







一.概念介绍
1.kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景。
2.Kafka基本概念
| 名称 | 作用 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
3.通信协议
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
二.安装
环境准备
1.由于Kafka是用Scala语言开发的,运行在JVM上,因此在安装Kafka之前需要先安装JDK。
yum install java-1.8.0-openjdk* -y
2.kafka依赖zookeeper,所以需要先安装zookeeper
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz cd apache-zookeeper-3.5.8-bin cp conf/zoo_sample.cfg conf/zoo.cfg
启动zookeeper bin/zkServer.sh start bin/zkCli.sh ls / #查看zk的根目录相关节点
第一步:下载安装包
下载2.4.1 release版本,并解压:
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11-2.4.1.tgz
2.11是scala的版本,2.4.1是kafka的版本 tar -xzf kafka_2.11-2.4.1.tgz cd kafka_2.11-2.4.1
第二步:修改配置
修改配置文件config/server.properties:
#broker.id属性在kafka集群中必须要是唯一 broker.id=0
#kafka部署的机器ip和提供服务的端口号 listeners=PLAINTEXT://192.168.65.60:9092
#kafka的消息存储文件 log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址 zookeeper.connect=192.168.65.60:2181
第三步:启动服务
启动脚本语法:kafka-server-start.sh [-daemon] server.properties
可以看到,server.properties的配置路径是一个强制的参数,-daemon表示以后台进程运行,否则ssh客户端退出后,就会停止服务。(注意,在启动kafka时会使用linux主机名关联的ip地址,所以需要把主机名和linux的ip映射配置到本地host里,用vim /etc/hosts)
启动kafka,运行日志在logs目录的server.log文件里
bin/kafka-server-start.sh -daemon config/server.properties 后台启动,不会打印日志到控制台 或者用 bin/kafka-server-start.sh config/server.properties
我们进入zookeeper目录通过zookeeper客户端查看下zookeeper的目录树
bin/zkCli.sh
ls /#查看zk的根目录kafka相关节点
ls /brokers/ids #查看kafka节点
停止kafka bin/kafka-server-stop.sh
三.参数解释
| Property | Default | Description |
|---|---|---|
| broker.id | 0 | 每个broker都可以用一个唯一的非负整数id进行标识;这个id可以作为broker的“名字”,你可以选择任意你喜欢的数字作为id,只要id是唯一的即可。 |
| log.dirs | /tmp/kafka-logs | kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。 |
| listeners | PLAINTEXT://192.168.65.60:9092 | PLAINTEXT://192.168.65.60:9092 |
| zookeeper.connect | localhost:2181 | zooKeeper连接字符串的格式为:hostname:port,此处hostname和port分别是ZooKeeper集群中某个节点的host和port;zookeeper如果是集群,连接方式为 hostname1:port1, hostname2:port2, hostname3:port3 |
| num.partitions | 1 | 创建topic的默认分区数 |
| default.replication.factor | 1 | 自动创建topic的默认副本数量,建议设置为大于等于2 |
| min.insync.replicas | 1 | 当producer设置acks为-1时,min.insync.replicas指定replicas的最小数目(必须确认每一个repica的写数据都是成功的),如果这个数目没有达到,producer发送消息会产生异常 |
| delete.topic.enable | 1 | 是否允许删除主题。 |
四.kafka消息
1.单播消息
一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可
分别在两个客户端执行如下消费命令,然后往主题里发送消息,结果只有一个客户端能收到消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --consumer-property group.id=luyao --topic luyao
2.多播消息
一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,要实现多播只要保证这些消费者属于不同的消费组即可。
查看消费者组名:
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.65.60:9092 --list
查看消费者偏移量:
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.65.60:9092 --describe --group luyao
五.主题Topic和消息日志Log
