






研究背景
- 研究问题:这篇文章要解决的问题是检索增强生成(RAG)在生成过程中依赖于检索上下文的质量和准确性,尤其是当检索到的非参数知识与内部记忆的知识发生冲突时,导致知识冲突和生成文本质量下降。
- 研究难点:该问题的研究难点包括:大语言模型(LLMs)难以评估外部检索到的非参数知识的正确性,导致在生成过程中出现知识冲突;现有的预评估和后评估方法计算开销大,且会减少生成信息,影响最终性能。
- 相关工作:该问题的研究相关工作有:传统的RAG方法、预评估和后评估方法、以及基于人类反馈的强化学习(RLHF)方法如DPO。这些方法在处理知识冲突和提高生成质量方面存在局限性。
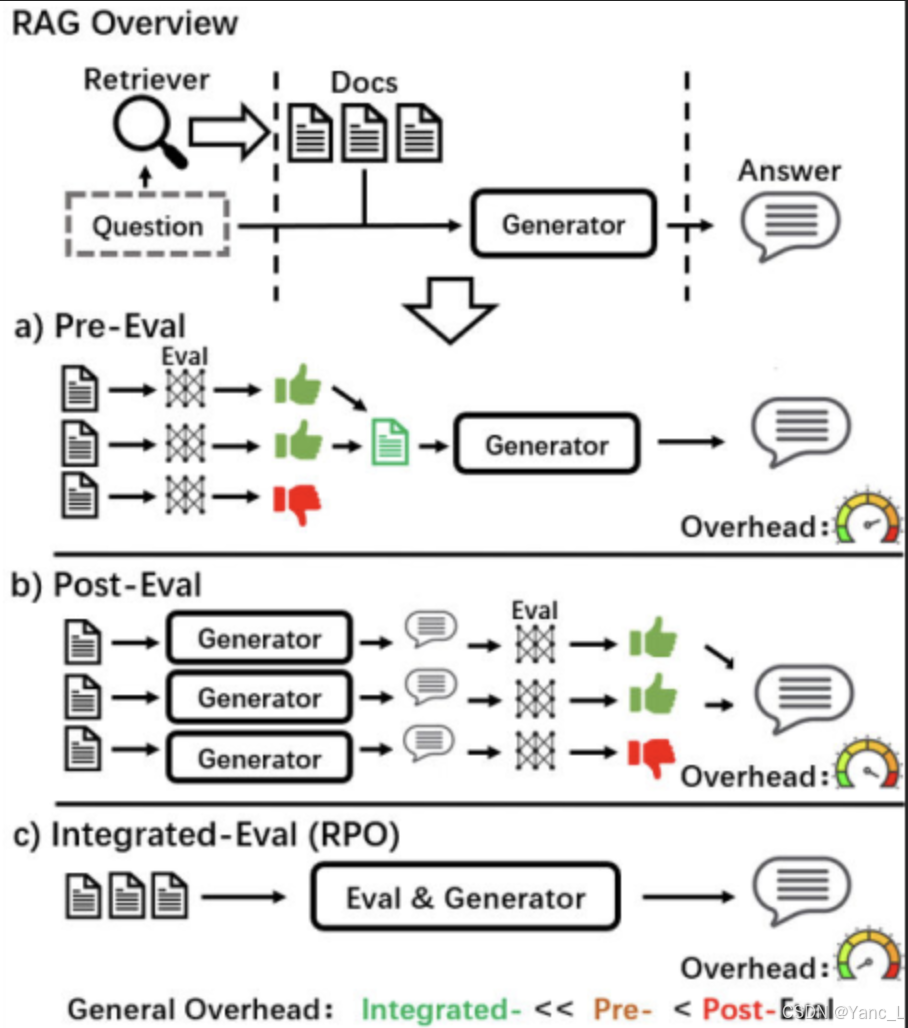
研究方法
这篇论文提出了检索偏好优化(RPO)算法,用于解决RAG中的知识冲突问题。具体来说,
- 理论分析:首先,作者进行了理论分析,指出了现有偏好优化算法在RAG场景中的局限性,并证明了这些算法的不足。
- 新的强化学习目标:作者提出了一个新的强化学习目标,将检索相关性表示形式纳入奖励模型,以自适应地奖励LLMs基于检索质量的表现。新的强化学习目标公式如下:
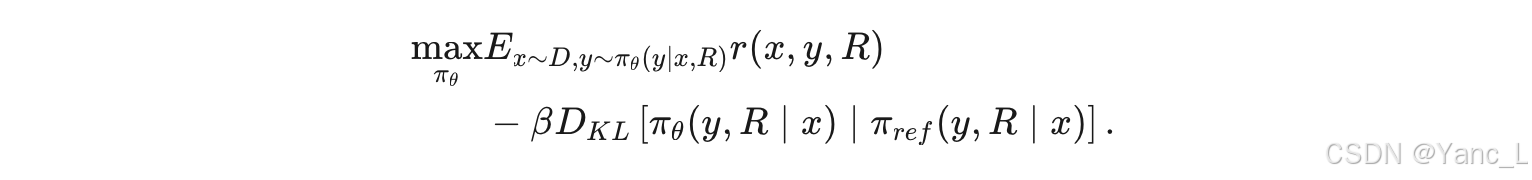
其中,r(x,y,R) 是奖励模型,β 是控制超参数,πθ 和 πref 分别是可训练和参考策略。
3. 奖励模型公式:基于新的强化学习目标,作者推导了RPO的奖励模型公式:
