






爬取东方财富网股票行情数据和资讯
这个需求源于我的一个练手项目
本篇博客参考:https://zhuanlan.zhihu.com/p/50099084
该博客介绍的东西本博客不做论述
使用技术:
- 语言:python
- 浏览器:Chrome
- 使用库:
- requests:发出请求获得源代码
- lxml.etree:解析html源代码
- re:正则匹配
- threading:多线程爬取
- time:多线程爬取时设置启动间隔,防止爬取线程过多
- json:解析json字符串为python字典
股票爬取简单分析
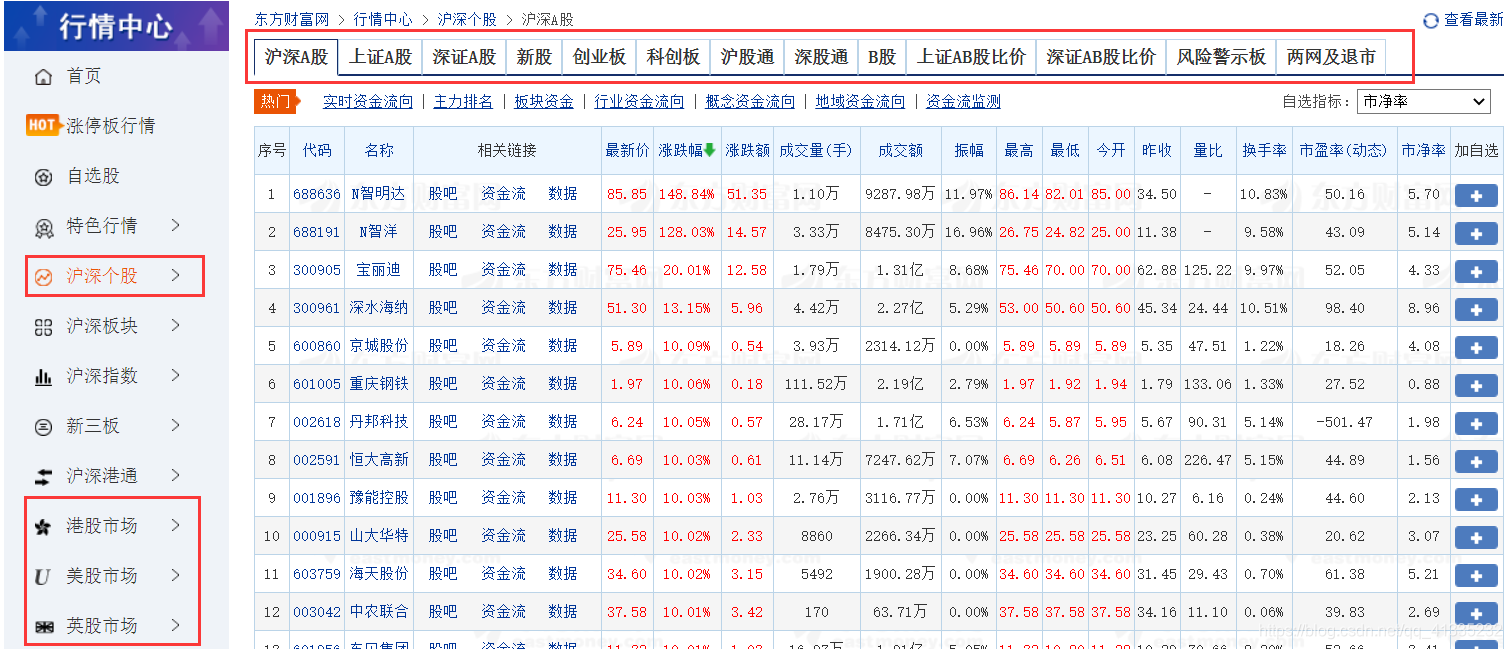
如上图,我们要爬取的是上面红框圈起来的股票数据,在F12>network页面获得所有的url后,得到以下的规律
首先,所有股票类型的有一个最关键的地方:不同的fs参数值。另外,可以发现沪深个股中的各类型都有一个共同的域名,而如果将沪深个股和港股、美股、英股作为大类,可以发现这些类型之间的域名都不同。
同时我们也应关注到,在每个类型的股票类里面是进行了分页显示的,
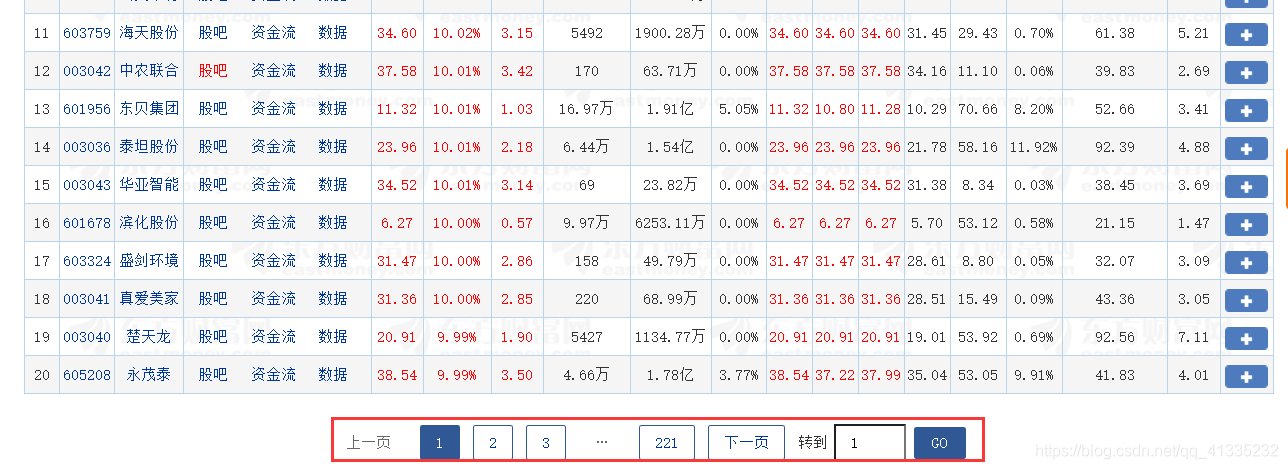
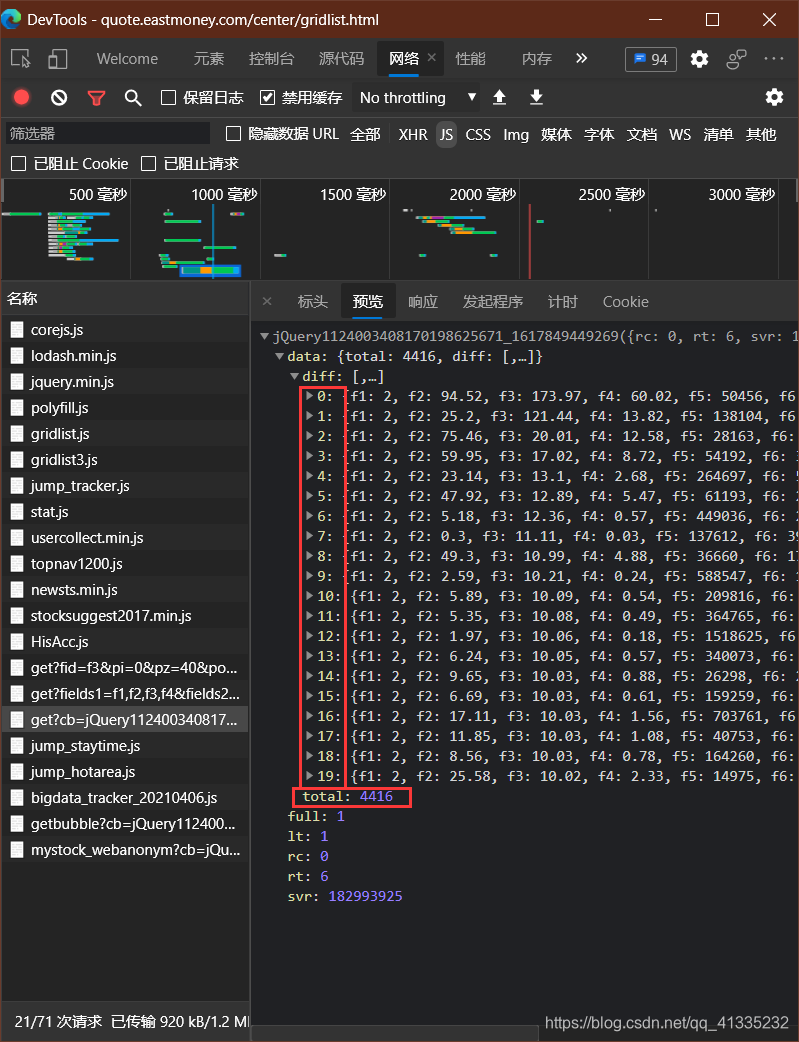
同时我们注意到所有url的参数里面都有一个pn和pz,并且经过测试后发现这确实是用于表示页数和页大小
所以现在我们了解了url的构成:即可得到以下的代码:
# 所有url的fs参数值
cmd = {
'沪深A股': "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
'上证A股': "m:1+t:2,m:1+t:23",
'深证A股': "m:0+t:6,m:0+t:13,m:0+t:80",
'新股': "m:0+f:8,m:1+f:8",
'中小板': "m:0+t:13",
'创业板': "m:0+t:80",
'科创板': "m:1+t:23",
'沪股通': "b:BK0707",
'深股通': "b:BK0804",
'B股': "m:0+t:7,m:1+t:3",
'上证AB股比价': "m:1+b:BK0498",
'深证AB股比价': "m:0+b:BK0498",
'风险警示板': "m:0+f:4,m:1+f:4",
'两网及退市': "m:0+s:3",
'港股': "",
'美股': "",
'英股': ""
}
def get_url(_type, page, _cmd):
if _type == "港股":
url = "http://66.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406357577502075646_1616143565610&pn=" + str(
page) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3," \
"m:128+t:4,m:128+t:1,m:128+t:2"
elif _type == "英股":
url = "http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124011375626195911481_1616142975767&pn=" + str(
