






I know, i know
地球另一端有你陪我
一、AZKABAN
一个 JAVA 编写的、开源的,任务调度工具
linux 中自带 crontab 的调度工具,但是只能够定时启动
而较难处理多个任务调度之间的依赖关系
1、安装
1 上传解压文件
unzip azkaban-solo-server.zip
2 修改配置文件中的时区
vim conf/azkaban.properties
// 修改时区
default.timezone.id=Asia/Shanghai
3 启动貌似一定要在外面一层启动,很怪
cd /usr/local/soft/azkaban-solo-server
./bin/start-solo.sh
4 访问 azkaban 控制页面
http://master:8081
用户名 / 密码:azkaban / azkaban
5 添加邮箱,可选操作
vim conf/azkaban.properties
mail.sender 发送方
mail.host 邮箱服务器的地址
mail.user 用户名
mail.password 授权码
增加以下配置
mail.sender=987262086@qq.com
mail.host=smtp.qq.com
mail.user=987262086@qq.com
mail.password=aaaaa
重启azkaban
cd /usr/local/soft/azkaban-solo-server
关闭
./bin/shutdown-solo.sh
启动
./bin/start-solo.sh
2、使用方法
1 先新建一个项目(projet)
2 接着需要现在网页中下载配置模板
3 会得到一个压缩包(jobs.zip),包含两个文件
flow20.project(这个是配置对应的版本号,不用改)
basic.flow(这个是需要修改的指令文件)
---
config:
day_id: $(new("org.joda.time.DateTime").minusDays(1).toString("yyyyMMdd"))
nodes:
- name: start-dwd-res-regn-mergelocation-msk-d
type: command
config:
