









目录
Hadoop HBase Hive | 一、Linux集群环境安装采坑介绍
1.上一篇
Hadoop HBase Hive | 一、Linux集群环境安装采坑介绍
2.检查hostname
检查每个节点的hostname,这个步骤很重要,接下来会用到。
vi /etc/sysconfig/network

3.上传hadoop
官网下载 http://hadoop.apache.org/releases.html
上传 hadoop-2.10.0.tar.gz
解压 tar -zxvf hadoop-2.10.0.tar.gz
4.修改配置文件
目录 cd etc/hadoop/

4.1 修改core-site.xml
这里面配置的是hdfs的文件系统地址。
hdfs://hadoop-master:9000 hadoop-master 即是 hostnam对应名称。
/usr/local/hadoop-2.10.0/data/tmp 临时文件路径
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.10.0/data/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>4.2 修改hdfs-site.xml
主要配置 secondary namenode的地址
dfs.namenode.name.dir namenode路径
dfs.datanode.data.dir nodedata 路径
dfs.namenode.secondary.http-address 下面的hadoop-slave即是 hostnam对应名称
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.10.0/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.10.0/data/dfs/data</value>
</property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.polic</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-slave:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-slave02:50091</value>
</property>
</configuration>4.3 修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.0.1.73</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>10.0.1.73:8320</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>864000</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>864000</value>
</property>
<property>
<name>yarn.nodemanager,remote-app-log-dir</name>
<value>/usr/local/hadoop-2.10.0/data/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://127.0.0.1:8325/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop-2.10.0/data/nodemanager</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>5000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>4.4 修改mapred-site.xml
拷贝 mapred-site.xml.template
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework set to Hadoop YARN.</description>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/usr/local/hadoop-2.10.0/data/yarn/tmp/hadoop-yarn/staging</value>
</property>
<!--MapReduce JobHistory Server地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>10.0.1.73:8330</value>
</property>
<!--MapReduce JobHistory Server Web UI地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>10.0.1.73:8331</value>
</property>
<!--MR JobHistory Server管理的日志的存放位置-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<!--MapReduce作业产生的日志存放位置-->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>1000</value>
</property>
<property>
<name>mapreduce.tasktracker.map.tasks.maximum</name>
<value>8</value>
</property>
<property>
<name>mapreduce.tasktracker.reduce.tasks.maximum</name>
<value>8</value>
</property>
<property>
<name>mapreduce.jobtracker.maxtasks.perjob</name>
<value>5</value>
<description>The maximum number of tasks for a single job.
A value of -1 indicates that there is no maximum.
</description>
</property>
</configuration>4.5 修改slaves、master

命令 vi slaves
hadoop-slave
hadoop-slave02
hadoop-slave03命令 vi master
hadoop-master4.6 检查JAVA_HOME
环境变量里面必须要配置 JAVA_HOME
4.7 检查HADOOP_HOME
vi ~/.bashrc
# .bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_74
export HADOOP_HOME=/usr/local/hadoop-2.10.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi5.相关文件复制
5.1 复制 hadoop至三个slave
scp -r /usr/local/hadoop-2.10.0 root@hadoop-slave:/usr/local
scp -r /usr/local/hadoop-2.10.0 root@hadoop-slave02:/usr/local
scp -r /usr/local/hadoop-2.10.0 root@hadoop-slave03:/usr/local

5.2 复制 ~/.bashrc 至三个slave
scp ~/.bashrc root@hadoop-slave:~/
scp ~/.bashrc root@hadoop-slave02:~/
scp ~/.bashrc root@hadoop-slave03:~/

6.集群初始化
初始化 hadoop-master
通过HDFS实现集群文件系统初始化

执行
./bin/hdfs namenode -format hba-hadoop
出现错误,说明配置文件不正确,按照提示仔细检查。确认无误再次初始化。

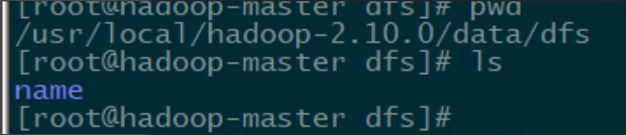
初始化成功

可以看到 /usr/local/hadoop-2.10.0/data/dfs 有文件 name,没看到再检查初始化及配置信息。
7.hdfs
7.1 启动hdfs集群
./sbin/start-dfs.sh

检查另外三台是否启动节点。



7.2 访问 集群
集群已经完成。

7.3 停止 hdfs 集群
./sbin/stop-dfs.sh

8.yarn
8.1 启动yarn
./sbin/start-yarn.sh

8.2 访问yarn管理程序

9.JobHistory
9.1 启动 JobHistory
./sbin/mr-jobhistory-daemon.sh start historyserver
![]()
9.2 访问 JobHistory

9.3 停止 JobHistory
./sbin/mr-jobhistory-daemon.sh stop historyserver

10.验证hdfs 分布式文件系统
10.1 创建文件test
vi test

10.2 创建hdfs 文件夹 input_test
./bin/hadoop fs -mkdir /input_test

10.3 把test文件放入input_test
./bin/hadoop fs -put test /input_test
![]()
10.4 检查input_test
./bin/hadoop fs -ls /input_test



10.5 删除hdfs文件
./bin/hadoop fs -rm -r /input_test
![]()
















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









