



本文是对多传感器数据融合中可见光图像和红外图像的融合方法的分类和整理。
首先,我参考了张老师的知乎文章、发表的论文、VIFB项目和imagefusion_DL项目以及关于可见光和红外图像融合的综述。讲目前主流的图像融合方法归纳为:
- 基于多尺度变换的方法;
- 基于稀疏表示的方法;
- 基于神经网络的方法;
- 基于子空间的方法;
- 基于显著性的方法;
- 基于混合的方法;
- 其他方法。

算法的获取可以参见张老师的知乎文章。
代表性的多尺度变换方法
- 拉普拉斯金字塔LP
- 小波变换Wavelet
- 非下采样轮廓波变换NSCT
- 双树多分辨率离散余弦变换DTMDCT
- 交叉双边滤波CBF
- 混合多尺度分解HMSD
- 导向滤波融合GFF
- 各向异性扩散融合ADF
代表性的稀疏表示方法
- ASR
- LP和稀疏表示LPSR
代表性的神经网络方法
- 方向信息激励PCNN OI-PCNN
- NSCT域SF-motivated PCNNs NSCT-SF-PCNN
代表性的子空间方法
- 方向离散余弦变换和主成分分析DDCTPCA
- FPDE
代表性的显著性方法
- 基于图像显著性的双尺度图像融合TSIFVS
- 局部边缘保留LEPLC
其他方法
- 梯度转移融合GTF
- IFEVIP
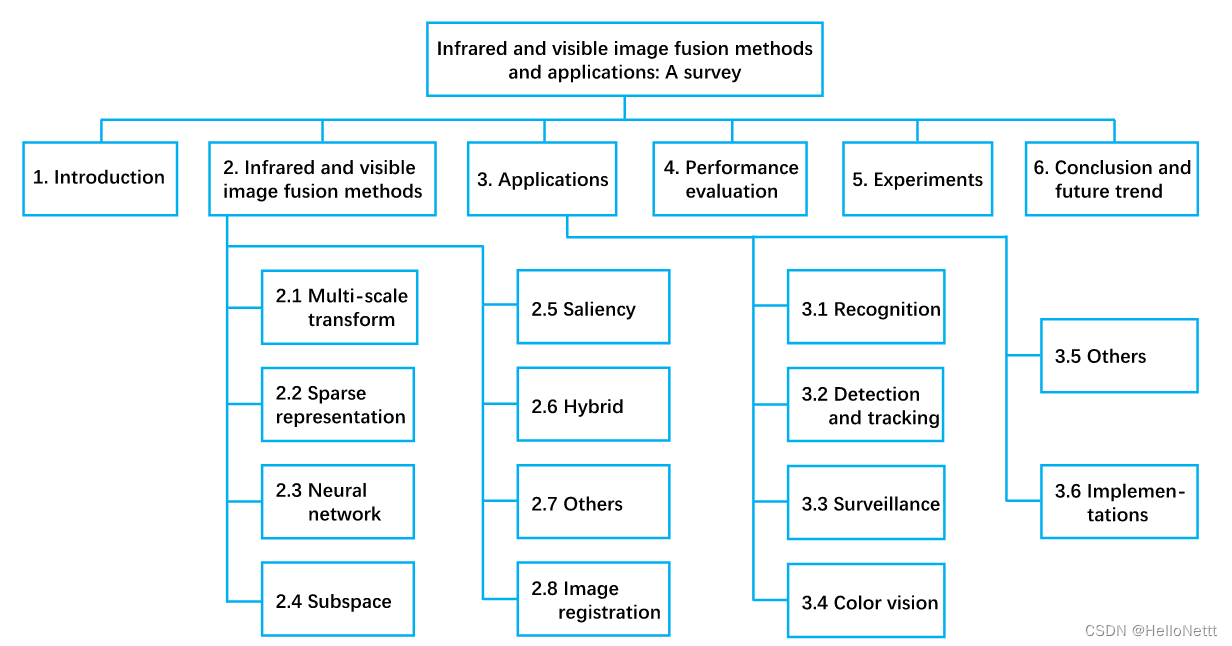
1. 基于多尺度变换的方法
这部分总结的主要参见@Dandelion_2的文章:
图像融合中多尺度变换方法总结(上)
图像融合中多尺度变换方法总结(下)
一般来说,基于多尺度变换的红外与可见光图像融合方案包括三个步骤[1],如图2所示。首先,将每个源图像分解为一系列多尺度表示。然后,根据给定的融合规则对源图像的多尺度表示进行融合。最后,对融合后的图像进行相应的多尺度逆变换得到融合后的图像。基于多尺度变换的融合方案的关键在于变换和融合规则的选择。接下来,我们在这两个方面的基础上,对这类技术进行综述。
1.1 金字塔变换
金字塔变换的概念提出于20世纪80年代,其目的是将原始图像分解为具有不同空间频带尺度的子图像,这些子图像具有金字塔数据结构[31]。从那时起,各种类型的金字塔变换被提出用于红外和可见光图像融合,拉普拉斯[32-34],可导向[35 -37]和对比[38-41]金字塔。
1.1.1 拉普拉斯金字塔变换LP
1.1.2 对比度金字塔CP
1.2 小波变换
