









数据下载
使用sklearn下载速度会非常缓慢,建议使用先用百度网盘下载后,再按照网上教程进行操作即可获得数据。
链接:https://pan.baidu.com/s/1xjF1O6s_sL44psOqnsx6Iw
提取码:3hxn
复制这段内容后打开百度网盘手机App,操作更方便哦
朴素贝叶斯算法
朴素贝叶斯算法特点是假设所有特征的出现相互独立互不影响,每一特征同等重要
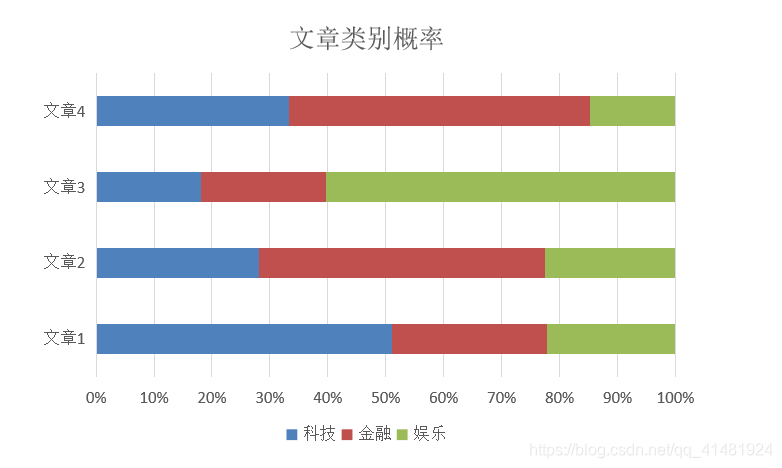



通过对训练集文本进行词频处理,然后对比测试集文本词频进行分析,获得该文本可能属于各类别的概率,概率最大的即为预测结果。
库导入
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
#获取数据
news = fetch_20newsgroups(subset='all')#拆分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)朴素贝叶斯算法对数据处理时,必须进行文本特征抽取!
#特征工程
#使用tf-idf进行文本特征抽取
tf = TfidfVectorizer()
#以训练集中词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test) #调用朴素贝叶斯算法 alpha为拉普拉斯平滑系数
nav = MultinomialNB(alpha=1.0)
nav.fit(x_train,y_train)
y_predict = nav.predict(x_test)
score = nav.score(x_test,y_test)

![]()
完整代码:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
def naivebayes():
#朴素贝叶斯算法进行文本分类
#获取数据
news = fetch_20newsgroups(subset='all')
#拆分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
#特征工程
#使用tf-idf进行文本特征抽取
tf = TfidfVectorizer()
#以训练集中词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
#调用朴素贝叶斯算法 alpha为拉普拉斯平滑系数
nav = MultinomialNB(alpha=1.0)
nav.fit(x_train,y_train)
y_predict = nav.predict(x_test)
score = nav.score(x_test,y_test)
print(tf.get_feature_names())
print(x_train)
print("预测的文章类型:",y_predict)
print("准确率:",score)
return None
if __name__ == "__main__":
naivebayes()


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