command: sh /home/dwd/start-dwd-res-regn-mergelocation-msk-d.sh ${day_id}
- name: start-dws-staypoint-msk-d
type: command
config:
command: sh /home/dws/start-dws-staypoint-msk-d.sh ${day_id}
dependsOn:
- start-dwd-res-regn-mergelocation-msk-d
- name: start-ads-city-tourist-msk-d
type: command
config:
command: sh /home/ads/start-ads-city-tourist-msk-d.sh ${day_id}
dependsOn:
- start-dws-staypoint-msk-d
config
获得当前时间,再减去 1 (T - 1 原则)
node
需要调度的指令,需要注意的是,由于无法在文件路径下直接启动指令
因此需要写绝对路径的
相对的,sh 文件中的路径,也需要使用绝对路径,
在 sh 脚本文件中添加以下指令可以获取并进入脚本执行位置,让代码相对简洁
#获取脚本所在目录
shell_home="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
#进入脚本目录
cd $shell_home
4 修改完之后,打包回 zip 文件,并上传
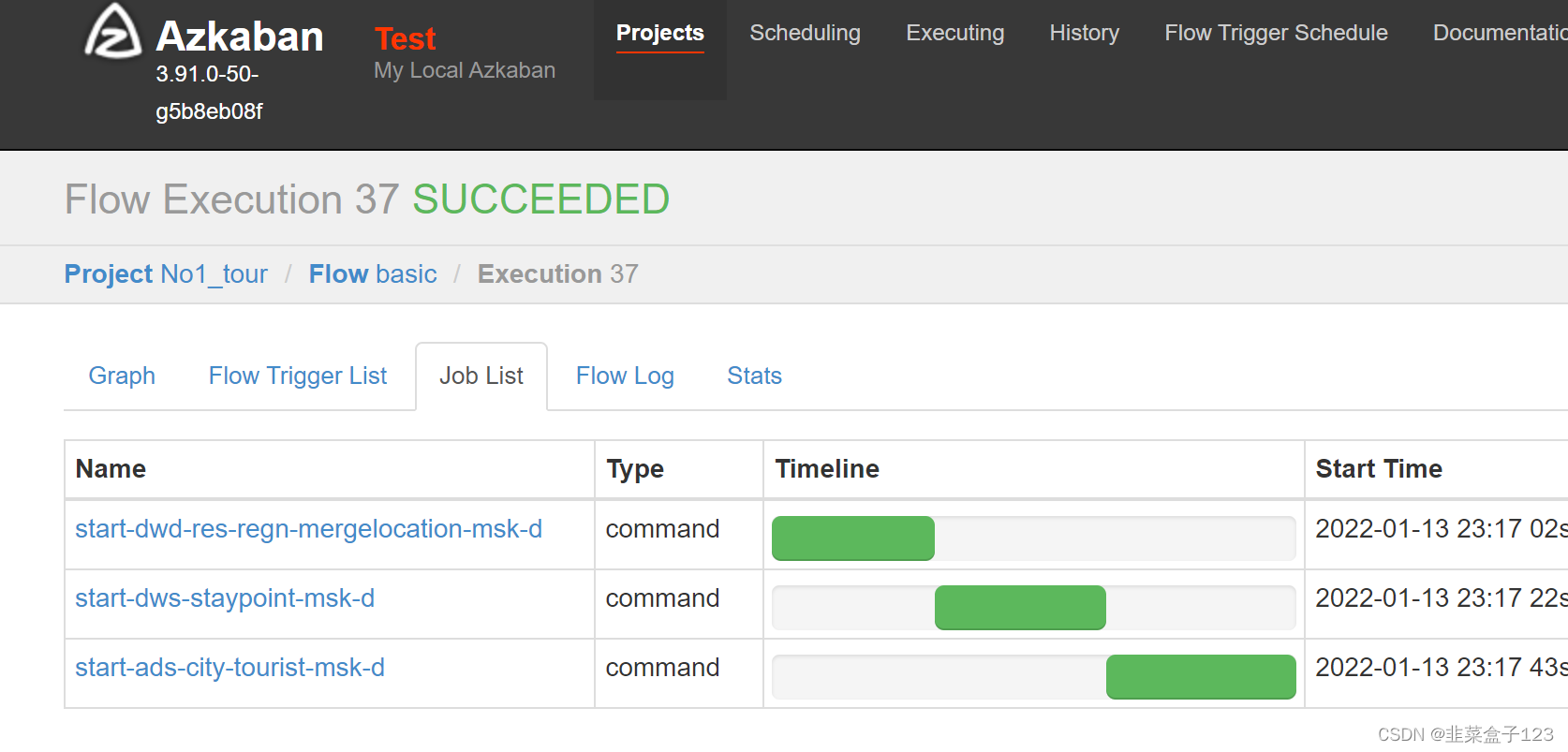
5 进入项目后,可以选择执行调度或执行一次。之后就是点点点了

6 此处可以看到历史任务和过程日志等
二、KYLIN
Apache Kylin是一个开源的、分布式的分析型数据仓库,
提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力,
以支持超大规模数据,能在亚秒内查询巨大的表
会将表中按照提供的高频字段作为维度预计算,将可能会使用的结果提前运算储存
1、安装
要求虚拟机主节点(master)的内存达到 3G 以上
1 上传解压配置环境变量
tar -xvf apache-kylin-2.5.0-bin-hbase1x.tar.gz
mv apache-kylin-2.5.0-bin-hbase1x kylin-2.5.0