小波变换的概念是由Grossman和Morlet在20世纪80年代提出的。然后,Mallet建立了小波变换的多分辨率理论;该理论的灵感来自于信号分解与重构的塔算法[43]。小波变换在图像融合及相关领域得到了广泛的应用。与金字塔变换的多尺度表示系数不同,小波变换的多尺度表示系数是不相关的。典型的基于小波变换的红外和可见光图像融合方法有离散小波变换[44-48]、双树离散小波变换[44,50]、提升小波变换[51]、提升平稳小波变换[52]、冗余提升不可分小波多向分析[53]、谱图小波变换[54]、四元数小波变换[55]、运动补偿小波变换[56]和多小波[57]。
1.2.1 离散小波变换DWT
1.2.2 双树复小波变换DTCWT
1.2.3 曲波变换CVT
1.2.4 非下采样轮廓波变换NSCT
小波变换是一种快速有效的表示一维分段平滑信号的方法,已成功地应用于信号处理和通信领域。将一维信号小波变换扩展为二维图像小波变换,可以隔离边缘点的不连续。然而,二维小波变换无法捕捉图像丰富的方向信息。为了克服这一问题,Minh N. Do和Martin Vetterli提出了一种高效的多方向多分辨率图像表示方法——contourlet变换[59]。该模型基于拉普拉斯金字塔[32]和定向滤波器组[60],能够很好地捕获图像边缘的几何形状[61-63]。但是,轮廓波变换存在下采样和上采样引起的移差和金字塔滤波器组结构造成的冗余等问题。
1.2.5 非下采样剪切波变换NSST

1.3 基于边缘保持滤波器
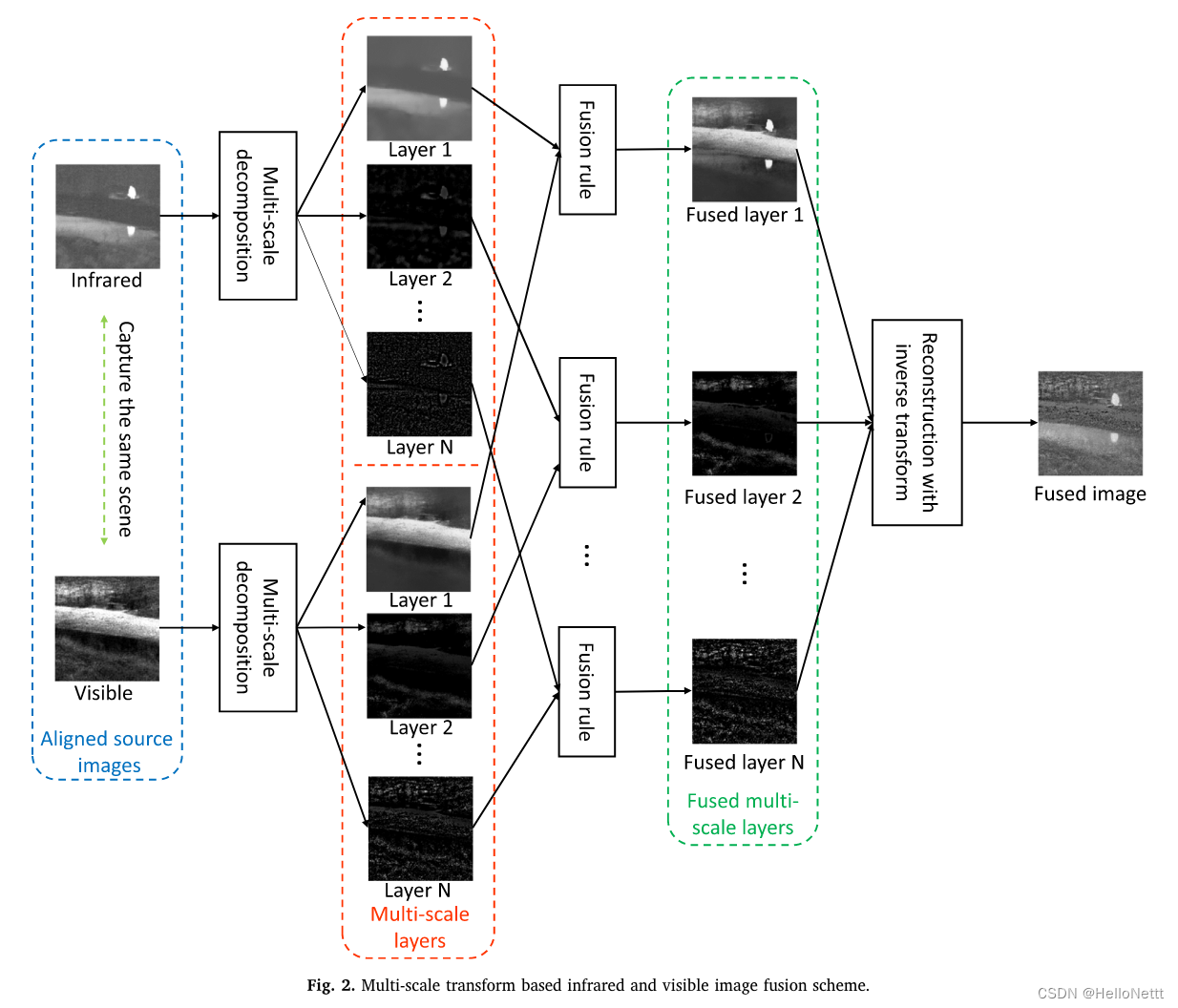
2.基于稀疏表示的方法
稀疏表示图像融合方法旨在从大量高质量的自然图像中学习一个过完备的字典。然后,通过学习字典对源图像进行稀疏表示,从而潜在地增强有意义且稳定的图像[26]的表示能力。此外,错配或噪声会使融合的多尺度表示系数产生偏差,从而导致融合图像中的视觉伪影。同时,基于稀疏表示的融合方法使用滑动窗口策略将源图像划分为几个重叠的小块,从而潜在地减少了视觉假象,提高了对错配[18]的鲁棒性。通常,基于稀疏表示的红外和可见光图像融合方案包括四个步骤[26],如图3所示。首先,使用滑动窗口策略将每个源图像分解为几个重叠的小块。其次,从大量高质量的自然图像中学习一个过完备字典,并对每个patch进行稀疏编码,利用学习到的过完备字典获得稀疏表示系数;第三,根据给定的融合规则对稀疏表示系数进行融合。最后,利用学习到的过完备字典对融合系数进行重构。基于稀疏表示的融合方案的关键在于过完备的字典构造、稀疏编码和融合规则。在接下来的章节中,我们将在这三个方面的基础上回顾相关的技术。