page) + "&pz=20&po=1&fid=f3&np=1&ut=fa5fd1943c7b386f172d6893dbfba10b&fs=m:155+t:1,m:155+t:2,m:155+t:3," \
"m:156+t:1,m:156+t:2,m:156+t:5,m:156+t:6,m:156+t:7,m:156+t:8"
elif _type == "美股":
url = "http://8.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406676382329604522_1616140562794&pn=" + str(
page) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:105,m:106,m:107"
else:
url = "http://30.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124022574761343490946_1616140246053&pn=" + str(
page) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=" + _cmd
return url
完成数据源的解析,现在就是正式爬取了
首先引入需要的python库
import threading
import json
import datetime
import requests
import re
import pandas as pd
import time
from lxml import etree
定义一个爬虫方法
# 用get方法访问服务器并提取页面数据
def get_json(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/88.0.4324.104 Safari/537.36 "
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
data = re.findall(r'jQuery[_\d]*\((.*)\)', r.text)[0]
return json.loads(data)['data']
接下来我们要创建两个线程,一个类型线程CmdThread,一个页线程PageThread,实现沪深个股,港股,英股,美股的并发爬取以及个类型股票所有页面的并发爬取
在CmdThread中我们可以请求一个获得总的页数,然后根据页数创建对应数目的线程
# 类型线程
class CmdThread(threading.Thread):
def __init__(self, cmd_key, cmd_value):
super().__init__()
# 股票名称或类型
self.cmd_key = cmd_key
# 股票参数fs,用于形成爬虫url
self.cmd_value = cmd_value
def run(self) -> None:
# 首先爬取第一页获得总页数
url = get_url(self.cmd_key, 1, self.cmd_value)