2 添加环境变量,需要额外添加一个 hive 配置的路径
export KYLIN=/usr/local/soft/kylin-2.5.0/bin
export HIVE_CONF=/usr/local/soft/hive-1.2.1/conf
由于目前还用不到 kafka 可以先注释掉,并
unset KAFKA_HOME
3 在 master 启动 jobhistory
mr-jobhistory-daemon.sh start historyserver
4 启动 zookeeper
zkServer.sh start
zkServer.sh status
5 启动 hbase
start-hbase.sh
6 验证环境是否可行,并启动
check-env.sh
kylin.sh start
7 访问 KYLIN
http://master:7070/kylin
用户名 / 密码
ADMIN / KYLIN
2、使用方法
1 新建项目 No1_tour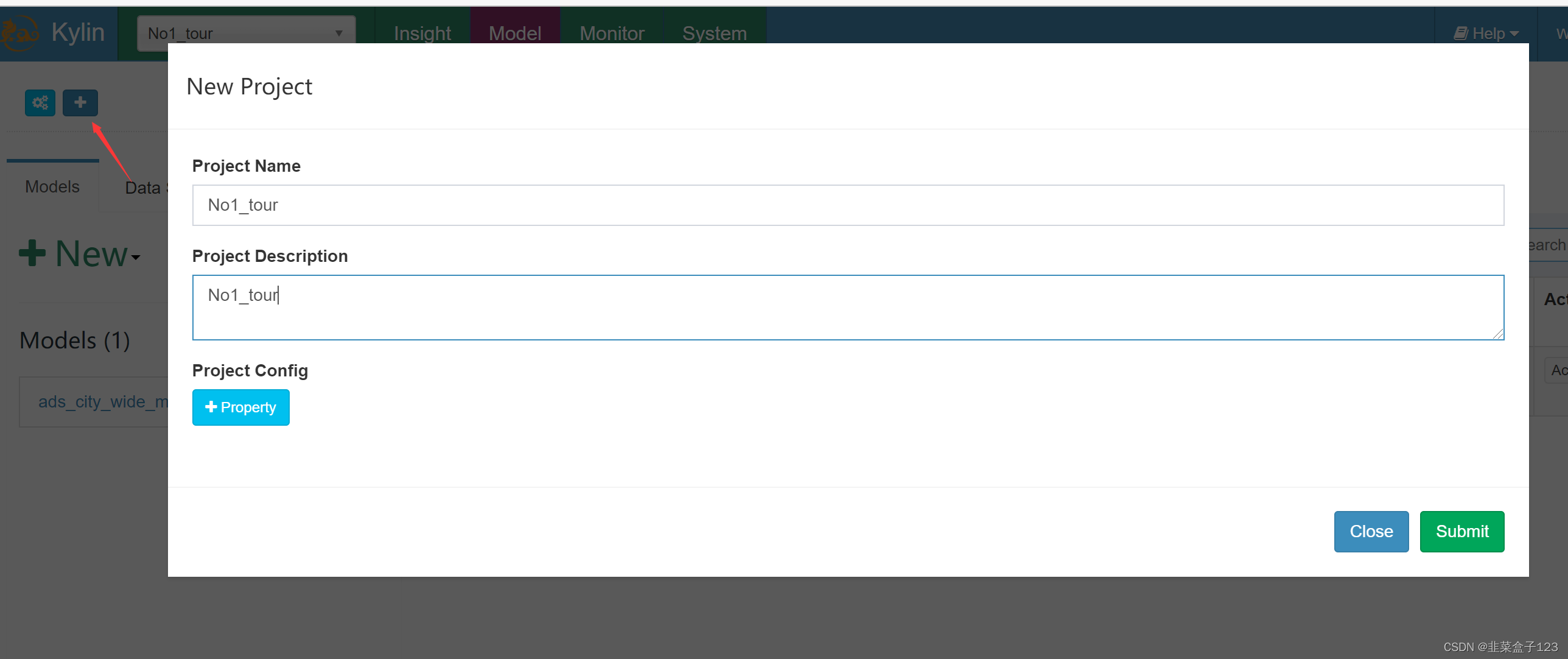
