







目录
-
变量
定义变量
val/var 变量标识:变量类型 = 初始值val:定义的是不可重新赋值的变量
var:定义的是可重新赋值的变量
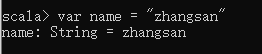
定义一个变量
val name:String = "tom"
使用类型推断来定义变量
scala可以自动根据变量的值来自动推断变量的类型,这样编写代码更加简洁
惰性赋值
在企业的大数据开发中,有时候会编写非常复杂的SQL语句,这些SQL语句可能有几百行甚至上千行。这些SQL语句,如果直接加载到JVM中,会有很大的内存开销。当有一些变量保存的数据较大时,但是不需要马上加载到JVM内存。可以使用惰性赋值来提高效率
语法格式:
lazy val/var 变量名 = 表达式
-
字符串
scala提供多种定义字符串的方式,将来我们可以根据需要来选择最方便的定义方式。
1.使用双引号
2.使用插值表达式
3.使用三引号
使用双引号
语法:
val/var 变量名 = “字符串”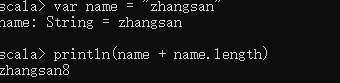
使用插值表达式
在定义字符串之前添加s
在字符串中,可以使用${}来引用变量或者编写表达式
语法:
val/var 变量名 = s"${变量/表达式}字符串"
使用三引号
如果有大段的文本需要保存,就可以使用三引号来定义字符串。例如:保存一大段的SQL语句。三个引号中间的所有字符串都将作为字符串的值。
语法:
val/var 变量名 = """字符串1 字符串2""" 
-
数据类型
| 基础类型 | 类型说明 |
| Byte | 8位带符号整数 |
| Short | 16位带符号整数 |
| Int | 32位带符号整数 |
| Long | 64位带符号整数 |
| Char | 16位无符号Unicode字符 |
| String | Char类型的序列(字符串) |
| Float | 32位单精度浮点数 |
| Double | 64位双精度浮点数 |
| Boolean | true或false |
- scala中所有的类型都使用大写字母开头
- 整形使用Int而不是Integer
- scala中定义变量可以不写类型,让scala编译器自动推断
-
运算符
| 类别 | 操作符 |
| 算术运算符 | +、-、*、/ |
| 关系运算符 | >、<、==、!=、>=、<= |
| 逻辑运算符 | &&、|| 、! |
| 位运算符 | &、、^、<<、>> |
1.scala中没有,++、--运算符
2.与Java不一样,在scala中,可以直接使用==、!=进行比较,它们与equals方法表示一致。而比较两个对象的引用值,使用eq
-
scala类型层次结构

| 类型 | 说明 |
| Any | 所有类型的父类,,它有两个子类AnyRef与AnyVal |
| AnyVal | 所有数值类型的父类 |
| AnyRef | 所有对象类型(引用类型)的父类 |
| Unit | 表示空,Unit是AnyVal的子类,它只有一个的实例() 它类似于Java中的void,但scala要比Java更加面向对象 |
| Null | Null是AnyRef的子类,也就是说它是所有引用类型的子类。 它的实例是null可以将null赋值给任何对象类型 |
| Nothing | 所有类型的子类不能直接创建该类型实例,某个方法抛出异常时,返回的就是Nothing类型,因为Nothing是所有类的子类,那么它可以赋值为任何类型 |
-
条件表达式
条件表达式就是if表达式,if表达式可以根据给定的条件是否满足,根据条件的结果(真或假)决定执行对应的操作。scala条件表达式的语法和Java一样。
有返回值的if
1.在scala中,条件表达式也是有返回值的
2.在scala中,没有三元表达式,可以使用if表达式替代三元表达式
例:
val sex = "male"
val result = if(sex == "male") 1 else 0
块表达式
1.scala中,使用{}表示一个块表达式
2.和if表达式一样,块表达式也是有值的,就是最后一个表达式的值
val a = {
println("1 + 1")
1 + 1
}
-
for循环
在scala中,可以使用for和while,但一般推荐使用for表达式,因为for表达式语法更简洁
for表达式
语法:
for(i <- 表达式/数组/集合) { // 表达式 }
简单循环
例:使用for表达式打印1-10的数字
val nums = 1.to(10)
for(i <- nums) println(i)
嵌套循环
for(i <- 1 to 3; j <- 1 to 5) {print("*");if(j == 5) println("")}
守卫
