







介绍
目前工作忽略了 O 标签实体潜在的语义信息。要是能从 O 标签中,再区分出一种之前未定义的类,就可以获取更多的实体之间的关系。
从 O 标签实体中识别出未定义类,有两大难点:
- 语义混乱:各种各样的类型都有可能归类为 O,这取决于标注的人怎么划分类型的,所以包含了大量的噪音
- 缺少 golden label:要划分的新类型,我们不知道长什么样子,没有样例和标准可以参考
为了解决这些问题,本文提出了MUCO(Mining Undefined Classes from Other-class)。在给 O 类型建原型的的时候,不止建一个原型,而是建立多个原型。如下图右边黑色圈圈所示。
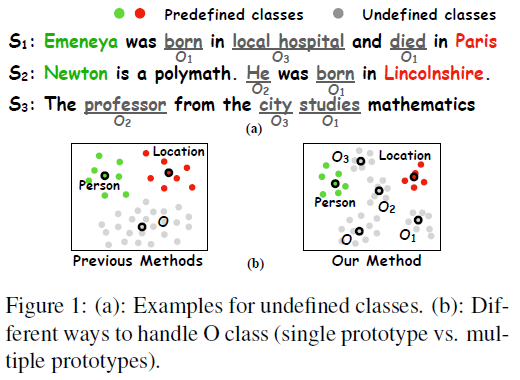
这样做的原因是,如果两个类型AB,A和B是任务相关的,A可以聚成一个簇,那么B也可以聚成一个簇。
本文主要贡献:
- 提出MUCO方法,可以丰富O类型的语义表示
- 对于未定义的类型,提出了一个 zero-shot 分类方法
- 大量的实验,证明方法有效性,还可以迁移到其他领域
相关工作
本文作者将小样本NER方法分为四类:
- 知识增强:利用本体、知识库作为旁白提升NER表现,但是有低覆盖率的问题
- 跨语言增强:用其他语言做外部监督信号,当语言差异大的时候,效果反而下降
- 跨领域增强:同上
- 主动学习:挑选信息量最大的样本人工标注,需要额外的人力
目前处理 O 标签的相关工作较少:
- Deng et al. 2020 训练了一个二分类器区分 O 和其他预定义的类型
- Fritzler et al. 2019 不训练 O 的原型,而是设置了超参数
b
o
b_o
bo,来表示距离相似性
[1] Shumin Deng, Ningyu Zhang, Jiaojian Kang, Yichi Zhang, Wei Zhang, and Huajun Chen. 2020. Metalearning with dynamic-memory-based prototypical network for few-shot event detection. In Proceedings of the 13th International Conference on Web Search and Data Mining, pages 151–159.
[2] Alexander Fritzler, Varvara Logacheva, and Maksim Kretov. 2019. Few-shot classification in named entity recognition task. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, pages 993–1000.
方法
检测未定义类
受到迁移学习的启发,先训练预先定义好的类,让它们聚在一起,如果是任务相关的未定义的类,使用之前训练好的模型,那么这些未定义好的类也会聚在一起。
上面的方法作者叫做 zero-shot 分类方法,可以分为3个步骤:
zero-shot 分类方法
step1: 在预先定义好的类中训练原型
其实就是训练 embedding,让向量更好的在空间中聚类,即缩小类内距离。
embedding 方法采用 BERT。距离定义为:
d
(
x
,
p
y
)
=
−
f
θ
(
x
)
T
p
y
d\left(x, p_{y}\right)=-f_{\theta}(x)^{T} p_{y}
d(x,py)=−fθ(x)Tpy
其中:
- x:输入
- f():embedding 方法
- p y p_y py:原型中心
损失函数定义为:
L
(
θ
1
)
=
−
log
exp
(
−
d
(
x
,
p
y
)
)
∑
p
c
∈
P
c
exp
(
−
d
(
x
,
p
c
)
)
L\left(\theta_{1}\right)=-\log \frac{\exp \left(-d\left(x, p_{y}\right)\right)}{\sum_{p_{c} \in P_{c}} \exp \left(-d\left(x, p_{c}\right)\right)}
L(θ1)=−log∑pc∈Pcexp(−d(x,pc))exp(−d(x,py))
step2:训练二分类器
根据位置特征信息,训练一个二分类器,判断两个点是否是在同一个簇中,每两个点都能判断的话,最后也能聚类成功。
具体方法是,假设原始的 embedding 方法为
f
θ
(
x
)
f_θ(x)
fθ(x),两个样本embedding之后的向量表示为
h
i
,
h
j
h_i, h_j
hi,hj。经过step1训练之后的embedding方法为
f
~
θ
(
x
)
\tilde f_θ(x)
f~θ(x),embedding之后的向量表示为
h
~
