







问题的重要性
机器学习系统是大型、复杂的,开发人员倾向于通过重用一系列通常经过预先训练的原始模型来构建ML系统,这种“即插即用”的模式加快了ML系统的开发周期,但不利的一面是大多数原始模型都是由第三方提供,它们缺乏标准化或规范化调整,带来严重的安全影响,事实上,在软件开发中重用外部模块的风险早就被人们认识,相反,对于采用原始模型作为ML系统的构建块的安全性影响,我们知之甚少
场景及假设:
这篇工作的研究背景是什么
有两种方式导致对抗模型进去ML系统
首先,它们可以在系统开发期间被合并。通常,原始模型的多个变体可能存在于市场上。更糟糕的是,敌对模型可能嵌套在其他原始模型中。不幸的是,ML系统开发人员经常缺乏时间(例如,由于发布新系统的压力哈哈哈哈)或有效的工具来审查给定的原始模型。
其次,它们也可以在系统维护期间被合并。由于它们对训练数据的依赖,预先训练的原始模型会随着新数据的出现而频繁更新。每一种变体都针对一个越来越大的数据集进行训练。由于ML系统的体内调优通常需要对整个系统进行重新培训,因此开发人员倾向于简单地合并原始模型更新,而不进行深入检查。
场景中有哪些假设
对抗者的目标:
我们假定对抗着企图扰乱ML系统从而对制定的输入x_分类到期望的x+类中(错误分类)
对抗者的知识:
我们假定对抗者对于以下资源没有了解和控制:
- 宿主ML系统的其他部分
- 开发人员使用的系统微调策略(例如,全系统或部分系统调优)—》意味着改变了还是可以破坏
- 开发者使用的数据库
中心思想:
我们提供了一个广泛的模型重用攻击类,其中恶意构建的模型(即,“对抗性模型”)迫使主机系统对目标输入(即(例如,将触发器错误地分类为指定的类)。这样的攻击会导致相应的损害。
方案:
- Generating semantic neighbors//生成语义邻居,即他们很像,因为给他附近的点增加了变化譬如自然噪声或者模糊
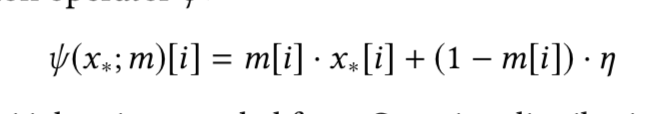
- 寻找突出的特征
由于DNNs对于上述上述噪声的容忍,他们可以被分为一类,从而获得·他们的突出特征
- 训练对抗模型,为了把x-错误分类为x+,计算各个特征的的梯度并且调整
模型重用攻击的4个特征
有效:攻击迫使主机ML系统在指定输入得到错误的输出,并且具有很高的概率。
闪烁其词(Evasive):在将给定的原始模型集成到系统之前,开发人员可能会检查它们。然而,就其对非目标输入的行为而言,对抗性模型与良性模型并无明显区别???
弹性:对抗性模型只是宿主系统的一个组成部分。我们假设对手既不知道也不能控制其他组件的使用(即,或如何调整系统。然而,我们表明模型重用攻击对各种系统设计选择或调优策略不敏感。
简单:对手能够发动这样的攻击,几乎不需要了解用于系统调优或推断的数据。
贡献
我们对ML系统开发中重用预训练原始模型的现状进行了实证研究,结果表明,目前广泛的ML系统都建立在流行的原始模型的基础上。这一发现表明,这些原始模型一旦被反向操纵,将对许多ML系统的安全造成巨大威胁。
提出了一类广泛的模型重用攻击,并将其应用于基于深度神经网络的原始模型。以安全关键应用中的四个ML系统为例,证明了模型重用攻击的有效性、高概率规避检测、对系统微调具有弹性、易于启动。
我们为此类攻击的有效性提供分析依据,并讨论可能的对策。本文分析了改进当前ML系统开发中原始模型集成实践的必要性,指出了几个值得研究的方向
实验:
所用数据集:
四种用于安全关键领域的深度学习系统,包括皮肤癌筛查、语音识别、人脸识别和自主驾驶
衡量指标:
•有效性——是否有这样的攻击可以触发主机主机系统,使其行为不符合要求?
攻击成功率: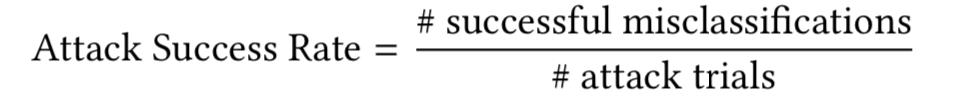
误分类置信度:错误分类的概率
•闪烁其词——在系统开发人员检查时,这种攻击是否闪烁其词?//不清楚怎么理解这个evasiveness
•弹性——这种攻击对系统设计选择或微调策略是否可靠?
为了评估攻击弹性,我们测量了系统设计选择(例如分类器体系结构)和微调策略(例如微调方法和调整步骤的数量)如何影响攻击的有效性和隐蔽性。
这篇论文是否有不合理的地方?或者明显的不足?
为了评估攻击弹性,我们测量了系统设计选择(例如分类器体系结构)和微调策略(例如微调方法和调整步骤的数量)如何影响攻击的有效性和隐蔽性。















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









