






 本文介绍了DSSM模型的双塔结构,区分了召回和粗排两种场景,详细阐述了样本准备、模型特征、loss函数的选择以及线上部署策略,强调了特征融合和分离的不同点,并讨论了负样本采样的重要性。
本文介绍了DSSM模型的双塔结构,区分了召回和粗排两种场景,详细阐述了样本准备、模型特征、loss函数的选择以及线上部署策略,强调了特征融合和分离的不同点,并讨论了负样本采样的重要性。
文章目录
简介
DSSM 模型总的来说可以分成三层结构,分别是输入层、表示层和匹配层。双塔结构如下图所示:
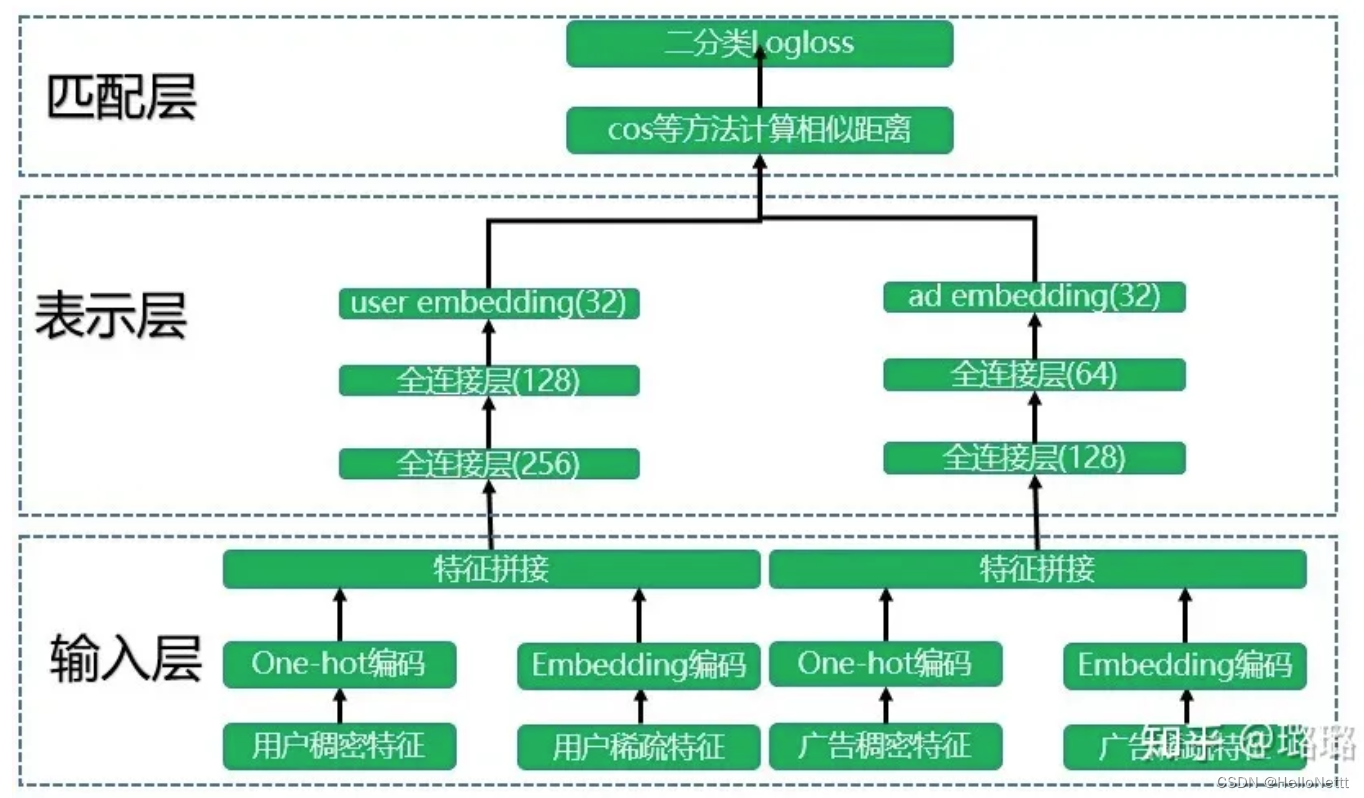