i
,
h
~
j
\tilde h_i, \tilde h_j
h~i,h~j。那么这两个样本是同一个簇的概率为:
b
i
j
=
W
(
[
h
i
;
h
j
;
h
~
i
;
h
~
j
;
∣
h
i
−
h
j
∣
∣
h
~
i
−
h
~
j
∣
;
∣
h
i
−
h
~
i
∣
;
∣
h
j
−
h
~
j
∣
]
)
+
b
\begin{aligned} &b_{i j}=W\left(\left[h_{i} ; h_{j} ; \tilde{h}_{i} ; \tilde{h}_{j} ;\left|h_{i}-h_{j}\right|\right.\right. \\ &\left.\left.\quad\left|\tilde{h}_{i}-\tilde{h}_{j}\right| ;\left|h_{i}-\tilde{h}_{i}\right| ;\left|h_{j}-\tilde{h}_{j}\right|\right]\right)+b \end{aligned}
bij=W([hi;hj;h~i;h~j;∣hi−hj∣∣∣∣h~i−h~j∣∣∣;∣∣∣hi−h~i∣∣∣;∣∣∣hj−h~j∣∣∣])+b
训练的交叉熵损失函数为:
L
(
θ
2
)
=
1
N
2
∑
i
N
∑
j
N
(
−
y
i
j
∗
log
(
b
i
j
)
+
(
1
−
y
i
j
)
∗
log
(
1
−
b
i
j
)
)
\begin{aligned} L\left(\theta_{2}\right)=\frac{1}{N^{2}} \sum_{i}^{N} \sum_{j}^{N} &\left(-y_{i j} * \log \left(b_{i j}\right)\right.\\ &\left.+\left(1-y_{i j}\right) * \log \left(1-b_{i j}\right)\right) \end{aligned}
L(θ2)=N21i∑Nj∑N(−yij∗log(bij)+(1−yij)∗log(1−bij))
step3:用二分类器预测 O 类型数据,并聚类
将两个输入 x u , x v x_u, x_v xu,xv 输入到step2训练好的二分类器中,如果输出的概率大于某个阈值 γ γ γ,那么认为这两个输入是同一个类。一些 O 类型的样本可能还是分不到某个类中,就不再继续分了。
对于每个未定义的类型 o i ∈ O = [ o 1 , o 2 , . . . , o r ] o_i ∈ O = [o_1, o_2,...,o_r] oi∈O=[o1,o2,...,or],计算每个类的中心,然后用余弦相似度重新给O标签样本打上软标签。这里打上的标签并不是具体的或者之前定义的标签,只是用 o 1 , o 2 o_1, o_2 o1,o2 这些代指。
联合训练
将之前分类好的
O
=
[
o
1
,
o
2
,
.
.
.
,
o
r
]
O = [o_1, o_2,...,o_r]
O=[o1,o2,...,or],同样也拿过来训练,也就是说实体类型变多了,然后作者在损失函数上加了一个可训练的缩放因子
s
s
s:
L
(
θ
3
)
=
−
log
exp
(
−
s
d
(
x
,
p
y
)
)
∑
p
∈
{
P
c
∪
P
t
}
exp
(
−
s
d
(
x
,
p
)
)
L\left(\theta_{3}\right)=-\log \frac{\exp \left(-s d\left(x, p_{y}\right)\right)}{\sum_{p \in\left\{P_{c} \cup P_{t}\right\}} \exp (-s d(x, p))}
L(θ3)=−log∑p∈{Pc∪Pt}exp(−sd(x,p))exp(−sd(x,py))
实验
baseline方法:
- BERT
- PN:原型网络
- LTC:LTapNet+CDT
- WPN:Warm Prototypical Network,迁移学习的原型网络
- MAML
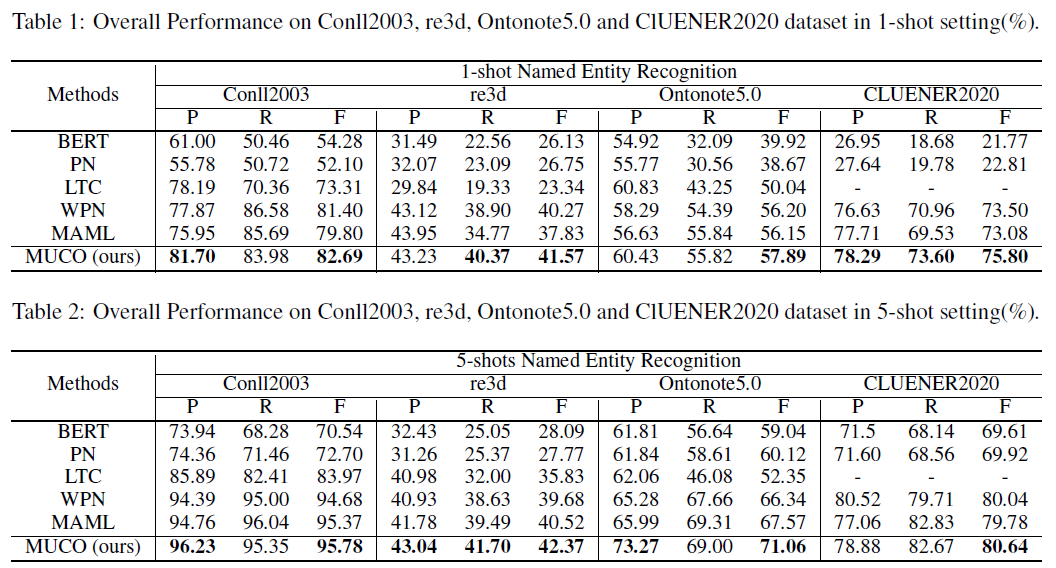
- 相比于监督学习方法BERT和PN,few-shot方法更好
- 在 few-shot 方法中,本文提出的 MUCO 效果最好
- 不管是英文数据集还是中文数据集,MUCO 都能提升 F1 值
总结
这篇论文关注到了以前学者忽略的O类型标签的问题,在做小样本NER的时候,O标签确实很多学者都跳过了,挺新颖的一种视角。
给O标签继续分类的依据是,迁移学习。如果两个标签AB是相关的,如果A标签能聚成一个类,那么B标签也能聚成一个类。所以作者考虑在已知的标签中训练,再迁移到未知的O标签中。















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