2.1 构造过完备字典
2.2 对参数进行稀疏编码
3. 基于神经网络的方法
大多数基于神经网络的红外和可见光图像融合方法都采用脉冲耦合神经网络(PCNN)或其变体。PCNN由Eckhorn等人在20世纪80年代末提出[162];他们引入了一种叫做埃克霍恩模型的神经方法,来模拟猫视觉皮层神经元的同步脉冲和耦合。这些发现推动了PCNN的发展和产生;即Johnson对Eckhorn的模型进行了修正,并将修正后的方法称为PCNN[163]。1996年,Broussard和Rogers在生理学启发的理论模型基础上,首次将PCNN应用于图像融合,从而证明了PCNN的可行性和优势[164]。此后,许多基于PCNN及其变体的红外和可见光图像融合方法被提出。
3.1 脉冲耦合神经网络PCNN及其变体
将PCNN应用于图像融合,除了结合多尺度变换和基于PCNN的红外和可见光图像融合方案外,还可以采用其他方法。如Chen等人在压缩域中采用PCNN [160], Lu等人采用PCNN对源图像进行分割并融合目标系数[146]。
此外,某些融合方法是基于改进的PCNN模型[13,76]。Kong等人提出了一种单位快速连接PCNN来融合高频和低频子带系数,从而利用了单位快速连接PCNN的优势[76];他们还提出了一种空间频率PCNN来融合高低频子带系数,这些子带系数使用非下采样剪切波变换[13]进行分解。
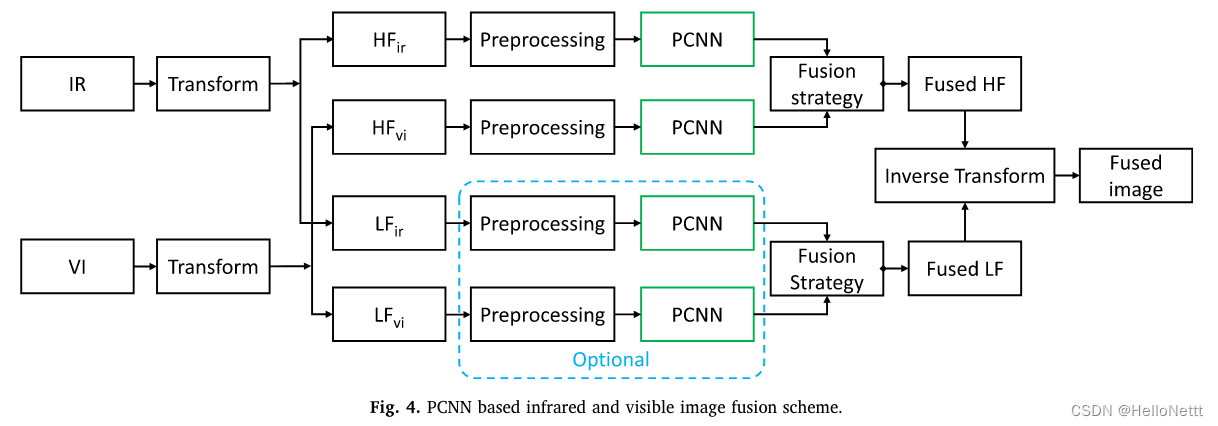
3.2深度网络CNN、ResNet等
这部分主要参考:Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review

深度学习具有很强的数据间复杂关系建模能力。此外,深度学习可以自动从数据中提取不同的特征,无需人工干预[165]。因此,深度学习也成功地应用于图像融合中,如多聚焦图像融合[166,167]、多模态图像融合[141,168,169]、遥感图像融合[170,171]以及红外和可见光图像融合[172]。据我们所知,目前只有一种基于深度学习的融合方法专门用于红外和可见光图像的融合。具体而言,Liu等人提出了一种基于卷积神经网络的方法,该方法可以将红外和可见光图像融合中的活度测量和权重分配作为一个整体来处理,以克服手工设计的困难[172]。然而,有几种通用的图像融合方法可以应用于红外和可见光图像的融合。例如,Liu等人介绍了用于图像融合的卷积稀疏表示[141];他们从反卷积网络(反卷积网络)中获得了这个想法[173],反卷积网络的目的是构建一个分层结构,每层包含一个编码器和一个解码器。Zhong等人提出了一种联合图像融合和超分辨率方法,该方法基于卷积神经网络(CNN)训练,使用来自ImageNet数据库的90张精选图像[168]。