total = get_json(url)['total']
thread_num = int(total / 20) + 1
# 添加相应页数的页线程
page_threads = []
for i in range(1, thread_num + 1):
url = get_url(self.cmd_key, i, self.cmd_value)
page_threads.append(PageThread(url, i, self.cmd_key, thread_num))
for thread in page_threads:
thread.start()
for thread in page_threads:
thread.join()
print("%s爬取完成" % self.cmd_key)
# 页线程
class PageThread(threading.Thread):
def __init__(self, url, page_index, _type, page_total):
super().__init__()
self.url = url
self.page_index = page_index
self._type = _type
self.page_total = page_total
def run(self):
data = get_json(self.url)
if data is not None and data['diff'] is not None:
df = pd.DataFrame(data['diff'])
columns = {"f12": "代码", "f14": "名称", "f2": "最新价格", "f3": "涨跌额", "f4": "涨跌幅", "f5": "成交量", "f6": "成交额",
"f7": "振幅", "f15": "最高", "f16": "最低",
"f8": "换手率", "f9": "市盈率", "f20": "总市值", "f23": "市净率", "f17": "今开", "f18": "昨收", "f10": "量比"}
df.rename(columns=columns, inplace=True)
df = df[columns.values()]
# 互斥锁,数据库写互斥
lock.acquire()
for index, row in df.iterrows():
temp_data = (row['代码'], row['名称'], row['最新价格'], row['涨跌额'], row['涨跌幅'],
row['成交量'], row['成交额'], row['振幅'], row['最高'], row['最低'],
row['换手率'], row['市盈率'], row['总市值'], row['市净率'], row['今开'],
row['昨收'], row['量比'], datetime.datetime.now().strftime('%Y-%m-%d'), self._type)
...
# 插入数据库操作
...
print("%s的爬取进度:%s/%s" % (self._type, self.page_index, self.page_total))
lock.release()
资讯和公告爬取简单分析