DSSM的训练方式
- Pointwise:独立看待每一个正样本、负样本,做简单的二元分类。

- Pairwise:每次取一个正样本,一个负样本。
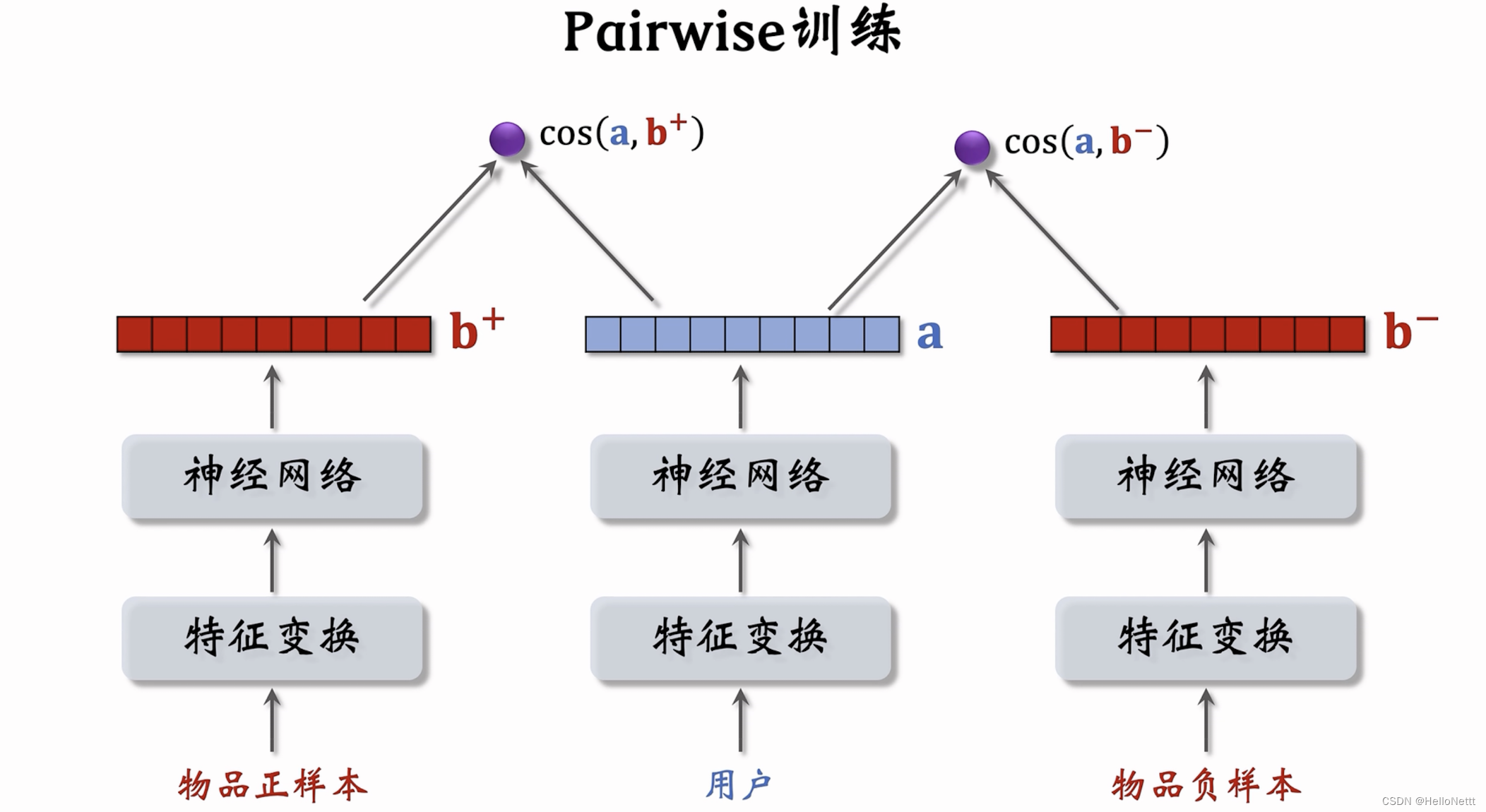
(1)第1种loss:Triplet Hinge Loss

(2)第2种loss:Triplet Logistic Loss,这里 σ \sigma σ是控制loss函数形状的超参数。

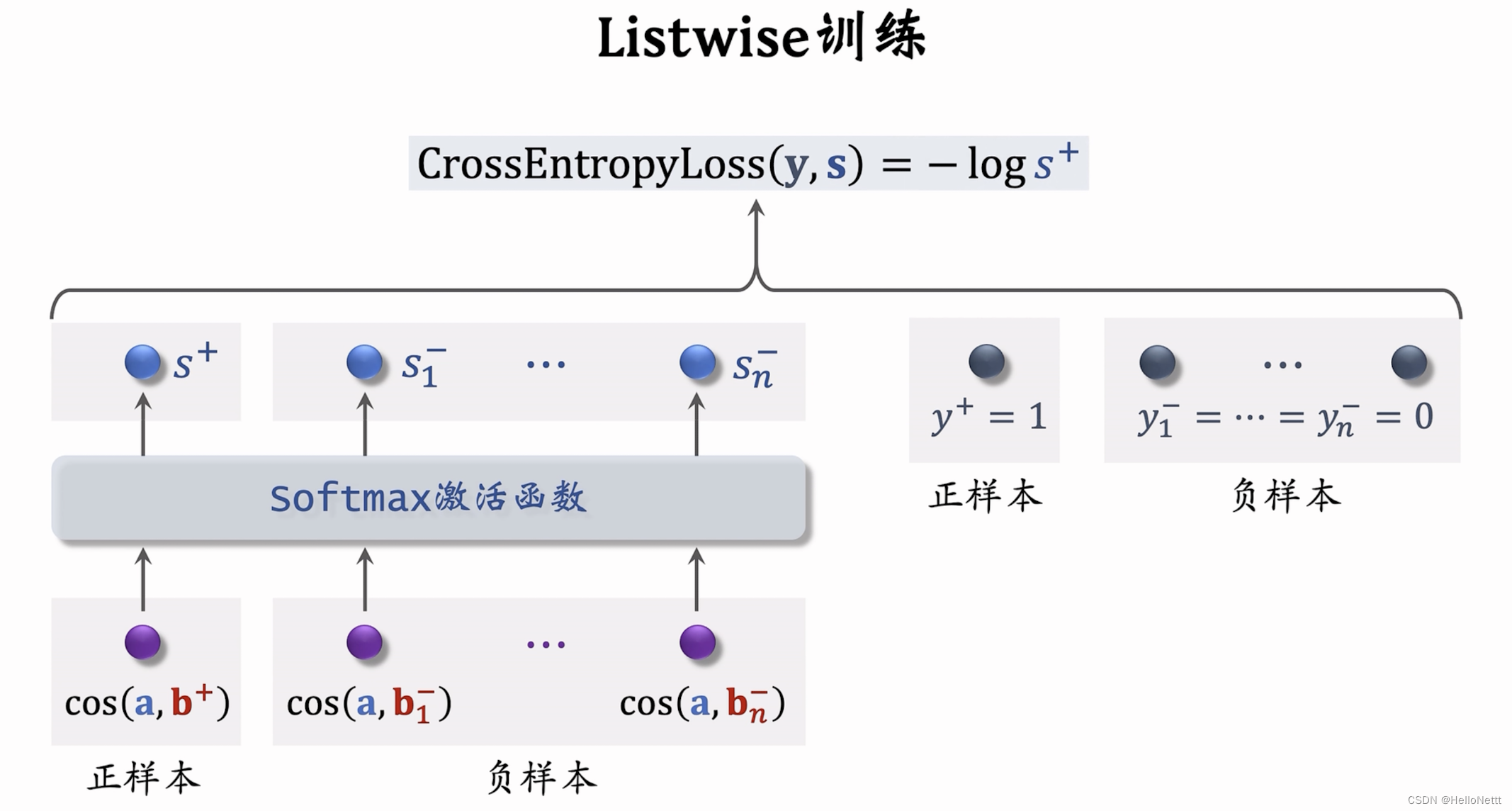
- Listwise:每次取一个正样本,多个负样本。