3.2.1 CNN及其变体
不足:
- 它只适用于多聚焦图像融合,只使用最后一层来计算结果。中间层获得的许多有用信息将会丢失。当网络深度增加时,信息丢失会变得更加严重。
- 特征提取仍然会丢失一些信息。
- 在不同的应用领域,由于分辨率和光谱差异较大,融合结果的准确性无法保证。不同源图像的具体性能需要在特定数据集中考虑。
- 大量复杂背景的样本给模型训练带来了大量的计算量。
3.2.2 CNN与高斯金字塔结合的方法
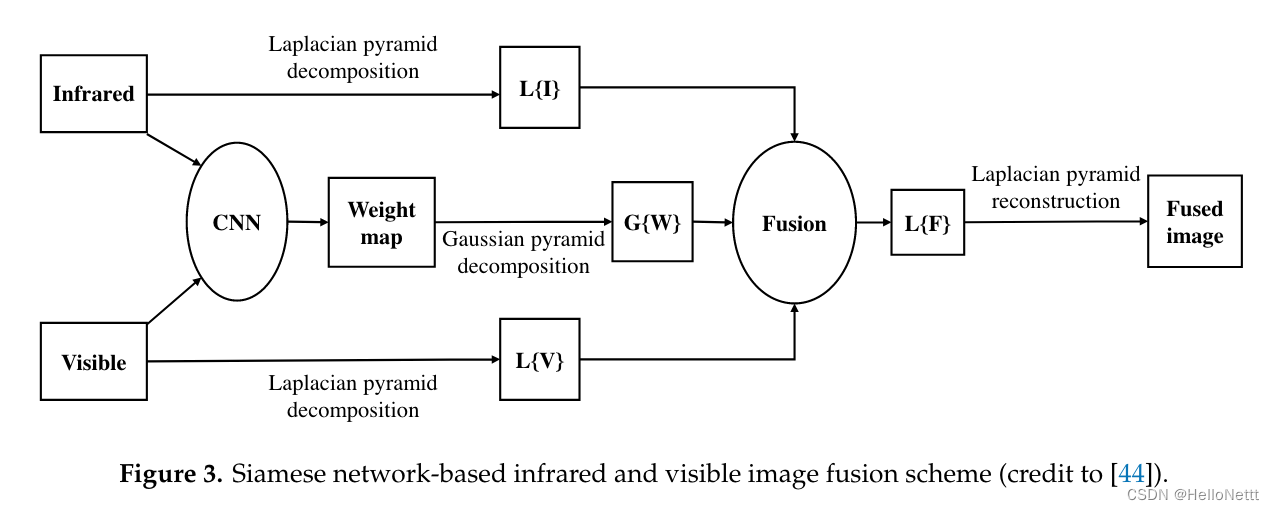
不足:
- 这个方法的出发点是目标跟踪。就融合效果而言,融合结果略有模糊。
- 它不能与传统的融合技术有效结合,也不适合复杂的数据集。
- 热红外网络训练使用可见图像,您可以考虑使用热红外图像以获得更好的效果。
- 由于使用了CPU来训练模型,因此模型的计算效率不是很突出。处理一对源图像平均需要19秒。
3.2.3 GAN及其变体
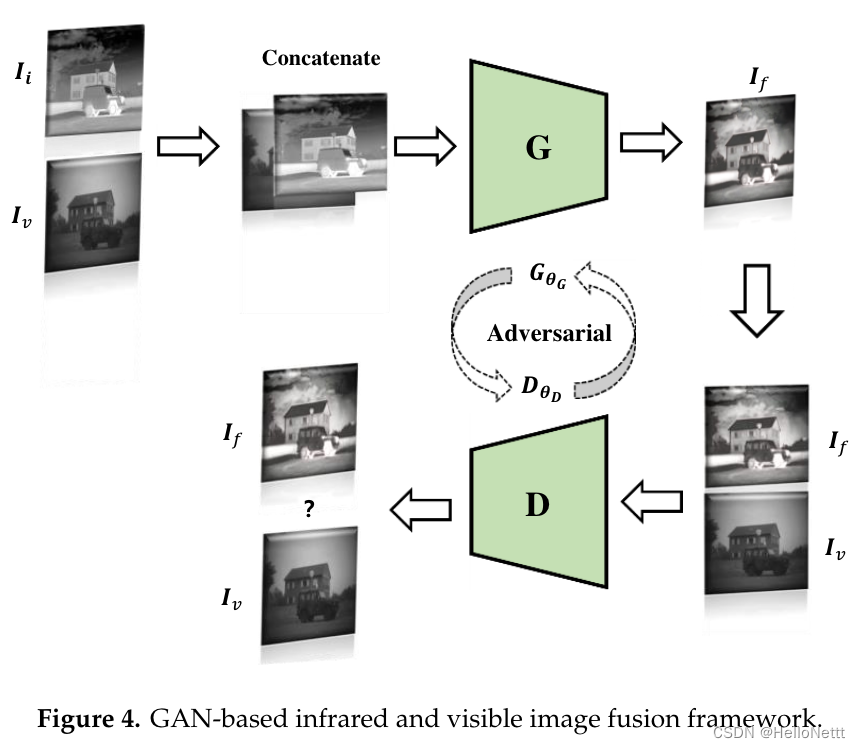
不足:
- 降低红外热目标的突出度。
- 改变了部分融合图像区域的像素强度,降低了整体亮度。
- 融合图像的一些边缘有点模糊。
- 独特的融合结果具有明亮的伪影。
- 在模型训练的早期,对预融合的图像进行标记需要一定的时间。
3.2.4 AE及其变体
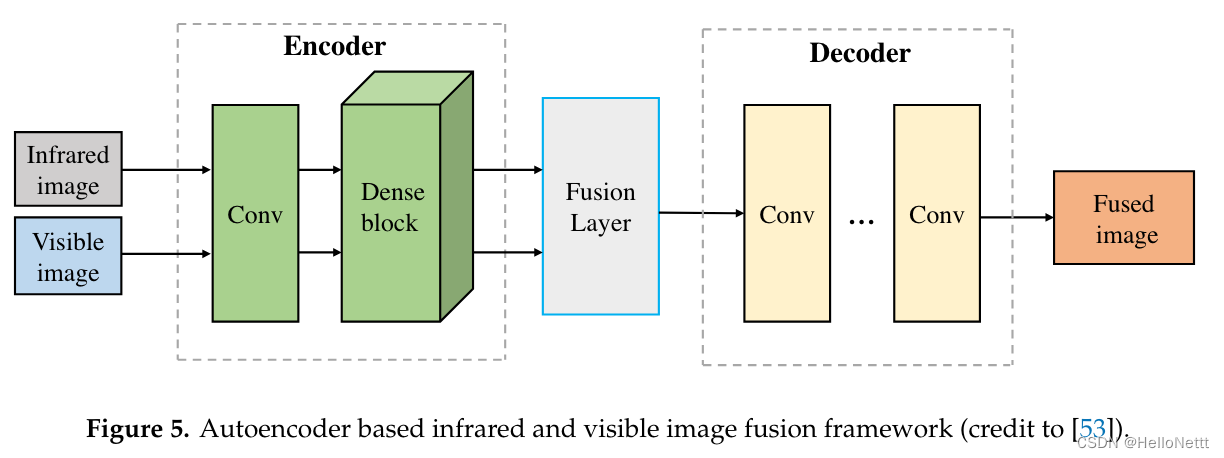
4. 基于子空间的方法
基于子空间的方法旨在将高维输入图像投射到低维空间或子空间中。对于大多数自然图像,存在冗余信息,低维子空间有助于捕捉原始图像的内在结构。此外,处理低维子空间数据比处理高维输入图像消耗更少的时间和内存。此外,低维子空间表示可用于改进泛化[174]。因此,基于子空间的方法,包括PCA、ICA和NMF,已经成功地应用于红外和可见光图像融合。
4.1 主成分分析PCA
PCA旨在将可能相关的变量转换为称为主成分的不相关变量,从而可能降低维数,同时保持原始数据的信息。此外,PCA可以减少冗余信息,突出异同[175]。因此,PCA已被应用于红外和可见光图像融合[14,61,176 - 179]。如Li等人采用PCA融合形态学-帽子变换分解的低频图像[61];能量信息主要存在于低频图像中,采用PCA对原始图像的亮度信息进行维护。Bavirisetti等使用PCA融合四阶偏微分方程[14]分解的细节图像;该方法可以获得将细节信息传递到最终融合图像的最佳权重。