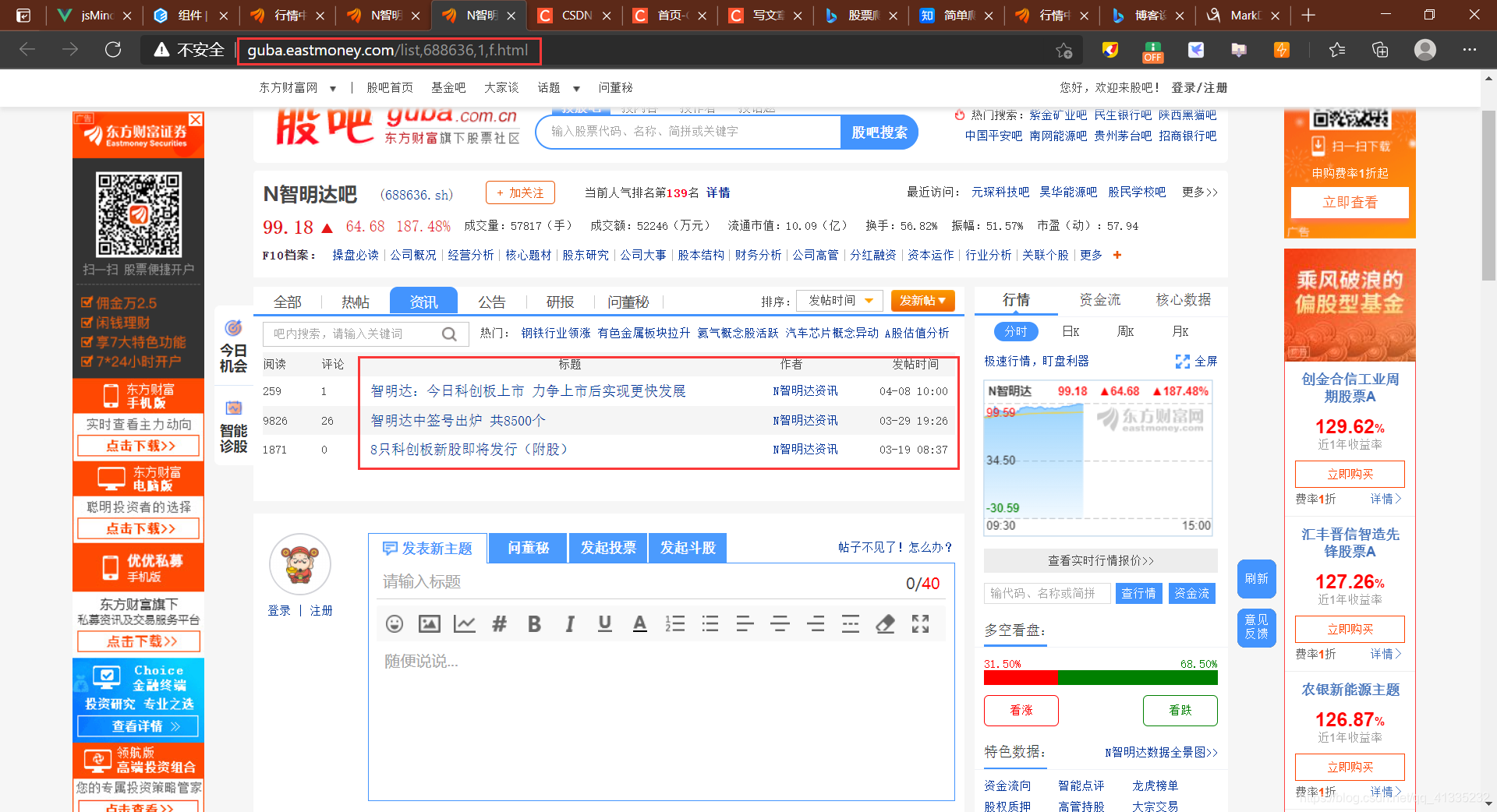
如上图,我们首先明确我们需要的数据是下方的红框(标题,作者,发布时间)
其次是url分析,很容看出来在url中的一个关键元素就是股票编号(部分股票资讯过多存在分页情况,对此不做处理,有兴趣可自行修改代码)
于是我们只要根据所有的股票编号构造出url,然后获得源代码,然后使用lxml进行解析,用xpath找到所需内容即可。
公告与资讯类似,在此不予赘述
接下来开始正式爬取
定义一个爬虫函数
def get_html_root(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/88.0.4324.104 Safari/537.36 "
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
return etree.HTML(r.text)
在这个函数中我们用到了lxml.etree的HTML解析,如果希望对lxml有更多了解请移步官方文档
# 定义一个专门爬取资讯和公告的类
class GrabNews:
def __init__(self):
self.gg_url = "http://guba.eastmoney.com/list,%s,3,f.html"
self.zx_url = "http://guba.eastmoney.com/list,%s,1,f.html"
self.codes = []
self.news_threads = []
# 获得搜索的股票编号
def get_codes(self):
# 查询数据库中所有的股票代码
# 设置长度为6的原因是只有code长度6的代码才可能有资讯
result = mysql.fetch("select distinct code from stock_db.stock where LENGTH(code)=6")
for item in result:
self.codes.append(item['code'])
def get_zx(self):
for code in self.codes:
self.news_threads.append(ZxThread(self.zx_url % code, code))
def get_gg(self):
for code in self.codes:
self.news_threads.append(GgThread(self.gg_url % code, code))
def get_start(self):
# 打乱thread顺序
random.shuffle(self.news_threads)
# 开启线程
for thread in self.news_threads:
thread.start()
time.sleep(1)
for thread in self.news_threads:
thread.join()
注意到上面的代码中我们使用了ZxThread和GgThread表示用于爬取资讯和公告的线程类
代码如下:
class ZxThread(threading.Thread):
def __init__(self, url, code):
super(ZxThread, self).__init__()