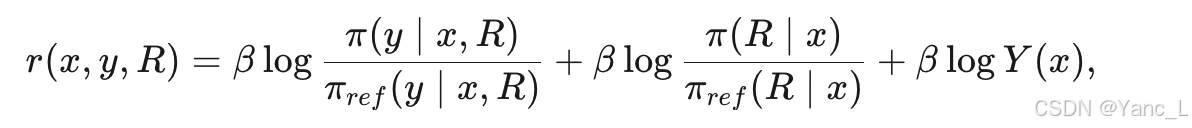
其中,Y(x) 是分区函数。
4. 长度归一化:为了缓解检索意识项的过度影响并克服LLMs的长度偏差,作者利用平均对数概率作为奖励的一部分,最终的RPO训练目标公式如下:
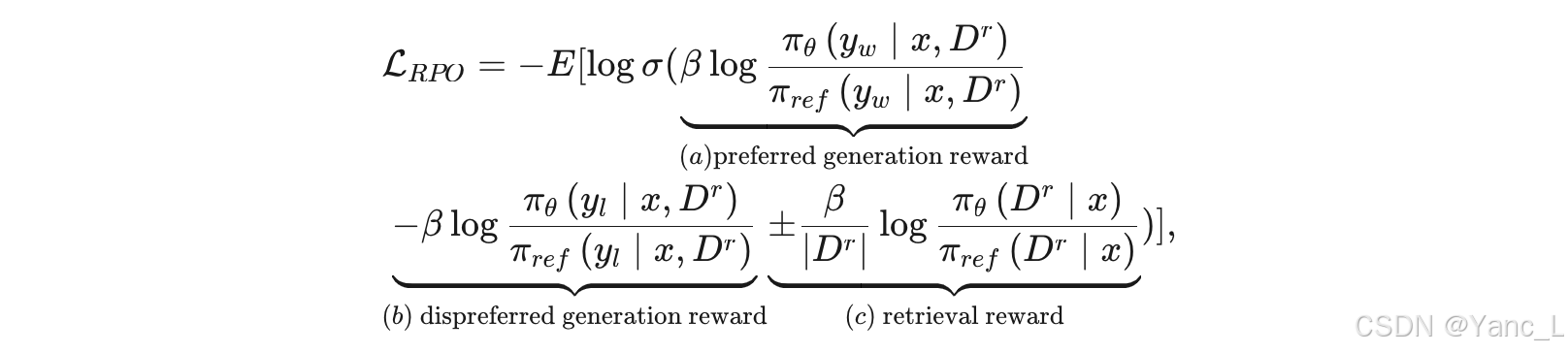
其中,第一项和第二项分别表示生成偏好和非偏好的奖励,第三项表示检索上下文的奖励。
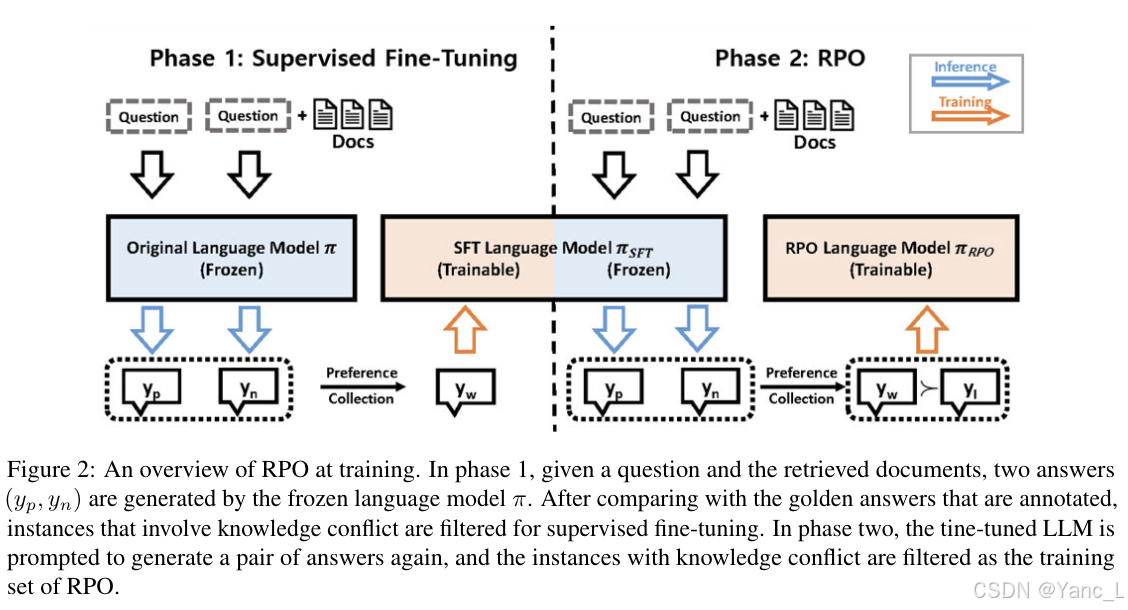
实验设计
- 数据收集:实验使用了四个数据集:PopQA、Natural Questions、TriviaQA和RGB。每个数据集包含问题和对应的维基百科页面,页面中包含一个或多个实际答案的短片段。
- 偏好对收集:通过分别指示模型生成有检索和无检索的答案对,构建偏好对。具体来说,从数据集中采样两个子集:D1 用于增强模型读取和理解检索上下文的能力,D2 用于缓解模型对检索知识的过度依赖。
- 监督微调:使用收集的偏好对进行监督微调,得到子集DSFT。
- 检索偏好优化:在微调后的策略πSFT上再次进行数据过滤,并使用RPO策略进行训练,最终得到优化策略πRPO
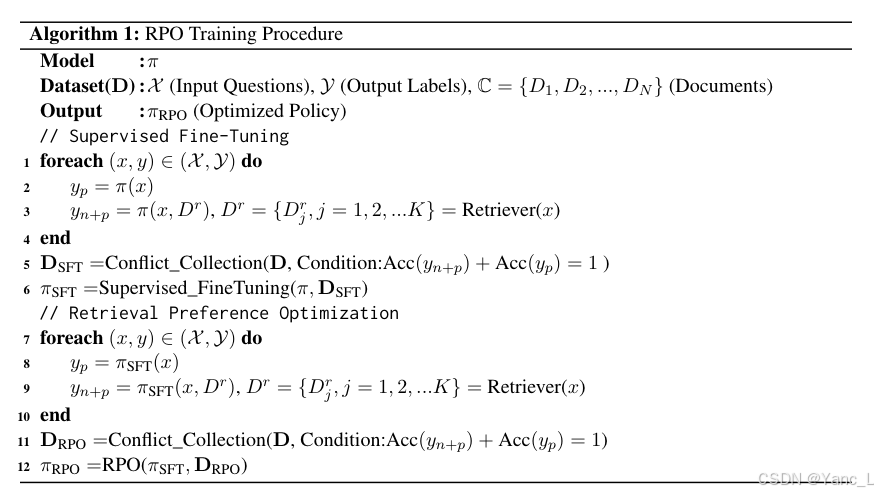
监督微调(SFT)阶段:
- 在论文中,SFT(Supervised Fine-Tuning)阶段用于初步训练模型。在这个阶段,模型被训练以更好地理解和利用检索到的上下文信息。这个阶段的目的是提高模型对检索质量的评估能力,并帮助模型在生成过程中做出更好的决策。
