







论文地址:
https://arxiv.org/abs/2103.14030
代码地址:
https://github.com/microsoft/Swin-Transformer
一、Swin Transformer的整体架构及流程
Swin变压器架构

W-MSA是常规多头自关注模块,SW-MSA是移位窗口多头自关注模块。
Stage 1
首先,输入的RGB图像先经过patch分割模块,被分割成不重叠的patch,每个patch被视为一个‘token’,特征值就是原始像素点的RGB值的串联。在该实验的实现过程中,采用的patch大小为4×4,因此每个面片的特征维数为4 × 4 × 3 = 48,也就是4×4×48,所以输入的token有H/4 × W/4个。然后,经过linear embedding也就是对该原始值特征线性嵌入,将其投影到任意维度C。然后,这些patch经过2个Swin Transformer blocks计算自注意,不改变数量和维度,输出为H/4 × W/4×C。
Stage 2
为了产生分层表示,随着网络变得更深,通过patch merging层来减少token的数量。第一个patch merging层连接每组2 × 2相邻patch的特征,并在4C维连接的特征上应用线性层。这会将token数减少2 × 2 = 4的倍数(分辨率下采样2倍),输出维度设置为2C。[自己理解:也就是说,经过patch merging层的合并,新token的大小会变成2patch × 2patch,如下图,此时维度也输出为2C。]随后经过2个Swin Transformer blocks进行特征变换,分辨率保持在H/8 × W/8,维度也是2C不改变。

Stage 3
原理同Stage 2,经过6个Swin Transformer blocks进行特征变换,该阶段的输出大小为H/16 × W/16×4C。
Stage 4
原理同Stage 2,经过2个Swin Transformer blocks进行特征变换,该阶段的输出大小为H/32 × W/32×8C。
Swin Transformer block
上述阶段中的Swin Transformer block是通过将多头注意模块中的W-MSA替换为SW-MSA来实现的,两个连续的Swin Transformer block结构详见架构图,一个W-MSA和一个SW-MSA的配置是为了实现两种窗口划分。
二、基于移动窗口的自我注意(Shifted Window based Self-Attention)
非重叠窗口中的自我注意(Self-attention in non-overlapped windows)
为了有效的建模,我们提出在局部窗口内计算自我注意。这些窗口被安排成以不重叠的方式均匀地分割图像。假设每个窗口包含M × M个小块,全局MSA模块和基于h × w个小块图像的窗口的计算复杂度是:
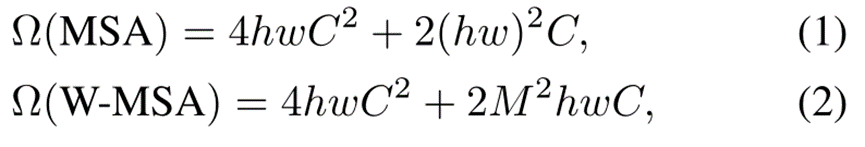
其中,前者与面片数hw成二次关系,后者在M固定(默认设置为7)时为线性关系。对于大型硬件来说,全局自关注计算通常是负担不起的,而基于窗口的自关注是可扩展的。
连续块中的移位窗口划分(Shifted window partitioning in successive blocks)

基于窗口的自我关注模块缺乏跨窗口的连接,这限制了它的建模能力。为了引入跨窗口连接,同时保持非重叠窗口的高效计算,我们提出了一种移位窗口划分方法,该方法在连续Swin变换器块中的两种划分配置之间交替。
第一个模块使用从左上像素开始的常规窗口分割策略,8 × 8特征图被均匀地分割成大小为4 × 4 (M = 4)的2 × 2窗口。然后,下一个模块采用与前一层的窗口配置不同的窗口配置,通过将窗口从规则分区的窗口移动(⌊M/2⌋,⌊M/2⌋)个像素。利用移位窗口划分方法,连续的Swin变换器模块计算如下:

移位配置的高效批量计算(Efficient batch computation for shifted configuration):

通过向左上方循环移位解决在窗口移位时产生更多窗口的问题,在这种移位之后,分批窗口可以由在特征图中不相邻的几个子窗口组成,因此采用掩蔽机制来将自我注意计算限制在每个子窗口内,移位后的窗口数量与常规窗口划分的数量相同。
相对位置偏差(Relative position bias):
在计算自我注意时,通过加入每个头部的相对位置偏差B∈ RM 2×M 2来计算相似性:

三、架构变体

QUOTE
[Swin Transformer]
This paper presents Swin Transformer, a new vision Transformer which produces a hierarchical feature representation and has linear computational complexity with respect to input image size.
[SwinTrack]
Swin-Transformer employs a hierarchical window attention-based architecture to address two major challenges in the Transformer architecture: the variety of visual elements in scale and the high computational complexity on high-resolution images. Unlike the ViT family using afixed-size feature map, Swin-Transformer builds the fea- ture map by gradually merging neighbor patches from large to small. With hierarchical feature maps, traditional multi-scale prediction techniques can be used to overcome the scaling problem. Besides, Swin-Transformer introduces a non-overlapping window partition operation. Self-attention computing is limited within the window. As a result, the computational complexity is greatly reduced. Furthermore, the partition windows are shifted periodically to bridge the windows in preceding layers.















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









