







目录
零:项目案例:
1:将项目放入桌面,使用pycharm打开。
2: 使用python3 manager.py migrate, python3 manager.py makemigrations ,进行迁移建表。
3:将sql文件放在桌面上,使用mysql -uroot -pmysql -D 数据库名 < sql文件名进行数据的恢复。
1: 定义模型类的序列化器:
-
规则: 名字必须相同,类型要比模型类更加严格。
-
例如: 定义一个模型类的序列化器:
这是我们的模型类:如何定义序列化器呢?
#定义图书模型类BookInfo class BookInfo(models.Model): btitle = models.CharField(max_length=20, verbose_name='名称') bpub_date = models.DateField(verbose_name='发布日期') bread = models.IntegerField(default=0, verbose_name='阅读量') bcomment = models.IntegerField(default=0, verbose_name='评论量') is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True) # heros隐藏字段,代表与当前书本关联的多个从表HeroInfo模型类对象 class Meta: db_table = 'tb_books' # 指明数据库表名 verbose_name = '图书' # 在admin站点中显示的名称 verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self): """定义每个数据对象的显示信息""" return self.btitle# 1: 在rest_framework 中导入serializers from rest_framework import serializers # 2: 定义模型类,继承于serializers.Serializer class BookInfoSerializers(serializers.Serializer): # 3: 里面的类型仿照模型类进行设计 btitle = serializers.CharField() bpub_date = serializers.DateField() bread = serializers.IntegerField() bcomment = serializers.IntegerField() is_delete = serializers.BooleanField() image = serializers.ImageField()
2: 序列化返回多个对象,序列化返回单一对象:
-
序列化返回单一对象:(获取模型类对象—>实例化序列化器对象 —> 获取序列化结果)
>>> # 1: 获取模型类对象 >>> book = BookInfo.objects.all()[0] >>> # 2: 实例化序列化器对象 >>> bs = BookInfoSerializers(instance = book) >>> # 3: 获取序列化结果 >>> bs.data {'bpub_date': '1980-05-01', 'bcomment': 34, 'btitle': '射雕英雄传', 'is_delete': False, 'bread': 12, 'image': None} -
返回多个对象:(实例对象是个结果集的时候,序列化器要加many = True)
>>> books = BookInfo.objects.all() >>> bs = BookInfoSerializers(instance = books, many = True) >>> bs.data [OrderedDict([('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False), ('image', None)]), OrderedDict([('btitle', '天龙八部'), ('bpub_date', '1'), ('bread', 36), ('bcomment', 40), ('is_delete', False), ('image', None)]), OrderedDict([('btitle', '笑傲江湖'), ('bpub_date', '1995-12-24'), ('bread', 20), ('bcomment', 80), ('is_delete', False'image', None)]), OrderedDict([('btitle', '雪山飞狐'), ('bpub_date', '1987-11-11'), ('bread', 58), ('bcomment', 24), ('is_delete', False), ('image', None)])] -
注意序列化器得到的是个字典:
# 获取其中一个有序字典对象 >>> b1 = bs.data[0] >>> b1 OrderedDict([('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False), ('image', None)]) # 字典取值 >>> b1.get("btitle") '射雕英雄传'
3:模型类隐藏字段如何映射?
-
1: 主键字段,在序列化器中写上就会映射过来。
序列化器中增加这个字段
# 4: 主键字段的映射 id = serializers.IntegerField()再次执行看看是否映射过来?
>>> from BooksTest.models import * >>> from BooksTest.serializers import * >>> books = BookInfo.objects.all() >>> bs = BookInfoSerializers(instance = books, many = True) >>> bs.data[0] OrderedDict([('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False), ('image', None), ('id', 1)]) -
2: 主表隐藏字段序列化—序列化成从表的主键:
主表隐藏字段的序列化器这样写:
# 5: 序列化成关联字段的主键 heros = serializers.PrimaryKeyRelatedField(queryset= HeroInfo.objects.all(), many=True)效果:从表的主键会在序列化结果中。(‘heros’, [1, 2, 3, 4, 5])
>>> from BooksTest.models import * >>> from BooksTest.serializers import * >>> books = BookInfo.objects.all() >>> bs = BookInfoSerializers(instance = books, many = True) >>> bs.data[0] OrderedDict([('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False), ('image', None), ('id', 1), ('heros', [1, 2, 3, 4, 5])]) -
3: 序列化成关联的名字:
主表隐藏字段的序列化器这样写:many= True的原因是被关联序列化是多条记录, 我们发现被关联序列化成了名字。
# 6: 序列化成主键的名字 heros = serializers.StringRelatedField(many=True)>>> from BooksTest.models import * >>> from BooksTest.serializers import * >>> books = BookInfo.objects.all() >>> bs = BookInfoSerializers(instance = books, many = True) >>> bs.data[0] OrderedDict([('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False), ('image', None), ('id', 1), ('heros', ['郭靖', '黄蓉', '黄药师', '欧阳锋', '梅超风'])]) -
4:序列化成关联的所有字段:
主表隐藏字段的序列化器这样写:
在当前序列化器前面定义一个序列化器:(注意HeroInfoSerializers必须在前面)
class HeroInfoSerializers(serializers.Serializer): hname = serializers.CharField() hgenser = serializers.IntegerField() hcomment = serializers.CharField() is_delete = serializers.BooleanField() class BookInfoSerializers(serializers.Serializer): ... # 7: 序列化成被关联的所有字段 heros = HeroInfoSerializers(many=True)>>> from BooksTest.models import * >>> from BooksTest.serializers import * >>> books = BookInfo.objects.all() >>> bs = BookInfoSerializers(instance = books, many = True) >>> bs.data[0] OrderedDict([('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False), ('image', None), ('id', 1), ('heros', [OrderedDict([('hname', '郭靖'), ('', 1), ('hcomment', '降龙十八掌'), ('is_delete', False)]), OrderedDict([('hname', '黄蓉'), ('hgender', 0), ('hcomment', '打狗棍法'), ('is_delete', False)]), OrderedDict([('hname', '黄药师'), ('hgecomment', '弹指神通'), ('is_delete', False)]), OrderedDict([('hname', '欧阳锋'), ('hgender', 1), ('hcomment', '蛤蟆功'), ('is_delete', False)]), OrderedDict([('hname', '梅超风'), ('hgender', 0), (九阴白骨爪'), ('is_delete', False)])])]) -
5:主表隐藏字段可以查询从表信息
现在HeroInfo有个隐藏字段:related_name = “heros”,也就是表示Heroinfo是个从表,BookInfo是个主表,主表中有一个隐藏字段heros,这个字段可以找到主表关联的所有从表对象。
# 利用隐藏字段查询从表字段 >>> from books.models import * >>> from books.serializers import * >>> book = BookInfo.objects.get(pk=1) >>> book <BookInfo: 射雕英雄传> >>> book.heros.all() <QuerySet [<HeroInfo: 郭靖>, <HeroInfo: 黄蓉>, <HeroInfo: 黄药师>, <HeroInfo: 欧阳锋>, <HeroInfo: 梅超风>]>
4: 序列化器的约束(用于反序列化的时候)
-
1: 序列化器的约束要根据模型类的约束,只能比序列化器的约束更加严格。
-
案例:这是图书的模型类,我们分析序列化器的约束是什么?
- btitle : max_length=20
- bpub_date: required = True
- bread : required = False , default=0
- is_delete : default=False
- image : required = False
#定义图书模型类BookInfo class BookInfo(models.Model): btitle = models.CharField(max_length=20, verbose_name='名称') bpub_date = models.DateField(verbose_name='发布日期') bread = models.IntegerField(default=0, verbose_name='阅读量') bcomment = models.IntegerField(default=0, verbose_name='评论量') is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True) # heros隐藏字段,代表与当前书本关联的多个从表HeroInfo模型类对象 class Meta: db_table = 'tb_books' # 指明数据库表名 verbose_name = '图书' # 在admin站点中显示的名称 verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self): """定义每个数据对象的显示信息""" return self.btitleclass BookInfoSerializers(serializers.Serializer): # 3: 里面的类型仿照模型类进行设计 btitle = serializers.CharField(max_length=20, required= True) bpub_date = serializers.DateField(required=True) bread = serializers.IntegerField(default=0, required=False) bcomment = serializers.IntegerField(default=0, required=False) is_delete = serializers.BooleanField(default=False, required=False) image = serializers.ImageField(required=False) # 4: 主键字段的映射: read_only = True 表示不参与反序列化 id = serializers.IntegerField(read_only=True)

-
2:自定义校验的三种方式:
-
1: 自己定义一个函数, 在序列化器的约束中增加: validators = [函数名];
class BookInfoSerializers(serializers.Serializer): def check_btitle(value): if 'django' not in value: raise serializers.ValidationError('这不是一本关于Django的书') # 3: 里面的类型仿照模型类进行设计 btitle = serializers.CharField(max_length=20, required= True, validators=[check_btitle]) -
2: 自定义校验之
validate_<字段名>:btitle = serializers.CharField(max_length=20, required= True) def validate_btitle(self, value): if 'django' not in value: raise serializers.ValidationError('这不是一本关于Django的书') return value # 注意必须返回 -
3:在validate函数中直接进行校验:
btitle = serializers.CharField(max_length=20, required= True) def validate(self, attrs): btitle = attrs.get('btitle') if 'django' not in btitle: raise serializers.ValidationError('这不是一本关于Django的书') return attrs # 必须返回有效数据 -