数据过滤:
- 在SFT阶段,数据集被过滤以选择涉及知识冲突的实例。这些实例用于增强模型对检索上下文的感知能力。
RPO训练阶段:
- 在SFT之后,模型会使用经过微调的策略来进一步优化。在RPO(Retrieval Preference Optimization)阶段,模型继续使用相同的过滤方法来收集数据,但这次是在微调后的策略下进行的。RPO的目标是通过强化学习来优化模型的策略,使其能够更好地处理知识冲突。
知识冲突的处理:
- 在RPO阶段,模型通过比较参数化和非参数化知识的生成结果来识别和处理知识冲突。通过这种方式,模型能够在生成过程中更有效地利用检索到的上下文信息。
结果与分析
-
总体评估结果:在四个数据集上的评估结果显示,RPO在准确率上显著优于现有的自适应RAG方法。例如,在PopQA数据集上,RPO比RAG提高了7.4%的准确率;在Natural Questions数据集上,RPO比RAG提高了10.6%的准确率。
-
计算效率:与现有的预评估和后评估方法相比,RPO在推理阶段的计算开销更低,提供了更实用的解决方案。
-
消融研究:通过消融研究验证了监督微调和偏好优化阶段对RPO性能的贡献。移除任一阶段都会导致性能下降,进一步说明了这两个阶段的重要性。
-
训练集过滤的影响:实验结果表明,没有数据过滤的监督微调模型性能显著下降,甚至低于未调优的原始模型,验证了假设。
-