for表达式中,可以添加if判断语句,这个if判断就称之为守卫。我们可以使用守卫让for表达式更简洁
语法:
for(i <- 表达式/数组/集合 if 表达式) {
// 表达式
} 例:
// 添加守卫,打印能够整除3的数字
for(i <- 1 to 10 if i % 3 == 0) println(i)
for推导式
在for循环体中,可以使用yield表达式构建出一个集合,我们把使用yield的for表达式称之为推导式
例:生成一个10、20、30...100的集合
// for推导式:for表达式中以yield开始,该for表达式会构建出一个集合
val v = for(i <- 1 to 10) yield i * 10 
-
while循环
scala中while循环和Java中是一致的
例:打印1-10的数字
scala> var i = 1
i: Int = 1
scala> while(i <= 10) {
| println(i)
| i = i+1
| }
-
break和continue
1.scala中,没有break/continue关键字
2.如果一定要使用break/continue,就需要使用scala.util.control包的Break类的breable和break方法
实现break
1.导入Breaks包import scala.util.control.Breaks._
2.使用breakable将for表达式包起来
3.for表达式中需要退出循环的地方,添加break()方法调用
例:使用for表达式打印1-100的数字,如果数字到达50,退出for表达式
// 导入scala.util.control包下的Break
import scala.util.control.Breaks._
breakable{
for(i <- 1 to 100) {
if(i >= 50) break()
else println(i)
}
}
实现continue
1.continue的实现与break类似,但有一点不同:
2.实现continue是用breakable{}将for表达式的循环体包含起来
例:打印1-100的数字,使用for表达式来遍历,如果数字能整除10,不打印
// 导入scala.util.control包下的Break
import scala.util.control.Breaks._
for(i <- 1 to 100 ) {
breakable{
if(i % 10 == 0) break()
else println(i)
}
}
-
方法
一个类可以有自己的方法,scala中的方法和Java方法类似。但scala与Java定义方法的语法是不一样的
定义方法
1.参数列表的参数类型不能省略
2.返回值类型可以省略,由scala编译器自动推断
3.返回值可以不写return,默认就是{}块表达式的值
语法:
def methodName (参数名:参数类型, 参数名:参数类型) : [return type] = {
// 方法体:一系列的代码
}例:定义一个方法,实现两个整形数值相加,返回相加后的结果,调用该方法
scala> def add(a:Int, b:Int) = a + b
m1: (x: Int, y: Int)Int
scala> add(10,20)
res9: Int = 30
-
方法参数
scala中的方法参数,使用比较灵活。它支持以下几种类型的参数:
1.默认参数
2.带名参数
3.变长参数
默认参数
在定义方法时可以给参数定义一个默认值
例:
def add(x:Int = 10, y:Int = 20) = x + y
add()
带名参数
在调用方法时,可以指定参数的名称来进行调用
例:
def add(x:Int = 0, y:Int = 0) = x + y
add(x=1)
变长参数
如果方法的参数是不固定的,可以定义一个方法的参数是变长参数
语法:
def 方法名(参数名:参数类型*):返回值类型 = {
方法体
}例:
def add(num:Int*) = num.sum
add(1,2,3,4,5)
-
方法调用方式
在scala中,有以下几种方法调用方式
1.后缀调用法
2.中缀调用法
3.花括号调用法
4.无括号调用法
后缀调用法
语法:
对象名.方法名(参数)例:使用后缀法Math.abs求绝对值
Math.abs(-1)
中缀调用法
语法:注意空格
对象名 方法名 参数例:使用中缀法Math.abs求绝对值
Math abs -1
花括号调用法
语法:方法只有一个参数,才能使用花括号调用法
对象名.方法名{
// 表达式1
// 表达式2
}例:使用花括号调用法Math.abs求绝对值
Math.abs{-10}
无括号调用法
语法:如果方法没有参数,可以省略方法名后面的括号
方法名例:定义一个无参数的方法,打印"hello",使用无括号调用法调用该方法
