









 ELMo是一种预训练语言模型,通过结合上下文信息实现词向量的动态表示,以解决一词多义的问题。它使用双向LSTM,一个从前向后,一个从后向前,来捕捉词语在句子中的不同含义。在预训练阶段,ELMo通过无监督学习预测文本中的下一个词或前一个词。在下游任务中,ELMo提供的词向量包含了词本身和上下文信息,提高了模型对句子中词汇意义的理解。经过训练,ELMo的loss逐渐降低,表明模型能更好地理解和预测句子中的词语。
ELMo是一种预训练语言模型,通过结合上下文信息实现词向量的动态表示,以解决一词多义的问题。它使用双向LSTM,一个从前向后,一个从后向前,来捕捉词语在句子中的不同含义。在预训练阶段,ELMo通过无监督学习预测文本中的下一个词或前一个词。在下游任务中,ELMo提供的词向量包含了词本身和上下文信息,提高了模型对句子中词汇意义的理解。经过训练,ELMo的loss逐渐降低,表明模型能更好地理解和预测句子中的词语。
李宏毅介绍过ELMO,但我已经忘记它是个啥东西了。说明不看代码,是无法牢固地记住一样东西的。我的笔记》》
莫烦简洁地介绍了该模型,结合之前笔记效果更佳。莫烦视频》》
预训练的作用
不管是图片识别还是自然语言处理,模型都朝着越来越臃肿,越来越大的方向发展。 每训练一个大的模型,都会消耗掉数小时甚至数天的时间。我们并不希望浪费太多的时间在训练上,所以拿到一个预训练模型就十分重要了。 基于预训练模型,我们能够用较少的
模型数据量 ,较快的速度得到一个适合于我们自己数据的新模型,而且这个模型效果也不会很差。
后面内容将要提到的都是目前比较厉害的、可以用作预训练模型的架构,包括GPT, bert.
ELMO目的
传统使用skip gram 或者 CBOW 训练出来的词向量,(我们有一个包含所有词的字典,利用每一句话进行无监督学习,得到了训练好的embedding层来表示词向量。此时每个词的表示就固定了), 在ELMo看起来,是有问题的。ELMo的全称是 Embeddings from Language Models,他的主要目标是:找出词语放在句子中的意思。
具体展开,ELMo还是想用一个向量来表达词语,不过这个词语的向量会包含上下文的信息。
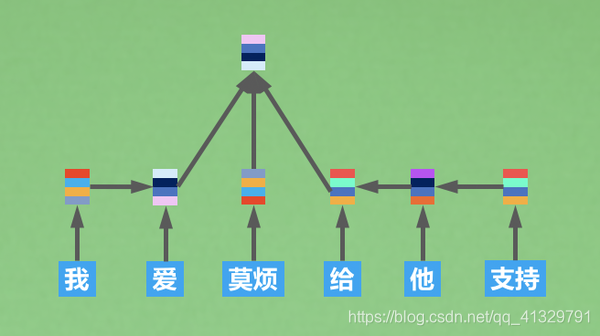
实现一词多义,就是要结合上下文语境来理解该词。在词向量中加上从前后文来的信息就好了,这就是ELMo最核心的思想。那么ELMo是怎样训练,为什么这样训练又可以拿到前后文信息呢?
