







一、简介
1、介绍
APSScheduler是python的一个定时任务框架,它提供了基于日期date、固定时间间隔interval、以及linux上的crontab类型的定时任务。该框架不仅可以添加、删除定时任务,还可以将任务存储到数据库中、实现任务的持久化。
2、APScheduler有四种组件
-
triggers(触发器):每触发器包含调度逻辑,描述一个任务何时被触发,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行,按日期或按时间间隔或按 cronjob 表达式三种方式触发。除了他们自己初始化配置外,触发器完全是无状态的。
-
job stores(作业存储):用来存储被调度的作业,默认的作业存储器是简单地把作业任务保存在内存中,其它作业存储器可以将任务作业保存到各种数据库中,支持MongoDB、Redis、SQLAlchemy存储方式。当对作业任务进行持久化存储的时候,作业的数据将被序列化,重新读取作业时在反序列化。
-
executors(执行器):执行器用来执行定时任务,只是将需要执行的任务放在新的线程或者线程池中运行。当作业任务完成时,执行器将会通知调度器。对于执行器,默认情况下选择ThreadPoolExecutor就可以了,但是如果涉及到一下特殊任务如比较消耗CPU的任务则可以选择ProcessPoolExecutor,当然根据根据实际需求可以同时使用两种执行器。
-
schedulers(调度器):调度器是将其它部分联系在一起,一般在应用程序中只有一个调度器,应用开发者不会直接操作触发器、任务存储以及执行器,相反调度器提供了处理的接口。通过调度器完成任务的存储以及执行器的配置操作,如可以添加。修改、移除任务作业。
3、APScheduler提供了七种调度器:
-
BlockingScheduler:调度器在当前进程的主线程中运行,也就是会阻塞当前线程。通常在调度器是你唯一要运行的东西时使用。
-
BackgroundScheduler: 调度器在后台线程中运行,不会阻塞当前线程。适合于要求任何在程序后台运行的情况,当希望调度器在应用后台执行时使用。
-
AsyncIOScheduler:适合于使用asyncio异步框架的情况
-
GeventScheduler: 适合于使用gevent框架的情况
-
TornadoScheduler: 适合于使用Tornado框架的应用
-
TwistedScheduler: 适合使用Twisted框架的应用
-
QtScheduler: 适合使用QT的情况
4、APScheduler提供了四种存储方式:
-
MemoryJobStore
-
sqlalchemy
-
mongodb
-
redis
5、APScheduler提供了三种任务触发器:
-
data:固定日期触发器:任务只运行一次,运行完毕自动清除;若错过指定运行时间,任务不会被创建
-
interval:时间间隔触发器
-
cron:cron风格的任务触发
二、简单示例
1、示例1:
- 调度器:BlockingScheduler调度器,会阻塞主线程
- 任务存储:MemoryJobStore(默认)
- 执行器:ThreadPoolExecutor(默认)
- 触发器:
(1)固定时间间隔(interval),每隔5秒钟执行一次
(2)date方式,在2020-06-12 14:58:20只执行一次
(3)cron方式,每天14:58:20执行
import time
from apscheduler.schedulers.blocking import BlockingScheduler
#定义要执行的操作
def myfunc():
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
if __name__ == '__main__':
# 该示例代码生成了一个BlockingScheduler调度器,使用了默认的任务存储MemoryJobStore,以及默认的执行器ThreadPoolExecutor,并且最大线程数为10。
# BlockingScheduler:在进程中运行单个任务,调度器是唯一运行的东西
scheduler = BlockingScheduler() # 采用阻塞的方式
# 采用固定时间间隔(interval)的方式,每隔5秒钟执行一次
scheduler.add_job(myfunc, 'interval', seconds=5,id="intervaltest")
#date方式,在2020-06-12 14:58:20只执行一次
scheduler.add_job(myfunc, 'date', run_date='2020-06-12 14:58:20',id="datetest")
#cron方式,每天14:58:20执行
scheduler.add_job(myfunc, 'cron', hour=14, minute=58, second=20, id="crontest")
scheduler.start()
print("测试是否阻塞")
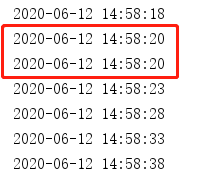
执行结果:每五秒执行一次,并且主线程阻塞
cron 参数
'''
year (int|str) – 4-digit year
month (int|str) – month (1-12)
day (int|str) – day of the (1-31)
week (int|str) – ISO week (1-53)
day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun)
hour (int|str) – hour (0-23)
minute (int|str) – minute (0-59)
econd (int|str) – second (0-59)
start_date (datetime|str) – earliest possible date/time to trigger on (inclusive)
end_date (datetime|str) – latest possible date/time to trigger on (inclusive)
timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone)
* any Fire on every value
*/a any Fire every a values, starting from the minimum
a-b any Fire on any value within the a-b range (a must be smaller than b)
a-b/c any Fire every c values within the a-b range
xth y day Fire on the x -th occurrence of weekday y within the month
last x day Fire on the last occurrence of weekday x within the month
last day Fire on the last day within the month
x,y,z any Fire on any matching expression; can combine any number of any of the above expressions
'''
2、示例2
- 调度器: BackgroundScheduler调度器,不阻塞主线程
- 任务存储:MemoryJobStore(默认)
- 执行器:ThreadPoolExecutor(默认)
- 触发器:固定时间间隔(interval)的方式,每隔5秒钟执行一次
import time
from apscheduler.schedulers.background import BackgroundScheduler
def myfunc():