self.url = url
self.code = code
def run(self) -> None:
root = get_html_root(self.url)
urls = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[3]/a/@href')
titles = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[3]/a/text()')
authors = root.xpath(
'//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[4]/a/font/text()')
times = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[5]/text()')
for i in range(len(urls)):
lock.acquire()
try:
sql = "insert ignore into stock_db.zx(code,title,author,time,text,url) values (%s,%s,%s,%s,%s,%s)"
mysql.update(sql, (self.code, titles[i], authors[i], times[i], "", urls[i]))
print("%s资讯爬取进度:%s/%s" % (self.code, i, len(urls)))
except Exception:
pass
lock.release()
if len(urls) == 0:
print("%s股票没有资讯" % self.code)
else:
print("%s资讯爬取完成" % self.code)
class GgThread(threading.Thread):
def __init__(self, url, code):
super(GgThread, self).__init__()
self.url = url
self.code = code
def run(self) -> None:
root = get_html_root(self.url)
urls = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[3]/a/@href')
titles = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[3]/a/text()')
types = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[4]/text()')
times = root.xpath('//*[@id="articlelistnew"]/div[contains(@class,"articleh normal_post")]/span[5]/text()')
for i in range(len(urls)):
lock.acquire()
try:
sql = "insert ignore into stock_db.gg(code,title,type,time,text,url) values (%s,%s,%s,%s,%s,%s)"
