






Few-shot NER方法介绍
2022
Template-free Prompt Tuning for Few-shot NER NAACL
1. 使用预训练语言模型的单词预测范式来预测实体对应的label word,非实体部分预测是其本身
2. label word是通过class标签映射过去的word集合,比如PER:John,Steve,POS:china,japan等
3. label word的构建:通过知识库和远程监督的方法构造伪数据集,使用预训练模型获取topn的实体,然后基于统计和LM获取的实体构建label word
4. 不太适合中文数据集
5. label word样例:



6. 模型架构图


Label Semantics for Few Shot Named Entity Recognition ACL
1. 使用BERT双塔模型,一个BERT对文档进行encoding,另外一个BERT对label的description进行embedding(如B_PER: begin person, I_PER:inside person)
2. label description的embedding方式:使用cls的embedding,使用引入上下文的label embedding(person is very good at playing basketball,然后获取person的embedding)
3. 使用dot product计算token embedding和label description embedding的相似度

Good Examples Make A Faster Learner Simple Demonstration-based Learning for Low-resource NER
1. 少样本NER中的示例学习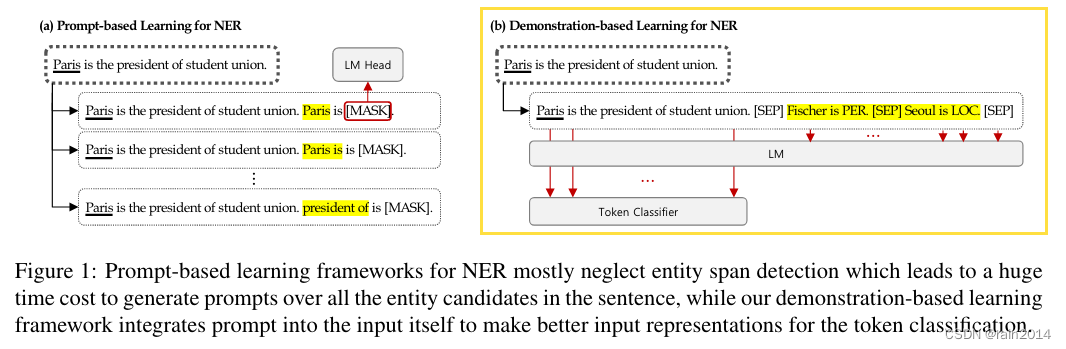

Prompt-based Text Entailment for Low-Resource Named Entity Recognition COLING
1. 使用文本蕴含的方式,将文档作为前提promise,将label转化为prompt(最后append上一个mask,用来表示蕴含的类型),并作为假设hypothesis。
2. prompt构建时,一种是将实体类型替换成其他实体类型,为不存在实体类型的span增加null类型,另一种是替换成非实体span
3. 推理时,需要对每个span候选进行推理,效率低。提出了一个unit-level的改进方法,即把每个token的标签转化为文本描述(如 XX is the part of a location entity)


SpanProto: A Two-stage Span-based Prototypical Network for Few-shot Named Entity Recognition
1. 提出一种两阶段的少样本实体识别网络
2. 使用global pointer网络进行候选span的提取,使用原型网络对span进行分类
3. 针对候选实体中的假正例,使用了一种margin-based的loss


2021
Template-Based Named Entity Recognition Using BART ACL Findings
1. 将source文本作为encoder的输入,构建template,并输入实体span和相应的label,作为decoder的target文本
2. 推理时,使用BART模型对所有候选实体构成的target文本进行打分,使用最高得分作为实体的标注结果
3. 训练:领域内,标签不均衡的情况;领域迁移,先在其他领域的丰富数据上训练,然后在少样本领域数据上fitune
4. 持续学习的能力
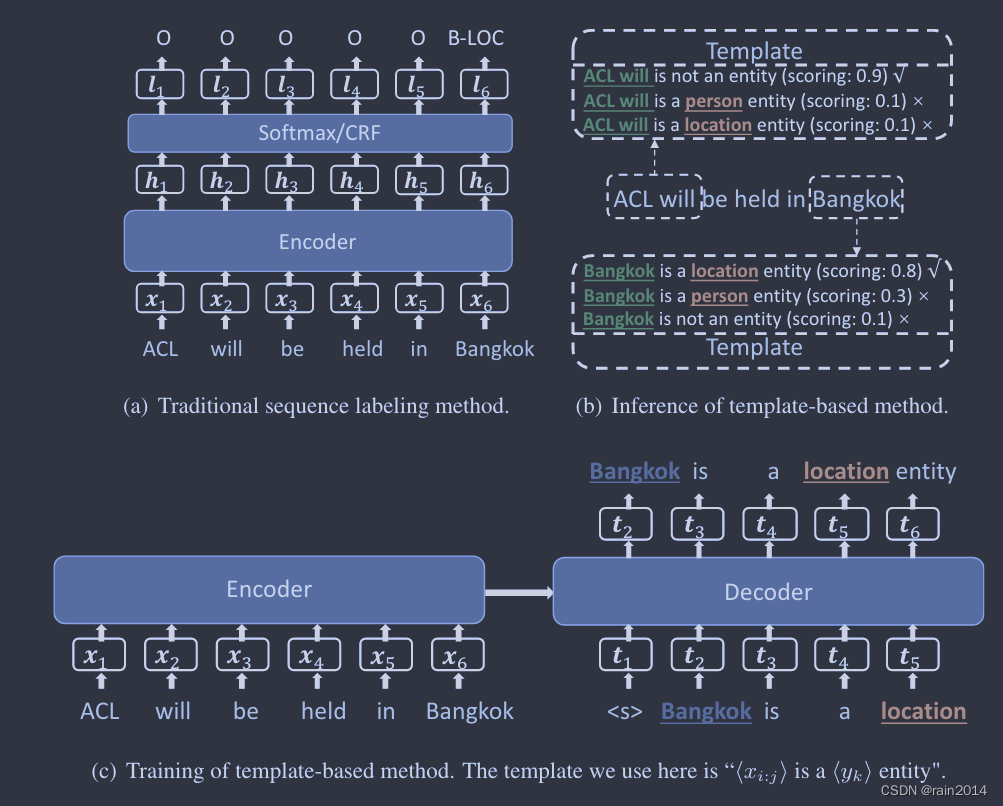

Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data



低资源数据增强
1. 使用相同类别的实体替换
2. 使用预训练语言模型对非实体部分进行替换(提升效果不显著),并可能出现替换实体类型不一致问题以及替换成非实体类型
3. 将golden实体插入到上下文中
4. 回译
方法1
Data Augmentation for Low-Resource Named Entity Recognition Using Backtranslation
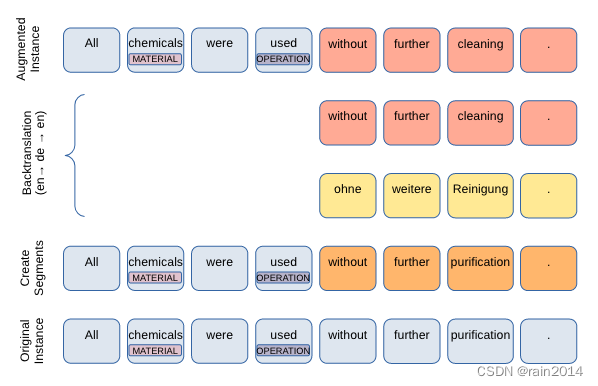

方法2:
MulDA: A Multilingual Data Augmentation Framework for Low-Resource Cross-Lingual NER ACL-IJCNLP 2021


2022
3Rs:Data Augmentation Techniques Using Document Contexts For Low-Resource Chinese Named Entity Recognition IJCNN
1. 代码:https://github.com/alexsivan/3Rs
2. 中文NER数据增广方法:句子片段的组合、随机交换、随机删除
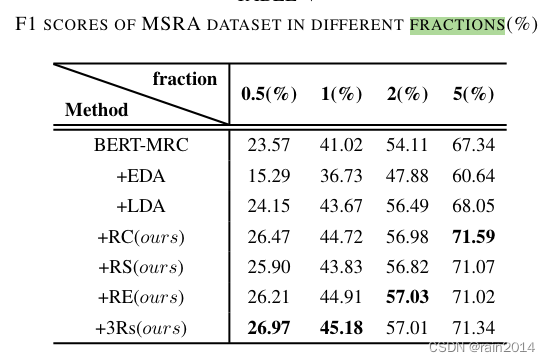

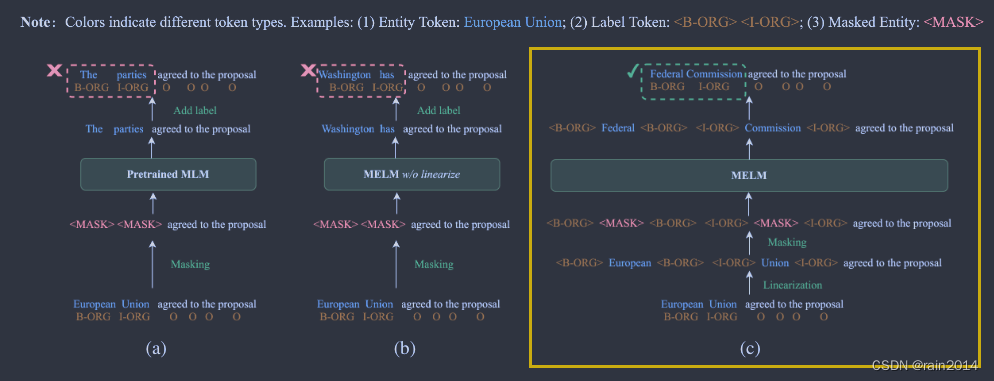
MELM: Data Augmentation with Masked Entity Language Modeling for Low-Resource NER ACL
1. 提出了一种低资源下NER任务的数据增强方法
2. 对实体进行mask,并对实体的每个token的首尾添加label,label的embedding使用标签文本的embedding结果,目的是为了是模型生成类别属于改标签的实体
3. 基于2中的数据进行模型的预训练,预训练只对实体的token进行mask,并应用了一种基于高斯概率分布的mask策略,为了提高生成数据的多样性,取top5作为增强的数据。
4. 用只使用了原始数据集训练的模型对增强好的数据进行过滤,保留预测label和gt label相同的数据集
5. 代码:https://github.com/RandyZhouRan/MELM/

Blog
1. 中文小样本NER模型方法总结和实战:中文小样本NER模型方法总结和实战-腾讯云开发者社区-腾讯云
2. 微软、UIUC韩家炜组联合出品:少样本NER最新综述:微软、UIUC韩家炜组联合出品:少样本NER最新综述
Few-Shot Named Entity Recognition: A Comprehensive Study















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