4.2 独立成分分析ICA
ICA是PCA的扩展,旨在将可能相关的变量转化为不相关的自变量[174];它还成功地应用于红外和可见光图像融合[184 -187]。基于ICA的图像融合方法通常使用与待融合图像内容相似的几张自然图像训练一组基。在获得一组经过预先训练的基地后,可以与内容相似的基地进行融合。
ICA是PCA的扩展,旨在将可能相关的变量转化为不相关的自变量[174];它还成功地应用于红外和可见光图像融合[184 -187]。基于ica的图像融合方法通常使用与待融合图像内容相似的几张自然图像训练一组基。在获得一组经过预先训练的基地后,可以与内容相似的基地进行融合。
Cvejic等人提出了一种基于区域的ICA图像融合方法[184],该方法将源图像分割为不同的区域,使用预先训练的基获得每个区域的ICA系数;然后根据融合图像质量最大化准则,用Piella融合度量对ICA系数进行加权。Mitianoudis等人在基于像素和区域的融合方案下采用ICA和地形ICA基进行图像融合[185]。与传统ICA基相比,地形ICA基表现出更好的方向选择性,从而获得更好的图像特征。此外,作者提出了一种基于自训练ICA基的图像融合方法;该方法在基于区域的融合方案下采用k-means聚类和分层分组来提高ICA图像融合性能[186]。Omar等人结合ICA和Chebyshev多项式逼近提出了一种新的图像融合方法[187];利用独立分量分析(ICA)捕获显著特征,利用切比雪夫多项式去除噪声,特别是在噪声严重退化的图像中。
4.3 基于非负矩阵分解NMF
NMF旨在将原始数据矩阵分解为两个非负矩阵的乘积。这种方法是一种基于部分的对象表示模型[188],符合人类的感知机制。鉴于这些优点,NMF已被应用于红外和可见光图像融合[15,189-191]。
Mou等人采用NMF提取源图像的特征库[191],从而保持可见图像中的细节,突出红外图像中的特征,去除噪声。然而,传统的NMF算法耗时长,效率低。为了克服这些问题,Kong等人采用了改进的NMF,它可以克服基于svd的随机初始化的缺点,因此比传统的随机初始化NMF收敛更快[190];采用快速NMF融合非下采样剪切波变换分解的低频和高频子图像;快速NMF比传统NMF[15]更简单,计算效率更高。
