







 本文介绍了如何在TensorFlow中使用`tensorflow.nn.bidirectional_dynamic_rnn()`函数创建双向LSTM。通过结合前向和后向细胞输出,实现更全面的序列理解。关键在于,尽管输入cell相同,函数内部通过反转序列来实现反向传播。在实践中,只需传入两个cell并配合输入tensor进行操作。
本文介绍了如何在TensorFlow中使用`tensorflow.nn.bidirectional_dynamic_rnn()`函数创建双向LSTM。通过结合前向和后向细胞输出,实现更全面的序列理解。关键在于,尽管输入cell相同,函数内部通过反转序列来实现反向传播。在实践中,只需传入两个cell并配合输入tensor进行操作。
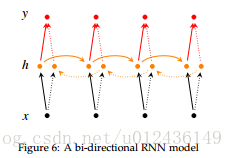
开门见山来两张比较蛋疼的图,它们确实很流行。直奔主题。
def bidirectional_dynamic_rnn(
cell_fw, # 前向RNN
cell_bw, # 后向RNN
inputs, # 输入
sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度)
initial_state_fw=None, # 前向的初始化状态(可选)
initial_state_bw=None, # 后向的初始化状态(可选)
dtype=None, # 初始化和输出的数据类型(可选)
parallel_iterations=None,
swap_memory=False,
time_major=False,
# 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`.
# 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`.
scope=None
)outputs为(output_fw, output_bw),是一个包含前向cell输出tensor和后向cell输出tensor组成的二元组。假设 time_major=false, 而且tensor的shape为[batch_size, max_time, depth]。实验中使用tf.concat(outputs, 2)将其拼接。 output_states为(output_state_fw, output_state_bw),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