2 从 hive 中获取数据(会自动连接到 hive 数据库)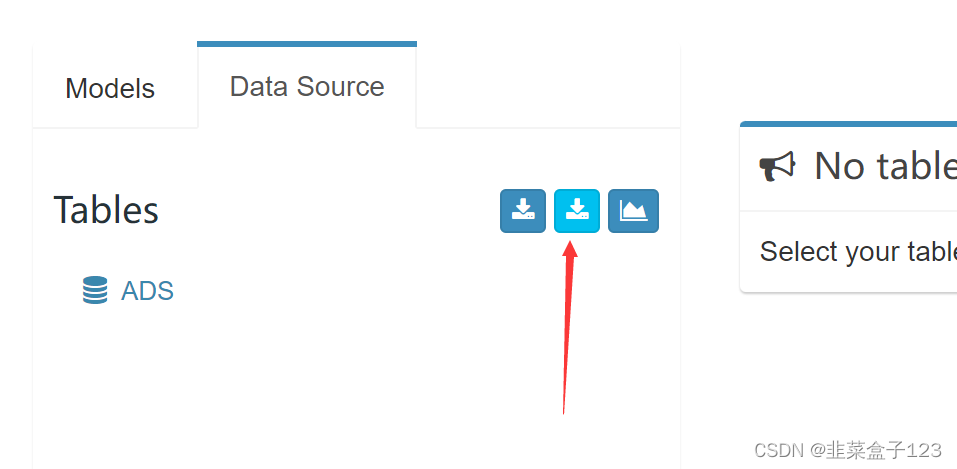
3 起始页新建 model,注意这两处选择维度、度量,和最后的分区字段格式
维度:表在聚合时,可能作为聚合标准的字段
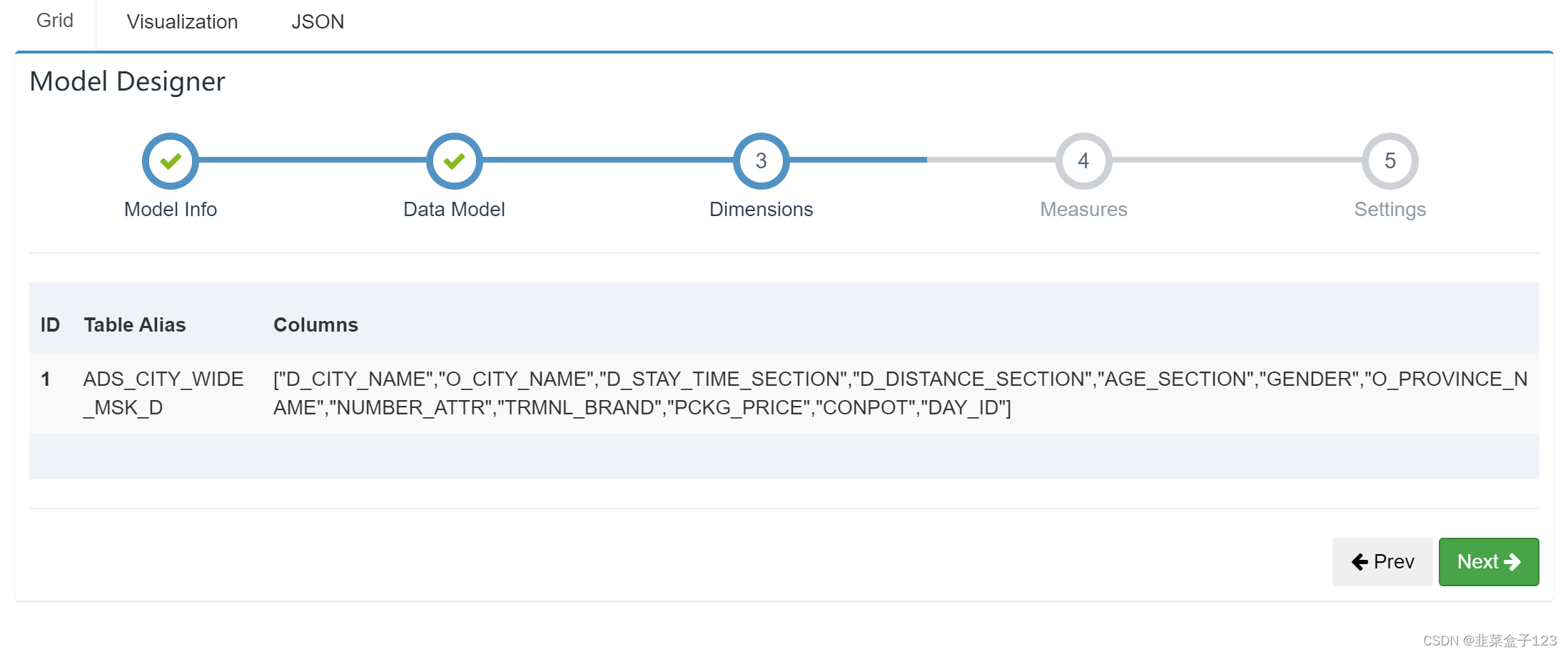
度量:在完成聚合后,会作为计算标准的字段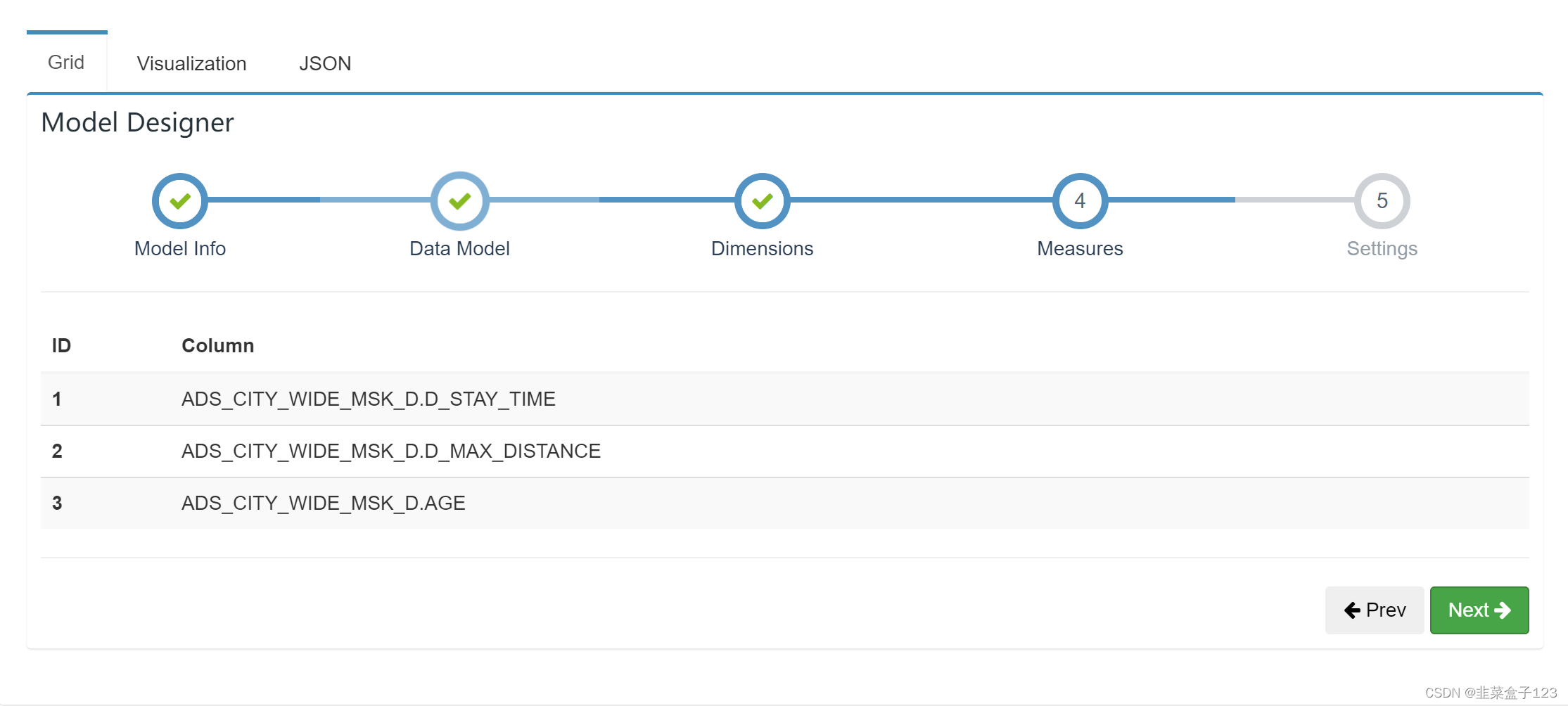
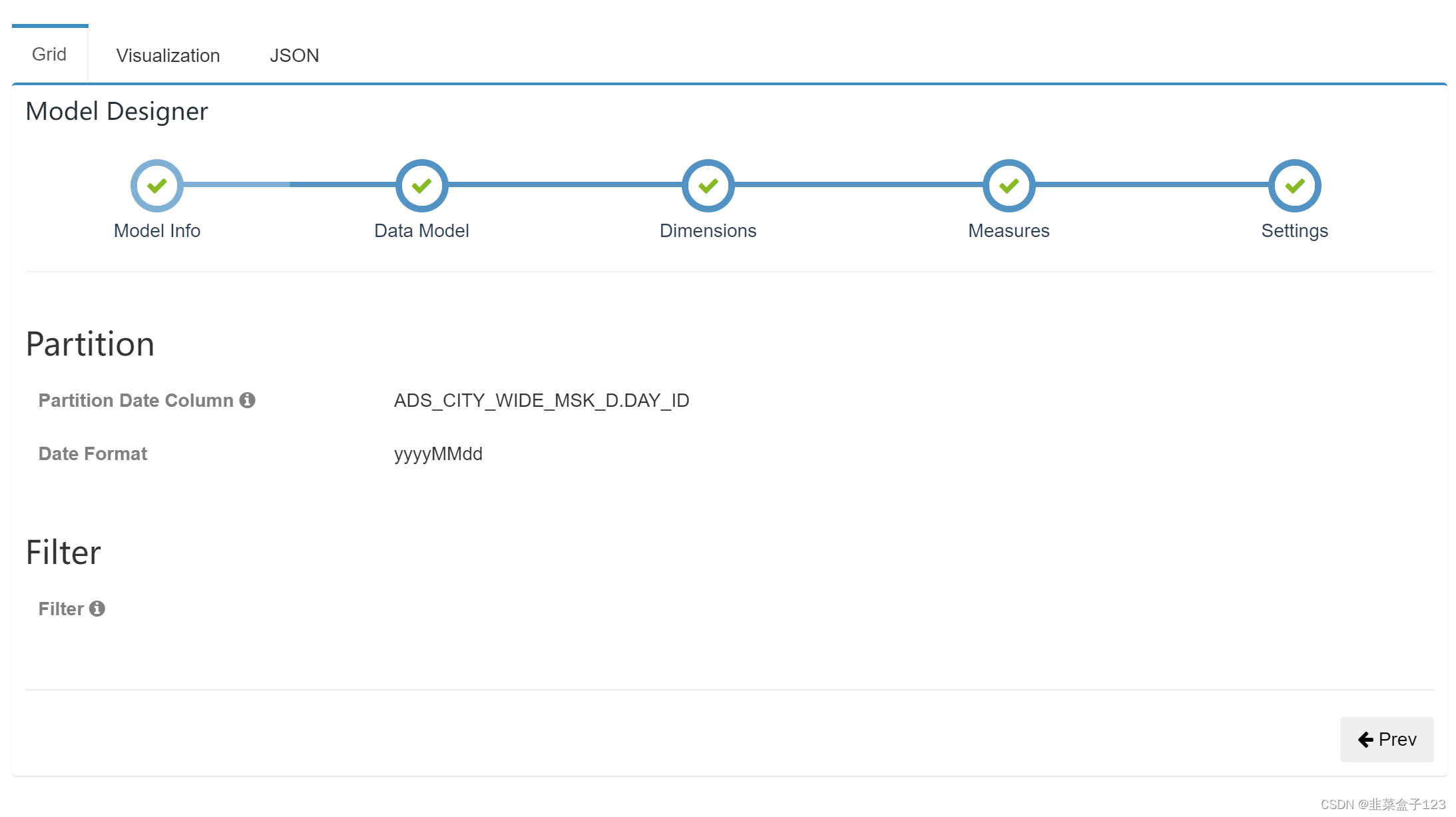
分区字段选择与格式
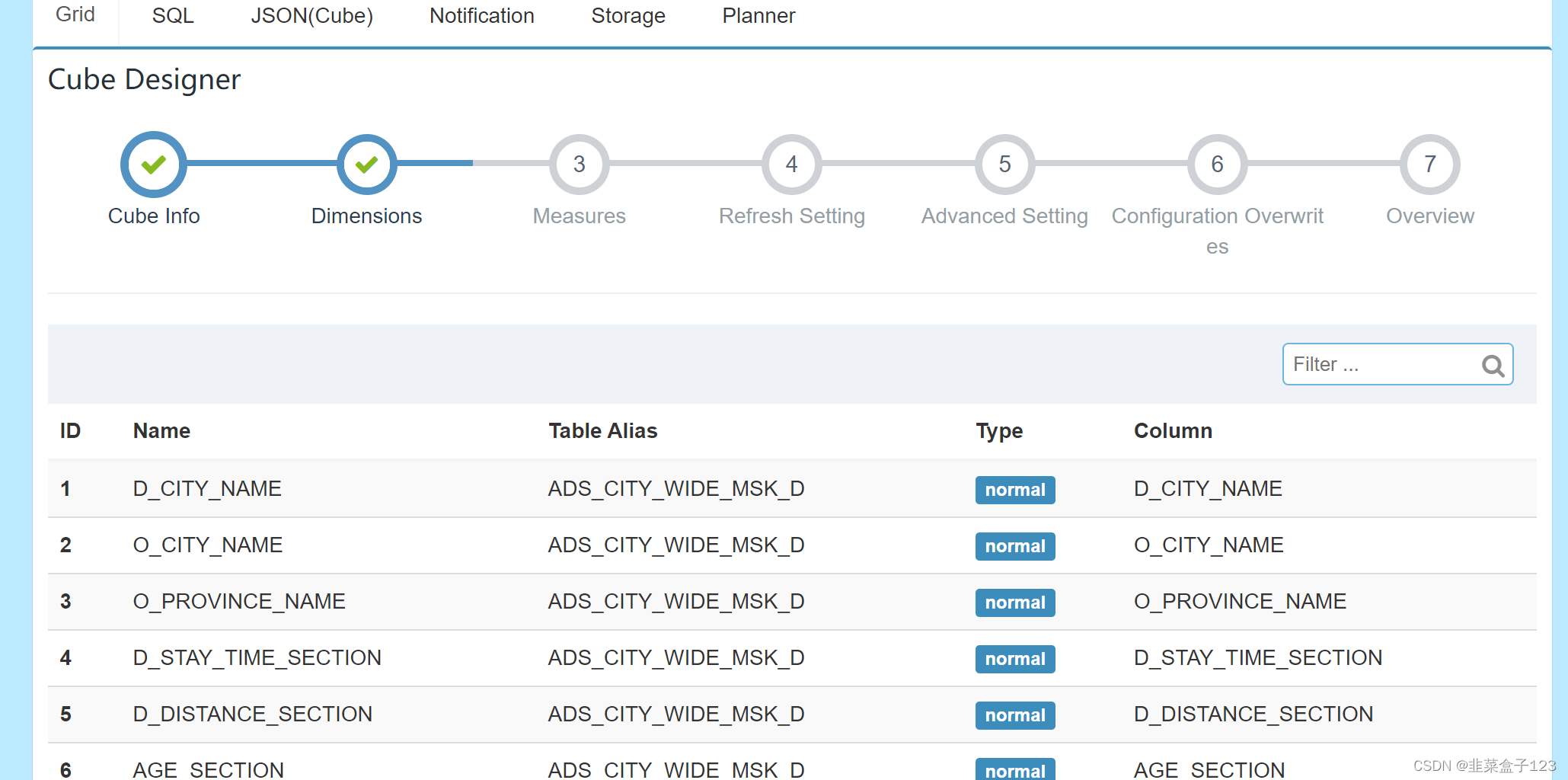
4 起始页新建 cube(立方)
选择 model 中的所有维度
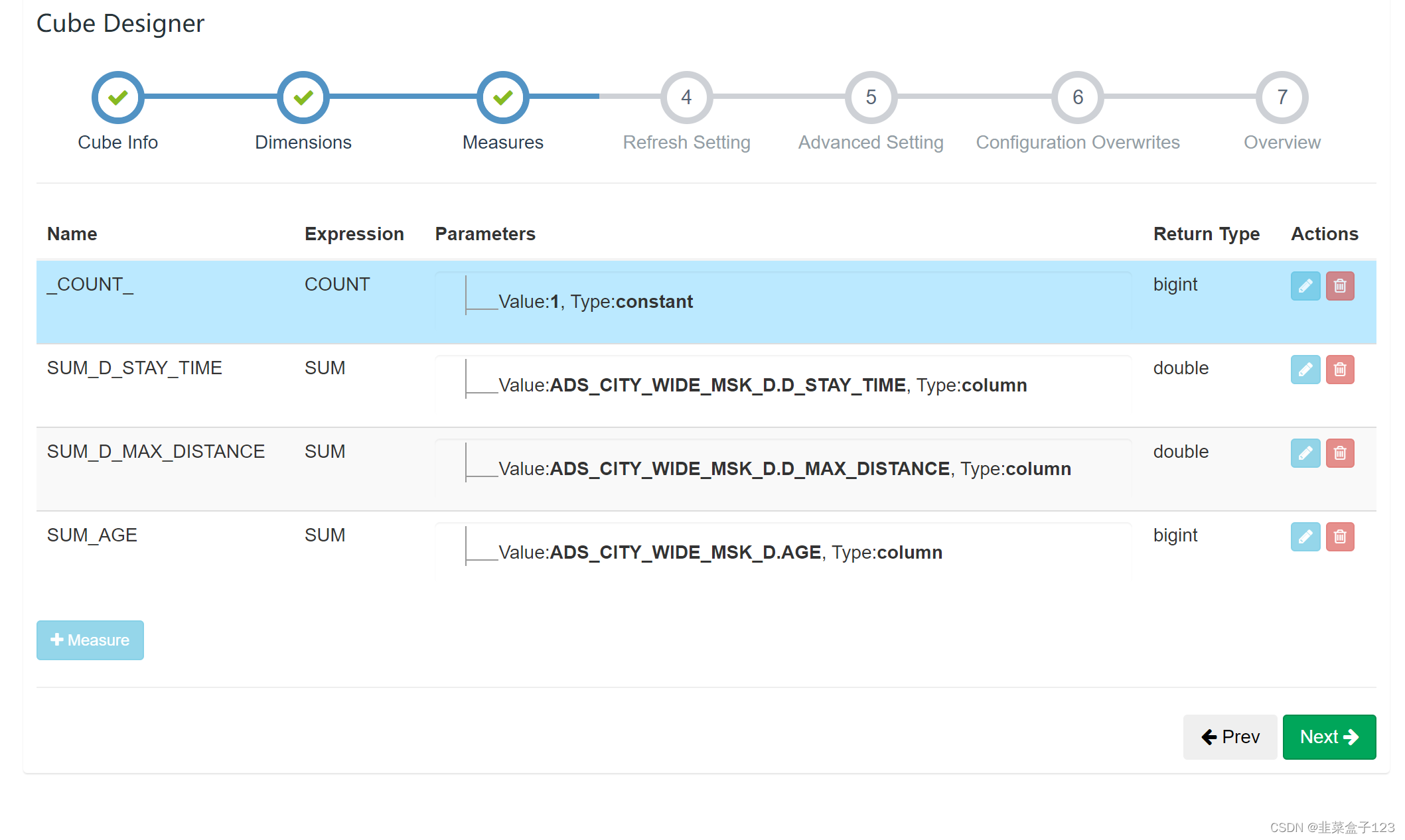
选择可能产生的运算(默认提供一个 count,好像不能直接均值,这里算一个 sum)
选择运算到的最大维度,每次必须添加的维度,次优选维度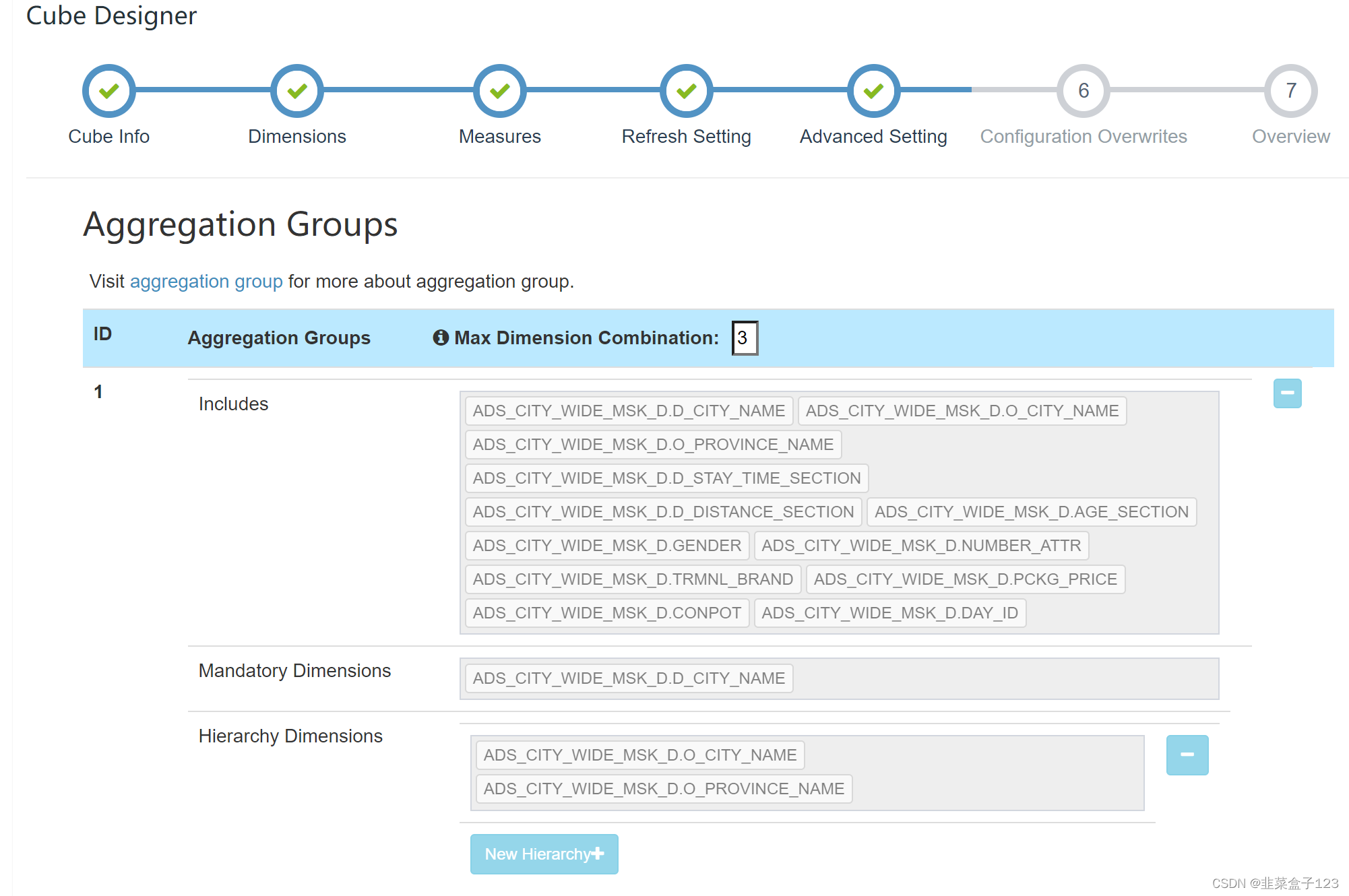
和使用的计算框架(MR 或 Spark)建议使用 MR,Spark 非常容易崩
