hibernate是一个开源的对象关系映射框架,通过轻量级的封装提供了对JDBC的访问。它建立了Java对象(POJO)与数据库表之间的映射关系,实现了对象与数据库的无缝交互。Hibernate是一个全自动的ORM框架,能够自动生成SQL语句并执行,使得Java开发人员能够以更符合对象编程思维的方式来操作数据库。通过Hibernate,开发者可以更专注于业务逻辑的实现,而不必过多关注数据库操作的细节。
2.2 JPA概述
JPA(Java Persistence API)是Java持久化API的全称,是由SUN公司推出的一套基于对象关系映射(ORM)的规范。它由一系列接口和抽象类构成。
JPA的主要功能是通过注解描述对象与关系数据库表之间的映射关系,并负责将运行时的实体对象持久化到数据库中。通过这一规范,Java开发者可以更方便地进行对象的存储和检索,而不必直接编写大量的SQL语句。
使用JPA,开发者可以通过注解(如@Entity、@Table、@Column等)来配置实体类与数据库表的映射关系,还可以定义查询语句、事务管理等。这样,开发者在进行数据库操作时可以更专注于业务逻辑的实现,而不必过多关注数据库细节。JPA的出现为Java应用程序提供了更便捷、标准的持久化方案。
2.3 JPA与hibernate的关系
JPA的出现旨在提供一个标准的ORM解决方案,使得开发者可以更轻松地切换不同的ORM实现,而不用过多关心底层的细节。JPA规范本质上就是一种ORM规范。
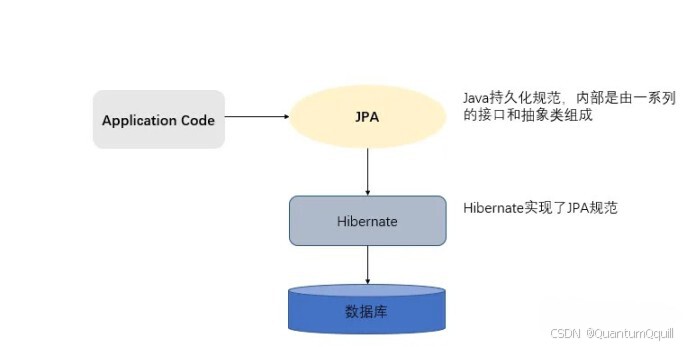
因此,JPA并不是直接取代Hibernate,而是提供了一个抽象层,使得开发者可以选择不同的实现供应商(如Hibernate、EclipseLink等)。JPA和Hibernate是一种规范与实现之间的典型关系,JPA提供了一套接口和规则,而Hibernate是其中的一种具体实现。这种分离使得开发者可以更加灵活地选择和切换不同的ORM实现。
在具体的项目中,你可以选择使用JPA接口进行开发,而具体的ORM实现可以是Hibernate。
三、JPA的入门案例
3.1 导入jar包
我们选择Hibernate作为JPA的实现,所以需要导入Hibernate的相关jar包。
下载网址
https://sourceforge.net/projects/hibernate/files/hibernate-orm/5.6.5.Final/
3.2 搭建开发环境
创建一个普通java项目,或者maven项目。导入jar包
对于JPA操作,只需要从下载的压缩包中找到我们需要的jar导入到工程中即可。
3.2.1 传统工程导入jar包
maven工程导入坐标
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.hibernate.version>5.6.5.Final</project.hibernate.version>
</properties>
<dependencies>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- c3p0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- log日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Mysql and MariaDB -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies> 3.2.2 创建客户的数据库表和客户的实体类
1.创建客户的数据库表
/*创建客户表*/
CREATE TABLE cust_customer (
cust_id BIGINT ( 32 ) NOT NULL AUTO_INCREMENT COMMENT '客户编号(主键)',
cust_name VARCHAR ( 32 ) NOT NULL COMMENT '客户名称(公司名称)',
cust_source VARCHAR ( 32 ) DEFAULT NULL COMMENT '客户信息来源',
cust_industry VARCHAR ( 32 ) DEFAULT NULL COMMENT '客户所属行业',
cust_level VARCHAR ( 32 ) DEFAULT NULL COMMENT '客户级别',
cust_address VARCHAR ( 128 ) DEFAULT NULL COMMENT '客户联系地址',
cust_phone VARCHAR ( 64 ) DEFAULT NULL COMMENT '客户联系电话',
PRIMARY KEY ( `cust_id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;2.创建客户的实体类
@Data
public class Customer implements Serializable {
private Long custId;
private String custName;
private String custSource;
private String custIndustry;
private String custLevel;
private String custAddress;
private String custPhone;
}3.2.3 编写实体类和数据库表的映射配置[重点]
-
在实体类上使用JPA注解的形式配置映射关系
package com.kaifamiao.entity; import lombok.Data; import javax.persistence.*; import java.io.Serializable; /** * 所有的注解都是使用JPA的规范提供的注解, */ @Data @Entity //声明实体类 @Table(name="cust_customer") //建立实体类和表的映射关系 public class Customer implements Serializable { @Id //声明当前私有属性为主键 @GeneratedValue(strategy= GenerationType.IDENTITY) //配置主键的生成策略 @Column(name="cust_id") //指定和表中cust_id字段的映射关系 private Long custId; @Column(name="cust_name") //指定和表中cust_name字段的映射关系 private String custName; @Column(name="cust_source")//指定和表中cust_source字段的映射关系 private String custSource; @Column(name="cust_industry")//指定和表中cust_industry字段的映射关系 private String custIndustry; @Column(name="cust_level")//指定和表中cust_level字段的映射关系 private String custLevel; @Column(name="cust_address")//指定和表中cust_address字段的映射关系 private String custAddress; @Column(name="cust_phone")//指定和表中cust_phone字段的映射关系 private String custPhone; }