def m3()=println("hello")
m3()
-
返回值类型推断
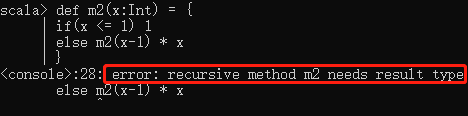
1.scala定义方法可以省略返回值,由scala自动推断返回值类型。
2.定义递归方法,不能省略返回值类型
例:定义递归方法(求阶乘)
def m2(x:Int) = {
| if(x<=1) 1
| else m2(x-1) * x
| } 
-
函数
1.scala支持函数式编程,将来编写Spark/Flink程序中,会大量使用到函数
2.函数是一个对象(变量)
3.类似于方法,函数也有输入参数和返回值
4.函数定义不需要使用def定义
5.无需指定返回值类型
定义函数
语法:
val 函数变量名 = (参数名:参数类型, 参数名:参数类型....) => 函数体例:
val add = (x:Int, y:Int) => x + y
add(1,2)
方法和函数的区别
1.方法是隶属于类或者对象的,在运行时,它是加载到JVM的方法区中
2.可以将函数对象赋值给一个变量,在运行时,它是加载到JVM的堆内存中
3.函数是一个对象,继承自FunctionN,函数对象有apply,curried,toString,tupled这些方法。方法则没有
4.方法无法赋值给变量
方法转换为函数
1.有时候需要将方法转换为函数,作为变量传递,就需要将方法转换为函数
2.使用_即可将方法转换为函数
例:
def add(x:Int,y:Int)=x+y
val a = add _
add(1,2)
-
数组
scala中,有两种数组,一种是定长数组,另一种是变长数组
定长数组
1.定长数组指的是数组的长度是不允许改变的
2.数组的元素是可以改变的
3.在scala中,数组的泛型使用[]来指定
4.使用()来获取元素
语法:
// 通过指定长度定义数组
val/var 变量名 = new Array[元素类型](数组长度)
// 用元素直接初始化数组
val/var 变量名 = Array(元素1, 元素2, 元素3...)例:
val a = new Array[Int](100)
a(0) = 110
println(a(0))
变长数组
1.变长数组指的是数组的长度是可变的,可以往数组中添加、删除元素
2.创建变长数组,需要提前导入ArrayBuffer类import scala.collection.mutable.ArrayBuffer
语法:
//创建空的ArrayBuffer变长数组
import scala.collection.mutable.ArrayBuffer
val/var a = ArrayBuffer[元素类型]()
//创建带有初始元素的ArrayBuffer
import scala.collection.mutable.ArrayBuffer
val/var a = ArrayBuffer(元素1,元素2,元素3....)例:定义一个长度为0的整型变长数组
val a = ArrayBuffer[Int]()例:定义一个包含"hadoop", "storm", "spark"元素的变长数组
val a = ArrayBuffer("hadoop", "storm", "spark")
变长数组添加/修改/删除元素
1.使用+=添加元素
2.使用-=删除元素
3.使用++=追加一个数组到变长数组
例:
// 定义变长数组
import scala.collection.mutable.ArrayBuffer
val a = ArrayBuffer("hadoop", "spark", "flink")
// 追加一个元素
a += "flume"
// 删除一个元素
a -= "hadoop"
// 追加一个数组
a ++= Array("hive", "sqoop")
遍历数组
1.0 until n:生成一系列的数字,包含0,不包含n
2.0 to n :包含0,也包含n
使用for表达式直接遍历数组中的元素
val a = Array(1,2,3,4,5)
for(i<-a) println(i)使用索引遍历数组中的元素
val a = Array(1,2,3,4,5)
for(i <- 0 to a.length - 1) println(a(i))
数组常用算法
1.求和:sum
2.求最大值:max
3.求最小值:min
4.排序:sorted
val a = Array(1,2,3,4,5)
//求和
a.sum
//求最大值
a.max
//求最小值
a.min
//升序排序
a.sorted
//降序排序
a.sorted.reverse
-
元组
元组可以用来包含一组不同类型的值。元组的元素是不可变的。
定义元组
语法:
//使用括号来定义元组
val/var 元组 = (元素1, 元素2, 元素3....)
