






 文章探讨了在大模型研究中如何降低硬件成本,提出了四个方向:效率提升(如PEFT)、利用现有预训练模型、即插即用的模块和数据集、评估与综述。重点介绍了参数效率微调方法,如Adapter和PromptTuning,以解决灾难性遗忘问题,并减少计算资源的使用。
文章探讨了在大模型研究中如何降低硬件成本,提出了四个方向:效率提升(如PEFT)、利用现有预训练模型、即插即用的模块和数据集、评估与综述。重点介绍了参数效率微调方法,如Adapter和PromptTuning,以解决灾难性遗忘问题,并减少计算资源的使用。
LLM高昂的硬件成本。大规模对于硬件的高昂要求举世皆知,即使是在微软加持之下的OpenAI也要疯狂控制交互次数。要想发挥出大模型当前已经取得的效果,如何更低成本就能部署一个大模型绝对是一个非常有研究价值的问题;而不必担心没有计算资源就不能研究这个问题。例如,如何在不影响Transformer的效果的情况下,能够使用更少的硬件资源、更完成高效的训练或推理,这样的研究只要在一个足以证明效果的模型上给出证明即可,不一定要在大模型上去完整的验证。
在此影响下,现在很多工作大力出奇迹,没有大力怎么出奇迹?没有计算资源如何选择合适的研究方向?我们提供四个方向。
四个方向
1. Efficient :
做效率提升的(哪里慢提升哪里的速度,哪里heavy使其轻量级)
例如:比较火的PEFT(parameter efficent fine tuning), 如何做大模型的微调。
2.Existing stuff(pretained model):
因为大规模训练对资源要求高,所以尽量避免做预训练,而是借助已有的模型,直接调用已有模型去做有意思的应用。直接用CLIP、VIT比直接微调简单很多。节省计算资源,有足够的时间迭代去扩展各个不同的领域。
上千篇论文直接调用CLIP模型去做非常有意思的应用,这些都很有影响力。CLIP出来之后能把Detection,Segmentation, Depth, Action, Audio所有的这些工作全都扩展开,不做预训练只做Fine-Tuning,计算资源可以节省很多。足够的时间迭代去扩展各个不同的领域。
同时也可以选新方向,避免撞车,竞争,刷榜。
3. Play-and-play:
尽量做通用的。即插即用的模块(模型,新的损失函数,数据增广的方法等等),总之是很简单的东西,但是可以在不同领域应用。好处是选你能承受的baseline,在你承受的设置下去做实验。公平对比足以说明你方法的有效性了。
4. Dataset,evaluation,and survey:
构建数据集,分析为主的文章,综述等文章。最不需要资源的,也非常有影响力,也让你对这个领域理解加深一些。
接下详细讲讲这四个方向
一:效率提升
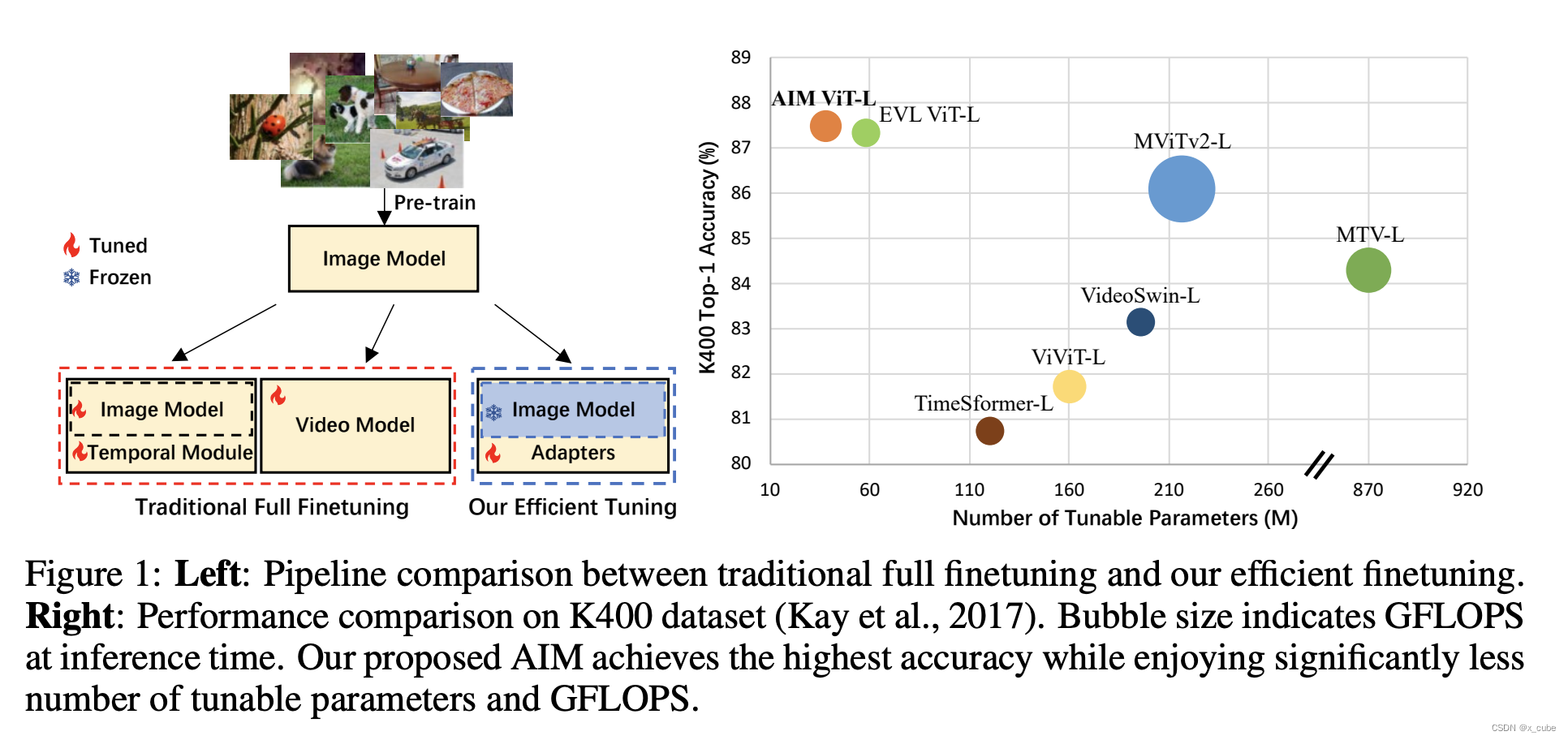
基于预训练模型进行训练。
第一类:时间空间分开
时间和空间分开训练。在已有图像模块之上,加了时序处理模块。
