









题目链接:牛客网甲级真题1002
题目简述:给一个图,每个节点处有一个正整数欢乐值。让你找出从起始点到终止点的最短路径,如果路径不止一条,那么找出沿途欢乐总值最大的那条路径;如果还是一样,那么再找出平均下来每个节点的欢乐值最大的那条路径。
- 超时的代码
#include<bits/stdc++.h>
using namespace std;
vector<bool> vis(202, false);
vector<int> preStore(202, 0), temp;
vector<vector<int>> routines, graph(202, vector<int>(202, 0));
unordered_map<string, int> name2id;
unordered_map<int, string> id2name;
int N, M, shortest = -1;
int ans_avg = -1, ans_happiness = -1, ans_id;
void dfs(int c, int dest, int cost){
if(shortest != -1 && cost > shortest)
return;
if(c == dest){
if(cost < shortest || shortest == -1)
routines.clear();
routines.push_back(temp);
shortest = cost;
return;
}
for (int i = 1; i <= N - 1; i++){
if(!vis[i] && graph[c][i] != 0){
vis[i] = true;
temp.push_back(i);
dfs(i, dest, cost + graph[c][i]);
vis[i] = false;
temp.pop_back();
}
}
}
int main(){
string s1, s2, s, start, end = "ROM";
int index = 0, c;
cin >> N >> M >> start;
name2id[start] = 0;
id2name[0] = start;
for (int i = 1; i <= N - 1;i++){
cin >> s >> c;
if(name2id[s] == 0){
name2id[s] = ++index;
id2name[index] = s;
}
preStore[name2id[s]] = c;
}
for (int i = 0; i < M;i++){
cin >> s1 >> s2 >> c;
graph[name2id[s1]][name2id[s2]] = graph[name2id[s2]][name2id[s1]] = c;
}
vis[0] = true;
temp.push_back(0);
dfs(0, name2id[end], 0);
for (int i = 0; i < routines.size();i++){
int happiness = 0;
for (int j = 1; j < routines[i].size();j++)
happiness += preStore[routines[i][j]];
if(happiness > ans_happiness || happiness == ans_happiness && happiness / (routines[i].size() - 1) > ans_avg){
ans_avg = happiness / (routines[i].size() - 1);
ans_happiness = happiness;
ans_id = i;
}
}
cout << routines.size() << " " << shortest << " " << ans_happiness << " " << ans_avg << endl;
cout << start;
for (int i = 1; i < routines[ans_id].size();i++)
cout << "->" << id2name[routines[ans_id][i]];
return 0;
}
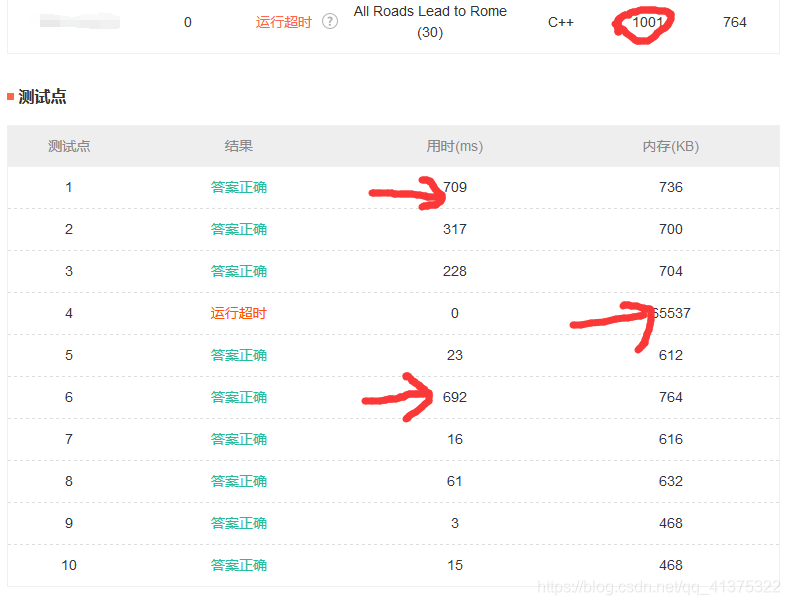
可以看到这个超时了。但是很怪啊,我开始试了几次,发现它又被AC了,只是用时较长,这个评测有点水啊。
分析一下原因,很显然内存的使用已经到达限制了65536KB,说明我的代码递归深度太深了,以至于解不出来。细想一下,这是为什么呢?其实是边的原因,由于我们只限定了顶点的数目上限为200,那它最多能有几条边?n*(n-1)/2条!!!如果这些递归起来,那确实是难以想象的。
但想一下,同类型的题目1001,参考我的题解,为什么就能过呢?其实是测试点的原因,它的这题测试点会设置的数据小一点,你可以在提交代码后看到一个错误报告,你点进去之后就能看到测试集,是比较小的,所以才通过了,很切还挺快的。但是你去看使用的内存,都是比较多的,1000多KB。
所以这个时候就需要使用比较高效的解法来解决这种问题了,当然是想到Dijkstra算法了,只不过我们需要在原来的框架下改动一些规则。这个思路和我的这篇题解基本一样,见PAT【甲级】1003 https://blog.csdn.net/qq_41375322/article/details/115441373。
- AC的代码(推荐学会这种写法)
#include<bits/stdc++.h>
using namespace std;
vector<int> preStore(202, 0), lowcost(202, 0x3f3f3f3f), ans_happiness(202, 0), ans_avg(202, 0), routines(202, 0), pre(202, -1);