PS:常用注解的说明
| 注解 | 作用 |
| @Entity | 指定当前类是实体类 |
| @Table | 指定实体类和表之间的对应关系 属性name :指定数据库表的名称 |
| @Id | 指定当前字段是主键 |
| @GeneratedValue | 指定主键的生成方式 属性strategy :指定主键生成策略。 |
| @Column | 指定实体类属性和数据库表之间的对应关系 属性name:指定数据库表的列名称 unique:是否唯一 nullable:是否可以为空 inserttable:是否可以插入 updateable:是否可以更新 columnDefinition: 定义建表时创建此列的DDL secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字搭建开发环境[重点] |
3.2.4 配置JPA的核心配置文件
在java工程的src路径(maven项目在resouces目录)下创建一个名为META-INF的文件夹,在此文件夹下创建一个名为persistence.xml的配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd" version="2.0"> <!--配置持久化单元 name:持久化单元名称 transaction-type:事务类型 RESOURCE_LOCAL:本地事务管理 JTA:分布式事务管理 -->
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<!--配置JPA规范的服务提供商 -->
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<properties>
<!-- 数据库驱动 -->
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<!-- 数据库地址 -->
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/jpa"/>
<!-- 数据库用户名 -->
<property name="javax.persistence.jdbc.user" value="root"/>
<!-- 数据库密码 -->
<property name="javax.persistence.jdbc.password" value=""/>
<!--jpa提供者的可选配置:我们的JPA规范的提供者为hibernate,所以jpa的核心配置中兼容hibernate的配 -->
<!-- 显示sql -->
<property name="hibernate.show_sql" value="true"/>
<!-- 格式化sql -->
<property name="hibernate.format_sql" value="true"/>
<!-- create:表示启动的时候先drop,再create
create-drop: 也表示创来建,只不过再系统关自闭前执行一下drop
update: 这个操作启动的时候会去检查schema是否一致,如果不一致会做百scheme更新
validate: 启动时验证现有schema与你配置的hibernate是否一致,如果不一致就抛出异常度,并不做更新 -->
<property name="hibernate.hbm2ddl.auto" value="create"/>
</properties>
</persistence-unit>
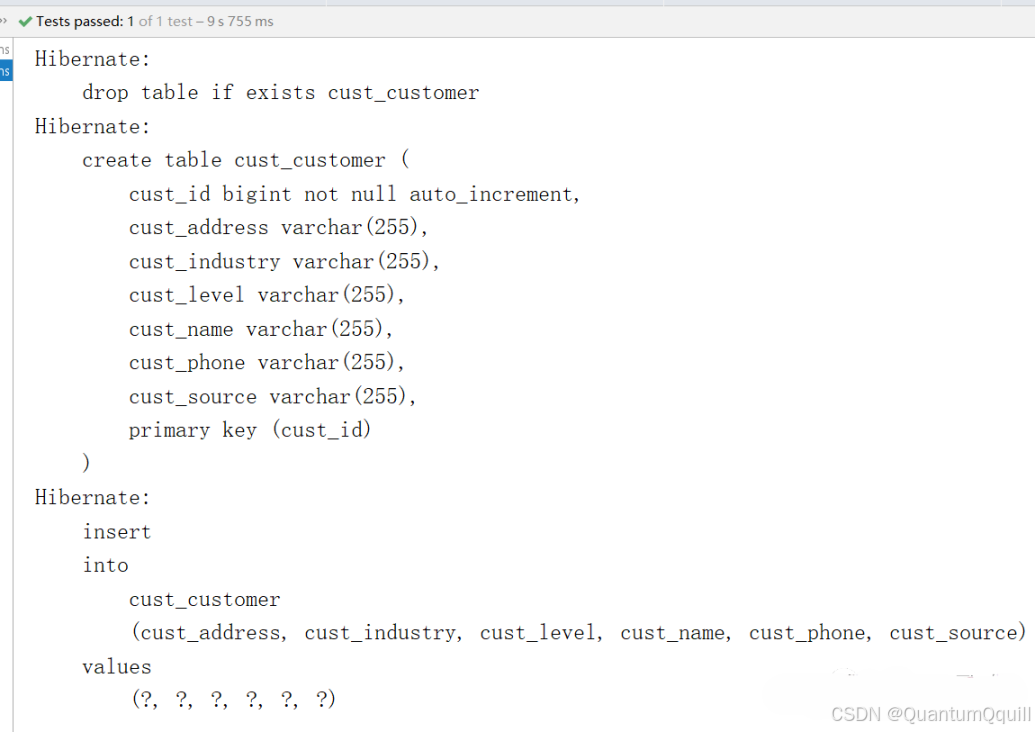
</persistence>3.3 实现保存操作
@Test
public void test() {
/**
* 创建实体管理类工厂,借助Persistence的静态方法获取
* 其中传递的参数为持久化单元名称,需要jpa配置文件中指定
*/
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
//创建实体管理类
EntityManager em = factory.createEntityManager();
//获取事务对象
EntityTransaction tx = em.getTransaction();
//开启事务
tx.begin();
//创建对象
Customer c = new Customer();
//设置值
c.setCustName("云创动力");
//保存操作
em.persist(c);
//提交事务
tx.commit();
//释放资源
em.close();
factory.close();
}
四、JPA中的主键生成策略
通过注解(annotation)来映射Hibernate实体时,使用@Id标识主键,其生成规则由@GeneratedValue设定。这里的@Id和@GeneratedValue都是JPA的标准用法。
JPA提供了四种标准的生成策略,分别是:TABLE、SEQUENCE、IDENTITY、AUTO。
具体说明如下:
-
IDENTITY: 主键由数据库自动生成(主要是自增长型)
用法:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long custId;
-
SEQUENCE :根据底层数据库的序列来生成主键,条件是数据库支持序列。
用法:
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,generator="payablemoney_seq")
@SequenceGenerator(name="payablemoney_seq", sequenceName="seq_payment")
private Long custId;//@SequenceGenerator源码中的定义
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface SequenceGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//属性表示生成策略用到的数据库序列名称。
String sequenceName() default "";
//表示主键初识值,默认为1
int initialValue() default 1;
//表示每次主键值增加的大小,例如设置1,则表示每次插入新记录后自动加1,默认为50
int allocationSize() default 50;
}
AUTO :主键由程序控制
用法:
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long custId;
TABLE :使用一个特定的数据库表格来保存主键
用法:
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator="payablemoney_gen")
@TableGenerator(name = "payablemoney_gen",
table="tb_generator",
pkColumnName="gen_name",
valueColumnName="gen_value",
pkColumnValue="CUSTOMER_PK",
allocationSize=1
)
