







 本文介绍了过拟合产生的原因,包括模型复杂度过高、特征过多、训练次数过多和数据集小。接着详细探讨了正则化方法,包括L1和L2正则化,它们通过添加惩罚项来避免过拟合,L1正则化产生稀疏模型,L2正则化则使参数值变小。此外,还介绍了dropout技术,通过在训练过程中随机丢弃神经元来防止过拟合,提高模型泛化能力。
本文介绍了过拟合产生的原因,包括模型复杂度过高、特征过多、训练次数过多和数据集小。接着详细探讨了正则化方法,包括L1和L2正则化,它们通过添加惩罚项来避免过拟合,L1正则化产生稀疏模型,L2正则化则使参数值变小。此外,还介绍了dropout技术,通过在训练过程中随机丢弃神经元来防止过拟合,提高模型泛化能力。
1. 产生过拟合的原因
- 模型的复杂度太高。比如:网络太深
- 过多的特征
- 训练迭代次数多
- 数据集太小
2. 应对过拟合的方法
一般来说有如下方法:
- 尽量减少特征的数量
- 数据集扩增
- 增加正则化参数 λ
- dropout
下面就比较难理解的正则化和 dropout 进行解释
2.1 正则化
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作 l1-norm 或 l2-norm,中文称作 L1 正则化 和 L2 正则化,或者 L1 范数 和 L2 范数。
L1 正则化和 L2 正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用 L1 正则化的模型叫做 Lasso 回归,使用 L2 正则化的模型叫做 Ridge 回归(岭回归)。
2.1.1 L1正则化
通常带有 L1 正则项的损失函数如下:
J = J 0 + λ ∑ i n ∣ ω i ∣ J = J_0 + λ\sum^n_i|ω_i| J=J0+λi∑n∣ωi∣
其中 J 0 J_0 J0 是原始的损失函数,加号后面一项是 L1 正则项,λ 是正则化参数,注意到:
- L1 正则项是权值的绝对值之和
我们在原始损失函数 J 0 J_0 J0 后添加 L1 正则项时,相当于对 J 0 J_0 J0 做了一个约束。令 L = α ∑ ω ∣ ω ∣ L = α\sum_ω|ω| L=α∑ω∣ω∣,则 J = J 0 + L J = J_0 + L J=J0+L,对此我们的任务变成在 L 约束下求出 J 0 J_0 J0 取最小值的解。考虑二维的情况,即只有两个权值 ω 1 ω^1 ω1 和 ω 2 ω^2 ω2。此时 L = ∣ ω 1 ∣ + ∣ ω 2 ∣ L = |ω^1| + |ω^2| L=∣ω1∣+∣ω2∣。对于梯度下降法,求解 J 0 J_0 J0 的过程可以画出等值线,同时 L1 正则化的函数 L 也可以在 ω 1 ω 2 ω^1ω^2 ω1ω2的二维平面上画出来。如下图所示:
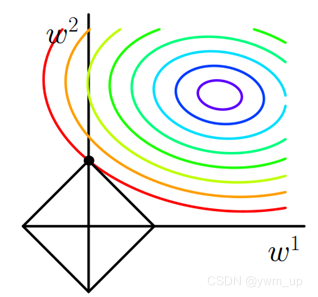
其中彩色的圈圈是 J 0 J_0 J0 的等值线,黑色四边形是 L 函数图形。
在图中,当 J 0 J_0 J0 等值线与 L 图形首次相交的地方就是最优解。上图中 J 0 J_0 J0 与 L 的一个顶点处相交,这个顶点就是最优解,值为 ( ω 1 , ω 2 ) = ( 0 , ω ) (ω^1, ω^2) = (0, ω) (ω1,ω2)=(0,ω)。 J 0 J_0 J0 与这些角接触的机率会远大于其它部位接触的机率(这是很直觉的想象,突出的角比直线的边离等值线更近些),而在这些角上,会有很多权值等于 0(因为角就在坐标轴上),所以:
- L1 正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,用于特征选择。
2.1.2 L2正则化
L2 正则化,也称为权重衰减。带有 L2 正则项的损失函数如下:
J = J 0 + λ ∑ i n ω i 2 J = J_0 + λ\sum^n_iω_i^2 J=J0+λi∑nωi2
- L2 正则项是权值的平方和
线性回归的损失函数为例:
J
(
ω
)
=
1
2
m
∑
i
=
1
m
(
h
ω
(
x
(
i
)
)
−
y
(
i
)
)
2
J(ω) = \frac{1}{2m} \sum^m_{i = 1}(h_ω(x^{(i)}) - y^{(i)}) ^ 2
J(ω)=2m1i=1∑m(hω(x(i))−y(i))2
在梯度下降算法中,需要先对损失函数求导,得到梯度。对于单个样本,先对某个参数
ω
j
ω_j
ωj 求导,最后得到下式:
∂
∂
ω
j
J
(
ω
)
=
1
m
∑
i
=
1
m
(
h
ω
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\frac{\partial}{\partial ω_j}J(ω) = \frac{1} {m} \sum^m_{i = 1}(h_ω(x^{(i)}) - y^{(i)})x^{(i)}_j
∂ωj∂J(ω)=m1i=1∑m(hω(x(i))−y(i))xj(i)
