






集成学习将多个学习器通过某种策略集合成一个强学习器,根据个体学习器间是否存在依赖关系分为【boosting系列算法】【个体学习器间存在强依赖关系】和【bagging、随机森林系列算法】【个体学习器间不存在强依赖关系】。
stacking?
一、Boosting算法
Boosting算法是将“弱学习算法”提升为“强学习算法“的过程,主要思想是”三个臭皮匠顶个诸葛亮“,Boosting算法涉及两个部分,加法模型和向前分步算法。前向分步算法用来推导弱学习器的系数
1.1 Adaboost
Adaboost是一种迭代算法,通过构造多个弱分类器,然后把这些弱分类器集合起来构成一个更强的最终分类器。Adaboost提供的是一种框架。它可以使用各种来构造弱分类器,比如使用单决策树作为弱分类器。
1.1.1 Adaboost分类问题:
在分类问题中有SAMME和SAMME.R两种算法,SAMME.R收敛速度更快
SAMME算法流程:
输入训练数据集
(1)初始化样本的权值分布:
(2)对m个弱分类器,m=1,2,...,M:
a)使用具有权值分布的训练数据集进行学习,得到基本分类器
,其输出值为{-1,1};
b)计算弱分类器在训练器数据集上的分类误差率,其值越小的基分类器在最终分类器中的作用越大。
,其中
取值为0或1,取0表示分类正确,取1表示分类错误。
c)计算弱分类器在强分类器中所占权重:
d)更新训练数据集的样本权值分布
其中,是规范化因子,主要作用是将的值规范化到0-1之间,使得
。
从权重的更新表达式可以看出,当分类正确时会得到比较小的更新权值,分类错误时,会得到比较大更新的权值。
(3)利用加权平均法构建基本分类器的线性组合:
得到最终强分类器:
SAMME.R算法流程:
(1)初始化样本的权值分布:
(2)对m个弱分类器,m=1,2,...,M:
(a)使用带有权重的样本来训练一个弱学习器
(b)获得带有权重分类的概率评估:,其中
表示第m个弱学习器把样本
分为第k类的 概率,k=1,2,...,K。
(c)使用加权概率推导出加法模型的更新,然后将其应用于数据:
(d)更新样本点权重系数:
(e)标准化样本点权重
(3)得到最终的强分类器:
,表示使
最大的K就是所预测的结果。
sklearn库中AdaBoost参数设置:https://www.cnblogs.com/pinard/p/6136914.html#!comments
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
#这里采用分类树作为基分类器
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
X1,y1=make_gaussian_quantiles(cov=2.0,n_samples=500,n_features=2,n_classes=2,random_state=1)
X2,y2=make_gaussian_quantiles(mean=(3,3),cov=1.5,n_samples=400,n_features=2,n_classes=2,random_state=1)
X=np.concatenate((X1,X2))
y=np.concatenate((y1,-y2+1))
bdt=AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,min_samples_split=20,min_samples_leaf=5),algorithm="SAMME",n_estimators=200,learning_rate=0.8)
bdt.fit(X,y)
x_min,x_max=X[:,0].min()-1,X[:,1].max()+1
y_min,y_max=X[:,1].min()-1,X[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02))
Z=bdt.predict(np.c_[xx.ravel(),yy.ravel()])
Z=Z.reshape(xx.shape)
cs=plt.contourf(xx,yy,Z,cmap=plt.cm.Paired)
plt.scatter(X[:,0],X[:,1],c=y,marker='o')
plt.show()
print(bdt.score(X,y))
1.1.2AdaBoost回归问题:
算法流程:
(1)初始化样本的权值分布:
(2)对m个弱分类器,m=1,2,...,M:
(a)使用具有权值分布的训练数据集进行学习,得到弱分类器
(b)计算训练集上的最大误差:
(c)计算每个样本点的相对误差:
如果是线性误差:
如果是平方误差:
如果是指数误差:
(d)计算回归误差率:
(e)计算弱学习器系数:
(f)更新样本权重分布:,其中
是规范化因子,
(3)得到强学习器
,其中
是所有
的中位数(m=1,2,...,M)
1.1.3 AdaBoost优缺点:
优点:
(1)分类精度很高
(2)不容易发生过拟合
(3)在AdaBoost框架下,可以使用各种模型来构建弱学习器
(4)参数少,不需要调节太多参数
缺点:
(1)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性
(2)弱分类器数目不太好设定,可以使用交叉验证来进行确定
(3)数据不平衡导致分类精度下降
(4)训练比较耗时,每次重新选择当前分类器最好切分点
1.2、GBDT(算法提升梯度树)
GBDT通过多伦迭代,每轮迭代产生一个弱学习器,每个学习器都是在上一轮学习器的残差基础上进行训练。GBDT的弱学习器采用的是回归树。
GBDT回归算法:输入训练集,T为最大迭代次数,m为样本个数,损失函数L。
(1)初始化弱学习器:
(2)对迭代次数t=1,2,...,T有:
(a)对样本i=1,2,...,m,计算负梯度:
(b)利用拟合一颗CART回归树,得到第t棵回归树,其对应的叶子节点区域为
。其中J为回归树t叶子节点的个数。
(c)对叶子区域,计算最佳拟合值:
(d)更新强学习器:
(3)得到强学习器f(x)的表达式:
参考资料:https://www.cnblogs.com/pinard/p/6140514.html(还讲了GDBT的分类算法步骤,用于分类时和回归的思路一样,只是损失函数不同)
实例参考:https://blog.csdn.net/zpalyq110/article/details/79527653
import pandas as pd
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import cross_validation,metrics
from sklearn.grid_search import GridSearchCV
import matplotlib.pyplot as plt
train=pd.read_csv('train_modified.csv')
train['Disbursed'].value_counts()
target='Disbursed'
IDcol='ID'
x_columns = [x for x in train.columns if x not in [target, IDcol]]
X=train[x_columns]
y=train['Disbursed']
#先不设置任何参数
gbm0=GradientBoostingClassifier(random_state=10)
gbm0.fit(X,y)
y_pred=gbm0.predict(X)
y_predprob=gbm0.predict_proba(X)[:,1]
print('Accuracy:%.4g'%metrics.accuracy_score(y.values,y_pred))
print('AUC Score (tain):%f'%metrics.roc_auc_score(y,y_predprob))
#通过网格搜索进行调参
param_test1 = {'n_estimators':list(range(20,81,10))}
gsearch1 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, min_samples_split=300,
min_samples_leaf=20,max_depth=8,max_features='sqrt', subsample=0.8,random_state=10),
param_grid = param_test1, scoring='roc_auc',iid=False,cv=5)
gsearch1.fit(X,y)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
param_test2 = {'max_depth':list(range(3,14,2)),'min_samples_split':list(range(100,801,200))}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60,
min_samples_leaf=20,max_features='sqrt', subsample=0.8,random_state=10),
param_grid = param_test2, scoring='roc_auc',iid=False,cv=5)
gsearch2.fit(X,y)
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_GBDT代码调参:https://www.cnblogs.com/pinard/p/6143927.html
1.3、XGboost
XGboost是GBDT的一种高效实现,XGboost相对于GBDT来说,在损失函数后加了一项正则项,
,其中
代表第j个叶子节点的最优值。要求损失函数的最小值,XGBoost采用泰勒二次展开式求解:
把第i个样本在第t个弱学习器的一阶导和二阶导分别记为:
此时损失函数表示为:
损失函数中第一项和最小化无关,可以去掉,由于每个决策树的第j个叶子节点的取值最终会是同一个值,因此损失函数可简化为:
把每个叶子节点区域样本的一阶和二阶导数表示为:
最终损失函数表示为:
损失函数对求导等于0可以得到叶子节点区域的最优解为:
,将期代入损失函数得到:
在对树进行分裂时,期望分裂后的损失函数值比分裂前小很多,假设分裂后左右子树的一阶二阶导数和为
则我们期望下式最大:
整理后为:
算法流程:

#使用原生的API接口
import numpy as np
import pandas as pa
import matplotlib.pyplot as plt
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.metrics import accuracy_score
X,y=make_classification(n_samples=10000,n_features=20,n_redundant=0,n_clusters_per_class=1,n_classes=2,flip_y=0.1)
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)
dtrain=xgb.DMatrix(X_train,y_train)
dtest=xgb.DMatrix(X_test,y_test)
param={'max_depth':5,'eta':0.5,'verbosity':1,'objective':'binary:logistic'}
raw_model=xgb.train(param,dtrain,num_boost_round=20)
pred_train_raw=raw_model.predict(dtrain)
for i in range(len(pred_train_raw)):
if pred_train_raw[i]>0.5:
pred_train_raw[i]=1
else:
pred_train_raw[i]=0
print('train_accuracy:',accuracy_score(dtrain.get_label(),pred_train_raw))
pred_test_raw=raw_model.predict(dtest)
for i in range(len(pred_test_raw)):
if pred_test_raw[i]>0.5:
pred_test_raw[i]=1
else:
pred_test_raw[i]=0
print('test_accuracy:',accuracy_score(dtest.get_label(),pred_test_raw))参数优化参考:https://www.cnblogs.com/pinard/p/11114748.html
参考文献:
XGBoost算法原理小结:https://www.cnblogs.com/pinard/p/10979808.html
https://blog.csdn.net/qq_19446965/article/details/82079486
https://blog.csdn.net/qq_24519677/article/details/81809157
二、bagging算法
Bagging算法基于自助采样法随机得到一些样本训练集,用来学习不同的基学习分类器,然后对不同的基学习分类器得到的结果投票得出最终分类结果。随机森林也算bagging的一种,有一点区别在于随机森林在构建决策树时会随机选择样本特征中的一部分来进行划分。
随机森林:随机森林集成了多棵决策树,每棵决策树有一个分类结果,将投票次数最多的类别作为最终输出。随机森林可以处理大量的输入变数,可以产生高准确度的分类器。
随机森林算法步骤:
1)假设训练集的大小为N,对每棵树,有放回地随机抽取N个样本(包括可能重复的样本)
2)假设每个样本的特征为M,随机地从M中抽取m个特征,每次树进行分裂时,从这m个特征中选取最优的特征
3)对每棵决策树选定样本和特征后,使用CART进行计算,不剪枝
4)得到决策树后,对每棵树的输出进行投票,投票最多的类作为随机森林的决策。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
iris=load_iris()
df=pd.DataFrame(iris.data,columns=iris.feature_names)
df['is_train']=np.random.uniform(0,1,len(df))<=.75
df['target']=iris.target
df.head(10)
train,test=df[df['is_train']==True],df[df['is_train']==False]
features=df.columns[:4]
clf=RandomForestClassifier(n_jobs=2)
y=train['target']
clf.fit(train[features],y)
preds=iris.target_names[clf.predict(test[features])]
species=iris.target_names[test['target'].values]
pd.crosstab(species, preds, rownames=['actual'], colnames=['preds'])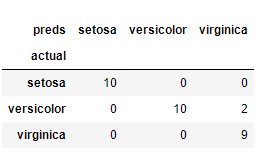
参考:https://blog.csdn.net/qq_39521554/article/details/80714734















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