private Long custId;//@TableGenerator的定义:
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface TableGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//表示表生成策略所持久化的表名,例如,这里表使用的是数据库中的“tb_generator”。
String table() default "";
//catalog和schema具体指定表所在的目录名或是数据库名
String catalog() default "";
String schema() default "";
//属性的值表示在持久化表中,该主键生成策略所对应键值的名称。例如在“tb_generator”中将“gen_name”作为主键的键值
String pkColumnName() default "";
//属性的值表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加。例如,在“tb_generator”中将“gen_value”作为主键的值
String valueColumnName() default "";
//属性的值表示在持久化表中,该生成策略所对应的主键。例如在“tb_generator”表中,将“gen_name”的值为“CUSTOMER_PK”。
String pkColumnValue() default "";
//表示主键初识值,默认为0。
int initialValue() default 0;
//表示每次主键值增加的大小,例如设置成1,则表示每次创建新记录后自动加1,默认为50。
int allocationSize() default 50;
UniqueConstraint[] uniqueConstraints() default {};
}
//这里应用表tb_generator,定义为 :
CREATE TABLE tb_generator (
id NUMBER NOT NULL,
gen_name VARCHAR2(255) NOT NULL,
gen_value NUMBER NOT NULL,
PRIMARY KEY(id)
)五、JPA的API介绍
5.1 Persistence对象
Persistence对象主要作用是用于获取EntityManagerFactory对象的 。通过调用该类的createEntityManagerFactory静态方法,根据配置文件中持久化单元名称创建EntityManagerFactory。
String unitName = "myJpa";
EntityManagerFactory factory = Persistence.createEntityManagerFactory(unitName);5.2 EntityManagerFactory
EntityManagerFactory 接口主要用来创建 EntityManager 实例。
//创建实体管理类
EntityManager em = factory.createEntityManager();由于EntityManagerFactory 是一个线程安全的对象(即多个线程访问同一个EntityManagerFactory 对象不会有线程安全问题),并且EntityManagerFactory 的创建极其浪费资源,所以在使用JPA编程时,我们可以对EntityManagerFactory 的创建进行优化,只需要做到一个工程只存在一个EntityManagerFactory 即可。
5.3 EntityManager
在JPA规范中,EntityManager是完成持久化操作的核心对象。实体类作为普通Java对象,只有在调用EntityManager将其持久化后才会变成持久化对象。EntityManager对象在一组实体类与底层数据源之间进行O/R映射的管理。它可以用来管理和更新Entity Bean,根据主键查找Entity Bean,还可以通过JPQL语句查询实体。
我们可以通过调用EntityManager的方法完成获取事务以及持久化数据库的操作。
方法说明:
getTransaction() 获取事务对象
persist() // 保存操作
merge() // 更新操作
remove() //删除操作
find/getReference() // 查询
5.4 EntityTransaction
在 JPA 规范中, EntityTransaction是完成事务操作的核心对象,对于EntityTransaction在我们的java代码中的功能比较简单。
begin:开启事务
commit:提交事务
rollback:回滚事务六、抽取JPAUtil工具类
package com.kaifamiao.dao;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
/**
* JPAUtil
* @Version v1.0
*/
public final class JPAUtil {
// JPA的实体管理器工厂:相当于Hibernate的SessionFactory
private static EntityManagerFactory em;
// 使用静态代码块赋值
static {
// 注意:该方法参数必须和persistence.xml中persistence-unit标签name属性取值一致
em = Persistence.createEntityManagerFactory("myJpa");
}
/**
* 使用管理器工厂生产一个管理器对象
*
* @return
*/
public static EntityManager getEntityManager() {
return em.createEntityManager();
}
}
七、使用JPA完成增删改查操作
JPA操作时,所有的修改(新增、修改、删除)操作应该在事务中完成。
7.1 保存客户信息
@Test
public void testAdd(){
// 定义对象
Customer c = new Customer();
c.setCustName("云创动力");
c.setCustLevel("VIP客户");
c.setCustSource("网络");
c.setCustIndustry("开发喵");
c.setCustAddress("西安市未央区");
c.setCustPhone("150****7009");
EntityManager em = null;
EntityTransaction tx = null;
try {
// 获取实体管理对象
em = JPAUtil.getEntityManager();
// 获取事务对象
tx = em.getTransaction();
// 开启事务
tx.begin();
// 执行操作
em.persist(c);
// 提交事务
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}7.2 修改信息
@Test
public void testMerge(){
//定义对象
EntityManager em=null;
EntityTransaction tx=null;
try{
//获取实体管理对象
em=JPAUtil.getEntityManager();
//获取事务对象
tx=em.getTransaction();
//开启事务