可以理解Topic是一个类别的名称,同类消息发送到同一个Topic下面。对于每一个Topic,下面可以有多个分区(Partition)日志文件:
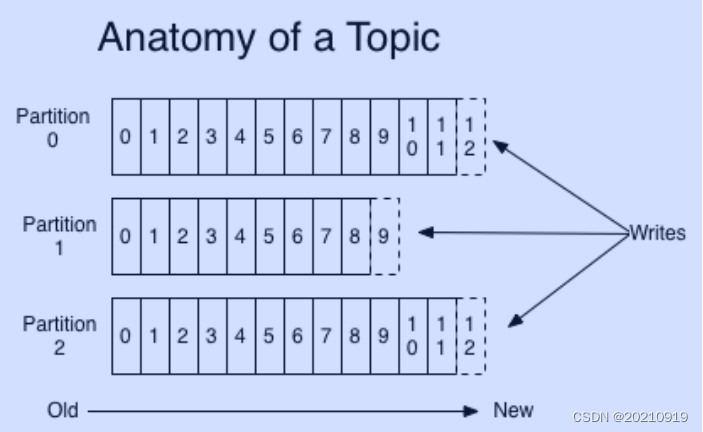
Partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,默认保留最近一周的日志消息。
kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日志信息不会有什么影响。
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由consumer自己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer来说,都是没有影响的,因为每个consumer维护各自的消费offset。
创建多个分区的主题:
bin/kafka-topics.sh --create --zookeeper 192.168.65.60:2181 --replication-factor 1 --partitions 2 --topic luyao1
查看topic
bin/kafka-topics.sh --describe --zookeeper 192.168.65.60:2181 --topic luyao1
为什么要对Topic下数据进行分区存储?
1、commit log文件会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于对数据做了分布式存储,理论上一个topic可以处理任意数量的数据。
2、为了提高并行度。
Consumers
传统的消息传递模式有2种:队列( queue) 和(publish-subscribe)
queue模式:多个consumer从服务器中读取数据,消息只会到达一个consumer。
publish-subscribe模式:消息会被广播给所有的consumer。
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
queue模式:所有的consumer都位于同一个consumer group 下。
publish-subscribe模式:所有的consumer都有着自己唯一的consumer group。
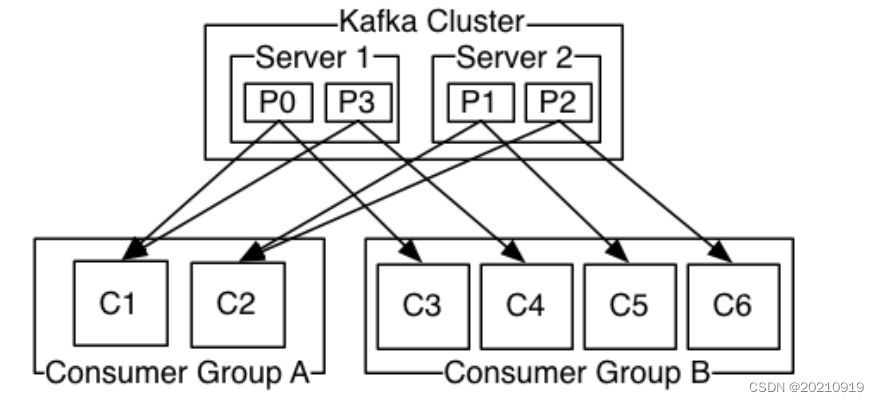
上图说明:由2个broker组成的kafka集群,某个主题总共有4个partition(P0-P3),分别位于不同的broker上。这个集群由2个Consumer Group消费, A有2个consumer instances ,B有4个。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。
消费顺序
一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费,从而保证消费顺序。
consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多,否则,多出来的consumer消费不到消息。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。
如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
参数设置:
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, “192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094”);
/* 发出消息持久化机制参数
(1)acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。
(2)acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一 条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
(3)acks=-1或all: 需要等待 min.insync.replicas(默认为1,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略会保证 只要有一个备份存活就不会丢失数据。
*/ /*props.put(ProducerConfig.ACKS_CONFIG, “1”);
// 发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如网络抖动,所以需要在 接收者那边做好消息接收的幂等性处理
// props.put(ProducerConfig.RETRIES_CONFIG, 3);
//重试间隔设置
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300); //设置发送消息的本地缓冲区,如果设置了该缓冲区,消息会先发送到本地缓冲区,可以提高消息发送性能,默认值是33554432,即32MB props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); // kafka本地线程会从缓冲区取数据,批量发送到broker, 设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去 // props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 默认值是0,意思就是消息必须立即被发送,但这样会影响性能 一般设置10毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果10毫秒内,这个batch满了16kb就会随batch一起被发送出去 如果10毫秒内,batch没满,那么也必须把消息发送出去,不能让消息的发送延迟时间太长
// props.put(ProducerConfig.LINGER_MS_CONFIG, 10);*/ //把发送的key从字符串序列化为字节数组