4: 校验的流程: 先经过序列化器的约束和类型校验---->自定义函数校验 ----->字段名函数校验---->validate函数校验。
-
-
3: 反序列化校验的流程:
-
4: 反序列化新建:
-
反序列化新建的时候如果是被关联主键则被反序列化成被关联的对象。
注意: 反序列化的时候尽量不要携带隐藏字段,隐藏字段多用于序列化的时候。
class BookInfoSerializers(serializers.Serializer): btitle = serializers.CharField(max_length=20, required= True) bpub_date = serializers.DateField(required=True) bread = serializers.IntegerField(default=0, required=False) bcomment = serializers.IntegerField(default=0, required=False) is_delete = serializers.BooleanField(default=False, required=False) image = serializers.ImageField(required=False) id = serializers.IntegerField(read_only=True)>>> book_info = {'btitle': '妞妞列传', 'bpub_date': '1998-10-09', 'heros' : [1, 2]} >>> bs = BookInfoSerializers(data = book_info) >>> bs.is_valid() True >>> bs.validated_data OrderedDict([('btitle', '妞妞列传'), ('bpub_date', datetime.date(1998, 10, 9)), ('bread', 0), ('bcomment', 0), ('is_delete', False), ('heros', [<HeroInfo: 郭靖>, <HeroInfo: 黄蓉>])]) # 此时发现,被反序列化成[<HeroInfo: 郭靖>, <HeroInfo: 黄蓉>] -
需要重写序列化器中的create方法:
# 被序列化校验完成的数据会传到validated_data中来 def create(self, validated_data): instance = BookInfo.objects.create(** validated_data) return instance>>> from BooksTest.models import * >>> from BooksTest.serializers import * >>> book = {'btitle': 'Django姐姐', 'bpub_date': '1998-10-08'} >>> bs = BookInfoSerializers(data = book) >>> bs.is_valid() True >>> bs.save() <BookInfo: Django姐姐> >>> bs.data {'bread': 0, 'btitle': 'Django姐姐', 'is_delete': False, 'image': None, 'id': 5, 'bpub_date': '1998-10-08', 'bcomment': 0}
-
-
5: 反序列化更新(需要在序列化器中重写update方法):
-
全更新:必要字段必传必须校验
重写序列化器的update方法:
# 被序列化校验完成的数据会传到validated_data中来,instance是指的被更新的对象 def update(self, instance, validated_data): for filed, value in validated_data.items(): # setattr 根据键对实例属性赋值 setattr(instance, filed, value) # 保存一下 instance.save() return instance>>> from BooksTest.models import * >>> from BooksTest.serializers import * >>> book = BookInfo.objects.get(pk = 1) >>> book_info = {'btitle': '妹妹的天下', 'bpub_date': '2020-10-09'} >>> bs = BookInfoSerializers(instance = book, data = book_info) >>> bs.is_valid() True >>> bs.save() <BookInfo: 妹妹的天下> >>> bs.data {'bread': 0, 'is_delete': False, 'btitle': '妹妹的天下', 'id': 1, 'bpub_date': '2020-10-09', 'image': None, 'bcomment': 0} -
部分更新:传什么校验什么?
>>> book_info = {'btitle':'或灵儿'} >>> bs = BookInfoSerializers(instance = book, data = book_info, partial = True) >>> bs.is_valid() True >>> bs.save() <BookInfo: 或灵儿> >>> bs.data {'bread': 0, 'is_delete': False, 'btitle': '或灵儿', 'id': 1, 'bpub_date': '2020-10-09', 'image': None, 'bcomment': 0}
-
-
6: save方法传递关键字参数:
-
传递的关键字参数,会被合并到
validated_data有效数据中,作用于create和update方法! -
如果前端没有传递给我们的字段,我们向新建或者更新的时候手动设置默认值,这个时候就需要save方法了。
>>> book = {"btitle": "善文正传", "bpub_date": "1998-10-9"} >>> bs = BookInfoSerializers(data = book) >>> bs.is_valid() True >>> bs.save(bread= 100, bcomment= 200) <BookInfo: 善文正传>
-
一:序列化:
1: 区分进入交互环境的不同:
python3 manager.py shell : 进入Django的环境
python3 shell : 进入python3的交互终端
2: 序列化对象如果是多个,使用many=True
book = BookInfo.objects.all()# 多个
bs = BookInfoSerializers(instance=book,many=True)# 使用many=True
3: 从表有关联字段related_name = “heros”,主表对象.heros.all()可以查看,当前主表关联的所有从表对象。
4:主表序列化时, 关联的隐藏字段如何序列化?
# 1: 序列化成从表的主键,如果一个主表对象关联多个从表对象,加many=True
heros = serializers.PrimaryKeyRelatedField(
queryset=HeroInfo.objects.all(),
many=True
)
# 2:序列化成从表的名字,如果一个主表对象关联多个从表对象,加many=True
heros = serializers.StringRelatedField(many=True)
# 3: 序列化从表的指定字段,如果一个主表对象关联多个从表对象,加many=True:得从表的一个列表套元组
# 先定义从表的序列化器,不需要序列化关联主表的字段。
heros = HeroInfoSerialiser(many=True)
5:从表序列化时,外键字段如何序列化呢?