ELMO图解
ELMo对你来说,只是另一种双向RNN架构。ELMo里有两个RNN(LSTM), 一个从前往后看句子,一个从后往前看句子,每一个词的向量表达,就是下面这几个信息的累积:
- 从前往后的前文信息(前文不一样,“他”的句向量就不一样)
- 从后往前的后文信息(后文不一样,“他”的句向量就不一样)
- 当前词语的词向量信息
累积:将“他”的词向量(embedding得到)+句向量(from RNN)得到了新的向量空间,就能表示“他”在不同语境下的不同意思。
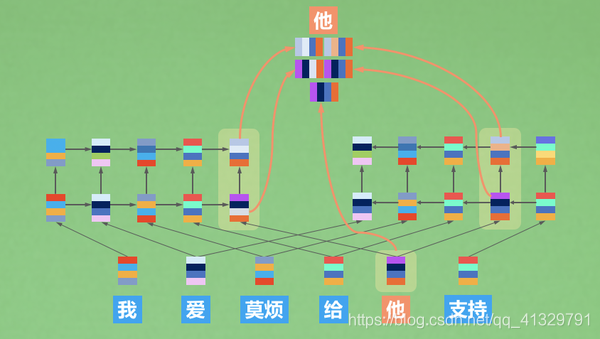
在预训练模型中,EMLo应该是最简单的种类之一了。有了这些加入了前后文信息的词向量,模型就能提供这个词在句子中的意思了。
训练
所谓NLP的无监督学习,实际上就是拿着网上一大堆论坛,wiki等文本, 用它们的前文预测后文,或者后文预测前文,或者两个一起混合预测。不管是 BERT还是GPT, 都是这样的方式. 如果模型能理解人类在网上说话的方式,那么这个模型就学习到了人类语言的内涵。
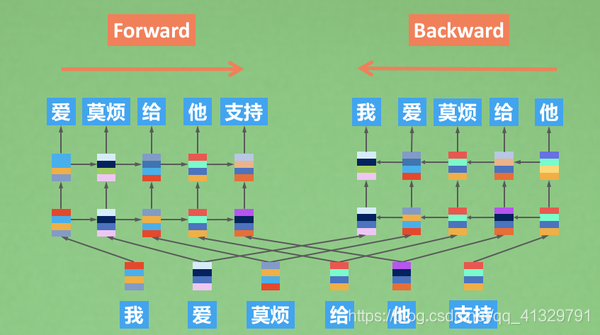
训练一个顺序阅读者(我、爱、莫烦——>给)+一个逆序阅读者(支持、他——>给),在下游任务的时候, 分别让顺序阅读者和逆序阅读者,提供他们从不同角度看到的信息。这就是ELMo的训练和使用方法。
我的疑惑,那ELMo有什么作用呢?
在把ELMo用在下游任务时,不管是下游任务的训练还是下游任务的预测,并不会像训练的call()那样。 时刻记得,我们要的是ELMo对于句子或者是词的理解。所以,我们只管拿着它训练出来的embedding使用就好了。这就是上图“他”所表达的意思。
举个例子,在预测句中某个词的属性时,我们就可以拿着这个词在每一层的向量表达,把它们整合起来,这样就有了词本身的信息和词在句中的信息。 对于这个词在句中到底表达什么意思有了更全面的信息。这也就是为什么我在call()这个函数中,返回的是每一层的output,而不是最后一层的output。
下面函数就是单个词在句子中的理解
def get_emb(self, seqs):
fxs, bxs = self.call(seqs)
xs = [tf.concat((f[:, :-1, :], b[:, 1:, :]), axis=2).numpy() for f, b in zip(fxs, bxs)]
for x in xs:
print("layers shape=", x.shape)
return xs
"""
layers shape= (4, 36, 512)
layers shape= (4, 36, 512)
layers shape= (4, 36, 512)
"""
这个例子中,layer shape=(4, 36, 512) 的意思是4句话,句长36,512的向量表达。 你还可以对每层的向量进行加权求和,或者让另一个下游任务的网络学习一种注意力机制对这些层向量进行加工。这都取决于你的下有任务是怎样考虑的了。
举个例子,现在ELMo给了我3层(4, 36, 512), 如果我的下游任务是句子分类,最简单的一种方式就是,将这三层向量在第3个维度取平均,从 3(4,36,512) 变成 1(4,36,512), 然后再过有一个LSTM得到分类结果。
实战
这次的案例我们就上些真实点的数据,这样才好判断这种体量大点的预训练模型的优势在哪。 所以我挑选到了学术界上常用的 Microsoft Research Paraphrase Corpus (MRPC) 数据集来测试训练过程。 这个数据集的内容大概是用这种形式组织的。
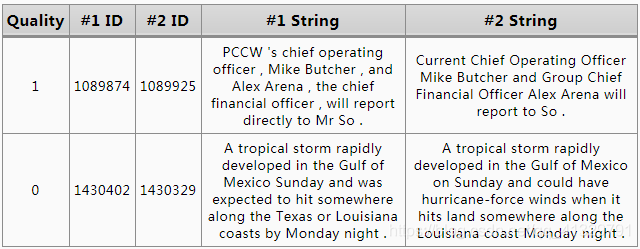
along with human annotations indicating whether each pair captures a paraphrase/semantic equivalence relationship.