在已经有的模型基础上单独增加一些时序处理模块。比如TSN将视频劈成几段,把视频抽出来的特征做加权平均,在temporporal shift module,在channel维度上进行来回的shift,从而模拟时序建模。在最近的,Transformer做视频理解工作中,先做 Time Attention,然后再做这个spatial Attention,把两者劈开来做。
第二类:
时间和空间一起学,主要是3D网络(例如i3D)或者Transformer时代的Video Swing,把2D的Shitfed window变成了3D的Shitfed window。总之输入的是3D的输出也是,是一个Joint Modeling的过程。
前两者的缺点
虽然效果好,但是代价大,需要 Full Fine Tune的,整个模型的参数都有拿下来在这个数据集做Fine Tune。本身数据集比较大,数据的IO一般也有Bottleneck, 模型本身也比较大,所以训练的Cost,非常昂贵。
第一类需要8卡机3到5天。Backbone特别大需要可能需要一周到十天的样子。稍微轻量些。
第二类Video Swing使用预训练模型,Fine Tune。还有从头训练Train From Sketch,这个需要更长时间。比如MaskFit,Video MAE自监督学习,训练代价以周为计算单位的。复现模型都很困难。
方向:如何把视频理解做的更亲民?
做过Gluon-cv视频开源,也写过综述,最近也准备在视频数据集上下功夫。
Clip(对比学习)模型, 需不需要微调?几个原因
1)即使ZeroShot它的效果很好,模型不变直接在各个数据集做推理。部分验证了这个假设。当有一个及其强大的已经训练好的这个图像模型之后,我们可能不需要Fine-Tune这个部分。
2)防止灾难性遗忘。如果已经训练好的一个特别大的模型,参数量也特别多。如果你下游任务没有很好(很多)的数据集,训练效果不好要么就直接overfit了。即使你能在你下游任务上表现的好,但是他有灾难性遗忘的这个特性,之前大模型有的特性全部丢失了,泛化性可能也丢失了,是件得不偿失的事情。
想尝试这条路,通过修改周边的方式,让模型具有时序建模的能力。从而让图像模型做视频理解的任务。就是拿来有效的image modal之后,能不能直接就把它这个模型参数锁住。在他上面加一些时序处理的模块,或者加一些新的目标函数。不需要从头训练视频模型,省时省力。
补充:灾难性遗忘
定义:
在新的数据集上训练模型,会遗忘掉旧数据上学习到的知识,在旧数据上测试会发生很大的掉点。
形成原因:
造成灾难性遗忘的一个主要原因是「传统模型假设数据分布是固定或平稳的,训练样本是独立同分布的」,所以模型可以一遍又一遍地看到所有任务相同的数据,但当数据变为连续的数据流时,训练数据的分布就是非平稳的,模型从非平稳的数据分布中持续不断地获取知识时,新知识会干扰旧知识,从而导致模型性能的快速下降,甚至完全覆盖或遗忘以前学习到的旧知识。