这里 s s s表示softmax输出的预测值, y y y表示正负样本的标签。
1 双塔模型的召回结构
召回模型一般是特征后融合。
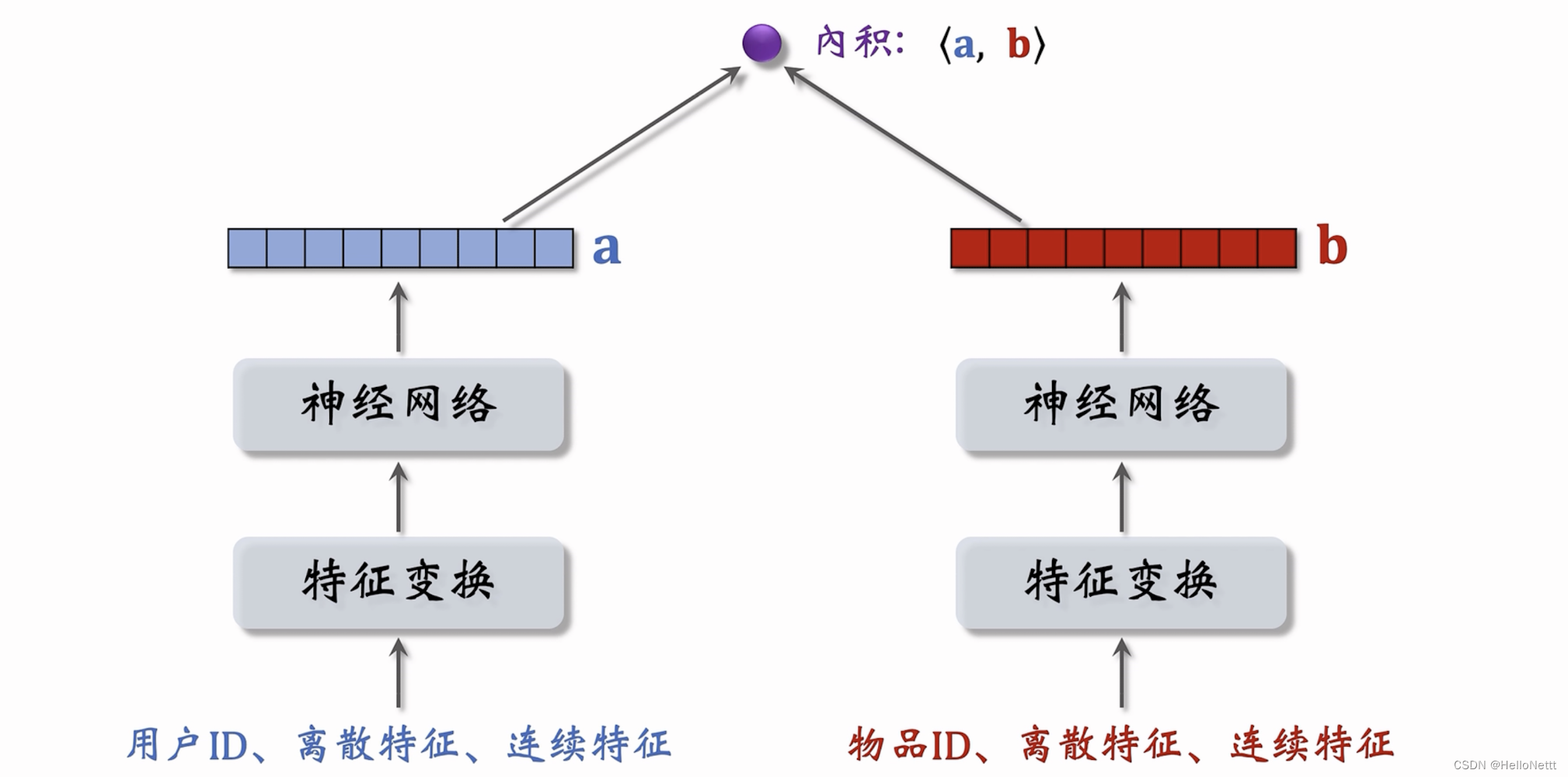
一个被实践的召回模型的实例:
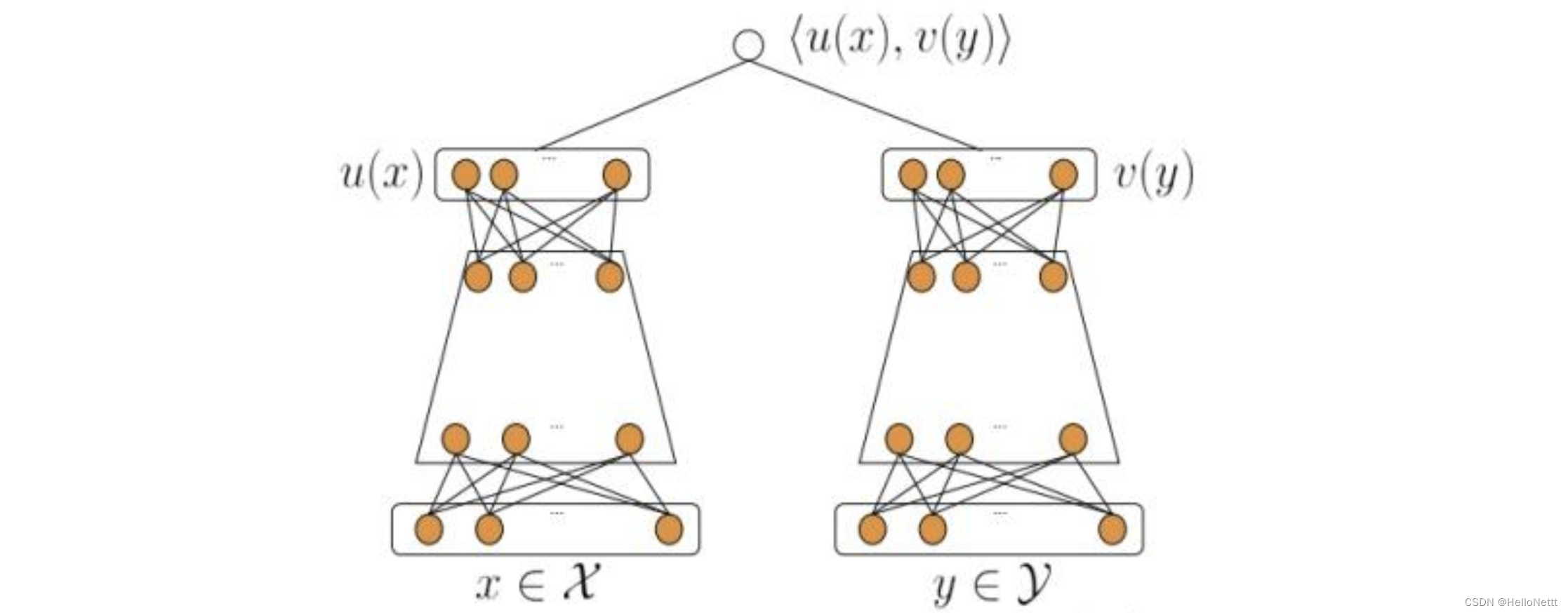
如图所示,其中:
- x x x为(user,上下文)的特征, y y y为(item)的特征;
- u ( x ) u(x) u(x)表示(user,上下文)最终的Embedding向量表示, v ( y ) v(y) v(y)表示(item)最终的Embedding向量表示;