# 1:序列化成主表的主键,从表关联一个主表对象,不用加many=True
hbook = serializers.PrimaryKeyRelatedField(
queryset=BookInfo.objects.all()
)
# 2: 序列化成主表对象的名字,从表关联一个主表对象,不用加many=True
hbook = serializers.StringRelatedField()
# 3: 序列化主表的指定的字段,从表关联一个主表对象,不用加many=True
hbook = BookInfoSerializers()
6: 关联序列化出现的问题:
1: 被关联的序列化器一定要在这个序列化器前面定义。
2:调用关联的序列化器时定要加括号。
二: 反序列化:
1: 反序列化校验流程:
# 1: 前端传递字典
hero = {'hname': "renshanwen"}
# 2: 进行反序列化
hs = HeroInfoSerialziers(data= hero)
# 3: 常规校验
hs.is_valid()
# 4: 自定义校验: 看下面的三种自定义校验
# 5: 创建create或者update方法
# 6: 保存
hs.save()
2: 三种自定义校验:要求传入英雄的名字必须以’任’开头。
方案一: 字段括号内使用validators=[方法名], 类外面定义一个check_字段名的函数进行校验。
def check_hname(value):
if "任" not in value:
raise serializers.ValidationError("英雄的名字居然没有任,还算英雄吗?")
hname = serializers.CharField(required=True,max_length=20, validators=[check_hname])
方案二: 类内部定义函数: validate_字段名(self,value) , 这个函数必须有返回值value。
def validate_hname(self, value):
if '善' not in value:
raise serializers.ValidationError("名字中没有善,也配叫英雄?")
return value
方案三:类内部定义 : validate(self, attrs) , 这个函数必须有返回值value。
def validate(self, attrs):
hname = attrs.get('hname')
if '文' not in hname:
raise serializers.ValidationError("名字中没有文,也配英雄?")
return attrs
3: 序列化器中的create方法和update方法:
为什么要重写序列化器中的create(update)方法??
答:因为我的序列化器继承于serializers.Serializer,而Serializer继承于BaseSerializers,BaseSerializers并没有实现只是定义了这个两个方法,所以需要子类继承重写,才能完成新建和更新。
# 传递进来有效数据,返回模型类对象
def create(self, validated_data):
instance = HeroInfo.objects.create(**validated_data)
return instance
# 传入被更新对象和校验之后的数据,返回更新后的模型类对象。
def update(self, instance, validated_data):
# instance指的是被更新的对象
# validated_data 是传入的要更新的数据
for key, value in validated_data.items():
setattr(instance, key, value)
instance.save()
return instance
4: setattr() 与getattr()的使用:
为什么要使用setattr进行更新??
答: 由于我们不知道传入的校验字段有哪些,所以不能根据字段进行一一修改,所以才采用setattr进行更新。
# setattr(对象,key,value)函数的作用: 给一个对象的某个属性设置值
# 例如:
setattr(hero, 'hname', '任善文')
5: 反序列化的注意事项:
1:一定要把主键设置成readonly = True
2: 外键字段不可省略。
6: PrimaryKeyRelatedField作用
1: 作用于序列化的时候,返回的数据是被关联模型类的主键。
2:作用于反序列化的时候, 把主键反序列化成关联的对象。(这也是queryset的作用:根据主键,转换成模型类对象)
7: 全更新和部分更新:
反序列化时传入partial = True: 传什么校验什么。
Serializer(instance=模型类对象,data=参数,partial=True)
三:模型类序列化器
1: 模型类序列化器与序列化器的区别(优点):
答: 模型类序列化器封装了,模型类字段的映射,和create方法update方法。
2: 使用格式
class 序列化器名(serializers.ModelSerialiser):
# 将来要更新或者新建的模型类
model = 模型类
# 自动映射除了外键字段的所有字段
fields = "__all__"
# 指定字段映射
fields = ['字段1','字段2'...]
# 指定除XXX字段,其余的映射
exclude = ['字段1', '字段2'...]