print('job:', time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
if __name__ == '__main__':
# BackgroundScheduler: 适合于要求任何在程序后台运行的情况,当希望调度器在应用后台执行时使用。
scheduler = BackgroundScheduler()
# 采用非阻塞的方式
# 采用固定时间间隔(interval)的方式,每隔5秒钟执行一次
scheduler.add_job(myfunc, 'interval', seconds=5)
# 这是一个独立的线程
scheduler.start()
print("测试是否阻塞")
#用来在脚本中保持主线程的运行,否则主线程执行完了调度器也就跟着执行完了。如果是在项目中就可以不用,项目启动时主线程便会一直在。
while True:
time.sleep(600)
执行结果:
并没有阻塞主线程,会另开一个线程来执行调度器,可以继续往下执行主线程的其他代码

示例3、添加作业时给函数传递参数
1 #coding:utf-8
2 from apscheduler.schedulers.blocking import BlockingScheduler
3 import datetime
4 from apscheduler.jobstores.memory import MemoryJobStore
5 from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
6
7 def my_job(id='my_job'):
8 print (id,'-->',datetime.datetime.now())
9 jobstores = {
10 'default': MemoryJobStore()
11
12 }
13 executors = {
14 'default': ThreadPoolExecutor(20),
15 'processpool': ProcessPoolExecutor(10)
16 }
17 job_defaults = {
18 'coalesce': False,
19 'max_instances': 3
20 }
21 scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
22 scheduler.add_job(my_job, args=['job_interval',],id='job_interval',trigger='interval', seconds=5,replace_existing=True)
23 scheduler.add_job(my_job, args=['job_cron',],id='job_cron',trigger='cron',month='4-8,11-12',hour='7-11', second='*/10',\
24 end_date='2018-05-30')
25 scheduler.add_job(my_job, args=['job_once_now',],id='job_once_now')
26 scheduler.add_job(my_job, args=['job_date_once',],id='job_date_once',trigger='date',run_date='2018-04-05 07:48:05')
27 try:
28 scheduler.start()
29 except SystemExit:
30 print('exit')
31 exit()
示例4、使用数据库作为存储器
1 #coding:utf-8
2 from apscheduler.schedulers.blocking import BlockingScheduler
3 import datetime
4 from apscheduler.jobstores.memory import MemoryJobStore
5 from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
6 from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
7 def my_job(id='my_job'):
8 print (id,'-->',datetime.datetime.now())
9 jobstores = {
10 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
11 }
12 executors = {
13 'default': ThreadPoolExecutor(20),
14 'processpool': ProcessPoolExecutor(10)
15 }
16 job_defaults = {
17 'coalesce': False,
18 'max_instances': 3
19 }
20 scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
21 scheduler.add_job(my_job, args=['job_interval',],id='job_interval',trigger='interval', seconds=5,replace_existing=True)
22 scheduler.add_job(my_job, args=['job_cron',],id='job_cron',trigger='cron',month='4-8,11-12',hour='7-11', second='*/10',\
23 end_date='2018-05-30')
24 scheduler.add_job(my_job, args=['job_once_now',],id='job_once_now')
25 scheduler.add_job(my_job, args=['job_date_once',],id='job_date_once',trigger='date',run_date='2018-04-05 07:48:05')
26 try:
27 scheduler.start()
28 except SystemExit:
29 print('exit')
30 exit()
三、调度器scheduler启动关闭和配置
1,启动调度器
scheduler.start()
除了BlockingScheduler以外的调度程序,此调用将立即返回,你可以继续应用程序的初始化过程,例如向调度程序添加作业。
对于BlockingScheduler,只需要在完成任何初始化步骤之后调用start()。
注意:启动调度程序后,不能再更改其设置。
2,关闭调度器
默认情况下,调度程序关闭其作业存储和执行器,并等待所有当前执行的作业完成。
scheduler.shutdown()
如果你不想等,你可以执行。仍然会关闭作业存储和执行器,但不会等待任何正在运行的任务完成。
scheduler.shutdown(wait=False)
3,配置调度器
APScheduler提供了许多不同的方法来配置调度程序。可以使用配置字典,也可以将选项作为关键字参数传入。还可以先实例化调度器,然后添加作业并配置调度器。通过这种方式,可以为任何环境获得最大的灵活性。
(1)默认配置:
如果调度程序在应用程序的后台运行,选择 BackgroundScheduler,并使用默认的 jobstore 和默认的executor,则以下配置即可:
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
(2)假如我们想配置更多信息:设置两个执行器、两个作业存储器、调整新作业的默认值,并设置不同的时区。下述三个方法是完全等同的。
配置需求
配置名为“mongo”的MongoDBJobStore作业存储器