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //把发送消息value从字符串序列化为字节数组 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
Controller选举机制
在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点,zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。
当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
更新集群的元数据信息,同步到其他普通的broker节点中。
Partition副本选举Leader机制
controller感知到分区leader所在的broker挂了(controller监听了很多zk节点可以感知到broker存活),controller会从ISR列表(参数unclean.leader.election.enable=false的前提下)里挑第一个broker作为leader(第一个broker最先放进ISR列表,可能是同步数据最多的副本),如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader,这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。
副本进入ISR列表有两个条件:
副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通
副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由 replica.lag.time.max.ms 配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的时候,key是consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据
因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区
公式:hash(consumerGroupId) % __consumer_offsets主题的分区数
消费者Rebalance机制
rebalance就是说如果消费组里的消费者数量有变化或消费的分区数有变化,kafka会重新分配消费者消费分区的关系。比如consumer group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他。
注意:rebalance只针对subscribe这种不指定分区消费的情况,如果通过assign这种消费方式指定了分区,kafka不会进行rebanlance。
如下情况可能会触发消费者rebalance
消费组里的consumer增加或减少了
动态给topic增加了分区
消费组订阅了更多的topic
rebalance过程中,消费者无法从kafka消费消息,这对kafka的TPS会有影响,如果kafka集群内节点较多,比如数百个,那重平衡可能会耗时极多,所以应尽量避免在系统高峰期的重平衡发生。
消费者Rebalance分区分配策略:
主要有三种rebalance的策略:range、round-robin、sticky。
Kafka 提供了消费者客户端参数partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况为range分配策略。
假设一个主题有10个分区(0-9),现在有三个consumer消费:
range策略就是按照分区序号排序,假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。
比如分区03给一个consumer,分区46给一个consumer,分区7~9给一个consumer。
round-robin策略就是轮询分配,比如分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、8给一个consumer
sticky策略初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下两个原则。
1)分区的分配要尽可能均匀 。
2)分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。
比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:
consumer1除了原有的0~3,会再分配一个7
consumer2除了原有的4~6,会再分配8和9
Rebalance过程如下:
第一阶段:选择组协调器
组协调器GroupCoordinator:每个consumer group都会选择一个broker作为自己的组协调器coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者rebalance。
consumer group中的每个consumer启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。
组协调器选择方式:
consumer消费的offset要提交到__consumer_offsets的哪个分区,这个分区leader对应的broker就是这个consumer group的coordinator
第二阶段:加入消费组JOIN GROUP
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。然后GroupCoordinator 从一个consumer group中选择第一个加入group的consumer作为leader(消费组协调器),把consumer group情况发送给这个leader,接着这个leader会负责制定分区方案。
第三阶段( SYNC GROUP)
consumer leader通过给GroupCoordinator发送SyncGroupRequest,接着GroupCoordinator就把分区方案下发给各个consumer,他们会根据指定分区的leader broker进行网络连接以及消息消费。















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