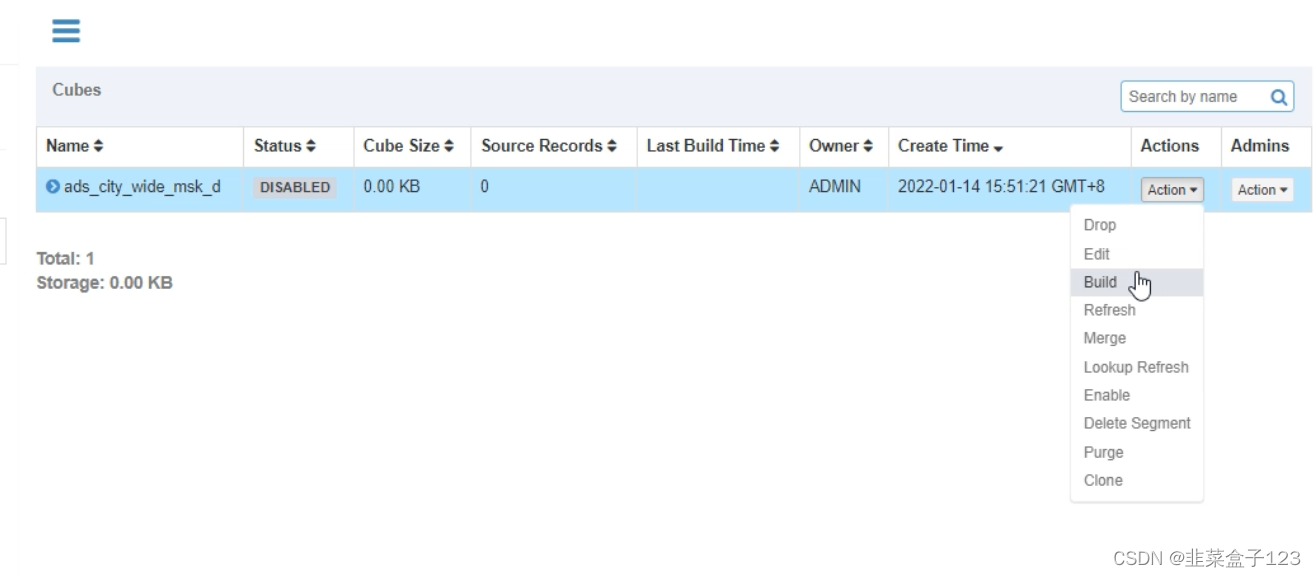
后面一路确定即可,最后将数据的状态改为 build,并选择时间分区
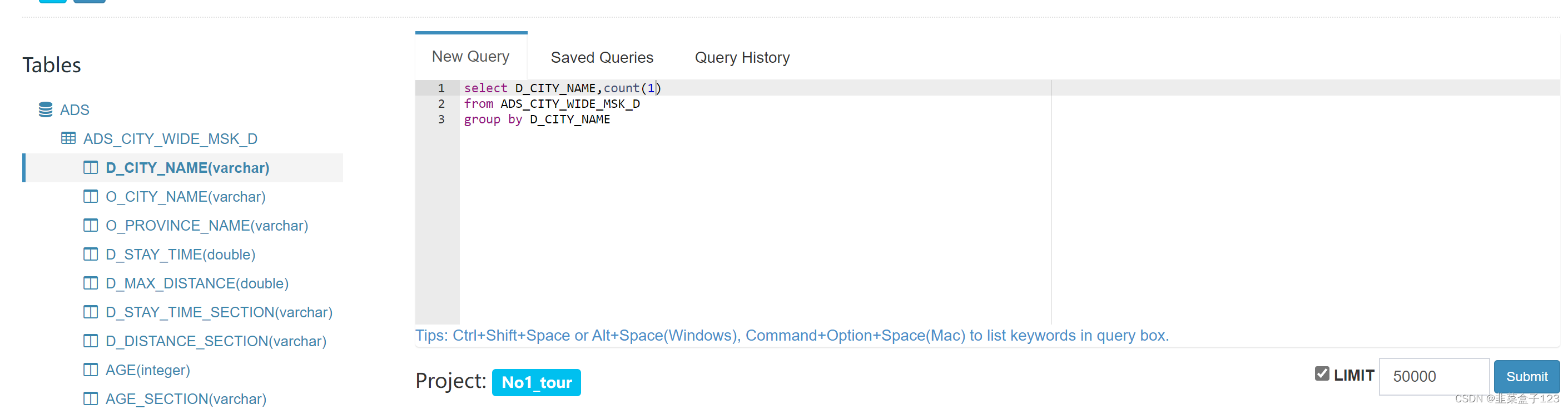
5 运算完成后就可以在首页使用 sql 语言进行数据查询
三、FineBI
可以将数据库中的数据查询结果转换为图像进行展示,例如刚刚使用 KYLIN
linux 的安装包是一个 .sh 脚本文件,直接运行就可以安装
1 需要先在 finebi 安装目录中添加 kylin 连接 jar 包
cd /usr/local/soft/finebi/webapps/webroot/WEB-INF/lib
2 如果已经打开,需要关闭进行并重启
ps -aux | grep finebi
kill -9 关闭的进程
3 重启,bin 目录下
./finebi
4 页面访问
http://master:37799/webroot/decision
5 设置完账号密码即可开始使用
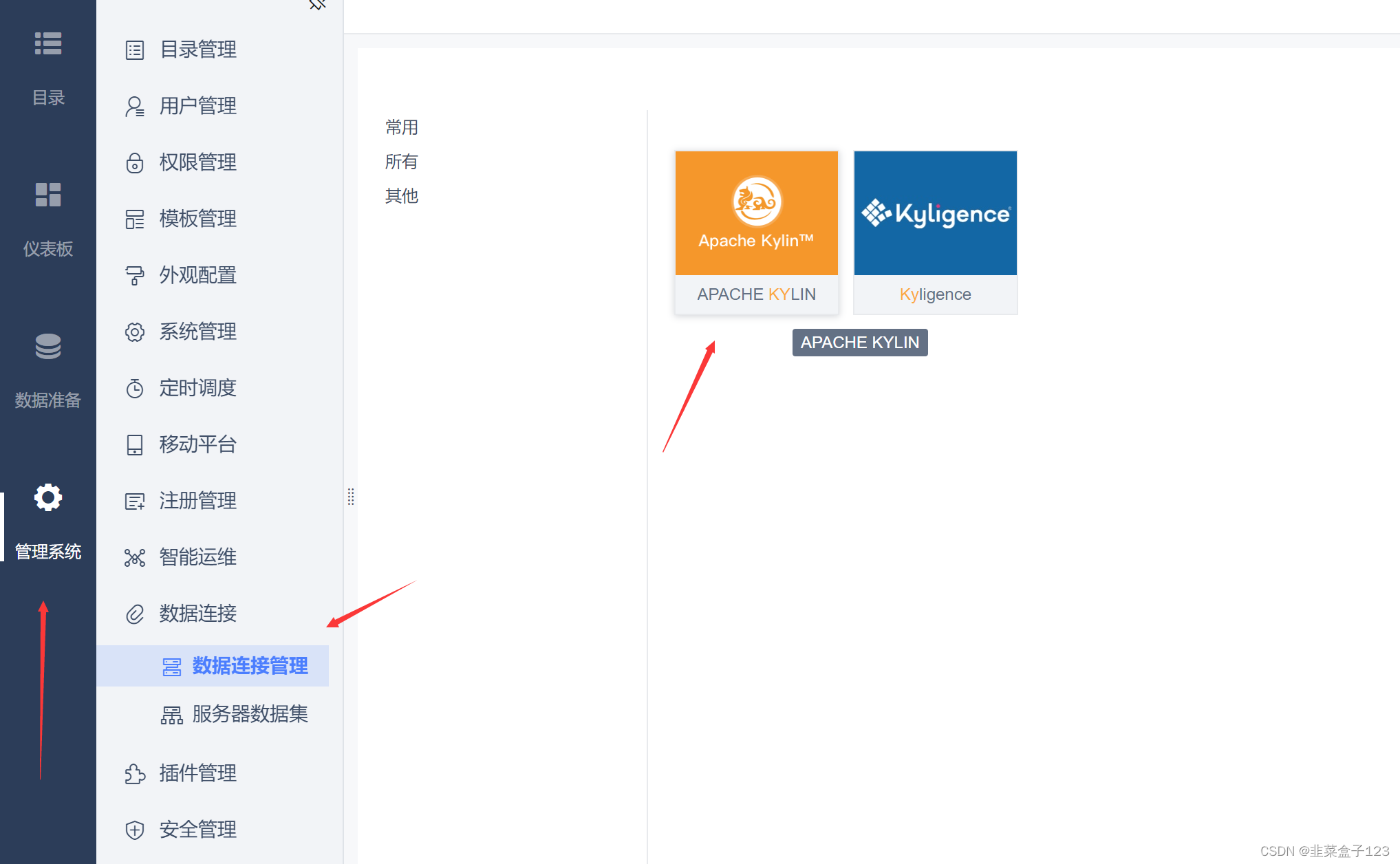