为了克服灾难性遗忘,我们希望模型一方面必须表现出从新数据中整合新知识和提炼已有知识的能力(可塑性),另一方面又必须防止新输入对已有知识的显著干扰(稳定性)。这两个互相冲突的需求构成了所谓的「稳定性-可塑性困境(stability-plasticity dilemma)」。
解决灾难性遗忘最简单粗暴的方案就是使用所有已知的数据重新训练网络参数,以适应数据分布随时间的变化。尽管从头训练模型的确完全解决了灾难性遗忘问题,但这种方法效率非常低,极大地阻碍了模型实时地学习新数据。而增量学习的主要目标就是在计算和存储资源有限的条件下,在稳定性-可塑性困境中寻找效用最大的平衡点。
场景:
- 相同任务,数据集不同,新数据和旧数据相似度高:finetuning效果可以
- 相同任务,数据集不同,新数据和旧数据相似度低:出现灾难性遗忘
- 不同任务或者有新增任务:出现灾难性遗忘
分析:
一个网络学完任务后权重,学习新的任务后可能完全变掉。理论上新旧任务可以实现重用的,分清任务目标能否找到一个基础网络层,这个解决方案就是常见的多任务学习。
多任务学习一个问题随着任务的增多新的任务就难训练,因为多个loss累加在一起,后加入的loss被优化的压力慢慢会变小,优化的压力会分摊到所有的loss上,而且这样也会带来训练上的成本,如果能在训练完一个任务后,再训练一个新任务,而老任务学到的东西不会遗忘就好了,这就产生了增量式学习的概念,也叫持续学习。(每增加一个loss,旧的不会被遗忘。)
增量学习和持续学习(Continual Learning)、终身学习(Lifelong Learning)的概念大致是等价的。
增量学习的方法主要有三种:
- 正则化:通过给新任务的损失函数施加约束的方法来保护旧知识不被新知识覆盖。
- 回放:基本思想就是"温故而知新"。在训练新任务时,一部分具有代表性的旧数据会被保留并用于模型复习曾经学到的旧知识,要保留旧任务的哪部分数据,以及如何利用旧数据与新数据一起训练模型」,就是这类方法需要考虑的主要问题。
- 参数隔离
其中基于正则化和回放的增量学习范式受到的关注更多,也更接近增量学习的真实目标,参数隔离范式需要引入较多的参数和计算量,因此通常只能用于较简单的任务增量学习。
周边加什么?PEFT试下。
传统的范式对大数据进行大模型预训练,然后对下游任务微调。然而模型变的越来越大,硬件资源有限,全部参数微调变得不可行。而且为每个下游任务独立存储和部署微调模型变得非常昂贵。因为微调模型与原始预训练模型的大小相同。参数高效微调(PEFT) 方法旨在解决这两个问题!
PEFT 方法仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。这也克服了灾难性遗忘的问题,这是在 LLM 的全参数微调期间观察到的一种现象。PEFT 方法也显示出在低数据状态下比微调更好,可以更好地泛化到域外场景。它可以应用于各种模态,例如图像分类以及 Stable diffusion dreambooth。