# 调整映射后的属性
extra_kwargs = {
'字段1': {'属性1':'属性值', '属性2': '属性值'},
'字段1': {'属性1':'属性值', '属性2': '属性值'}
}
# 设置只能参与序列化的字段
read_only_fields = ['id']
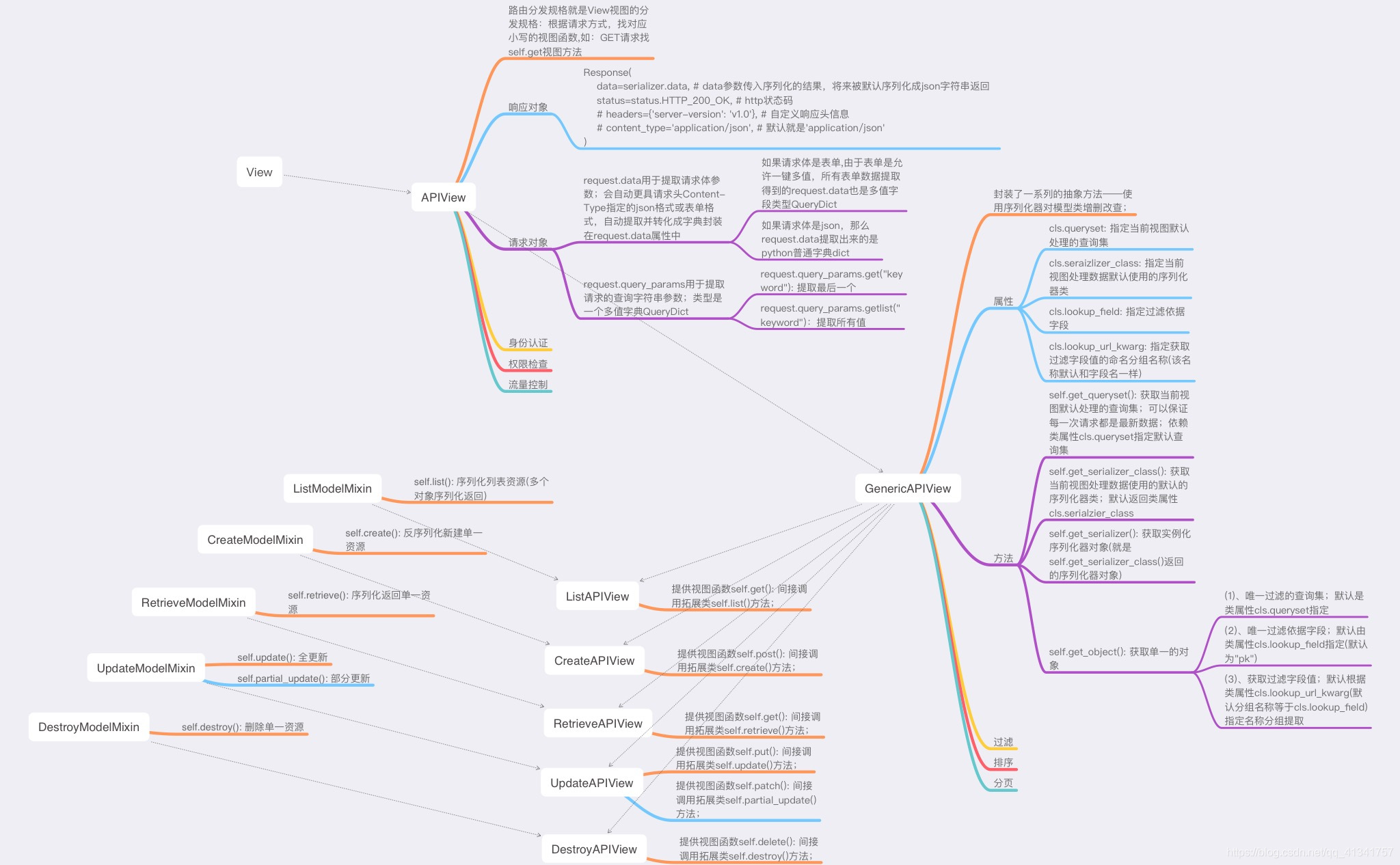
四:APIView
1: APIView的作用:
- 继承于View,是DRF视图的基类。
- 他在View的基础上,首先延续了,View视图的路由匹配规则:即get请求寻找get方法。
- 自己封装了属于DRF的请求和响应。例如:request.data 和request.query_params
2: APIView实现5大逻辑,代码展示:
re_path(r"^hero/$", BooksInfoView.as_view()),
re_path(r"^hero/(?P<pk>\d+)/$", BookInfoView.as_view()),
class BooksInfoView(APIView):
# 序列化返回多个资源
def get(self, request):
# 1: 获取查询集对象
books = BookInfo.objects.all()
# 2: 进行序列化
bs = BookInfoSerializers(instance=books, many=True)
# 3: 序列化返回
return Response(data=bs.data, status=status.HTTP_200_OK)
# 反序列化新建资源
def post(self, request):
# 1: 进行反序列化
bs = BookInfoSerializers(data=request.data)
# 2: 进行校验
if not bs.is_valid():
return Response(data='校验失败', status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
bs.save()
return Response(data=bs.data, status=status.HTTP_200_OK)
class BookInfoView(APIView):
# 序列化返回单一资源
def get(self, request, pk):
# 1: 获取查询对象
book = BookInfo.objects.get(pk=pk)
# 2: 进行序列化
bs = BookInfoSerializers(instance=book)
return Response(data=bs.data, status=status.HTTP_200_OK)
# 反序列化更新单一资源(全更新)
def post(self, request, pk):
# 1: 获取更新对象
try:
book = BookInfo.objects.get(pk=pk)
except Exception as e:
return Response(data="数据库中没有数据", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
# 1: 进行反序列化
bs = BookInfoSerializers(instance=book, data=request.data)
# 2: 进行校验
if not bs.is_valid():
return Response(data='校验失败', status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
bs.save()
return Response(data=bs.data, status=status.HTTP_200_OK)
# 反序列化更新单一资源(部分更新)
def patch(self, request, pk):
# 1: 获取更新对象
try:
book = BookInfo.objects.get(pk=pk)
except Exception as e:
return Response(data="数据库中没有数据", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
# 1: 进行反序列化
bs = BookInfoSerializers(instance=book, data=request.data, partial=True)
# 2: 进行校验
if not bs.is_valid():
return Response(data='校验失败', status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
bs.save()
return Response(data=bs.data, status=status.HTTP_200_OK)
# 反序列化删除单一资源
def delete(self, request, pk):
try:
book = BookInfo.objects.get(pk=pk)
except Exception as e:
return Response(data='您要删除的数据不存在', status= status.HTTP_500_INTERNAL_SERVER_ERROR)
book.delete()
return Response(data="删除成功", status= status.HTTP_200_OK)
3: 注意点:
- request.query_params⽤于提取请求的查询字符串参数;类型是⼀个多值字典QueryDict。
request.query_params.get(“keyword”): 提取最后⼀个。
五:GenericAPIView
1: GenericAPIView的作用:
- 封装了获取模型类和列化器的属性和方法
- 4大属性:queryset, serializer_class, lookup_field, lookup_url_kwargs
- 4大方法: get_queryset(), get_serializer_class(), get_serializer(), get_object()
- 对于单一资源的操作,获取对象get_object已经封装好了,只需要调用即可。
2: GenericAPIView实现5大逻辑,代码展示:
class BooksInfoView(GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
# 序列化返回多个资源
def get(self, request):
# 1: 获取查询集对象
books = self.get_queryset()
# 2: 进行序列化
bs = self.get_serializer(instance=books, many=True)
# 3: 序列化返回
return Response(data=bs.data, status= status.HTTP_200_OK)
# 反序列化创建资源
def post(self, request):