vector<vector<int>> graph(202, vector<int>(202, 0));
unordered_map<string, int> name2id;
unordered_map<int, string> id2name;
vector<bool> vis(202, false);
int N, M;
void Dijkstra(int beg){
lowcost[beg] = 0;
routines[beg] = 1;
for (int i = 0; i < N;i++){
int k = -1, Min = 0x3f3f3f3f;
for (int j = 0; j < N;j++){
if(!vis[j] && lowcost[j] < Min){
Min = lowcost[j];
k = j;
}
}
if(k == -1) break;
vis[k] = true;
for (int j = 0; j < N;j++){
if(!vis[j] && graph[k][j] != 0){
if(lowcost[k] + graph[k][j] < lowcost[j]){//路径代价优先选择
lowcost[j] = lowcost[k] + graph[k][j];
ans_happiness[j] = ans_happiness[k] + preStore[j];
ans_avg[j] = ans_avg[k] + 1;
routines[j] = routines[k];
pre[j] = k;
}else if(lowcost[k] + graph[k][j] == lowcost[j]){
if(ans_happiness[j] < ans_happiness[k] + preStore[j]){//优先选取欢乐总值最小的
ans_happiness[j] = ans_happiness[k] + preStore[j];
ans_avg[j] = ans_avg[k] + 1;
pre[j] = k;
}else if(ans_happiness[j] == ans_happiness[k] + preStore[j]){//选取欢乐总值相同时,节点总数最小的,平均值才能大
if(ans_avg[j] > ans_avg[k] + 1){
pre[j] = k;
ans_avg[j] = ans_avg[k] + 1;
}
}
routines[j] += routines[k];
}
}
}
}
}
void print(int beg){
if(beg == -1){
return;
}
print(pre[beg]);
if(pre[beg] != -1)
cout << "->";
cout << id2name[beg];
}
int main(){
string s1, s2, s, start, end = "ROM";
int index = 0, c;
cin >> N >> M >> start;
name2id[start] = 0;
id2name[0] = start;
for (int i = 1; i <= N - 1;i++){
cin >> s >> c;
if(name2id[s] == 0){
name2id[s] = ++index;
id2name[index] = s;
}
preStore[name2id[s]] = c;
}
for (int i = 0; i < M;i++){
cin >> s1 >> s2 >> c;
graph[name2id[s1]][name2id[s2]] = graph[name2id[s2]][name2id[s1]] = c;
}
Dijkstra(0);
cout << routines[name2id[end]] << " " << lowcost[name2id[end]] << " " << ans_happiness[name2id[end]];
cout << " " << ans_happiness[name2id[end]] / ans_avg[name2id[end]] << endl;
print(name2id[end]);
return 0;
}
 这个牛客的评测感觉有问题,同一份代码刚才评测的时候竟然又出现问题了。。。。。
这个牛客的评测感觉有问题,同一份代码刚才评测的时候竟然又出现问题了。。。。。
其实关键就是在Dijkstra框架中进行的操作,对于路径的选择应该去按照题意要求进行一个个处理分析。我的代码应该是能看懂的,其中
preStore(202, 0) 是记录每个节点的欢乐值的;
lowcost(202, 0x3f3f3f3f)是记录从源点每个节点的最小代价的;
ans_happiness(202, 0) 是记录从源点到每个节点的最大欢乐总值的;
ans_avg(202, 0)是记录从源点到目的节点路径中,截止经过该关键点节点总数最小的值, 以此来保证欢乐平均值最大;
routines(202, 0)是记录最短路径总数的(有没有和我上面提到的PAT甲级题库中那道题目一样);
pre(202, -1)是用来记录符合要求的最短路径的那个路径。
做的时候有个点也要注意到,我看别人写的代码是用Dijkstra来求解得到所有路径,通过维护一个vector<vector<int>>二维数组,来链式表示所有的路径,再通过dfs来遍历这颗路径树,在这过程中,来求解得到我们最后需要的路径。
其实没必要,因为我们并不需要去这样做,因为题目并没有要求我们去输出所有的路径,只需要知道路径数目,最优路径即可,那其实就可以像我做的一样,在Dijkstra算法框架里来解决它。
最后总结一下
还是要用Dijkstra算法啊,因为你并不知道测试集会给你多大的数据集,用这个算法就能保证上限了。














 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