最后再乘以一个系数α(学习率),得到没有添加正则项的
ω
j
ω_j
ωj 参数更新公式为:
ω
j
:
=
ω
j
−
α
1
m
∑
i
=
1
m
(
h
ω
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
ω_j := ω_j - α \frac{1} {m} \sum^m_{i = 1}(h_ω(x^{(i)}) - y^{(i)})x^{(i)}_j
ωj:=ωj−αm1i=1∑m(hω(x(i))−y(i))xj(i)
正则项 L2 对参数
ω
j
ω_j
ωj 求导:
∂
∂
ω
j
L
2
=
2
λ
ω
j
\frac{\partial}{\partial ω_j}L2 = 2 λ ω_j
∂ωj∂L2=2λωj
综合 L2 正则项之后参数
ω
j
ω_j
ωj 的更新公式为:
ω
j
:
=
ω
j
(
1
−
2
λ
)
−
α
1
m
∑
i
=
1
m
(
h
ω
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
ω_j := ω_j(1 - 2 λ) - α \frac{1} {m} \sum^m_{i = 1}(h_ω(x^{(i)}) - y^{(i)})x^{(i)}_j
ωj:=ωj(1−2λ)−αm1i=1∑m(hω(x(i))−y(i))xj(i)
其中 λ 就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代, θ j \theta_j θj 都要先乘以一个小于1的因子,即 ( 1 − 2 λ ) (1 - 2 λ) (1−2λ),从而使得 θ j \theta_j θj 不断减小,因此总的来看, θ θ θ 是不断减小的。所以:
- L2 正则化可以产生参数值较小的模型,能适应不同的数据集,一定程度上防止过拟合,抗扰动能力强。
2.2 dropout
除了前面介绍的正则化方法以外,深度学习模型常常使用丢弃法(dropout)[4] 来应对过拟合问题。丢弃法有一些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。
描述一个单隐藏层的多层感知机。其中输入个数为 4,隐藏单元个数为 5,且隐藏单元
h
i
(
i
=
1
,
.
.
.
,
5
)
h_i (i=1,...,5)
hi(i=1,...,5) 的计算表达式为:
h
i
=
φ
(
x
1
ω
1
i
+
x
2
ω
2
i
+
x
3
ω
3
i
+
x
4
ω
4
i
+
b
i
)
h_i = φ(x_1ω_{1i} + x_2ω_{2i} + x_3ω_{3i} + x_4ω_{4i} + b_i)
hi=φ(x1ω1i+x2ω2i+x3ω3i+x4ω4i+bi)
这里 φ 是激活函数,
x
1
,
.
.
.
,
x
4
x_1,...,x_4
x1,...,x4 是输入,权重参数为
ω
1
i
,
.
.
.
,
ω
4
i
ω_{1i},...,ω_{4i}
ω1i,...,ω4i ,偏差参数为
b
i
b_i
bi。当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为
p
p
p,那么有
p
p
p 的概率
h
i
h_i
hi 会被清零,有
1
−
p
1-p
1−p的概率
h
i
h_i
hi 会除以
1
−
p
1-p
1−p 做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量
ξ
i
\xi_i
ξi 为 0 和 1 的概率分别为
p
p
p 和
1
−
p
1-p
1−p。使用丢弃法时我们计算新的隐藏单元
h
i
′
=
ξ
i
1
−
p
h
i
h_i'= \frac{\xi_i}{1-p} h_i
hi′=1−pξihi
- 即丢弃法不改变其输入的期望值,而随机丢弃训练中隐藏层的神经元,从而应对过拟合。
- 在测试模型中,我们为了拿到更加确定性的结果,一般不使用丢弃法。
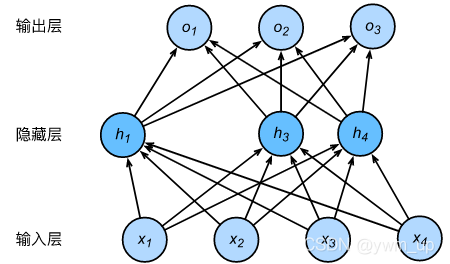
在上图中, h 2 h_2 h2 和 h 5 h_5 h5 被丢弃了,输出层的计算无法过度依赖 h 1 i , . . . , h 5 i h_{1i},...,h_{5i} h1i,...,h5i 中的任一个,从而在训练模型时起到正则化的作用,可以用来应对过拟合。
参考资料:
[1]机器学习中正则化项L1和L2的直观理解
[2]《动手学深度学习》(PyTorch版)3.12 权重衰减
[3]数据预处理–特征选择-L1、L2正则化
[4]Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. JMLR
[5]《动手学深度学习》(PyTorch版)3.13 丢弃法

















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