以下是目前支持的 PEFT 方法:
LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Prefix Tuning:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
P-Tuning: GPT Understands, Too
Google Colab 中 whisper-large 模型的 INT8 训练以及使用 PEFT 方法调整 RLHF 组件 (例如策略和排序器) whisper large
一:PEFT中比较普遍的方法:Adapter和Prompt Tuning
1. Adapter
1. Adapter来自2019年Parameter-Efficient Transfer Learning for NLP
CV用这个原因是大家都用Transformer做backbone,NLP能用的大概率也能在这用,可以很好的迁移过来。所以这些PEFT的技术,或者比较火的in-context learning, RLHF(reinforcement learning with human feedback)基于强化学习都会快速应用到视觉里面。
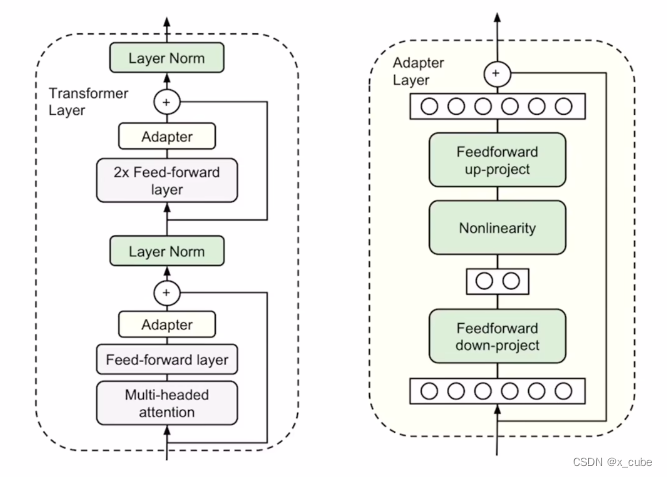
是一个下采样的FC层,再过一个非线性的激活层,上采样的FC层加上残差连接。 像一个即插即用的模块一样,可以插到Transformer Layer里的任何一个地方。在attention后面插一个,MLP后面加一个Adapter。
加他的作用以及为什么叫PEFT?因为原来训练好的Transformer他是不动的,参数是锁住的,微调的过程中完全没有梯度更新,只有新添加的Adapter层在不停地学习。所以它的参数量是非常之少的,只有几十B或者几百B,相比于几million的新参数量可以完全忽略不计了。比如新出来的peft方法中,LOLA(Learning with Opponent-Learning Awareness)这个论文的摘要说GPT-3,17B的模型里使用LOLA,最后需要训练的模型参数只是原来模型的万分之一,节省可训练的模型参数,非常有影响力的。
Adapter其实跟CV之前的18年的一篇论文,《SENet:Sequeeze and Excitation Network》,这个Channel Attention非常相近,所以很多方法都有共同性的。
2. Prompt Tuning
预训练模型微调(Fine-tuning),根据不同下游任务引入各种辅助任务loss和垂直领域数据,将其添加到预训练模型中,以便让模型更适配下游任务的方式。每个下游任务都存下整个预训练模型的副本,并且推理必须在单独的批次中执行。