tx.begin();
//执行操作
Customer c1 = em.find(Customer.class, 1L);
c1.setCustName("西安云创动力");
em.clear();//把c1对象从缓存中清除出去
em.merge(c1);
//提交事务
tx.commit();
}catch(Exception e){
//回滚事务
tx.rollback();
e.printStackTrace();
}finally{
//释放资源
em.close();
}
}7.3 删除
/**
* 删除
*/
@Test
public void testRemove() {
// 定义对象
EntityManager em = null;
EntityTransaction tx = null;
try {
// 获取实体管理对象
em = JPAUtil.getEntityManager();
// 获取事务对象
tx = em.getTransaction();
// 开启事务
tx.begin();
// 执行操作
Customer c1 = em.find(Customer.class, 2L);
em.remove(c1);
// 提交事务
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}7.4 查询
/**
* 查询一个: 使用立即加载的策略
*/
@Test
public void testGetOne() {
// 定义对象
EntityManager em = null;
EntityTransaction tx = null;
try {
// 获取实体管理对象
em = JPAUtil.getEntityManager();
// 获取事务对象
tx = em.getTransaction();
// 开启事务
tx.begin();
// 执行操作
Customer c1 = em.find(Customer.class, 1L);
// 提交事务
tx.commit();
System.out.println(c1); // 输出查询对象
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}
// 查询实体的缓存问题
@Test
public void testGetOne1() {
// 定义对象
EntityManager em = null;
EntityTransaction tx = null;
try {
// 获取实体管理对象
em = JPAUtil.getEntityManager();
// 获取事务对象
tx = em.getTransaction();
// 开启事务
tx.begin();
// 执行操作
Customer c1 = em.find(Customer.class, 1L);
Customer c2 = em.find(Customer.class, 1L);
System.out.println(c1 == c2);// 输出结果是true,EntityManager也有缓存
// 提交事务
tx.commit();
System.out.println(c1);
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}
// 延迟加载策略的方法:
/**
* 查询一个: 使用延迟加载策略
*/
@Test
public void testLoadOne() {
// 定义对象
EntityManager em = null;
EntityTransaction tx = null;
try {
// 获取实体管理对象
em = JPAUtil.getEntityManager();
// 获取事务对象
tx = em.getTransaction();
// 开启事务
tx.begin();
// 执行操作
Customer c1 = em.getReference(Customer.class, 1L);
// 提交事务
tx.commit();
System.out.println(c1);
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}
7.5 JPA中的复杂查询
JPQL全称Java Persistence Query Language。
Java持久化查询语言(JPQL)基于首次在EJB 2.0中引入的EJB查询语言(EJB QL)。JPQL是一种可移植的查询语言,旨在以面向对象表达式语言的形式将SQL语法和简单查询语义绑定在一起。使用这种语言编写的查询是可移植的,可以被编译成所有主流数据库服务器上的SQL。
JPQL的特征与原生SQL语句类似,并且完全面向对象。通过类名和属性访问,而不是表名和表的属性。
7.5.1 查询全部
//查询所有客户
@Test
public void findAll() {
EntityManager em = null;
EntityTransaction tx = null;
try {
//获取实体管理对象
em = JPAUtil.getEntityManager();
//获取事务对象
tx = em.getTransaction();
tx.begin();
// 创建query对象
String jpql = "from Customer";
Query query = em.createQuery(jpql);
// 查询并得到返回结果
List list = query.getResultList(); // 得到集合返回类型
for (Object object : list) {
System.out.println(object);
}
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}7.5.2 分页查询
//分页查询客户
@Test
public void findPaged () {
EntityManager em = null;
EntityTransaction tx = null;
try {
//获取实体管理对象
em = JPAUtil.getEntityManager();
//获取事务对象
tx = em.getTransaction();
tx.begin();
//创建query对象
String jpql = "from Customer";
Query query = em.createQuery(jpql);
//起始索引
query.setFirstResult(0);
//每页显示条数
query.setMaxResults(2);
//查询并得到返回结果
List list = query.getResultList(); //得到集合返回类型
for (Object object : list) {
System.out.println(object);
}
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}7.5.3 条件查询
//条件查询
@Test
public void findCondition () {
EntityManager em = null;
EntityTransaction tx = null;
try {
//获取实体管理对象
em = JPAUtil.getEntityManager();
//获取事务对象
tx = em.getTransaction();