6 添加 kylin 连接

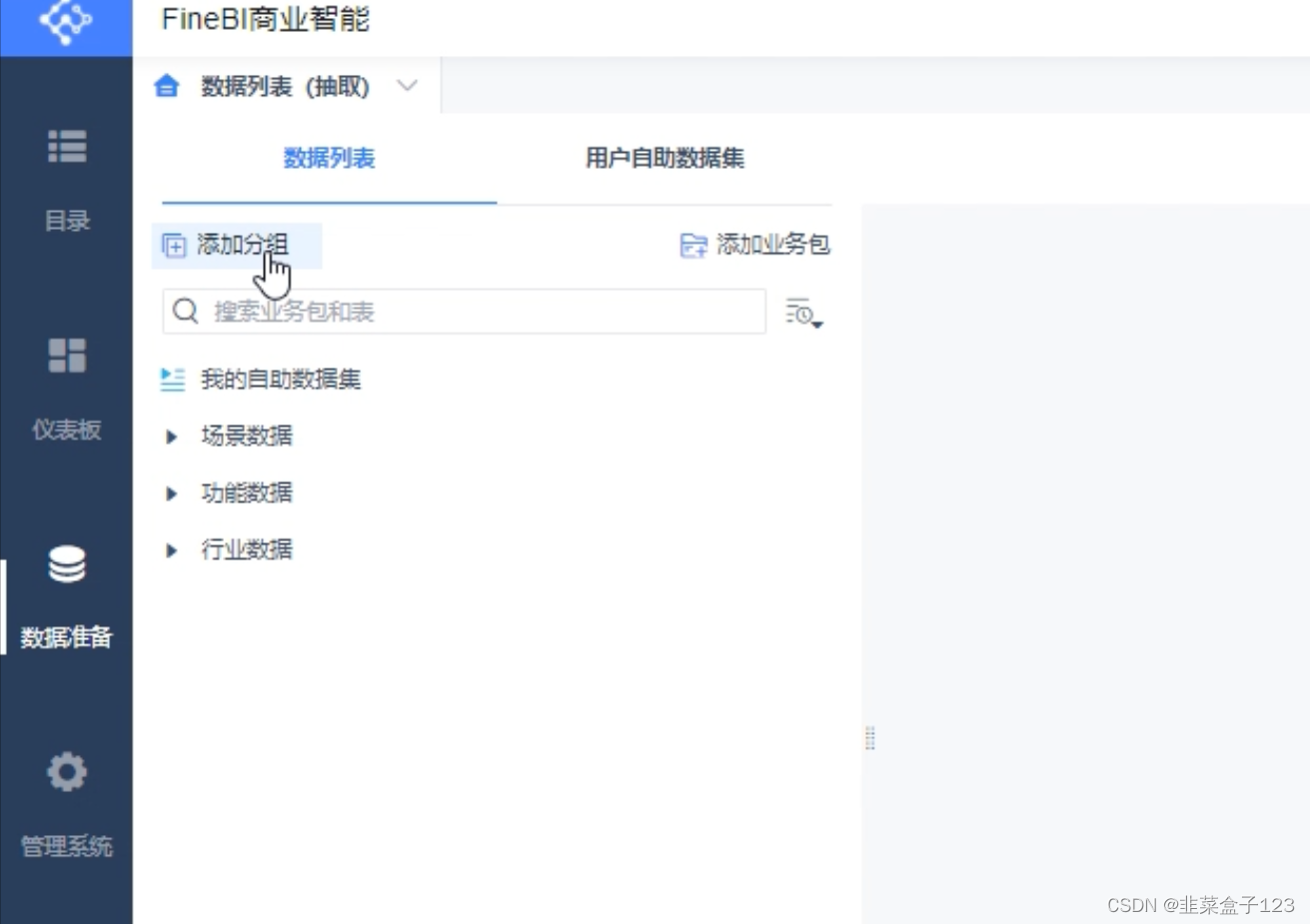
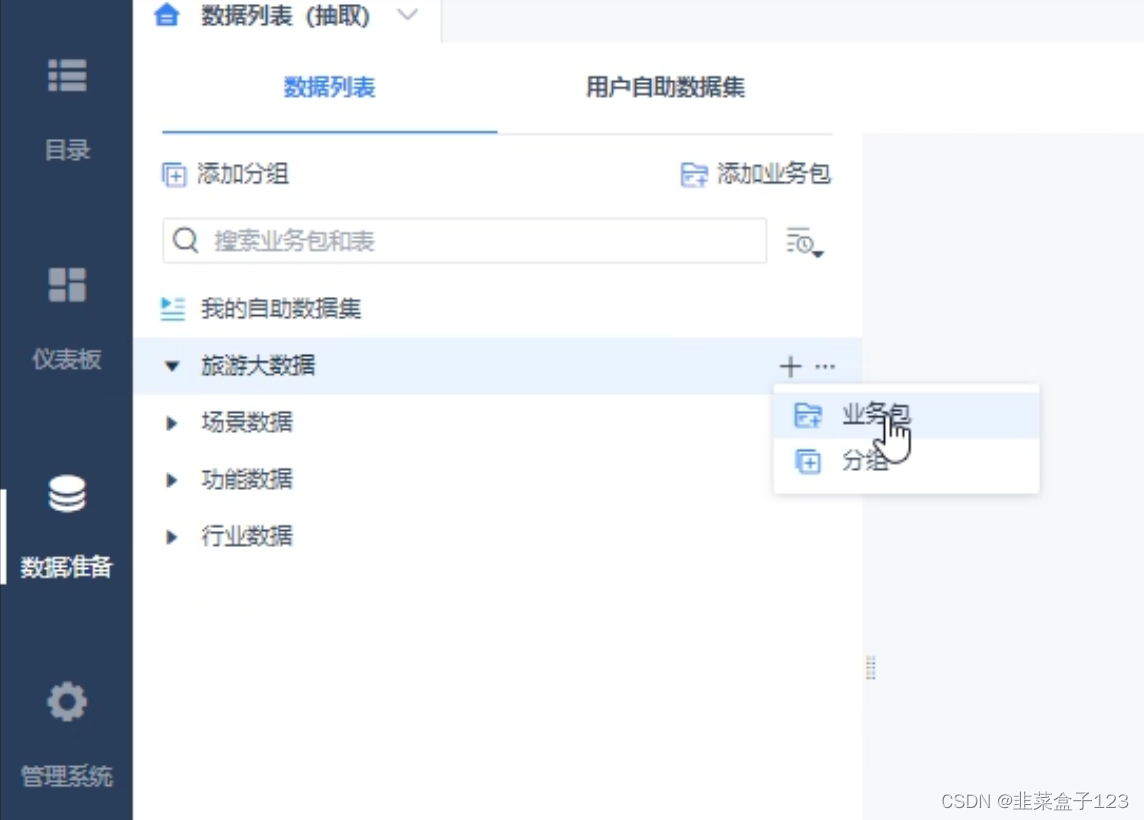
7 添加新分组和业务包
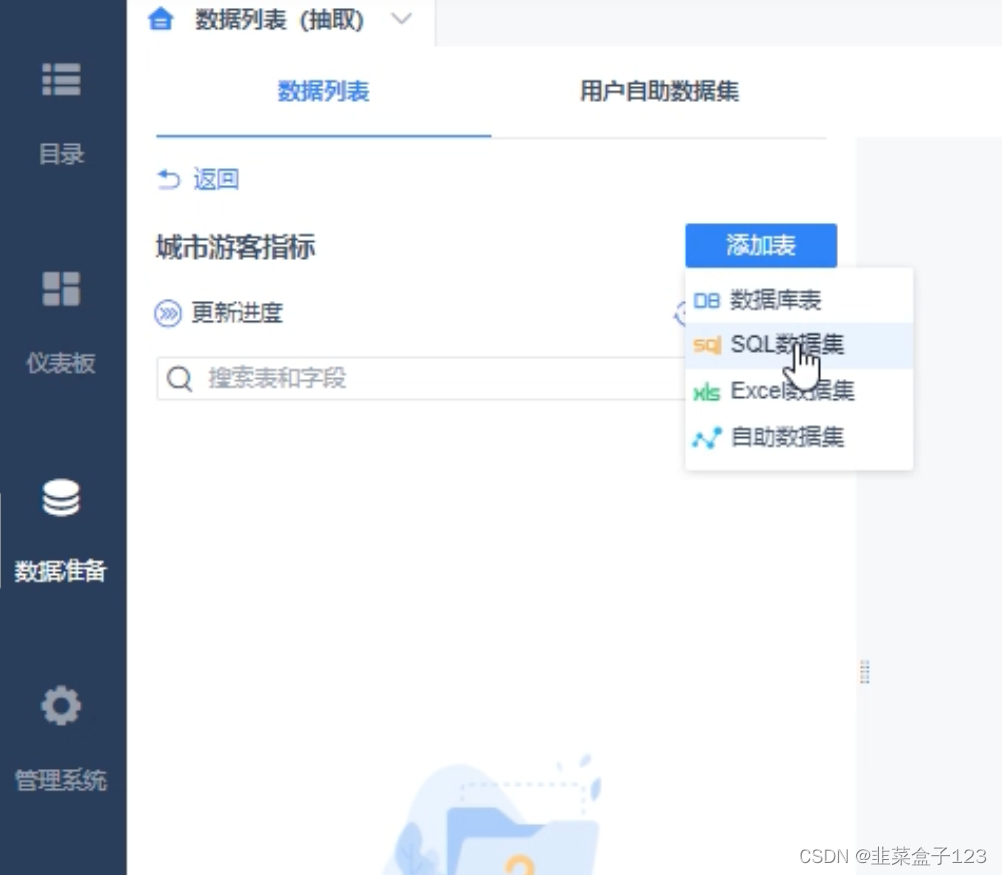
8 添加新查询并保存
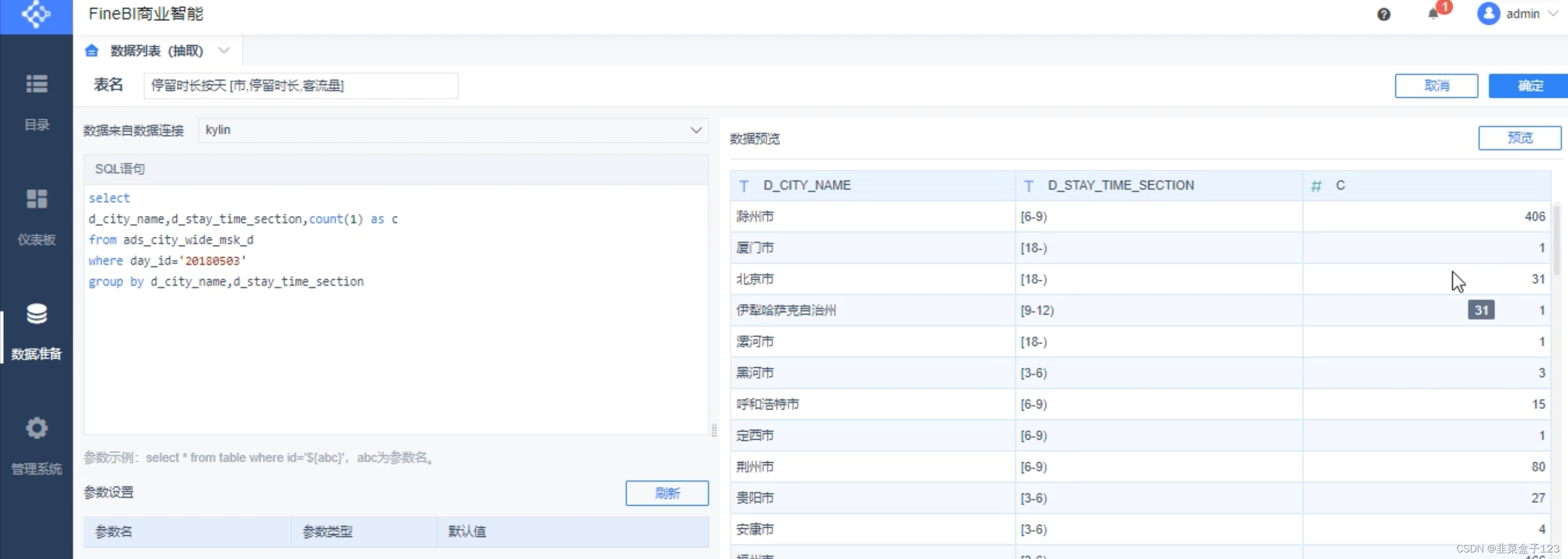
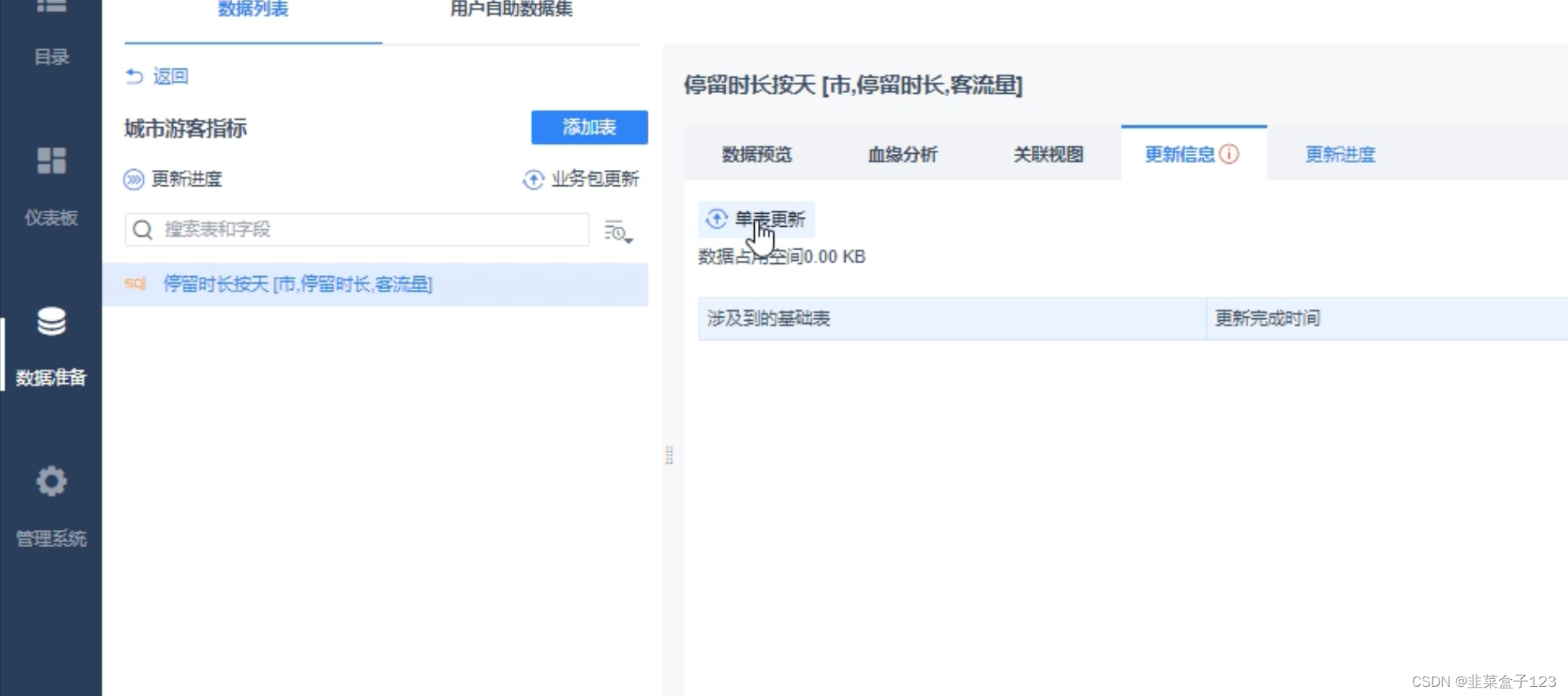
9 最后新建仪表盘,进去拖拉拽
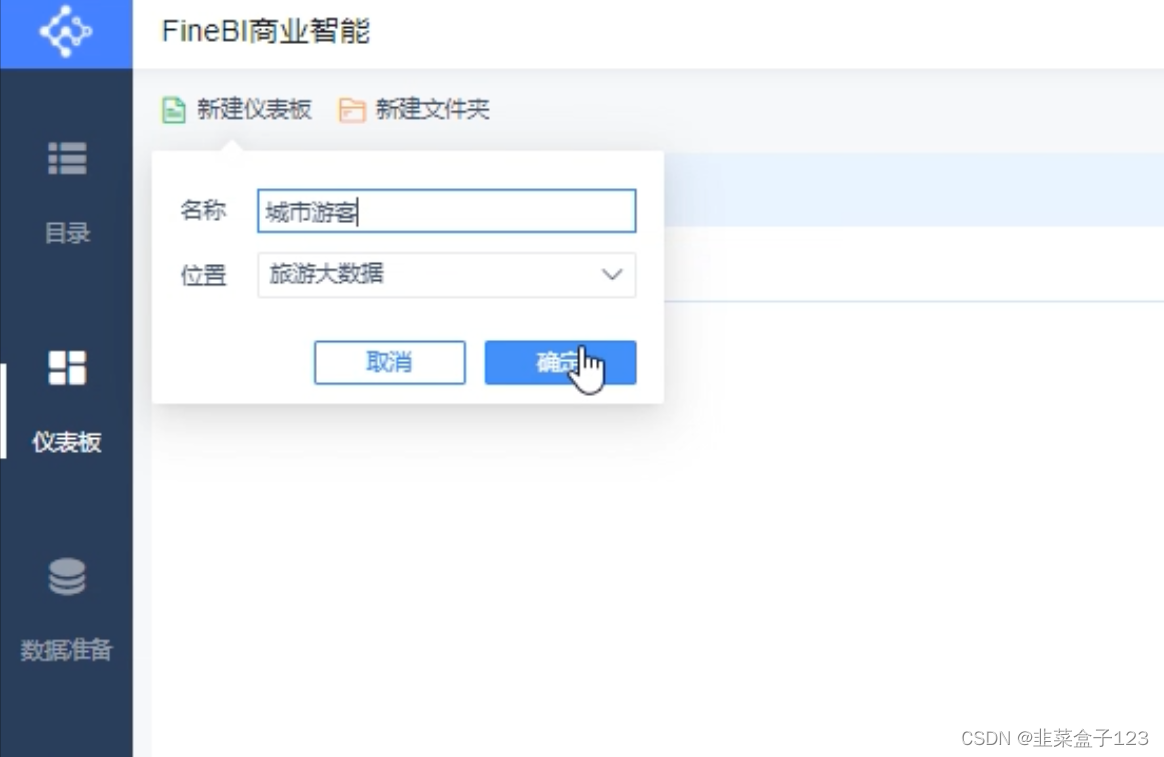
零碎
关于如何重置 hbase
1 停止 hbase
stop-hbase.sh
2 删除数据
hadoop dfs -rmr /hbase
3 删除元数据
zkCli.sh
rmr /hbase
4 重新启动 habase
start-hbase.sh















 3153
3153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