知识选择性能:与之前的训练策略相比,RPO在评估知识和选择正确答案方面表现出色,特别是在涉及知识冲突的集群中,RPO显示出显著的改进。
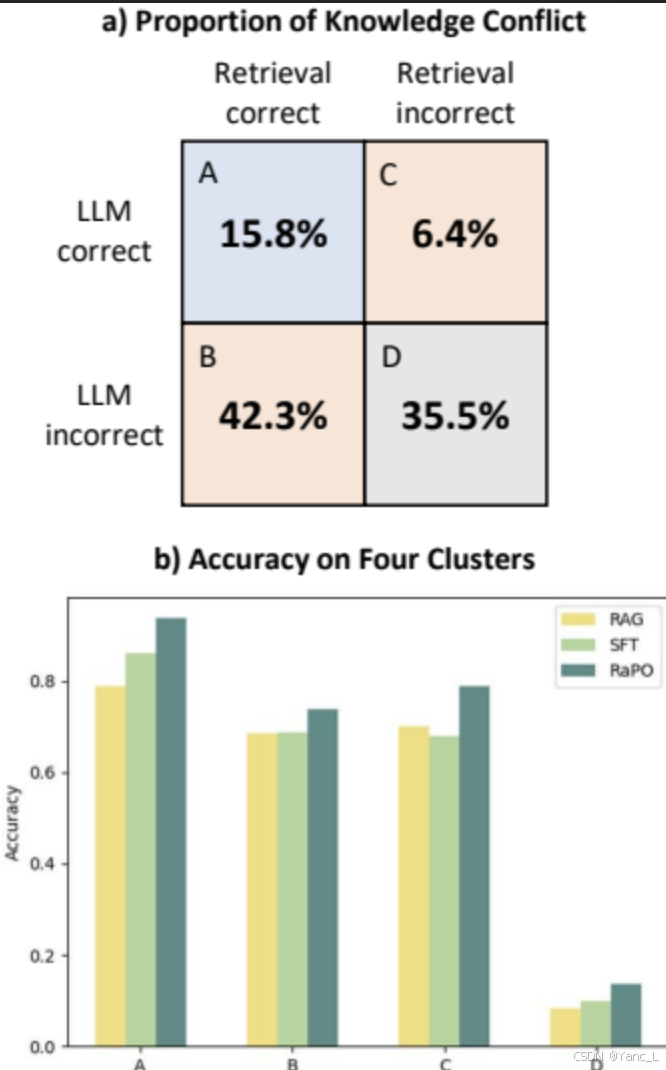
总体结论
这篇论文研究了RAG中参数知识和检索到的非参数知识之间的知识冲突问题。提出的RPO算法通过将LLMs的检索评估能力集成到生成过程中,显著提高了与先前自适应RAG方法相比的效率。广泛的实验表明了其进步性和在各种基准测试中的一致性能提升。未来的工作将继续探索更集成和隐式的检索评估方法,以进一步增强RAG的可靠性和鲁棒性。
优点与创新
- 提出了一种新的优化策略RPO:旨在鼓励LLMs在生成响应时同步评估检索到的上下文并选择性利用非参数知识,而无需显式处理。
- 数学证明:提供了现有偏好优化策略在RAG场景中不适用的数学证明,并提出了一种更高效的算法以及用于训练的数据收集方法,以解决这一限制。
- 实验验证:通过多个LLMs和基准测试验证了所提出的RPO算法的有效性,并展示了其在各种基准上的一致性能提升。
- 计算效率:RPO在推理阶段表现出显著的计算效率,不需要额外的API或LLM调用,展示了其在实际应用中解决知识冲突的潜力。
- 综合评估:RPO在生成过程中隐式地整合了检索评估,解决了先前方法需要额外步骤来评估检索质量的问题。
不足与反思
- 未来工作:未来的研究将继续探索更集成和隐式的检索评估方法,以进一步增强RAG的可靠性和鲁棒性。
关键问题及回答
问题1:RPO算法如何解决RAG中的知识冲突问题?