//使用箭头来定义元组(元组只有两个元素)
val/var 元组 = 元素1->元素2例:
val a = ("zhangsan", 20)
val b = "zhangsan" -> 20
访问元组
1.使用_1、_2、_3....来访问元组中的元素,_1表示访问第一个元素,依次类推
例:
val a = "zhangsan" -> "male"
a._1
-
列表
1.列表是scala中最重要的、也是最常用的数据结构
2.列表可以保存重复的值
3.列表有先后顺序
4.在scala中,也有两种列表,一种是不可变列表、另一种是可变列表
不可变列表
1.不可变集合都在immutable包中(默认导入)
语法:
val/var 变量名 = List(元素1, 元素2, 元素3...)
//使用Nil创建一个不可变的空列表
val/var 变量名 = Nil
//使用::方法创建一个不可变列表,使用::拼接方式来创建列表,必须在最后添加一个Nil
val/var 变量名 = 元素1 :: 元素2 :: Nil例:
//创建一个不可变列表,存放以下几个元素(1,2,3,4)
val a = List(1,2,3,4)
//使用Nil创建一个不可变的空列表
val a = Nil
//使用::方法创建列表,包含-2、-1两个元素
val a = -2 :: -1 :: Nil
可变列表
1.可变列表就是列表的元素、长度都是可变的
2.要使用可变列表,先要导入import scala.collection.mutable.ListBuffer
3.可变集合都在mutable包中
语法:
//使用ListBuffer[元素类型]()创建空的可变列表
val/var 变量名 = ListBuffer[Int]()
//使用ListBuffer(元素1, 元素2, 元素3...)创建可变列表
val/var 变量名 = ListBuffer(元素1,元素2,元素3...)例:
import scala.collection.mutable.ListBuffer
//创建空的整形可变列表
val a = ListBuffer[Int]()
//创建一个可变列表,包含以下元素:1,2,3,4
val a = ListBuffer(1,2,3,4)
可变列表操作
1.获取元素(使用括号访问(索引值))
2.添加元素(+=)
3.追加一个列表(++=)
4.更改元素(使用括号获取元素,然后进行赋值)
5.删除元素(-=)
6.转换为List(toList)
7.转换为Array(toArray)
例:
val a = ListBuffer(1,2,3,4)
//获取0号索引的值
a(0)
//添加一个元素
a+=5
//追加一个列表
val b = ListBuffer(10,20,30)
a ++= b
//更改元素
a(0) = 111
//删除元素
a -= 2
//转换为List(toList)
a.toList
//转换为Array(toArray)
a.toArray
列表常用操作
1.判断列表是否为空(isEmpty)
2.拼接两个列表(++)
3.获取列表的首个元素(head)和剩余部分(tail)
4.反转列表(reverse)
5.获取前缀(take)、获取后缀(drop)
6.扁平化(flaten)
7.拉链(zip)和拉开(unzip)
8.转换字符串(toString)
9.生成字符串(mkString)
10.并集(union)
11.交集(intersect)
12.差集(diff)
例:
//判断列表是否为空
val a = List(1,2,3,4)
a.isEmpty
//拼接两个列表
val a = List(1,2,3)
val b = List(4,5,6)
a ++ b
//获取列表的首个元素和剩余部分
val a = List(1,2,3)
a.head
a.tail
//反转列表
val a = List(1,2,3)
a.reverse
//获取列表前缀和后缀
val a = List(1,2,3,4,5)
a.take(3)
a.drop(3)
//扁平化(压平) 扁平化表示将列表中的列表中的所有元素放到一个列表中
val a = List(List(1,2), List(3), List(4,5))
a.flatten
//拉链与拉开
//拉链:使用zip将两个列表,组合成一个元素为元组的列表
//拉开:将一个包含元组的列表,解开成包含两个列表的元组
val a = List("zhangsan", "lisi", "wangwu")
val b = List(19, 20, 21)
a.zip(b)
res1.unzip
//转换字符串 toString方法可以返回List中的所有元素
val a = List(1,2,3,4)
println(a.toString)
//生成字符串 mkString方法,可以将元素以分隔符拼接起来。默认没有分隔符
val a = List(1,2,3,4)
a.mkString
a.mkString(":")
//并集 union表示对两个列表取并集,不去重 可以调用distinct去重
val a1 = List(1,2,3,4)
val a2 = List(3,4,5,6)
a1.union(a2)