mysql.update(sql, (self.code, titles[i], types[i], times[i], "", urls[i]))
print("%s公告爬取进度:%s/%s" % (self.code, i, len(urls)))
except Exception:
pass
lock.release()
if len(urls) == 0:
print("%s股票没有公告" % self.code)
else:
print("%s公告爬取完成" % self.code)
那么上面的代码中使用了lxml.etree提供的xpath路径解析,关于该路径的获取我们可以直接在devtools中复制获得
但是需要做一些修改,否则就只能获得一项数据,具体怎么修改,需要具有xpath的知识,需要了解xpath,可以参考https://www.runoob.com/xpath/xpath-tutorial.html
启动爬取:
grab = GrabNews()
grab.get_codes()
grab.get_zx()
grab.get_gg()
grab.get_start()
最后,其实我们通常还需要爬取这个资讯的内容,但是对于我的项目来说,短时间内爬取这个太过笨重了,从而改成了实时爬取的形式,即用户在访问到的时候才进行爬取,更多的东西没法展示了,就简单地给出这个爬取的代码吧
def get_zx_by_url(url):
print("http://guba.eastmoney.com" + url)
node = get_html_root("http://guba.eastmoney.com" + url)
try:
text = etree.tostring(node.xpath('//*[@id="zw_body"]')[0])
mysql.update("update stock_db.zx set text='%s' where url='%s'" % (bytes.decode(text), url), None)
return text
except IndexError:
try:
text = etree.tostring(node.xpath('//*[@id="zwconbody"]')[0])
mysql.update("update stock_db.zx set text='%s' where url='%s'" % (bytes.decode(text), url), None)
return text
except Exception as e:
print(e)
return "地址无效"
爬虫总结:
根据网页加载方式决定爬取方式(源代码解析,控制台抓包解析json)
前者可以使用lxml.etree(BeautifulSoup也可以,看个人选择吧),使用xpath或其它函数进行路径访问获得数据
后者主要就是控制台找数据,解析url的构成,解析json数据格式。如果要爬取的url中含有随机串,同时url数目很多,那就没办法了


















 6704
6704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











