







 本文记录了在使用Spark DataFrame执行join操作后写入HDFS时遇到的错误,首先出现文件找不到的问题,尝试清理HDFS缓存未解决问题。作者建议先在本地测试,如果本地可行而虚拟机不行,可能是虚拟机配置问题。通过查看日志发现是datanode的错误,并通过添加配置文件解决了问题。最后呼吁加强原创内容审核。
本文记录了在使用Spark DataFrame执行join操作后写入HDFS时遇到的错误,首先出现文件找不到的问题,尝试清理HDFS缓存未解决问题。作者建议先在本地测试,如果本地可行而虚拟机不行,可能是虚拟机配置问题。通过查看日志发现是datanode的错误,并通过添加配置文件解决了问题。最后呼吁加强原创内容审核。
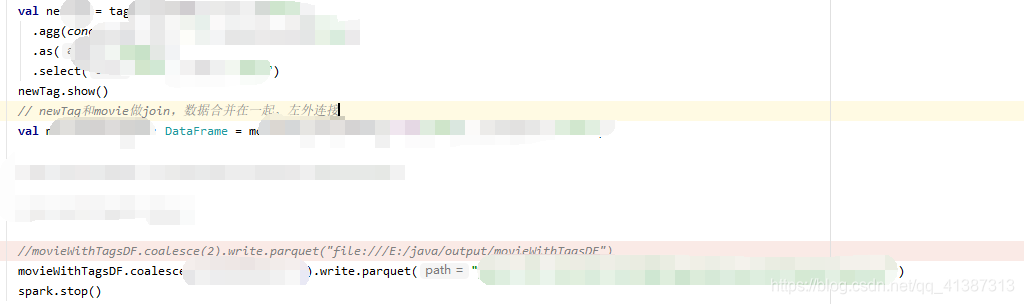
这个是代码的片段,然后在运行的时候这段代码的时候报错,刚开始是报文件找不到。例如下图

然后开始一顿百度,其他的人都说什么清除hdfs的临时目录,再此我提醒大家
如果你的代码在一开始执行前面的过程能够正常写入hdfs的时候!就不要相信那些所谓的清除hdfs的缓存目录。你可以放到本地测试一下,
如果本地可以,虚拟机不行的话,那么就是你的虚拟机的问题。
记得要养成看log的文件的习惯!
例如下图
这个是datanode的报错。
然后确定是虚拟机问题以后在去百度。添加配置文件
<property>
<name>dfs.replication</name>
&l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3133
3133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