5. 基于显著性的方法
显著性以一种自下而上的方式吸引人类的视觉注意力[192],这种注意力通常被比它们的邻居更重要的对象或像素所捕获。根据人类视觉系统的机制,基于显著性的融合方法可以保持显著目标区域的完整性,提高融合图像的视觉质量。因此,基于显著性的方法已广泛应用于红外和可见光图像的融合。
近年来,研究人员采用基于显著性的方法进行红外和可见光图像融合,主要有两种方法:权重计算[16,19,79,80,85,87,88,109,129]和显著性物体提取[6,107,153,193 -195]。
5.1 权重计算
第一种情况下,采用显著性对融合图像进行重构。通过多尺度变换将红外图像和可见光图像分解为基层和细节层,在源图像的基层和细节层应用显著性提取模型,得到显著性图。然后,通过显著性图得到权重图,得到融合后的基像或/和细节图,再通过融合后的基像和细节图构造融合后的图像。如Gan等采用相位一致的方法获得源图像的基层和细节层的显著性图,然后对显著性图进行引导滤波得到加权图[87]。Ma等人首先采用滚动制导和高斯滤波将红外和可见光图像分解为基层和细节层,然后使用改进的视觉显著性图和加权最小二乘优化将基层和细节层分别融合为[19]。
5.2 显著性物体提取
显著性还可以用于提取源图像的显著目标区域,从而获得良好的视觉效果,并保留图像细节。因此,该模型非常适合于目标检测和识别等监控应用。例如,文献[65,107,193]中的某些研究工作采用显著性模型提取红外图像的显著区域。孟等采用显著性检测方法提取显著性目标区域,将显著性目标区域映射到最终融合图像的区域。Zhang等使用基于超像素的显著性模型,获得红外图像的显著性区域;该模型能够很好地保存红外图像的目标信息[107]。此外,一些研究工作[153,194,195]采用显著性模型从红外和可见光图像中提取显著性目标和信息。Liu等人将显著性检测集成到红外和可见光图像融合的稀疏表示框架中,采用全局和局部显著性映射来获取融合图像重建的权重[153]。Shibata从红外和可见光图像中提取显著信息,从而保留显著信息[195]。
6. 基于融合的方法
上述红外和可见光图像融合方法各有优缺点,应结合两者的优点来提高图像融合性能。最常见的红外和可见光混合图像融合方法将其他类型的方法集成到多尺度变换框架中,如混合多尺度变换和显著性[16,19,65,79,80,85,87,88,88,101,103,107],混合多尺度变换和稀疏表示[18,48,73,148,196,197],混合多尺度变换和神经网络[13,53,57,62,63,104],混合多尺度变换、稀疏表示和神经网络方法[74108,198]。