tx.begin();
//创建query对象
String jpql = "from Customer where custName like ? ";
Query query = em.createQuery(jpql);
//对占位符赋值,从1开始
query.setParameter(1, "%云创%");
//查询并得到返回结果
Object object = query.getSingleResult(); //得到唯一的结果集对象
System.out.println(object);
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}7.5.4 排序查询
//根据客户id倒序查询所有客户
//查询所有客户
@Test
public void testOrder() {
EntityManager em = null;
EntityTransaction tx = null;
try {
//获取实体管理对象
em = JPAUtil.getEntityManager();
//获取事务对象
tx = em.getTransaction();
tx.begin();
// 创建query对象
String jpql = "from Customer order by custId desc";
Query query = em.createQuery(jpql);
// 查询并得到返回结果
List list = query.getResultList(); // 得到集合返回类型
for (Object object : list) {
System.out.println(object);
}
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}7.5.5 统计查询
//统计查询
@Test
public void findCount() {
EntityManager em = null;
EntityTransaction tx = null;
try {
//获取实体管理对象
em = JPAUtil.getEntityManager();
//获取事务对象
tx = em.getTransaction();
tx.begin();
// 查询全部客户
// 1.创建query对象
String jpql = "select count(custId) from Customer";
Query query = em.createQuery(jpql);
// 2.查询并得到返回结果
Object count = query.getSingleResult(); // 得到集合返回类型
System.out.println(count);
tx.commit();
} catch (Exception e) {
// 回滚事务
tx.rollback();
e.printStackTrace();
} finally {
// 释放资源
em.close();
}
}
八、Spring Data JPA概述
官网(https://spring.io/projects/spring-data-jpa,建议使用翻译功能后查看,体验更佳)

Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
8.1 Spring Data JPA的特性

SpringData Jpa 极大简化了数据库访问层代码。如何简化的呢?使用了SpringDataJpa,我们的dao层中只需要写接口,就自动具有了增删改查、分页查询等方法。
8.2 Spring Data JPA 与 JPA和hibernate之间的关系
JPA是一套规范,内部是有接口和抽象类组成的。hibernate是一套成熟的ORM框架,而且Hibernate实现了JPA规范,所以也可以称hibernate为JPA的一种实现方式,我们使用JPA的API编程,意味着站在更高的角度上看待问题(面向接口编程)。
Spring Data JPA是Spring提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案。
九、 Spring Data JPA的快速入门
9.1 需求说明
使用SpringBoot整合Spring Data JPA 完成客户的基本CRUD操作。
9.2 实现
9.2.1 Spring Data JPA的起步依赖
<!-- springBoot JPA的起步依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>9.2.2 添加数据库驱动依赖
<!-- MySQL连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>9.2.3 在application.yml中配置数据库和jpa的相关属性
spring:
# DB Configuration:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/jpa
username: root
password:
type: com.alibaba.druid.pool.DruidDataSource
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
filters: wall,stat,log4j
# jpa
jpa:
database: mysql
show-sql: true
generate-ddl: true
hibernate:
ddl-auto: update
9.2.4 使用JPA注解配置映射关系
我们使用之前案例中的Customer实体类对象,已经配置好了映射关系。
package com.kaifamiao.jpa.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
/**
* @Classname Customer
* 所有的注解都是使用JPA的规范提供的注解,
* 所以在导入注解包的时候,一定要导入javax.persistence下的
* @Version v1.0
*/
@Data
@Entity //声明实体类
@Table(name="cust_customer") //建立实体类和表的映射关系
public class Customer implements Serializable {
// @Id //声明当前私有属性为主键
// @GeneratedValue(strategy= GenerationType.IDENTITY) //配置主键的生成策略
// @Column(name="cust_id") //指定和表中cust_id字段的映射关系
// private Long custId;
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator="payablemoney_gen")
@TableGenerator(name = "payablemoney_gen",
table="tb_generator",
pkColumnName="gen_name",
valueColumnName="gen_value",
pkColumnValue="CUSTOMER_PK",
allocationSize=1
)
private Long custId;
@Column(name="cust_name") //指定和表中cust_name字段的映射关系