-
<
u
(
x
)
,
v
(
y
)
>
<u(x), v(y)>
<u(x),v(y)>表示(user,上下文)和(item)的余弦相似度(或者 点积),如下式。
R ( u , v ) = c o s i n e ( u , v ) = u T v ∣ ∣ u ∣ ∣ ∣ ∣ v ∣ ∣ R(u,v) = cosine(u,v) = \frac{u^T v}{||u||\; ||v||} R(u,v)=cosine(u,v)=∣∣u∣∣∣∣v∣∣uTv
在推荐系统中,一般左侧为User Tower,右侧为Item Tower,因此称之为双塔模型。
优点:
- 该结构对工业界非常友好,两个子网络产生的embedding向量可以独自获取以及缓存;
- 两个塔可以分别对user和item建模,可拓展性强,使用灵活。
缺点:
- 该结构进行的是特征后融合,即user和item仅在最后softmax才产生交互
1.1 样本准备
用户链路:曝光-点击-下载-购买。
正样本:曝光&&下载
负样本为什么不能是 曝光&&未下载?
如果只是曝光未下载当做负样本的话,那训练样本分布就和精排无异了,但实际上精排的样本是经过召回粗排等层层筛选过的,而召回面对的是庞大的物料库。所以,如果只是用曝光未下载当做负样本那线上线下的的样本分布就不一致了。
负样本如何选择?