# 1: 进行反序列化
bs = self.get_serializer(data= request.data)
# 2: 进行校验
if not bs.is_valid():
return Response(data='校验失败', status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
bs.save()
return Response(data=bs.data, status=status.HTTP_200_OK)
class BookInfoView(GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
lookup_field = "pk"
lookup_url_kwarg = "pk"
# 序列化获取单一资源
def get(self, request, pk):
# 1: 获取查询集对象
book = self.get_object()
# 2: 进行序列化
bs = self.get_serializer(instance=book)
# 3: 序列化返回
return Response(data=bs.data, status=status.HTTP_200_OK)
# 反序列化更新单一资源(全更新)
def post(self, request, pk):
try:
# 1: 获取查询集对象
book = self.get_object()
except Exception as e:
return Response(data="查询的对象不存在", status= status.HTTP_500_INTERNAL_SERVER_ERROR)
# 2: 进行反序列化
bs = self.get_serializer(instance=book, data=request.data)
# 3: 进行校验
if not bs.is_valid():
return Response(data="校验失败", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
bs.save()
return Response(data=bs.data, status= status.HTTP_200_OK)
# 反序列化更新单一资源(部分更新)
def patch(self, request, pk):
try:
# 1: 获取查询集对象
book = self.get_object()
except Exception as e:
return Response(data="查询的对象不存在", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
# 2: 进行反序列化
bs = self.get_serializer(instance=book, data=request.data, partial=True)
# 3: 进行校验
if not bs.is_valid():
return Response(data="校验失败", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
bs.save()
return Response(data=bs.data, status= status.HTTP_200_OK)
def delete(self, request, pk):
# 1: 获取模型类对象
try:
book = self.get_object()
except Exception as e:
return Response(data="查询对象数据库中不存在", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
# 2: 删除
try:
book.delete()
except Exception as e:
return Response(data="删除失败", status=status.HTTP_500_INTERNAL_SERVER_ERROR)
return Response(data="删除成功", status= status.HTTP_200_OK)
六:五大拓展类
1: 五大拓展类的作用:
- 将序列化和反序列化流程封装成自己的方法
- 可以将原生的任何方法转换成拓展类的方法,比如 反序列化更新单一资源(全更新),可以用post,也可以用patch。
2: 使用5大拓展类实现5大逻辑,代码展示:
class BooksInfoView(GenericAPIView, ListModelMixin, CreateModelMixin):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
# 序列化返回多个资源
def get(self, request):
return self.list(request)
# 反序列化新建资源
def post(self, request):
return self.create(request)
class BookInfoView(GenericAPIView, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
lookup_field = 'pk'
lookup_url_kwarg = 'pk'
# 序列化返回单一资源
def get(self, request, pk):
return self.retrieve(request, pk)
# 反序列化更新单一资源(全更新)
def post(self, request, pk):
return self.update(request, pk)
# 反序列化更新单一资源(部分更新)
def patch(self, request, pk):
return self.partial_update(request, pk)
# 反序列化删除单一资源
def delete(self, request, pk):
return self.destroy(request, pk)
七: 五大子类
1: 五大子类的作用:
- 继承了5大拓展类和GenericAPIView
- get—>list post---->create
- get---->retrieve put—>update delete—>destroy
2: 使用5大子类实现5大逻辑,代码展示:
class BooksInfoView(ListAPIView, CreateAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
class BookInfoView(RetrieveAPIView,UpdateAPIView, DestroyAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
lookup_field = 'pk'
lookup_url_kwarg = 'pk'
3: 注意的点:
- UpdateAPIView 将put—>update, patch—>partial_update