每行有两句话 #1 String 和 #2 String, 如果他们是语义相同的话,Quality 为1,反之为0。这份数据集可以做两件事:
- 两句合起来(使用一对)训练文本匹配;
- 两句拆开(针对每一句)单独对待,理解人类语言,学一个语言模型。
这个教学中,我们在训练ELMo理解人类语言的时候,用的是无监督的方法训练第2种模式。让ELMo通读人类语言,然后在大数据中寻找人类说话的规律。 学完之后,模型就有对词语和句子有一定的理解能力了。
语言模型是干嘛的?答:这句话出现的概率。参考连接
代码
数据预处理
数据存放在train_url = 'https://mofanpy.com/static/files/MRPC/msr_paraphrase_train.txt',官网下载也可以。
- step1:下载,将引号"换成
r = requests.get(url, proxies=proxies)
with open(raw_path, "w", encoding="utf-8") as f:
f.write(r.text.replace('"', "<QUOTE>"))
print("completed")
- step2:读csv文件
df.iloc[:,[0]]返回DataFrame df.iloc[:,0]返回Series
df.iloc[:, 0].values,返回取值numpy
不懂正则表达式,参考链接
text = re.sub(r" \d+(,\d+)?(\.\d+)? ", " <NUM> ", text) #32.25 或者 32,25 其中()表示分组,32,.25不行
text = re.sub(r" \d+-+?\d*", " <NUM>-", text) #32-25 其中+?表示尽可能取少 " 25--52 "变成 <NUM> -52
- step3:分词,构造字典
vocab = set()
#循环
cs = data[n][m][i].split(" ")
vocab.update(set(cs))
# 补充字典
v2i["<PAD>"] = PAD_ID
v2i["<MASK>"] = len(v2i)
v2i["<SEP>"] = len(v2i)
v2i["<GO>"] = len(v2i)
- step4:word换成对应的索引(id)
data[n][m+"id"] = [[v2i[v] for v in c.split(" ")] for c in data[n][m]]
data[“train”][“s1id”]的内容为(sentences,words)二维矩阵
将将句子1和句子2前后加上标记,合并成一个数据集
x += [
[self.v2i["<GO>"]] + data["train"]["s2id"][i] + [self.v2i["<SEP>"]]
for i in range(len(data["train"]["s2id"]))
]
self.x = pad_zero(x, max_len=self.max_len) #完整的数据集
塔建模型ELMo
需要构建一个正向的多层LSTM模型,一个反向的LSTM模型,LSTM每个time step的任务是,每次用上文预测的是紧接着的下一个词。
构建一个最初的word embedding, 获取到词语的信息,然后再分别构建前向LSTM和后向LSTM,在构建后向LSTM的时候,要注意写上go_backwards=True表明是逆向读取的。 最后在将从LSTM出来的信息转成logits就能预测了。
在计算loss时,将要考虑前向和后向的误差,将两者加起来一起计算。
没什么复杂,直接上代码吧
函数参数解释
-
keras.layers.Embedding中mask_zero=True,塔配循环神经网络使用。单词id为0,RNN认为是padding值,所以并没有参与运算,输出就是前一个时间步的输出。链接
-
keras.layers.LSTM中return_sequences返回每一个timestep的hidden state。return_state返回最后一个时间步的hidden state和cell state。链接
-
go_backwards=True表明是逆向读取的。网上没找到详细用法
-
embedding自带一个computemask函数,引申的话:自己构造一个compute_mask 。这里不延伸了。根据是否为padding值返回boolean二维矩阵。链接
ID_seq0 = [1, 0, 0, 0]
ID_seq1 = [1, 1, 0, 0]
ID_seq2 = [1, 1, 1, 0]
ID_seq3 = [1, 1, 1, 1]
data = np.array([ID_seq0, ID_seq1, ID_seq2, ID_seq3])
tf.Tensor(
[[ True False False False]
[ True True False False]
[ True True True False]
[ True True True True]], shape=(4, 4), dtype=bool)
正向lstm结果
tf.Tensor(
[[[-0.0010896 -0.00319956 0.00095092]
[-0.0010896 -0.00319956 0.00095092]
[-0.0010896 -0.00319956 0.00095092]
[-0.0010896 -0.00319956 0.00095092]]
[[-0.0010896 -0.00319956 0.00095092]
[-0.00223545 -0.00562784 0.0013137 ]
[-0.00223545 -0.00562784 0.0013137 ]
[-0.00223545 -0.00562784 0.0013137 ]]
[[-0.0010896 -0.00319956 0.00095092]
[-0.00223545 -0.00562784 0.0013137 ]
[-0.00329297 -0.00742414 0.00133942]
[-0.00329297 -0.00742414 0.00133942]]
[[-0.0010896 -0.00319956 0.00095092]
[-0.00223545 -0.00562784 0.0013137 ]
[-0.00329297 -0.00742414 0.00133942]
[-0.00419841 -0.00872188 0.0011895 ]]], shape=(4, 4, 3), dtype=float32)
反向lstm结果
tf.Tensor(
[[[ 0. 0. 0. ]
[ 0. 0. 0. ]
[ 0. 0. 0. ]