那么能不能将所有自然语言处理的任务转换为语言模型任务?就是所有任务都可以被统一建模,任务描述与任务输入视为语言模型的历史上下文,而输出则为语言模型需要预测的未来信息。因此,Prompt新范式被提出,无需要fine-tune,让预训练模型直接适应下游任务。Prompt方式更加依赖先验,而 fine-tuning 更加依赖后验。
论文《GPT Understands, Too》中的Prompt tuning,称为P-tuning v1,代码
《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》代码,称为P-Tuning v2。
2.1 P-Tuning v1
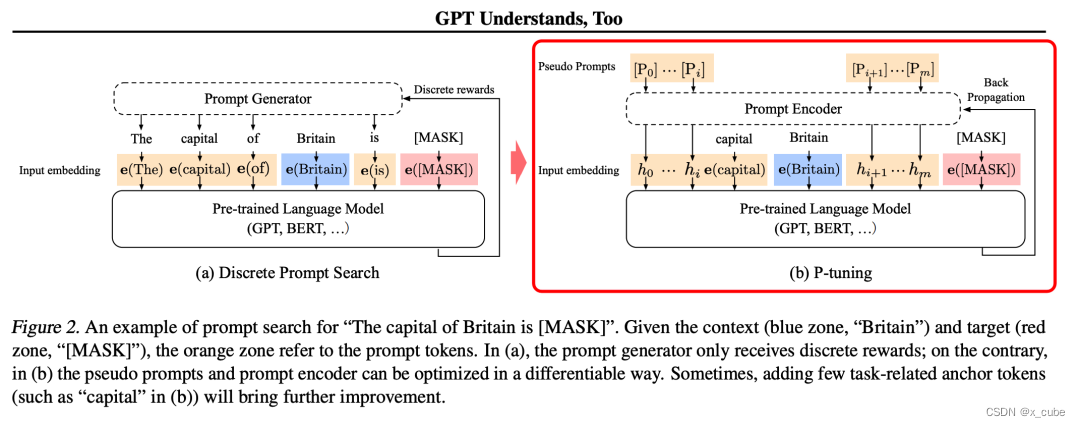
主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode(离散token)再与input embedding进行拼接,同时利用LSTM进行 Reparamerization 加速训练,并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果。然后结合(capital,Britain)生成得到结果,再优化生成的encoder部分。
P-tuning v1有两个显著缺点:任务不通用和规模不通用。
2.2 P-Tuning v2
相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。对于不同的任务和模型结构需要不同的prefix,论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
V2版本主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
将Prompt tuning技术首次拓展至序列标注等复杂的NLU任务上,而P-tuning(v1)在此任务上无法运作。
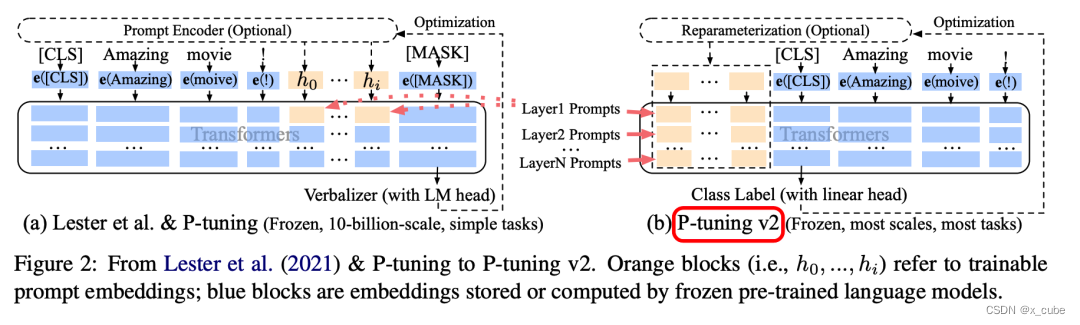
v1只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。
p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。
v2变化:
移除了Reparameterization,舍弃了词汇Mapping的Verbalizer的使用,重新利用CLS和字符标签,来增强通用性,这样可以适配到序列标注任务。此外,作者还引入了两项技术:
-
Deep Prompt Encoding:
采用 Prefix-tuning 的做法,在输入前面的每层加入可微调的参数。使用无重参数化编码器对pseudo token,不再使用重参数化进行表征(如用于 prefix-tunning 的 MLP 和用于 P-tuning 的 LSTM),且不再替换pre-trained word embedding,取而代之的是直接对pseudo token对应的深层模型的参数进行微调。