八:ViewSetMixin
1: 自定义视图集的作用:
- 五大子类固定了转换,再继承ViewSetMixin就可以指定其他的转换了。
2: 自定义视图集的使用:案例:让post方法找自定义的findlist方法
# 视图
class BooksInfoView(ViewSetMixin, GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
def mylist(self, request, *args, **kwargs):
books = self.get_queryset()
serializer = self.get_serializer(instance=books, many=True)
return Response(data=serializer.data)
# 路由:
re_path(r"^hero/$", BooksInfoView.as_view({'get': 'mylist'})),
九:ModelViewSet
1: modelViewSet的作用:(五大子类和自定义视图集的合体)
- 继承5大拓展类
- 继承GenericViewSet。
- GenericViewSet继承于ViewSetMixin和GenericView。
2: 使用模型类视图集来实现5大逻辑。
# 视图
class BookInfoView(ModelViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializers
# 路由
re_path(r"^hero/$", BookInfoView.as_view({'get': 'list', 'post': 'create'})),
re_path(r"^hero/(?P<pk>\d+)/$", BookInfoView.as_view({'get': 'retrieve', 'put': 'update', 'patch': 'partial_update', 'delete': 'destroy'})),
3: 模型类视图集自定义转换:
# 路由
re_path(r"^books/latest/$", BookView.as_view({"get": "latest"}))
# 视图
class BookView(ModelViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoModelSerializers
def latest(self, request, *args, **kwargs):
book = self.queryset.latest('bpub_date')
serializers = self.get_serializer(instance=book)
return Response(data=serializers.data)
4: 自动映射路由:SimpleRouter或者DefaultRouter
# 自动映射5大逻辑
# 1: 实例化router对象
router = SimpleRouter()
# 2: 指定映射规则: 前缀,视图,路由反解析。
router.register(prefix='book', viewset=BookInfoView, base_name='books')
# 3: 追加进去: router.urls就是一个路由列表
urlpatterns.extend(router.urls)
映射我们自己定义的视图:需要在视图上增加装饰器。
@action(methods=['get'], detail=False, url_path="latest")
def mylist(self, request, *args, **kwargs):
books = self.queryset.latest('bpub_date')
serializer = self.get_serializer(instance=books)
return Response(data=serializer.data)
# 相当于
re_path(r"^hero/list/$", BooksInfoView.as_view({'get': 'mylist'})),
- methods : 请求的方式
- url_path: 路径 的尾缀,如果不写默认是方法的名字。
- detail : 如果是True:
路径= 前缀(prefix)+ pk正则分组 + 尾缀 - 如果是Fase:
路径= 前缀 + 尾缀
十:身份认证
1: 身份认证的注意事项:
- 分为:基本身份认证后端和Session身份认证后端。BasicAuthentication(一般测试才用),SessionAuthentication(最常用)
- 身份认证后端只作用于DRF视图,对于Django视图不起作用。(原因配置文件是在REST_FRAMEWORK中配置的)
- 全局配置:在REST_FRAMEWORK配置,对所有的DRF视图都起作用。
- 局部配置:在DRF视图中配置,对当前视图起作用。
- SessionAuthentication的原理:在DRF视图处理一个请求的过程中,会提取cookie中的sessionId,并在缓存中读取用户信息。
- 多个身份认证后端,只要有一个通过就算认证成功。
2: 身份认证的配置:
# 1: 全局身份认证配置,session默认就是使用默认的0号库
REST_FRAMEWORK = {
# 认证后端
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework.authentication.SessionAuthentication',
)
}
# 2: 局部认证:在视图中加入这个属性:
authentication_classes = [SessionAuthentication]
十一: 权限认证后端:
1: 权限的分类:
- IsAuthenticated: 必须经过身份认证之后
- IsAdminUser: 必须是管理员身份
- AllowAny : 允许所有
- IsAuthenticatedOrReadOnly: 必须身份认证通过,或者是只读操作。
2: 权限认证后端的配置:
# 全局配置: 配置文件中
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.IsAdminUser', # is_staff=True才能访问 —— 管理员(员工)权限
),
}
# 局部配置:DRF视图中
permission_classes = [IsAdminUser]
十二: 限流后端
1: 按匿名用户和非匿名用户进行配置:
# 全局配置
REST_FRAMEWORK = {
# 流量限制后端
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle', # 限制匿名用户访问限制
'rest_framework.throttling.UserRateThrottle', # 非匿名用户访问限制
),
# 流量(请求次数)限制频率
'DEFAULT_THROTTLE_RATES': {