[ 0.00244427 0.00061177 -0.0005686 ]]
[[ 0. 0. 0. ]
[ 0. 0. 0. ]
[ 0.00244427 0.00061177 -0.0005686 ]
[ 0.00421863 0.00095914 -0.00094639]]
[[ 0. 0. 0. ]
[ 0.00244427 0.00061177 -0.0005686 ]
[ 0.00421863 0.00095914 -0.00094639]
[ 0.00551624 0.00114066 -0.00119164]]
[[ 0.00244427 0.00061177 -0.0005686 ]
[ 0.00421863 0.00095914 -0.00094639]
[ 0.00551624 0.00114066 -0.00119164]
[ 0.00647225 0.00122006 -0.00134506]]], shape=(4, 4, 3), dtype=float32)
fxs, bxs = [embedded[:, :-1]], [embedded[:, 1:]],因为这一步改变了原来完整的embedding层输出(embedded = self.word_embed(seqs)),所以才需要一个mask矩阵提醒LSTM。 代码可验证。即如果输入LSTM的数据是embedded ,我们不需做mask = self.word_embed.compute_mask(seqs)这一步。
- bxs.append(tf.reverse(bx, axis=[1])) # backwards的输入是【4321】,对应输出为【3210】,结果翻转后predict为 0123。方便做后续处理。
class ELMo(keras.Model):
def __init__(self, v_dim, emb_dim, units, n_layers, lr):
super().__init__()
self.n_layers = n_layers
self.units = units
# encoder
self.word_embed = keras.layers.Embedding(
input_dim=v_dim, output_dim=emb_dim, # [n_vocab, emb_dim]
embeddings_initializer=keras.initializers.RandomNormal(0., 0.001),
mask_zero=True,
)
# forward lstm
self.fs = [keras.layers.LSTM(units, return_sequences=True) for _ in range(n_layers)]
self.f_logits = keras.layers.Dense(v_dim)
# backward lstm
self.bs = [keras.layers.LSTM(units, return_sequences=True, go_backwards=True) for _ in range(n_layers)]
self.b_logits = keras.layers.Dense(v_dim)
self.cross_entropy1 = keras.losses.SparseCategoricalCrossentropy(from_logits=True) #True表示没经过softmax
self.cross_entropy2 = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.opt = keras.optimizers.Adam(lr)
def call(self, seqs):
embedded = self.word_embed(seqs) # [n, step, dim]
"""
0123 forward
1234 forward predict
1234 backward
0123 backward predict
"""
mask = self.word_embed.compute_mask(seqs)
fxs, bxs = [embedded[:, :-1]], [embedded[:, 1:]]
for fl, bl in zip(self.fs, self.bs):
fx = fl(
fxs[-1], mask=mask[:, :-1], initial_state=fl.get_initial_state(fxs[-1])
)
# [n, step-1, dim] fxs[-1]是指每次取上一层的结果embedding->layer1->layer2
bx = bl(
bxs[-1], mask=mask[:, 1:], initial_state=bl.get_initial_state(bxs[-1])
) # [n, step-1, dim]
fxs.append(fx) # predict 1234
bxs.append(tf.reverse(bx, axis=[1])) # predict 0123 矩阵的初等行列变换
return fxs, bxs
def step(self, seqs):
with tf.GradientTape() as tape:
fxs, bxs = self.call(seqs)
fo, bo = self.f_logits(fxs[-1]), self.b_logits(bxs[-1])
loss = (self.cross_entropy1(seqs[:, 1:], fo) + self.cross_entropy2(seqs[:, :-1], bo))/2
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss, (fo, bo)
def get_emb(self, seqs):
fxs, bxs = self.call(seqs)
xs = [tf.concat((f[:, :-1, :], b[:, 1:, :]), axis=2).numpy() for f, b in zip(fxs, bxs)]
# f:<go>...lastword b:firstword...<EOS> 所以concat的是firstword...lastword
for x in xs:
print("layers shape=", x.shape)
return xs
if __name__ == "__main__":
data = MRPCSingle("./MRPC", rows=2000)
UNITS = 256
N_LAYERS = 2
BATCH_SIZE = 16
LEARNING_RATE = 2e-3
