







什么是语言模型
本文参考维基百科语言模型 language model
统计语言模型是一个单词序列上的概率分布,对于一个给定长度为m的序列,它可以为整个序列产生一个概率 P(w_1,w_2,…,w_m) 。其实就是想办法找到一个概率分布,它可以表示任意一个句子或序列出现的概率。
Unigram models
Unigram models也即一元文法模型,它是一种上下文无关模型。该模型仅仅考虑当前词本身出现的概率,而不考虑当前词的上下文环境。概率形式为 :
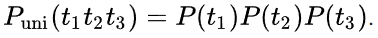
即一个句子出现的概率等于句子中每个单词概率乘积。
以一篇文档为例,每个单词的概率只取决于该单词本身在文档中的概率,而文档中所有词出现的概率和为1,每个词的概率可以用该词在文档中出现的频率来表示,如下表中
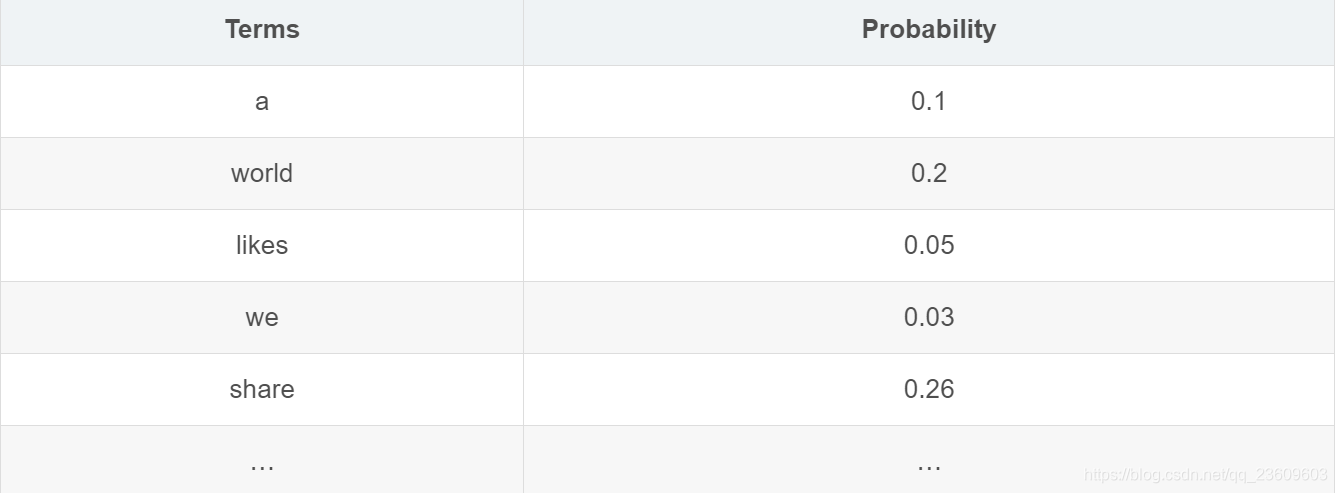
对于这篇文档中,所有概率和相加为1,即 :∑P(term)=1
n-gram模型
n-gram models也即n元语言模型,针对一个句子 w1,w2,w3…的概率表示如下:
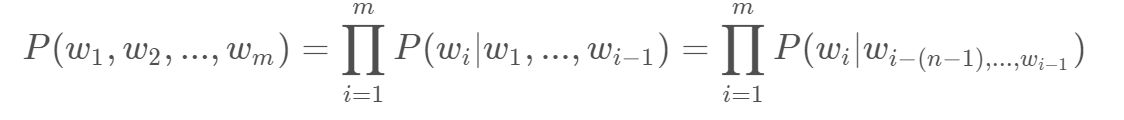 这里可以理解为当前词的概率与前面的n个词有关系,可以理解为上下文有关模型。
这里可以理解为当前词的概率与前面的n个词有关系,可以理解为上下文有关模型。
n-gram模型中的条件概率可以用词频来计算:
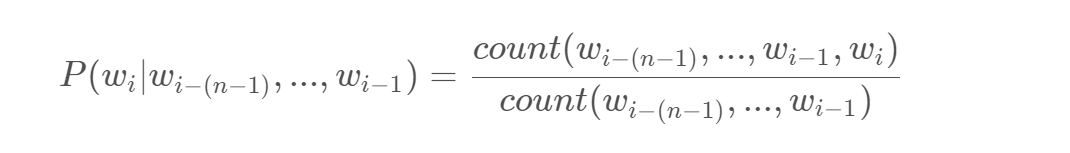
这里举个栗子:我们的原始文档是 doc = “我不想写代码了” ,经过中文分词处理后为 words = [“我”, “不想”, “写”, “代码”, “了”]。
那么产生原始文档doc的概率为:
P(我, 不想, 写, 代码, 了) =
P(我) x P(不想|我) x P(写|我, 不想) x P(代码|我, 不想, 写) x P (了|我, 不想, 写, 代码)
相乘的每个概率可以通过统计词频来获得:

多元的计算复杂,可以考虑二元bigram模型,当前的词只与它前面的一个词有关,这样求概率就会容易很多:
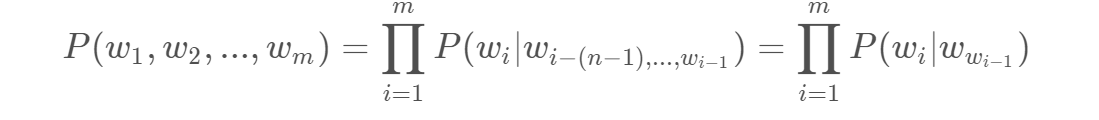 P(我, 不想, 写, 代码, 了) = P(我) x P(不想|我) x P(写|不想) x P(代码|写) x P (了|代码)
P(我, 不想, 写, 代码, 了) = P(我) x P(不想|我) x P(写|不想) x P(代码|写) x P (了|代码)
相乘的每个概率就更简单了:
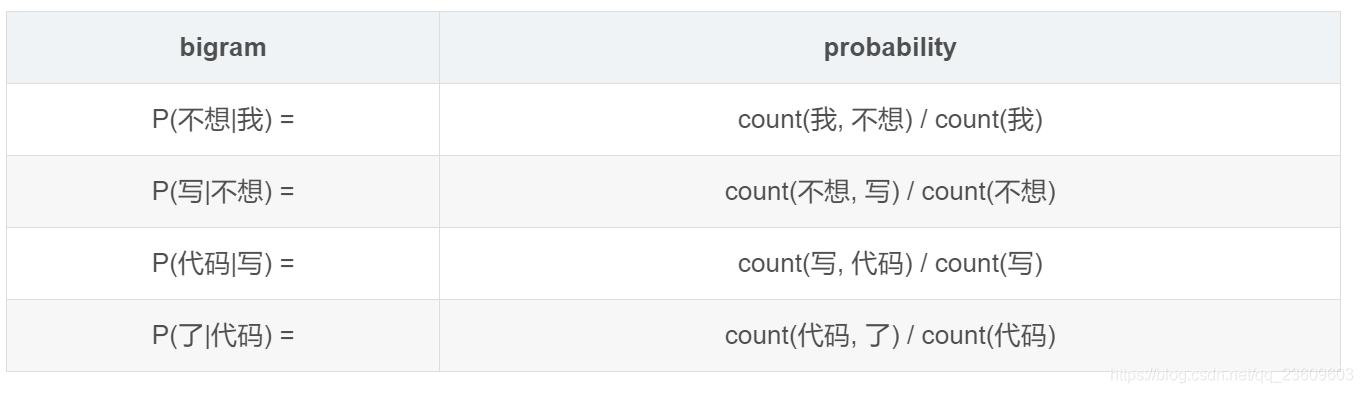
这样我们只需要计算语料中每个词出现的次数,以及每两个词出现的次数,就可以求上面的概率了。
这里是以二元模型说明,你也可以使用三元(trigram)、四元模型,方法类似不在多说。前面提到的 Unigram模型其实就是一元模型。
参考:https://blog.csdn.net/huanghaocs/article/details/77935556
https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html














 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









