






爬取数据时,HTTP ERROR 401解决办法
在爬取网页数据时,遇到这样一个问题:
浏览器能可以浏览的网页,按F12后,打开network,找到数据所在的链接,双击(或者将header中的Request URL复制粘贴到浏览器地址栏),发现报了401的错误。

这个问题的原因是网站做了反爬机制。有两种解决思路。
一、添加Authorization字段
在爬虫代码请求URL时,在请求头header中添加Authorization字段,从浏览器中拷贝该字段的值。
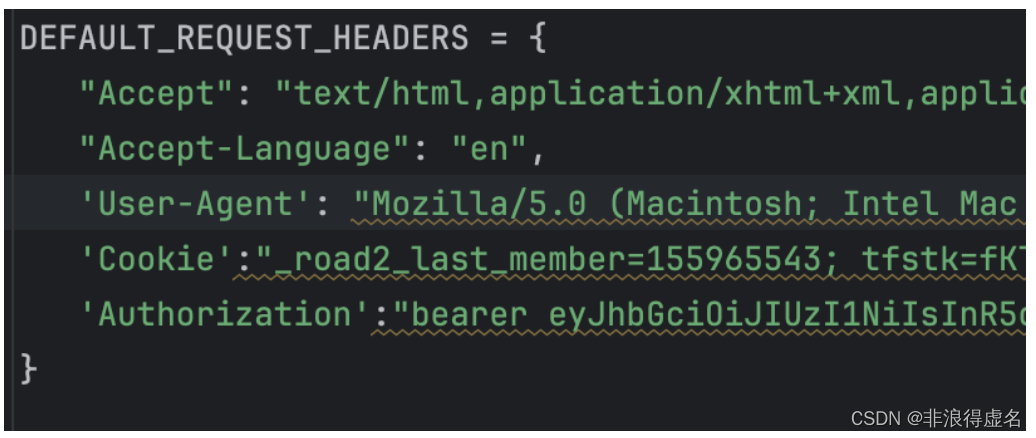
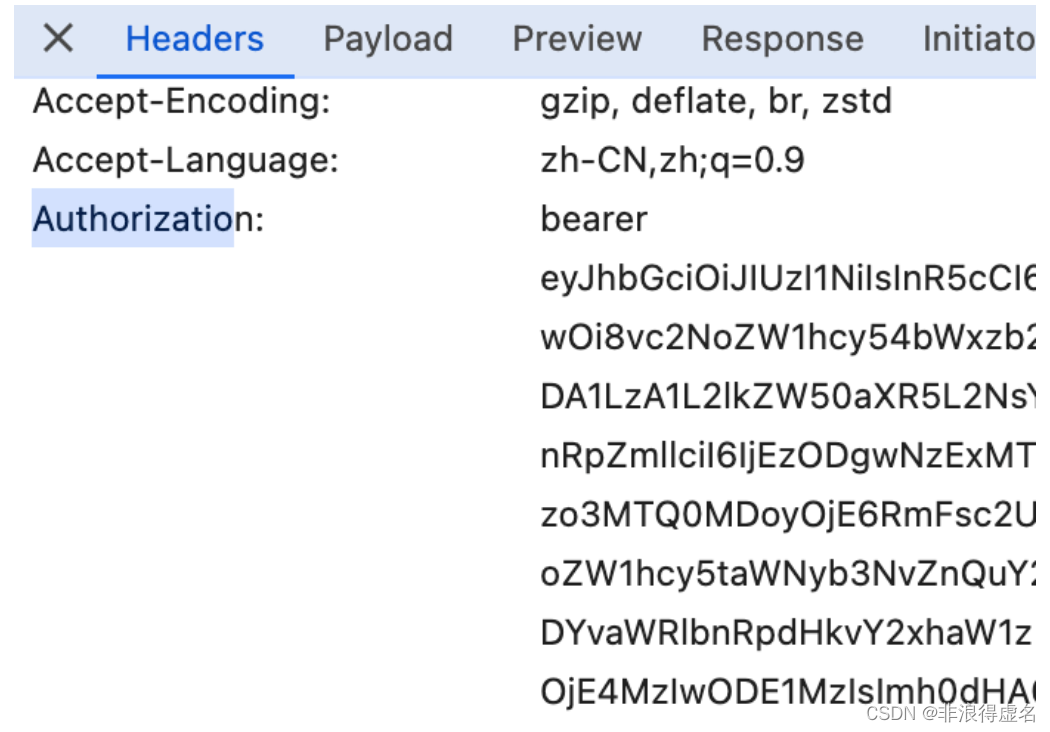
注意,该方法是临时的。当重新登陆时,Authorization会重置,这时需要再次拷贝该值到代码中。
二、JS逆向
这种方法需要对该网页的js代码进行分析,找出产生密钥的token,并在代码中模拟生成这个token。由于这个过程稍微有些复杂,对于不同的网站,都需要一步步去做逆向。感兴趣的小伙伴可以深入了解下。
这种方法不是临时的,重新登陆后仍然有效。
综上,介绍了两种解决401问题的方法。如果只是临时爬一下数据,用第一种方法更简便。如果要多次爬取数据,采用js逆向方法来解决。














 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