model = ELMo(data.num_word, emb_dim=UNITS, units=UNITS, n_layers=N_LAYERS, lr=LEARNING_RATE)
训练模型
计算loss的时候,作者把padding也算进去了。
def train(model, data, step):
t0 = time.time()
for t in range(step):
seqs = data.sample(BATCH_SIZE)
loss, (fo, bo) = model.step(seqs)
if t % 500 == 0:
fp = fo[0].numpy().argmax(axis=1) #batch里第一句 只剩【timestep,dim】
bp = bo[0].numpy().argmax(axis=1)
t1 = time.time()
print(
"\n\nstep: ", t,
"| time: %.2f" % (t1 - t0),
"| loss: %.3f" % loss.numpy(),
"\n| tgt: ", " ".join([data.i2v[i] for i in seqs[0] if i != data.pad_id]),
"\n| f_prd: ", " ".join([data.i2v[i] for i in fp if i != data.pad_id]),
"\n| b_prd: ", " ".join([data.i2v[i] for i in bp if i != data.pad_id]),
)
t0 = t1
os.makedirs("./visual/models/elmo", exist_ok=True)
model.save_weights("./visual/models/elmo/model.ckpt")
train(model, data, 10000)
利用EMLo得到词向量
def export_w2v(model, data):
model.load_weights("./visual/models/elmo/model.ckpt")
emb = model.get_emb(data.sample(4))
print(emb)
if __name__ == "__main__":
data = MRPCSingle("./MRPC", rows=2000)
UNITS = 256
N_LAYERS = 2
BATCH_SIZE = 16
LEARNING_RATE = 2e-3
mod = ELMo(data.num_word, emb_dim=UNITS, units=UNITS, n_layers=N_LAYERS, lr=LEARNING_RATE)
export_w2v(mod, data)
结果来了
1 Physical GPUs, 1 Logical GPUs
num word: 12880
step: 500 | time: 48.72 | loss: 7.036
| tgt: <GO> based on having at least one of these symptoms , most students were hung over between three and <NUM> times in the past year . <SEP>
| f_prd: the the the , , , , , , , , , , , , , , , , , , , , , , , ,
| b_prd: the <NUM> the <NUM> the the <NUM> the the <NUM> the the <NUM> the the the the <NUM> the <NUM> <NUM> the the the <NUM> . <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP> <SEP>
step: 1000 | time: 48.50 | loss: 6.245
| tgt: <GO> he was eventually taken to london 's hammersmith hospital , where doctors regulated blair 's heart beat via electric shock . <SEP>
| f_prd: the , the the the the , the , , the the , , , the , , the , . <SEP>
| b_prd: <GO> , , the <NUM> the , the the <NUM> , , , , , the the <NUM> , , <NUM> .
step: 10000 | time: 46.24 | loss: 0.415
| tgt: <GO> avalon means the next windows os will support new styles of user interfaces and elements . <SEP>
| f_prd: the means the next windows os will support new styles of user interfaces and elements . <SEP>
| b_prd: <GO> avalon means the next windows longhorn will support new styles of user interfaces interface <NUM> .
step: 10500 | time: 46.23 | loss: 0.394
| tgt: <GO> o 'brien 's attorney , jordan green , declined to comment . <SEP>
| f_prd: the 'donnell 's attorney , jordan green , declined to comment . <SEP>
| b_prd: <GO> o 'brien 's attorney , jordan schindler officials declined for said .
layers shape= (4, 36, 512)
layers shape= (4, 36, 512)
layers shape= (4, 36, 512)
大概过了一万步训练后,loss 从9降到0.5,正向LSTM在句末的预测都会相对准确,反向LSTM在句首的预测也会相对准确了。这就说明模型真的在认真学习,并且学习得还好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