(1)随机采样物料库作为负样本
大部分实验采用随机采样物料库作为负样本。这样能保证召回模型中存在不同的物料。
(2)参考word2vec中的负采样方法
采样概率应该与物料出现频率相关。当高频物料作正样本时,要降采样;当高频物料作负样本时,要适当过采样。这样可以抵消高频物料对正样本集的绑架,同时也保证低频物料在负样本集的出现机会。
(3)在batch内随机采样
考虑工程复杂度,这是工程实现中最常用的方案。
针对每条正样本,在每个batch内采样m个负样本。
注意:这里有一个点需要注意,如果你的物料比较少,且头部效应比较明显,这种情况下在batch随机采样为负样本很有可能采样到正样本当做负样本,所以是不适合该方案的。这种物料足够少的情况下,物料大部分都出现过,甚至没必要进行负采样。
P.S.:在(3)的基础上,还有 a.丢弃重采样; b.伪负样本反转;c. 伪负样本反转&&伪负样本赋权
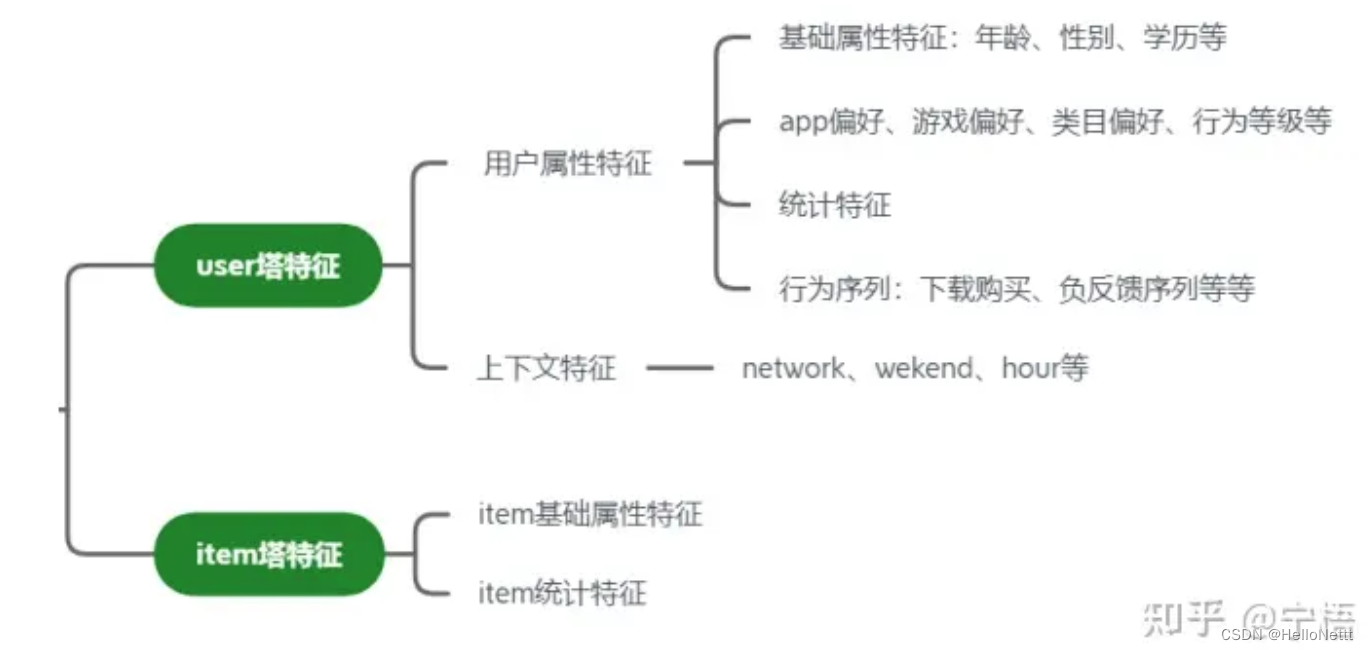
1.2 模型特征
1.3 模型loss
一般采样方法是在batch内随机采样,针对每条正样本,在每个batch内采样m个负样本。所以最终选用的是softmax的交叉熵损失函数,即交叉熵(softmax®)。