-
Multi-task learning:
基于多任务数据集的Prompt进行预训练,然后再适配到下游任务。对于pseudo token的continous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训练多个数据集,共享continuous prompts去进行多任务预训练,可以让prompt有比较好的初始化。
2.3 hard Prompt
借用CoOP,对图片进行分类,如何给Prompt?
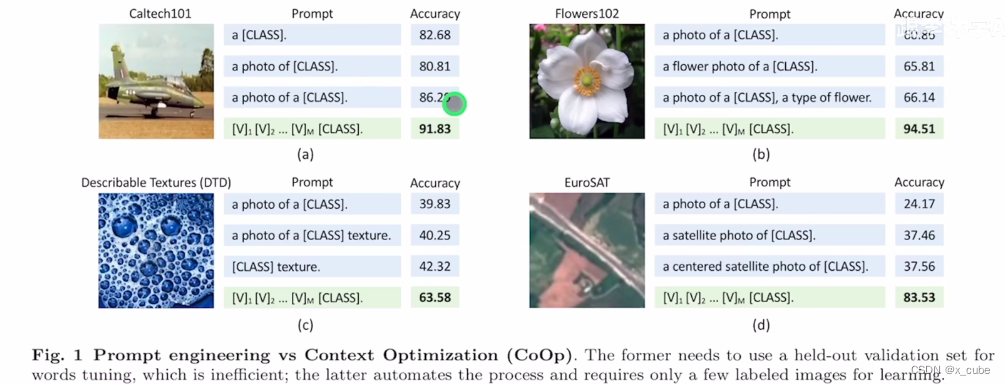
将这些[class]类别名称,我把这个类别名称一个一个给它,看哪个文字和图片相似度最高。Tuning体现在Prompt可以各种各样的调,可能最后的影响非常之大。
很火的原因是它对性能的影响非常之大。你能否得到很好的结果很大程度上取决你有没有选择一个很好的Prompt。手工写的叫hard Prompt,不能动也不能学。
2.4 soft Prompt
hard Prompt 需要先验知识,但是我们不知道先验知识是否有用。所以我们来学不就好了吗? CLIP使用手工模板做到了Zero-shot,并取得了非常出色的性能表现。但是,因为手工模板对于改动非常敏感,不同的模板可以产生差距巨大的效果。因此,CoOp提出,将模板的选择权交给模型来决定。
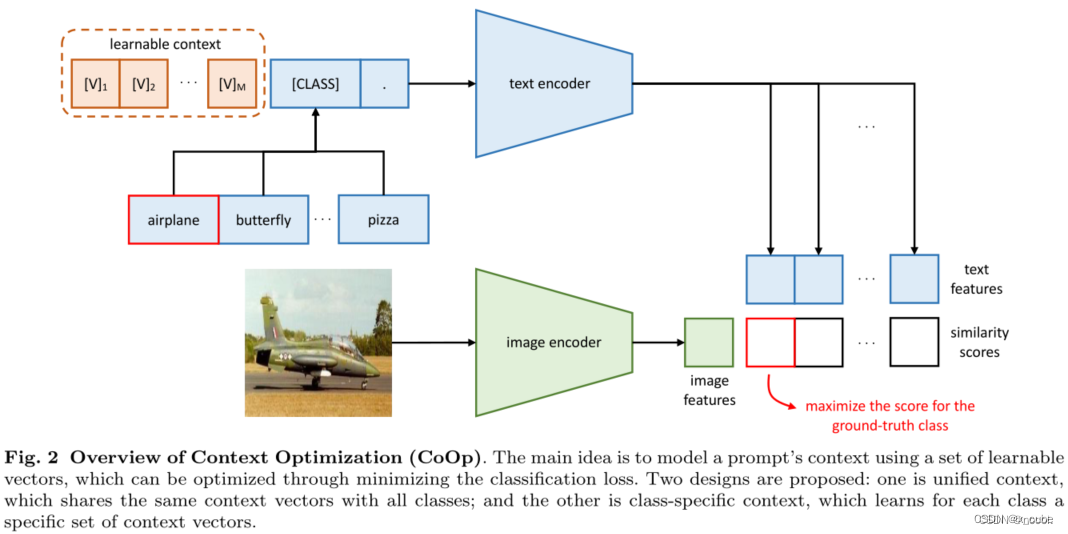
把hard Prompt变成soft Prompt,学习它。和DETR的那个learnable query一样,一个可学习的向量,训练过程中模型锁住不变,只根据loss调整这个Prompt。 总览图和clip做推理一样,区别是在训练的,文本输入不是固定的,而是可以学习的内容,所以起名就是context optimization,主要优化Prompt这个可学习向量。
2.5 Visual Prompt
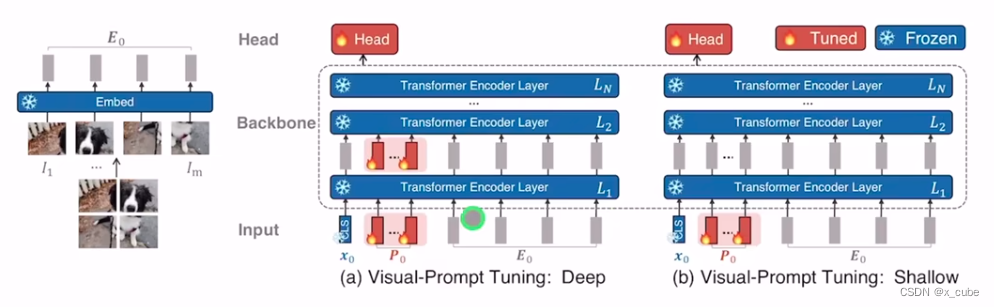
Prompt加在哪里?提出了两种方式,一个是VPT Deep,一个是VPT Shallow,前者增加了可学习的参数量,一般效果更好。两者都比不用Prompt要好。
2.6 通性
当你已经有一个已经训练好的大模型时候,我希望模型是锁住不动的。这样不光有利于我的训练,而且有利于部署。而且性能还不降,不降反升。
博文《PEFT:Parameter-Efficent Fine-Tuning of Billion-Scale Modals on Low-Resource Hard ware》
类似综述《Towards a Unified View of Parameter-Efficient Transfer Learning 》总结了PEFT的方法。
3. 如何加周边?
到底应该插在哪?每个Transformer block到底插几个?
