







问题描述
- 一表有排污费变量,一表有政府环保补助变量。想要通过股票代码(stkcd)和年份(year)一一对应,将两表汇成一表。
- 预实现:stkcd(重污染行业)、year(2011-2017)、排污费、环保补助四列的面板数据。
- stata代码:merge 1:1 stkcd year using “环保补助的文件夹路径”
- 报错提醒:variables stkcd year do not uniquely identify observations in the master data
处理报错方法(无用)
- duplicates list,显示没有重复值,但是仍没解决问题
- list stkcd if stkcd ==stkcd[_n-1],还没解决问题
最终解决方法
- **问题的发现:**发现在master表格中,存在几列的stack、year相同,但是排污费不同。如图:
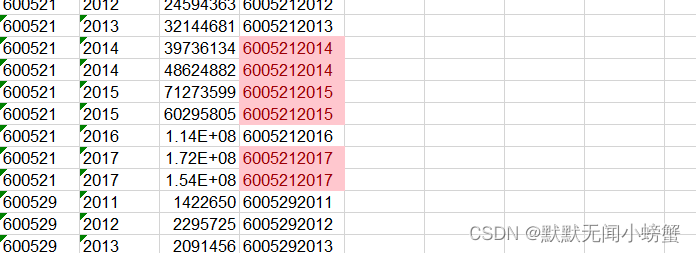
- 解决方法:
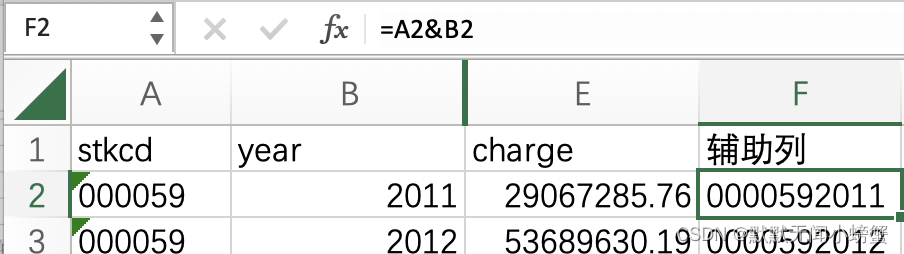
用Excel排查重复项目:
先建一列,=A2&B2,后应用到下面的所有行。
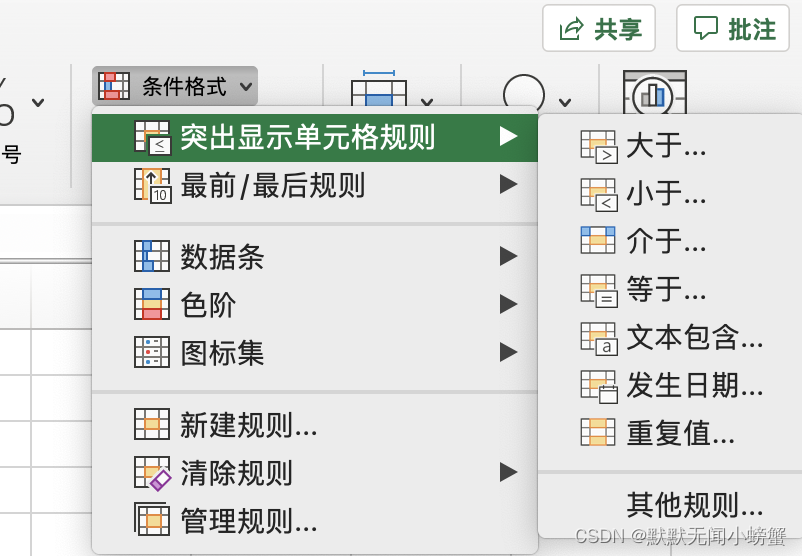
在根据条件格式中筛选出重复值即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