1.4 线上部署
DSSM的召回分为u2i、u2i2i、i2i等等召回。这里以u2i召回举例说明。
在做DSSM的u2i召回时,考虑到用户量在亿级别,item在18w级,用户量庞大而物料库比较小,所以这里u2i的整体思路是用户向量在线生成,而物料库向量离线生成,线上生成的向量再用faiss与离线item embeding计算点积生成候选集。
(1)用户向量如何在线生成
双塔模型的两个塔结构时完全分离的,所以这里把user和item两个塔的模型分别输出,方便后续使用user模型线上生成用户向量。
(2)物料库向量如何生成
这里我们需要先构造包含所有物料的测试数据集(可以伪造一个用户信息和上下文信息,然后拼接物料库所有item数据来构造),然后predict测试集的时候输出物料塔的最后一层隐向量当做物料embeding。
2 双塔模型的粗排结构
粗排模型一般是特征前融合。
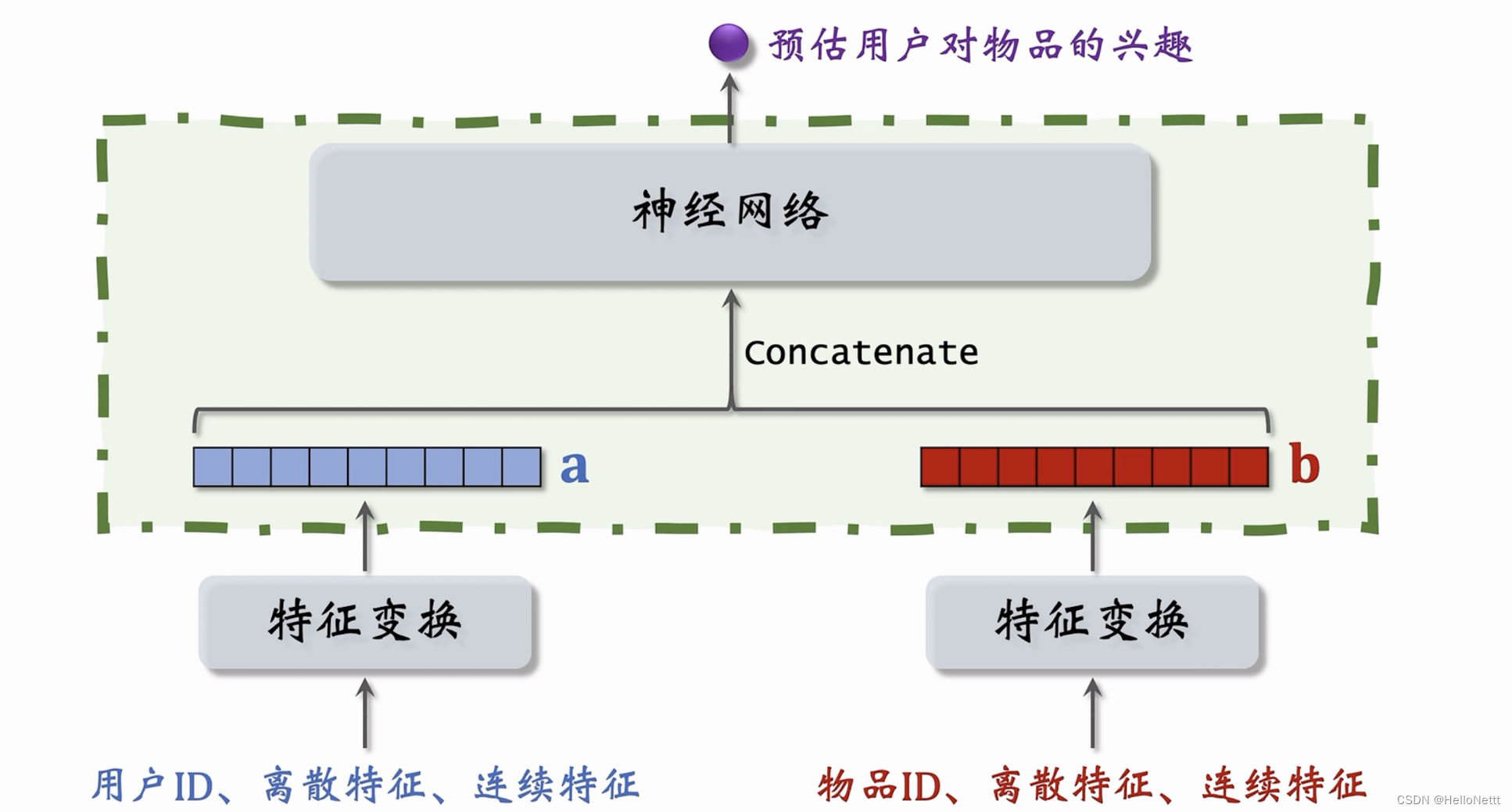
一个被实践的粗排模型的实例:
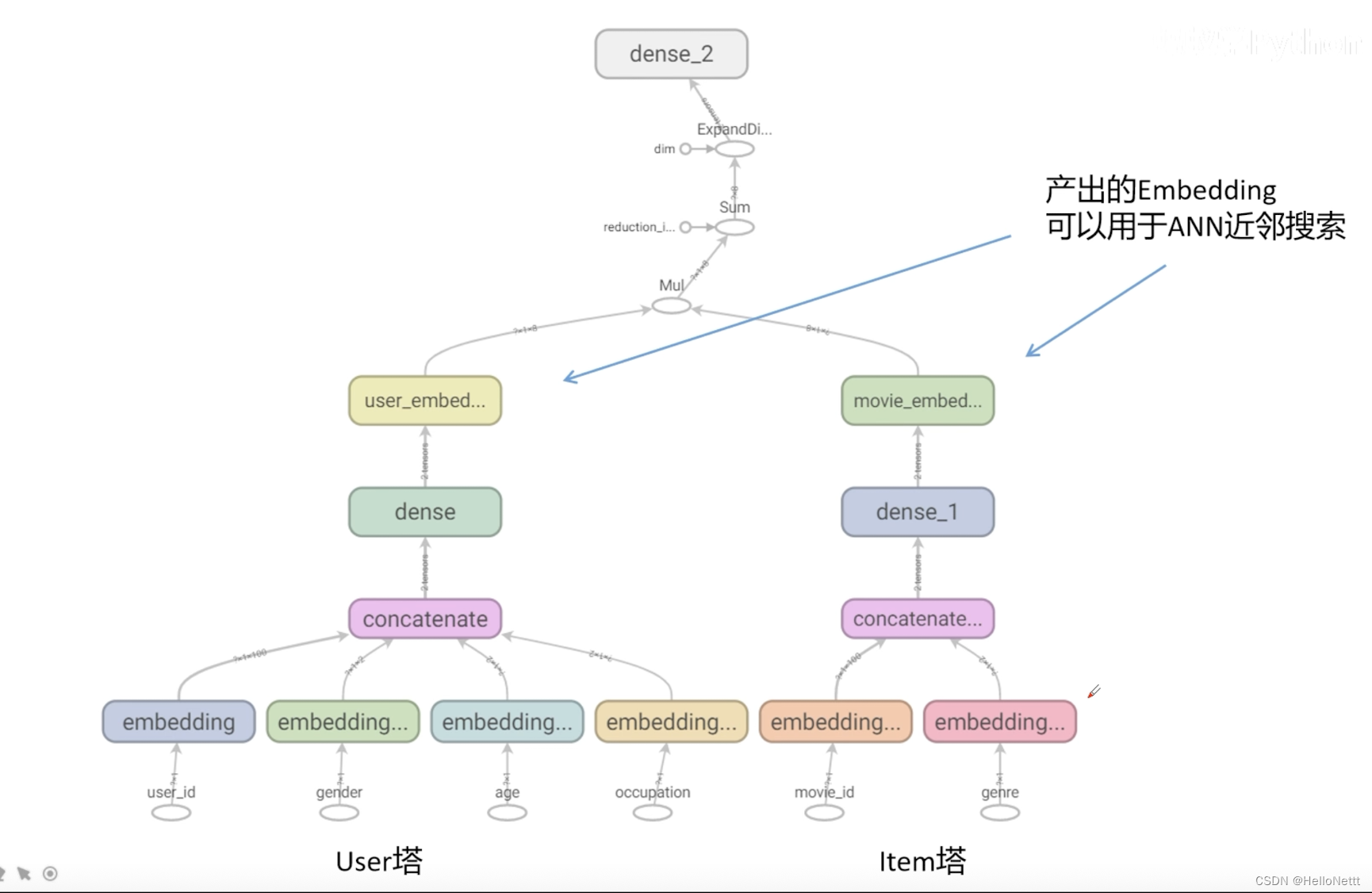
2.1 样本准备
粗排的样本分布一般与精排保持一致。
正样本:曝光&&下载
负样本:曝光&&未下载
2.2 模型特征
2.3 模型loss
一般采样方法是在batch内随机采样,针对每条正样本,在每个batch内采样m个负样本。所以最终选用的是softmax的交叉熵损失函数,即交叉熵(softmax®)。
2.4 线上部署
在做DSSM粗排粗排时,具体来说:
(1)用户塔模型和物料塔模型按天/时生成,部署线上
双塔模型的两个塔结构是完全分离的,所以这里把user和item两个塔的模型分别输出,部署线上,方便后续生成user向量和item向量。
(2)粗排如何产生候选集
DSSM拿到召回结果后,分别从user塔模型生成user embedding,item塔模型生成item embedding,然后两个embedding做点积,产出 T o p K TopK TopK候选集。

















 2326
2326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