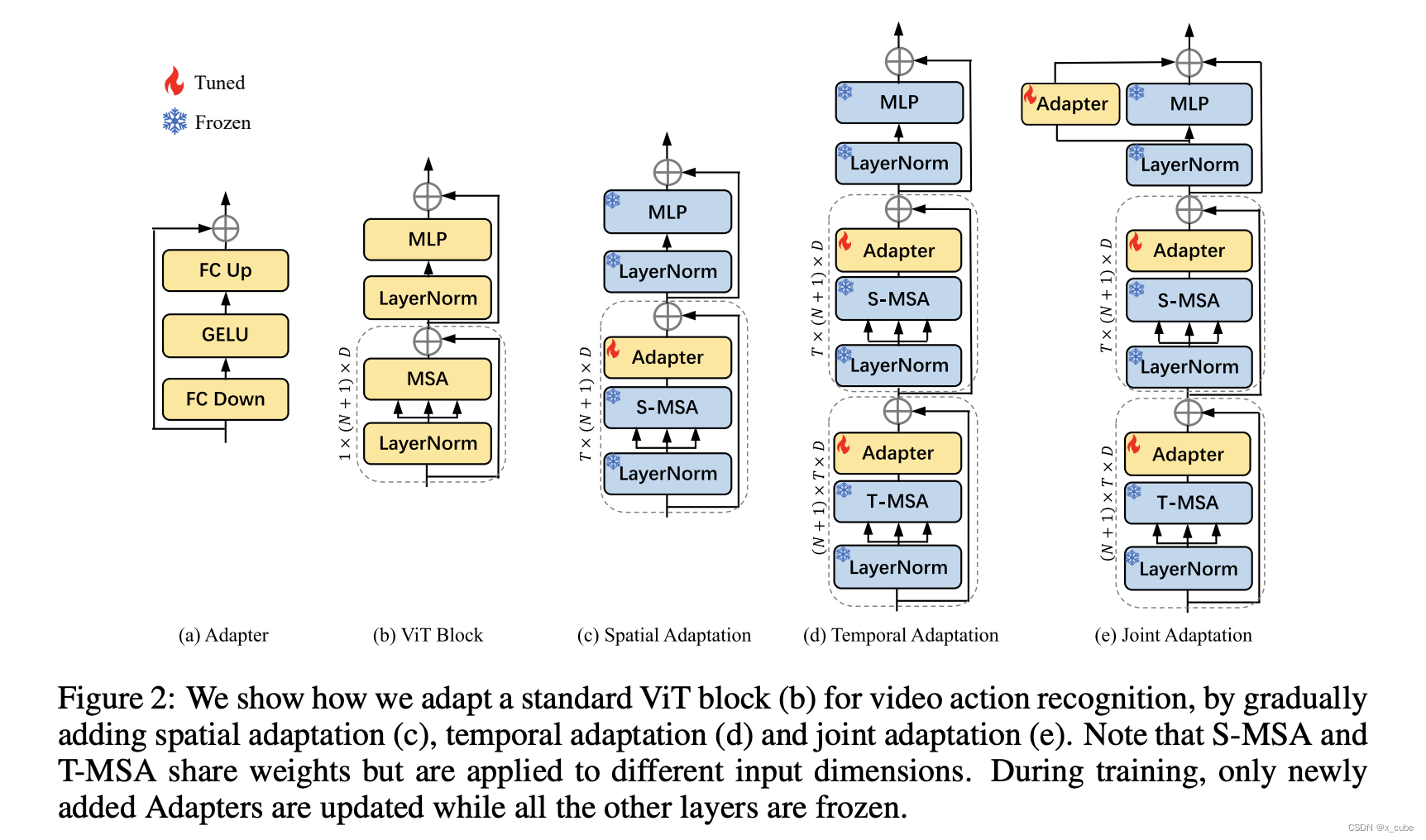
视频计算量很大,用过PEFT只要八卡机短则半天,长则三四天。
组里另一篇用Prompt Tuning做Test Time Adaptation,本身比视频省计算资源很多,4卡机。
如何把Attention做成Efficient Attention?
比如Lean Former、Performer、Flash Attention 这些Attention的近似, Flash Attention更省内存,而且效果好,已经应用到文字生成图像。
二: Existing stuff
尽量不要碰预训练,现在规模越来越大,尽量Zero-Shot,不能Zero-Shot,就Few-Shot,实在不行就Fine Tuning。
Language Guided Segmention,VOC unsupervised,利用Swing做Remote Sensing地理任务。
最多就是Fine-Tuning的实验加上一些比较新的topic,比如Causality Learning因果学习,或者说Hinton之前提出的这个Feedforward Network , FFNet。或者说Language那边的In-Context Learning或者Chain of Thought Prompting。Aston那个AI鼓励师,COT。这些topic都很新很有前途,很快成为新的研究热点。
三:即插即用
- 既可以是模型上的一个模块,比如非局部模块,在已有的ResNet后加一个非局部;
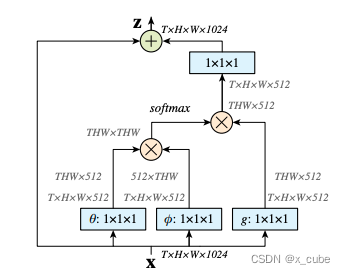
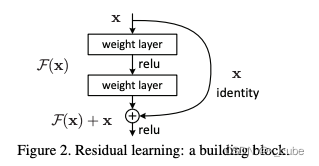
非局部(non-local) 模块把非局部感受野的信息提取操作做成一个神经网络模块,方便了端到端的视频分析。
左图输入是X是32帧的视频(32张图片帧数 T=32,长宽为H×W)。左端的跳层连接,为了把视频额外的时空信息提取作为一个残差操作,这样模块可以任意插入一个残差网络中。
参考:https://arxiv.org/pdf/1711.07971.pdf
Deep Residual Learning for Image Recognition | IEEE Conference Publication | IEEE Xplore
CVPR2018精选#2: 视频分析的非局部(non-local) 神经网络模块,CMU与Facebook AI研究室视频分类识别新贡献 | David 9的博客 --- 不怕"过拟合"
- 目标函数把正常的Loss换成Focal Loss;
Focal Loss的引入主要是为了解决one-stage目标检测中正负样本数量极不平衡问题。
Focal Loss损失函数(超级详细的解读)_BigHao688的博客-CSDN博客
- 数据增强,方法通用,不受任务或模态的限制。
比如Mixup,有几十种Mixup的变体。它最初用在图像分类里的,后来用在检测,分割, 视频,文本,多模态等。
mixup对两个样本-标签数据对按比例相加后生成新的样本-标签数据。变种的方法有
cutMix,manifold mixup,patchUp,puzzleMix,saliency Mix,fMix,co-Mix

(一开始想在多模态加上Knowledge distillation蒸馏,在看VLMo那篇论文,自注意力的参数都能共享,为什么不能拿一个文本的大模型来蒸馏一个小模型,或者拿视觉的模型也去蒸馏这个文本模型。加了蒸馏之后这个训练Pipeline也变得更复杂了,涨幅不超过一个点。还得选到底选择用什么teacher来做知识蒸馏,这样又会多很多消融实验。计算开销也会随这个Teacher模型变大而变大。