private String custName;
@Column(name="cust_source")//指定和表中cust_source字段的映射关系
private String custSource;
@Column(name="cust_industry")//指定和表中cust_industry字段的映射关系
private String custIndustry;
@Column(name="cust_level")//指定和表中cust_level字段的映射关系
private String custLevel;
@Column(name="cust_address")//指定和表中cust_address字段的映射关系
private String custAddress;
@Column(name="cust_phone")//指定和表中cust_phone字段的映射关系
private String custPhone;
}
9.3 使用Spring Data JPA完成需求
9.3.1 编写符合Spring Data JPA规范的Dao层接口
Spring Data JPA 是spring提供的一款对于数据访问层(Dao层)的框架,使用Spring Data JPA,只需要按照框架的规范提供dao接口,不需要实现类就可以完成数据库的增删改查、分页查询等方法的定义,极大的简化了我们的开发过程。
在Spring Data JPA中,对于定义符合规范的Dao层接口,我们只需要遵循以下几点就可以了:
-
1. 创建一个Dao层接口,并实现
org.springframework.data.jpa.repository.JpaRepository和org.springframework.data.jpa.repository.JpaSpecificationExecutor接口 -
2. 提供相应的泛型
package com.kaifamiao.jpa.dao;
import com.kaifamiao.jpa.entity.Customer;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
/**
* @Classname CustomerDao
* @Description JpaRepository<实体类类型,主键类型>:用来完成基本CRUD操作
* JpaSpecificationExecutor<实体类类型>:用于复杂查询(分页等查询操作)
*/
public interface CustomerDao extends JpaRepository<Customer,Long>, JpaSpecificationExecutor<Customer> {
}
这样我们就定义好了一个符合Spring Data JPA规范的Dao层接口。
9.3.2 完成基本CRUD操作
完成了Spring Data JPA的环境搭建,并且编写了符合Spring Data JPA 规范的Dao层接口之后,就可以使用定义好的Dao层接口进行客户的基本CRUD操作。
package com.kaifamaio.jpa.dao;
import com.kaifamaio.jpa.entity.Customer;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Optional;
@SpringBootTest
class CustomerDaoTest {
@Autowired
private CustomerDao customerDao;
@Test
public void findOne(){
Optional<Customer> customer = customerDao.findById(3L);
System.out.println(customer.get());
}
@Test
public void findAll(){
System.out.println(customerDao.findAll());
}
@Test
public void save(){
Customer customer = new Customer();
customer.setCustName("spring-data");
customer.setCustPhone("123123123");
System.out.println(customerDao.save(customer));
}
@Test
public void update(){
Customer customer = customerDao.findById(3L).get();
customer.setCustName(customer.getCustName() + "-update");
customerDao.save(customer);
}
@Test
public void delete(){
customerDao.deleteById(3L);
}
}十、 Spring Data JPA的内部原理剖析
10.1 Spring Data JPA的常用接口分析
在客户的案例中,我们发现在自定义的CustomerDao中,并没有提供任何方法就可以使用其中的很多方法,那么这些方法究竟是怎么来的呢?答案很简单,对于我们自定义的Dao接口,由于继承了org.springframework.data.jpa.repository.JpaRepository和org.springframework.data.jpa.repository.JpaSpecificationExecutor,所以我们可以使用这两个接口的所有方法。
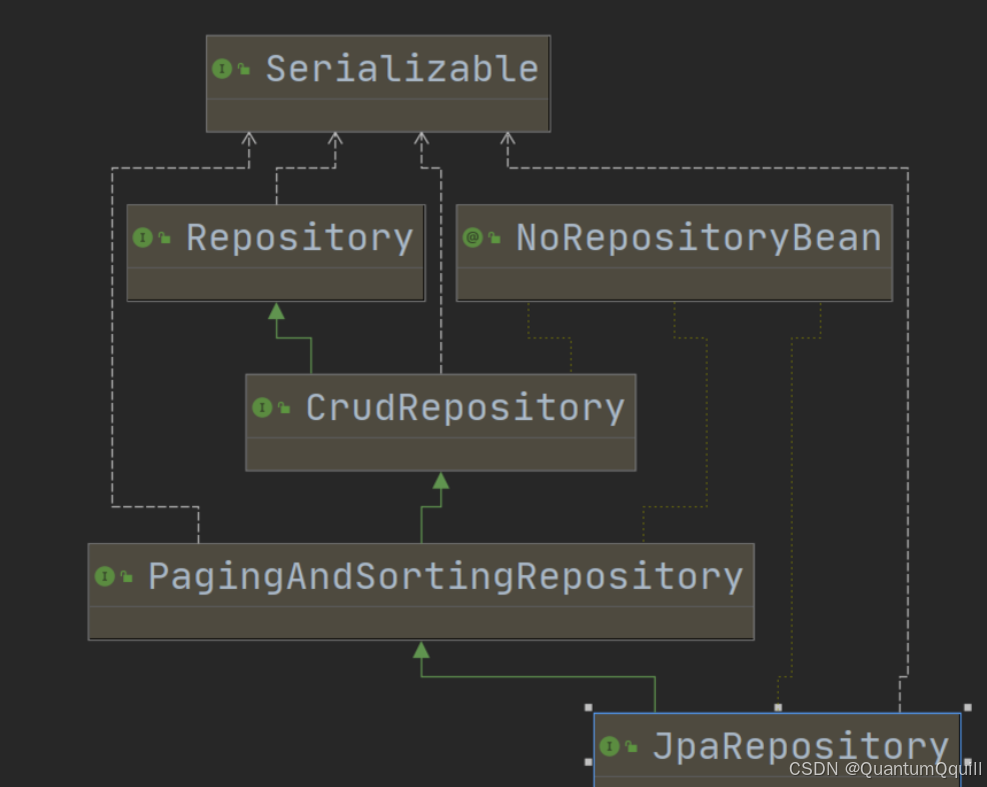
在使用Spring Data JPA时,一般继承 JpaRepository 和 JpaSpecificationExecutor 接口,这样就可以使用这些接口中定义的方法,但是这些方法都只是一些声明,没有具体的实现方式,那么在 Spring Data JPA中它又是怎么实现的呢?
10.2 Spring Data JPA的实现过程
通过对客户案例,以debug断点调试的方式,通过分析Spring Data JPA的原来来分析程序的执行过程。
我们以findOne方法为例进行分析:
代理子类的实现过程
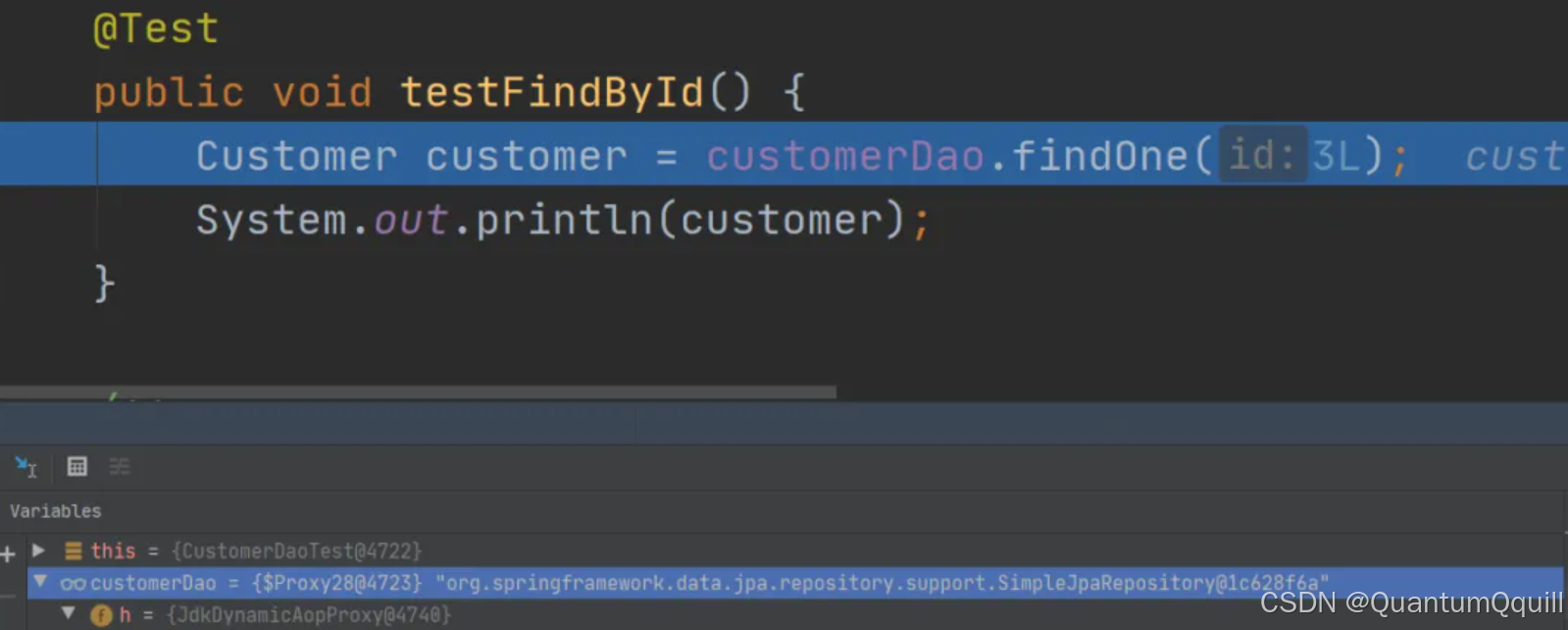
断点执行到方法上时,我们可以发现注入的customerDao对象,本质上是通过JdkDynamicAopProxy生成的一个代理对象。
l代理对象中方法调用的分析
当程序执行的时候,会通过JdkDynamicAopProxy的invoke方法,对customerDao对象生成动态代理对象。根据对Spring Data JPA介绍而知,要想进行findOne查询方法,最终还是会出现 JPA 规范的API完成操作,那么这些底层代码存在于何处呢?答案很简单,都隐藏在通过JdkDynamicAopProxy生成的动态代理对象当中,而这个动态代理对象就是org.springframework.data.jpa.repository.support.SimpleJpaRepository

通过org.springframework.data.jpa.repository.support.SimpleJpaRepository的源码分析,定位到了findOne方法,在此方法中,返回em.find()的返回结果,那么em又是什么呢?