配置名为“default”的SQLAlchemyJobStore(使用SQLite)
配置名为“default”的ThreadPoolExecutor,最大线程数为20
配置名为“processpool”的ProcessPoolExecutor,最大进程数为5
UTC作为调度器的时区
coalesce默认情况下关闭
作业的默认最大同时运行实例限制为3,这在某个job在下次运行时间到达之后仍未执行完毕时,能达到控制的目的。(如果不设置的时候默认是1,同一个job在同一时间只能运行一个实例)
方法一
1 from pytz import utc
2
3 from apscheduler.schedulers.background import BackgroundScheduler
4 from apscheduler.jobstores.mongodb import MongoDBJobStore
5 from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
6 from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExec
7
8
9 jobstores = {
10 'mongo': MongoDBJobStore(),
11 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
12 }
13 executors = {
14 'default': ThreadPoolExecutor(20),
15 'processpool': ProcessPoolExecutor(5)
16 }
17 job_defaults = {
18 'coalesce': False,
19 'max_instances': 3
20 }
21 scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
方法二
1 from apscheduler.schedulers.background import BackgroundScheduler
2 scheduler = BackgroundScheduler({
3 'apscheduler.jobstores.mongo': {
4 'type': 'mongodb'
5 },
6 'apscheduler.jobstores.default': {
7 'type': 'sqlalchemy',
8 'url': 'sqlite:///jobs.sqlite'
9 },
10 'apscheduler.executors.default': {
11 'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
12 'max_workers': '20'
13 },
14 'apscheduler.executors.processpool': {
15 'type': 'processpool',
16 'max_workers': '5'
17 },
18 'apscheduler.job_defaults.coalesce': 'false',
19 'apscheduler.job_defaults.max_instances': '3',
20 'apscheduler.timezone': 'UTC',
21 })
方法三
1 from pytz import utc
2 from apscheduler.schedulers.background import BackgroundScheduler
3 from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
4 from apscheduler.executors.pool import ProcessPoolExecutor
5
6 jobstores = {
7 'mongo': {'type': 'mongodb'},
8 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
9 }
10 executors = {
11 'default': {'type': 'threadpool', 'max_workers': 20},
12 'processpool': ProcessPoolExecutor(max_workers=5)
13 }
14 job_defaults = {
15 'coalesce': False,
16 'max_instances': 3
17 }
18 scheduler = BackgroundScheduler()
19
20 # .. do something else here, maybe add jobs etc.
21
四、操作job
1.添加作业
上面是通过add_job()来添加作业,另外还有一种方式是通过scheduled_job()修饰器来修饰函数
import time
from apscheduler.schedulers.blocking import BlockingScheduler
sched = BlockingScheduler()
@sched.scheduled_job('interval', seconds=5)
def my_job():
print time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
sched.start()
2.移除作业
job = scheduler.add_job(myfunc, 'interval', minutes=2)
job.remove()
#如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
sched.remove_job('my_job_id')
3、暂停和恢复作业
暂停
apsched.job.Job.pause()
apsched.schedulers.base.BaseScheduler.pause_job()
恢复
apsched.job.Job.resume()
apsched.schedulers.base.BaseScheduler.resume_job()
4、获得job列表
scheduler.add_job(job, 'cron', hour=10, minute=54,second=20,id="id1")
scheduler.add_job(job,'interval', seconds=3,id="id2")
print(scheduler.get_jobs()) #获取调度器作业列表 [<Job (id=id1 name=job)>, <Job (id=id2 name=job)>]
print(scheduler.get_jobs()[0].id) #调度器作业列表第一个作业的获取具体id id1
print(scheduler.get_job(job_id="id1")) #获取作业job对象 job (trigger: cron[hour='10', minute='54', second='20'], pending)
5、限制同一个job实例的并发执行数
默认情况下同一个job,只允许一个job实例运行。这在某个job在下次运行时间到达之后仍未执行完毕时,能达到控制的目的。你也可以改变这一行为,在你调用add_job时可以传递max_instances=5或者设置job_defaults来同时运行同一个job的5个job实例。
参考:python实现定时任务
python中schedule模块的使用
花10分钟让你彻底学会Python定时任务框架apscheduler
Python定时任务-APScheduler
Python APScheduler 定时任务















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