clip用简单的Random Resized Crop,因为认为数据很多了,所以不需要数据则增强。还有ALBEF,还有后续的BEIT。虽然用了很好的数据增强,比如Auto Augment,但是把里面的Color Jittering和Random Flip给去掉了。原因是位置和颜色的变化,使文本和图片不再是一对了。)
为什么不用多模态的数据增强?
原来的图像文本对,可能不再是一对。也就是说做信息增强有的会被改变或者丢失了,所以导致他们两个不匹配。怎么才能让信息不丢失?不去毁坏它原来的东西。天然的选择就是Mixup,将两张图片线性的插值到一起,人眼看的比较诡异,毕竟只是加了起来,所以该有信息都还在里面。
文本那边如何保留信息?Mixup,还有Random Erasing, Random Insertion,Back Translation各种增强方法。直接将两个句子拼接在一起就行了,这样什么信息都不回丢失。所有的单词还在新生成的句子里面,得到MIxGen的雏形。两张图片做Linear Interpolation。
数据增强一般在没有足够多的数据时候,才做。但是你有很多数据。但是在多模态下游任务里,当您做transfer的时候,你的数据集不多,所以考虑在Fine-Tuning的时候用数据增强。但是在每个不同的下游任务里,这个Mixed Gen 的形式会变一变。
为什么即插即用对计算资源要求会少?
如果你想要一个东西,非常的有效,做了大量的实验任务去验证,可能花费的资源也不少。但是有一个好处就是只想验证有效性,证明这个方法有用,你不需要达到最高效果,不需要刷榜。或者在很多数据集上有统一的提升就可以。
证明方法的有效性不一定非要拿到数据集上的第一,即使拿到第一你可能只是overfit,反而不能证明你多有效。往往是那些很简单的能泛化到各种各样的任务,数据集上,才是真正有效的。这个时候你可以选择很多baseline,自己定一个setting,让他们能够公平比较。这个setting可大可小,可以根据你的计算资源来定。只要在setting里面加上你这个即插即用的模块之后,都能有统一的涨点。你也能给出合适的分析,那就非常有说服力。
四:Dataset,evaluation,and survey
做数据集,纯分析,写一篇综述。比如HELM。将已有的数据集,三个合在一起《BigDetection:A Large-scale Benchmark for Improved Object Detector Pre-training》,不是简单的合在一起,每个数据集也不是完全一样的,如何merge这些class?如何重新分布这些类别,而且根据你任务的需求,是预训练?下游任务?到底想target哪一个domain,这决定你物体类别到底该多细粒度,都是研究方法,都可以写论文。可以在上面做一些out of distribution的分析。robustness的分析。few-shot、 zero-shot的各种分析和评测。做新的数据集提出新的evalution metric,去主页找。
视频综述论文举例,想写很细碎的点,就索性写一篇综述。有助于帮你理解已有的这些方法,这些优点和缺点都在哪?所有方法的limitation都在哪?现在的痛点以及未来的future work该在哪个方向上发力。都是通过evaluation的工作,大家才能找到这些insight。 evaluation可能只是做inference,就算做一下训练,更多的时候可能只是Fine Tuning,或者在小范围上做这个训练。考验的事写作能力和你对问题的清晰程度。
参考:
大模型时代下做科研的四个思路【论文精读·52】_哔哩哔哩_bilibili
增量学习(Incremental Learning)小综述 - 知乎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









