







一、介绍
- 有时候在命令行输入命令后会显示乱码,其实是语系的不一样导致的:比如说在英语语序下不会显示中文
- 打印中文语系的日期

- 将中文语系改为英语语系

-
提示:设置语系只在本次命令行操作中生效,退出命令行后失效,下次进入命令行需要重新设置,想要永久设置,请修改配置文件。
二、相关命令
- 列出当前各项支持的语系:
locale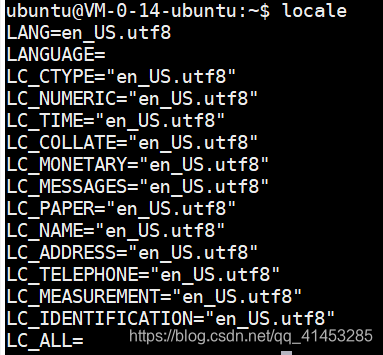
- 列出所有语系后,可以选择一项设置为自己想要设置的语系,也可以设置所有的语系(LC_ALL代表同步所有语系的设置值)
- 关于更多"locale"命令的介绍请参阅:https://blog.csdn.net/qq_41453285/article/details/87922188
- 设置所有的语系一致:
export LC_ALL=xxx- 设置单独一项的语系:
LC_xx=xxx三、演示案例
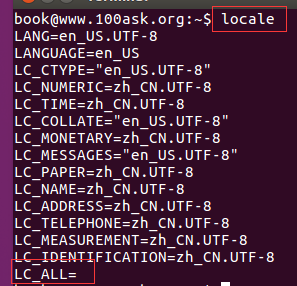
- 列出所有语系。LANG是主要语系的输出。LC_开头的是个别特殊的输出语系,LC_ALL代表LC_开头的所有语系设置
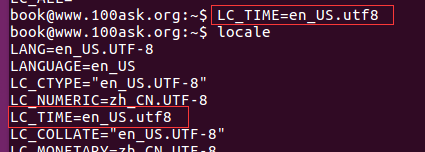
- 更改其中一项语系:下面以LC_TIME为例
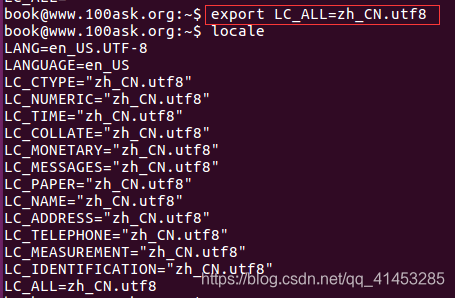
- 将所有语系都更改为一致的语系,LC_ALL前需要加export
四、中文编码问题
- 我们有时使用vim打开文件,会发现显示乱码。中文编码有Big5,GBK,UTF-8等,如果你的文件使用的是GBK编码,但是在vim终端界面使用的是UTF-8,则打开是就会显示乱码
- 原因:
- 你的Linux语系默认支持的语系数据,这与/etc/locale.conf有关
- 你的终端(bash)的语系,这与LANG、LC_ALLA这几个变量有关
- 你的文件原本的编码
- 打开终端的软件,例如在GNOME下面的窗口界面
- 解决办法:可以通过设置终端的语系
LANG=zh_CN.gb18030
export LC_ALL=zh_CN.gb18030五、文件语系编码转换(iconv命令)
- 概念:通过这个命令可以将一个文件的语系编码进行转换,这个命令是针对于文件而言的
- 命令格式:
iconv --list
iconv -f 原本编码 -t 新编码 原文件名 [-o 新文件名]- 相关参数与选项:
- --list:列出iconv支持的语系编码数据
- -l(小写的L):同上
- -f encoding:后面跟这个文件的原本编码
- -t encoding:后面跟你要转换的编码
- -o file:指定输出文件。如果你想将转换后的内容保存到一个文件中,可以使用这个选项
- -c:忽略输出的非法字符
- -s:禁止警告信息,但不是错误信息
- --verbose:显示进度信息
- 备注:语系的转换需要保证转换之后不会出错,否则可能会转换失败(例如我将ASCII文件转换为UTF-8文件的时候就一直不成功)
- iconv开发库可以参阅:https://blog.csdn.net/qq_41453285/article/details/106637833
演示案例
- 列出iconv支持的语系编码

演示案例(编码转换)
- 现在有一个UTF-16编码的文件UTF-16.txt(小端存储)

- 现在我们想将这个文件转换为UTF-8格式的文件,并且保存到UTF-8.txt文件中
iconv -f UTF-16 -t UTF-8 UTF-16.txt -o UTF-8.txt 
- 现在查看这个文件的类型

特殊案例(繁体中文/其他编码转简体中文)
- 将一个utf8编码的vi.utf8文件转换为简体中文gb2312编码的vi.gb.utf8文件
iconv -f utf8 -t big vi.utf8 | iconv -f big5 -t gb2312 | iconv -f gb2312 -t utf8 -o vi.gb.utf8- 我是小董,V公众点击"笔记白嫖"解锁更多【Linux入门基础】资料内容。



















 4038
4038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