多尺度变换与显著性混合方法旨在将显著性区域检测融合到多尺度变换图像融合框架中,增强感兴趣区域,保留细节。例如,Zhang等人采用局部保边滤波器将源图像分解为基层和细节层,并利用红外图像检测到的显著目标确定基层[16]的权重。
稀疏表示和神经网络常常被整合到多尺度变换的红外和可见光图像融合框架中。如Liu等人将多尺度变换与稀疏表示[18]相结合,提出了一种通用的图像融合框架,并采用稀疏表示得到融合后的低频子带系数。Lin等人提出了一种新的基于contourlet变换和改进PCNN的红外和可见光图像融合方法;利用contourlet变换将源图像分解为多尺度子图像,利用改进的PCNN融合高低频子带系数[62]。Yin等人提出了一种新的混合多尺度变换、稀疏表示和神经网络融合方法,采用一种新的移不变双树复shearlet变换将源图像分解为多尺度子图像,采用稀疏表示获取融合低频子带系数,采用自适应双通道PCNN获取融合高频子带系数[108]。
混合稀疏表示和显著性方法[139,153]和混合稀疏表示和神经网络方法[143,146]。如Liu等人将显著性检测融入到稀疏表示框架中[153],在稀疏表示系数的基础上构建显著图,再通过显著图得到融合的稀疏表示系数。Chang等人提出了一种新的图像融合方法,该方法基于稀疏表示和深度神经网络的结合[143],将外部和内部的卡通和纹理稀疏表示结果结合起来。
7. 其他方法
其他的红外和可见光图像融合方法可以为图像融合提供新的思路和视角。Ma等人提出了一系列基于全变分的红外和可见光图像融合方法[20,199,200]。之前的一项工作[20,199]的主要思想是保留红外图像的强度信息,同时保留可见图像的外观信息。然而,忽略了可见光图像的强度信息,导致动态范围较低,细节丢失。在[200]中,Guo等人不仅保留了红外和可见光图像的强度信息,还保留了可见光图像的外观信息,从而提高了融合性能。
高质量的图像融合是一个模糊问题[201],模糊理论是通过模糊逻辑或基于模糊的方法解决模糊问题的有效工具。因此,模糊理论已成功应用于红外和可见光图像融合[25,49,66202 -204]。该理论常用于确定红外和可见光图像融合的融合规则[25,49,66202]。如Yin等采用模糊逻辑获得自适应加权平均规则[66]。模糊逻辑系统也被应用到红外和可见光图像融合中[203],模糊逻辑系统的关键概念是从0到1的隶属函数,它可以用来衡量图像融合性能的不确定性。Bai等人也提出了一种新的基于模糊测度权重策略的红外与可见光图像融合规则[204]。