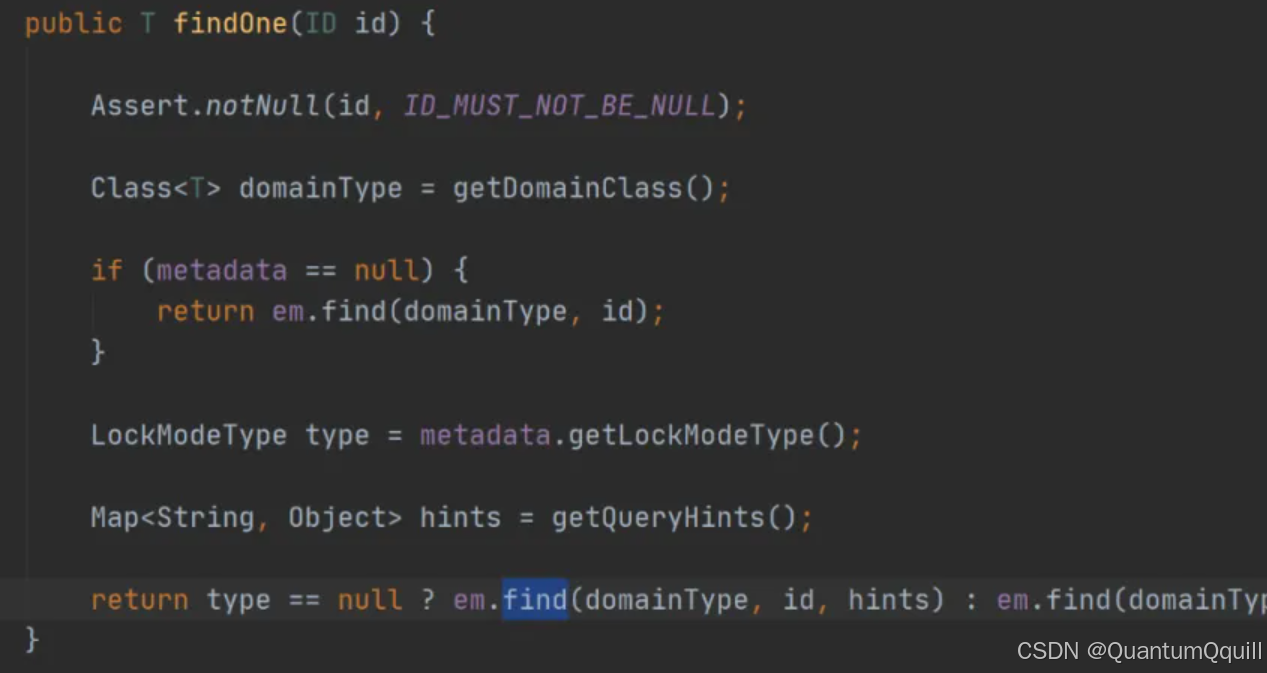
带着问题继续查找em对象,我们发现em就是EntityManager对象,而他是JPA原生的实现方式,所以我们得到结论Spring Data JPA只是对标准JPA操作进行了进一步封装,简化了Dao层代码的开发。
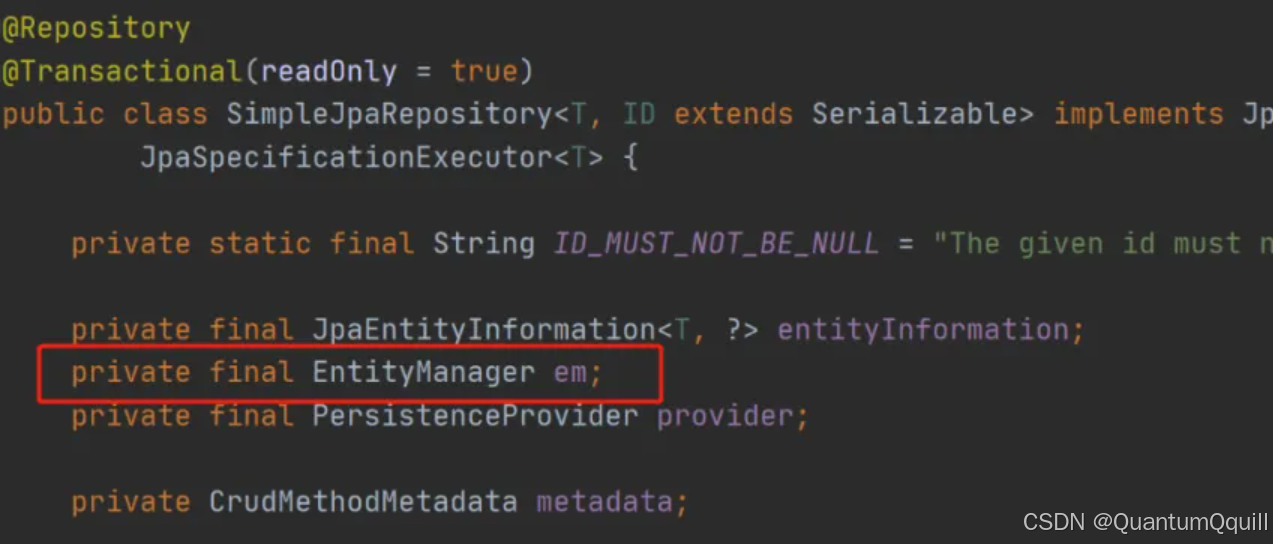
10.3 Spring Data JPA完整的调用过程分析
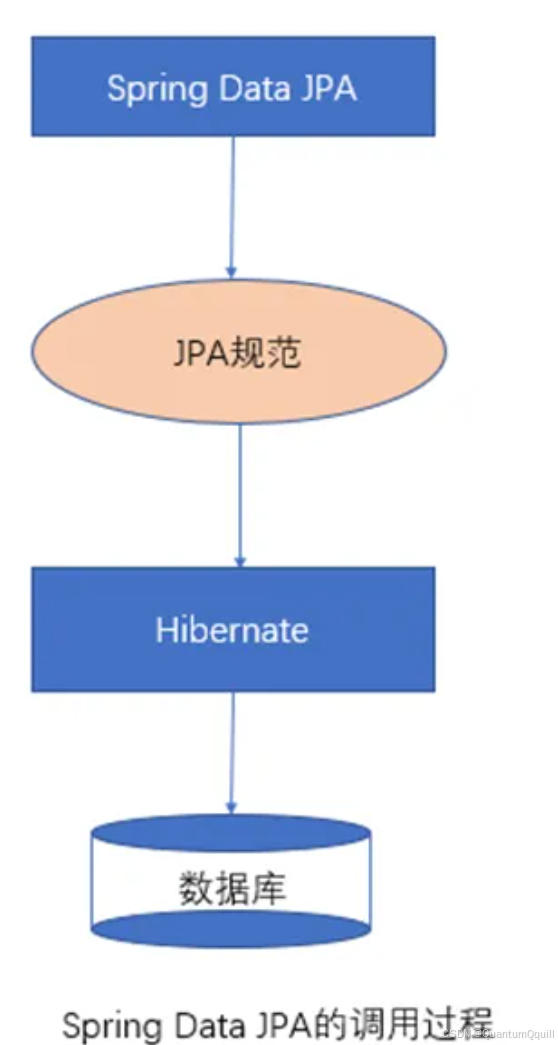
十一、 Spring Data JPA的查询方式
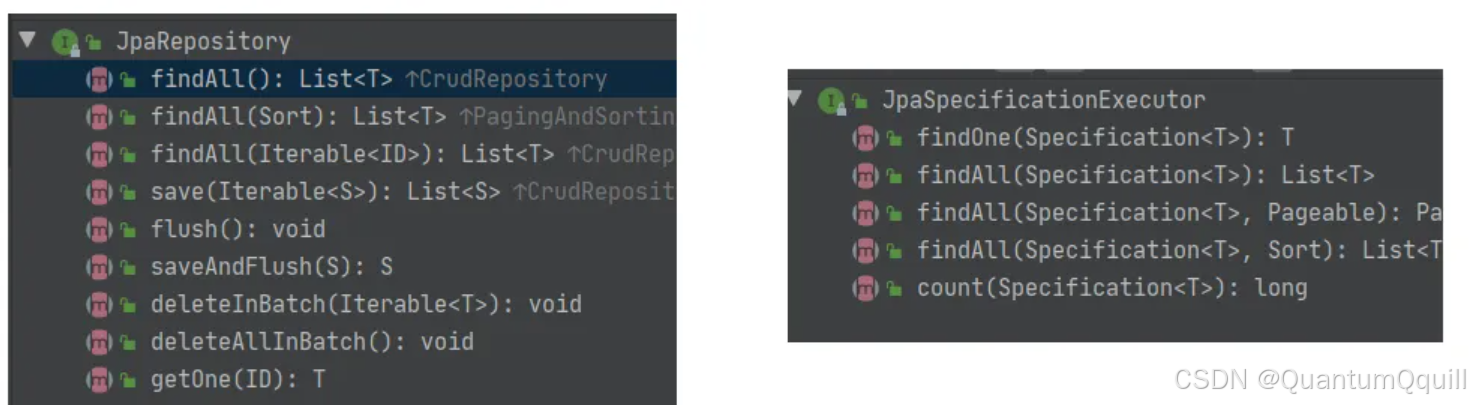
11.1 使用Spring Data JPA中接口定义的方法进行查询
在继承 JpaRepository 和 JpaSpecificationExecutor 接口后,我们就可以使用接口中定义的方法进行查询。
接口中的方法列表:
11.2 使用 JPQL 的方式查询
使用Spring Data JPA提供的查询方法已经可以解决大部分的应用场景,但是对于某些业务来说,我们还需要灵活的构造查询条件,这时就可以使用@Query注解,结合JPQL的语句方式完成查询。
@Query 注解的使用非常简单,只需在方法上面标注该注解,同时提供一个JPQL查询语句即可。
public interface CustomerDao extends JpaRepository<Customer,Long>, JpaSpecificationExecutor<Customer> {
/**
* @Query 使用jpql的方式查询。
*/
@Query(value="from Customer")
public List<Customer> findAllCustomer();
/**
* @Query 使用jpql的方式查询。?1代表参数的占位符,其中1对应方法中的参数索引
*/
@Query(value="from Customer where custName = ?1")
public Customer findByCustName(String custName);
}此外,也可以通过使用 @Query 来执行一个更新操作,为此,我们需要在使用 @Query 的同时,用 @Modifying 来将该操作标识为修改查询,这样框架最终会生成一个更新的操作,而非查询。
@Query(value="update Customer set custName = ?1 where custId = ?2")
@Modifying
@Transactional //让spirng来管理事务
public void updateCustomer(String custName,Long custId);
11.3 使用SQL语句查询
Spring Data JPA同样也支持sql语句的查询,如下:
/**
* nativeQuery : 使用本地sql的方式查询
*/
@Query(value="select * from cust_customer",nativeQuery=true)
public List<Customer> findSql();11.4 方法命名规则查询
顾名思义,方法命名规则查询就是根据方法的名字,就能创建查询。只需要按照Spring Data JPA提供的方法命名规则定义方法的名称,就可以完成查询工作。Spring Data JPA在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询。
按照Spring Data JPA 定义的规则,查询方法以findBy开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
//方法命名方式查询(根据客户名称查询客户)
public Customer findByCustName(String custName);具体的关键字,使用方法和生产成SQL如下表所示:
| 关键字 | 举例 | JPQL |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs, findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