a1.union(a2).distinct
//交集 intersect表示对两个列表取交集
val a1 = List(1,2,3,4)
val a2 = List(3,4,5,6)
a1.intersect(a2)
//差集 diff表示对两个列表取差集 a1.diff(a2),表示获取a1在a2中不存在的元素
val a1 = List(1,2,3,4)
val a2 = List(3,4,5,6)
a1.diff(a2)
-
Set
1.Set(集)是代表没有重复元素的集合,元素不重复
2.不保证插入顺序
3.scala中的集也分为两种,一种是不可变集,另一种是可变集。
不可变集
语法:
//创建一个空的不可变集
val/var 变量名 = Set[类型]()
//给定元素来创建一个不可变集
val/var 变量名 = Set(元素1, 元素2, 元素3...)例:
//定义一个空的不可变集
val a = Set[Int]()
//定义一个不可变集,保存以下元素:1,1,3,2,4,8
val a = Set(1,1,3,2,4,8)
基本操作
1.获取集的大小(size)
2.遍历集(和遍历数组一致)
3.删除一个元素,生成一个Set(-)
4.添加一个元素,生成一个Set(+)
5.拼接两个集,生成一个Set(++)
6.拼接集和列表,生成一个Set(++)
例:
// 创建集
val a = Set(1,1,2,3,4,5)
// 获取集的大小
a.size
// 遍历集
for(i <- a) println(i)
// 删除一个元素
a - 1
//添加一个元素
a + 1
// 拼接两个集
a ++ Set(6,7,8)
// 拼接集和列表
a ++ List(6,7,8,9)
可变集
可变集合不可变集的创建方式一致,只不过需要提前导入一个可变集类。手动导入:import scala.collection.mutable.Set
例:
import scala.collection.mutable.Set
val a = Set(1,2,3,4)
a += 5
a -= 1
-
映射(Map)
Map可以称之为映射。它是由键值对组成的集合。在scala中,Map也分为不可变Map和可变Map
不可变Map
语法:
val/var map = Map(键->值, 键->值, 键->值...) // 推荐,可读性更好
val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)例:
val map = Map("zhangsan"->30, "lisi"->40)
val map = Map(("zhangsan", 30), ("lisi", 30))
//根据key获取value
map("zhangsan")
可变Map
定义语法与不可变Map一致。但定义可变Map需要手动导入import scala.collection.mutable.Map
例:
val map = Map("zhangsan"->30, "lisi"->40)
Map基本操作
1.获取值(map(key))
2.获取所有key(map.keys)
3.获取所有value(map.values)
4.遍历map集合
5.找到指定键的值如果不存在返回指定值(getOrElse)
6.增加key,value对(+)
7.删除key(-)
例:
val map = Map("zhangsan"->30, "lisi"->40)
//获取zhagnsan的年龄
map("zhangsan")
//获取所有的key
map.keys
//获取所有的value
map.values
//遍历打印所有的key value
for((x,y) <- map) println(s"${x} ${y}")
//获取wangwu的年龄,如果wangwu不存在,则返回-1
map.getOrElse("wangwu", -1)
//新增一个学生:wangwu, 35
map += "wangwu"->35
//将lisi从可变映射中移除
map - "lisi"
-
iterator迭代器
1.scala针对每一类集合都提供了一个迭代器(iterator)用来迭代访问集合
2.使用iterator方法可以从集合获取一个迭代器
3.迭代器的两个基本操作
4.hasNext——查询容器中是否有下一个元素
5.next——返回迭代器的下一个元素,如果没有,抛出NoSuchElementException
6.每一个迭代器都是有状态的
7.迭代完后保留在最后一个元素的位置
8.再次使用则抛出NoSuchElementException
9.可以使用while或者for来逐个返回元素
例:
//定义一个列表,包含以下元素:1,2,3,4,5
var a = List(1,2,3,4,5)
//创建迭代器
val ite = a.iterator
//使用while循环和迭代器,遍历打印该列表
while(ite.hasNext) {
println(ite.next)
}















 3924
3924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