其他类型的红外和可见光图像融合方法也存在,如熵[21,205],马尔可夫随机场[193,206],形态学[207,208],红外特征提取和视觉信息保存[209]。熵是一种客观的度量指标,用来衡量从源图像传递到融合图像的信息量。Zhao等人采用全局最大熵准则,将尽可能多的源图像信息转移到融合图像[21]中。 马尔可夫随机场也是红外与可见光图像融合的有效工具。例如,Han等人采用马尔可夫随机场进行显著性检测,这可以表述为像素标记问题[193]。Shibata等人利用马尔可夫随机场来保留源图像的可见信息和空间相干性[206]。 形态学方法也应用于图像融合。具体而言,Bai等人采用形态学方法提取多尺度形态学特征,用于红外和可见光图像融合[207,208]。
上述的红外和可见光图像融合方法大多在像素级进行,将源图像中的每个像素进行组合,直接获得融合后的图像。然而,图像融合也可以在特征级或决策级执行。特征级图像融合方法通常先提取源图像的特征,然后根据提取的特征得到具有特定目的的融合图像,与像素级融合策略相比,其优点是根据提取的特征设计更智能的语义融合规则[210]。因此,红外和可见光图像融合也采用了特征级融合方法[72,191,207,209,211,212]。例如Li等人提出了一种基于非下采样contourlet变换和底层视觉特征的融合方案[72]。由于人类视觉系统对图像质量的感知主要是根据一些底层特征,他们设计了基于底层特征的非下采样contourlet变换分解的低通子带和高通子带两种活动度量。另外,Bai等人提出了一种通过形态顺序切换算子进行特征提取的融合方法[207]。利用序列切换算子提取源图像的特征,然后基于多尺度形态学理论将原始红外图像和可见光图像的多尺度特征转移到融合图像中。
8. 图像融合评价指标
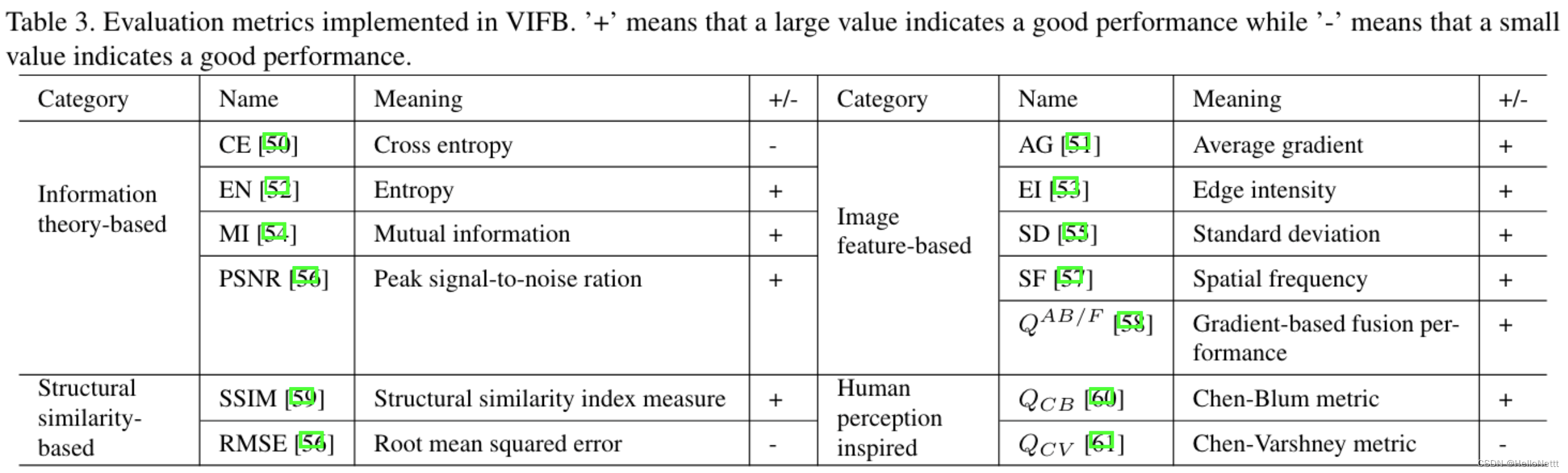
这里可以参考系列文章:
图像融合质量评价方法SSIM、PSNR、EN、MSE与NRMSE(一)
图像融合质量评价方法AG、SF、STD、MI与NMI(二)
图像融合质量评价方法MSSIM、MS-SSIM、FS、Qmi、Qabf与VIFF(三)
图像融合质量评价方法FMI(四)


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