'anon': '3/day', # 匿名用户访问次数 3/day 3/hour 3/second 3/minute
'user': '5/day', # 非匿名用户访问次数
},
}
# 局部配置
throttle_classes = [AnonRateThrottle, UserRateThrottle]
2: 自定义限流后端:
# 全局配置
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.ScopedRateThrottle', # 自定义限流后端
),
'DEFAULT_THROTTLE_RATES': {
# 自定义限流后端的访问次数规则
'books': '3/day',
'heros': '5/day'
},
}
# 局部配置
1:在boook视图中指定
throttle_scope = "books"
2:在hero视图中指定
throttle_scope = "heros"
十三:过滤后端:
1: 过滤后端的作用域:
- 过滤后端的作用范围是: DRF视图中的序列化返回多个资源。
2: 过滤后端的配置:
# 1: 安装拓展包: pip install django-filter
# 2:注册应用:
INSTALLED_APP = [
'django_filters',
]
# 3: 配置过滤后端
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': (
'django_filters.rest_framework.DjangoFilterBackend',
)
}
# 4: 在视图中配置根据那个来过滤
filterset_fields = ['bread', 'bcomment', 'btitle']
十四: 排序后端:
1: 配置:
# 1: 配置文件配置
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS': (
'rest_framework.filters.OrderingFilter', # 排序后端(过滤)
)
}
# 2: 视图中指定配置
ordering_fields = ['bread', 'bcomment', 'bpub_date']
十五: 分页后端
1: PageNumberPagination
1.1: 原理:按照每页bagesize个,去第page页。
1.2:配置
# 1: 全局配置
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 3
}
# 2: 局部配置
pagination_class = PageNumberPagination
1.3: 自定义分页后端
# 1: 任意位置重写PageNumberPagination
class MyPageNum(PageNumberPagination):
# 约定:/books/?page=1&pagesize=5
# 通过类属性,定义查询字符串参数
page_query_param = 'page' # 指定查询字符串参数key为'page',传递取第几页
page_size_query_param = 'pagesize' # 指定查询字符串参数key为'pagesize',传递每页数目
page_size = 5 # 指定后端默认按照每页几个划分
max_page_size = 10 # 每页数目的最大值
# 2: 局部修改成这个
pagination_class = MyPageNum
2: LimitOffsetPagination
2.1: 原理:从第一个数据开始,偏移offset条数据,向下取limit条数据。
2.2: 配置
# 1:全局配置
REST_FRAMEWORK = {
# PageNumberPagination: 按照每页pagesize个划分,取第page页
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 3 # 后端定义默认每页数目
}
# 2:局部配置
pagination_class = LimitOffsetPagination
2.3: 自定义分页后端:
# 1: 任意位置定义
class MyLimitOffset(LimitOffsetPagination):
# 约定:/books/?offset=5&limit=2
# 通过类属性,定义查询字符串参数
pagination_class = LimitOffsetPagination
limit_query_param = 'limit'
offset_query_param = 'offset'
default_limit = 2
max_limit = 10
# 2: 视图中指定
pagination_class = MyLimitOffset
十六: 分页-自定义返回格式
方案一: 在视图中重写GenericAPIView里面的get_paginated_response函数。(只作用于当前视图)
class HerosView(ModelViewSet):
queryset = HeroInfo.objects.all()
serializer_class = HeroInfoModelSerializer
# 自定义分页后端(分页器),一般需要自定义分页器的时候,可以采用局部配置
pagination_class = MyPageNum
# 重写GenericAPIView函数实现自定义分页返回结果(只作用于当前资源视图)
def get_paginated_response(self, data):
# 构造响应结果
# data:查询集分页子集序列化的结果
# 返回响应对象
return Response(data={
'code': 0,
'errmsg': 'ok',
'lists': data
})
方案二: 在自定义分页器中,重写get_paginated_response函数。(作用于使用自定义分页器的所有DRF视图)
class MyPageNum(PageNumberPagination):
# 约定:/books/?page=1&pagesize=5
# 通过类属性,定义查询字符串参数
page_query_param = 'page' # 指定查询字符串参数key为'page',传递取第几页
page_size_query_param = 'pagesize' # 指定查询字符串参数key为'pagesize',传递每页数目
page_size = 5 # 指定后端默认按照每页几个划分
max_page_size = 10 # 每页数目的最大值
# 重写分页器中该函数,作用于所有使用当前分页器的资源视图
def get_paginated_response(self, data):
return Response(data={
'code': 0,
'errmsg': 'ok',
'lists': data
})
十七:DRF 视图的思维导图:















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