RPO算法通过将检索相关性表示形式纳入奖励模型,以自适应地奖励LLMs基于检索质量的表现。具体来说,RPO提出了一个新的强化学习目标,将检索相关性表示形式纳入奖励模型,以自适应地奖励LLMs基于检索质量的表现。新的强化学习目标公式如下:
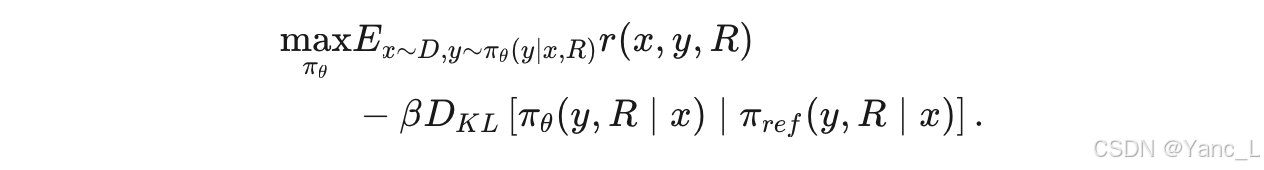
其中,r(x,y,R) 是奖励模型,β 是控制超参数,πθ 和 πref 分别是可训练和参考策略。通过这种方式,RPO能够在生成过程中同步评估检索质量,并根据检索质量自适应地奖励生成的答案,从而缓解知识冲突问题。
问题2:RPO算法在实验中是如何验证其有效性的?
RPO算法在四个数据集(PopQA、Natural Questions、TriviaQA和RGB)上进行了广泛的实验验证。实验结果表明,RPO在准确率上显著优于现有的自适应RAG方法。例如,在PopQA数据集上,RPO比RAG提高了7.4%的准确率;在Natural Questions数据集上,RPO比RAG提高了10.6%的准确率。此外,与现有的预评估和后评估方法相比,RPO在推理阶段的计算开销更低,提供了更实用的解决方案。消融研究也验证了监督微调和偏好优化阶段对RPO性能的贡献,进一步说明了这两个阶段的重要性。
问题3:RPO算法在处理知识冲突时的具体策略是什么?
RPO算法通过以下策略处理知识冲突:
- 偏好对收集:通过分别指示模型生成有检索和无检索的答案对,构建偏好对。具体来说,从数据集中采样两个子集:D1 用于增强模型读取和理解检索上下文的能力,D2 用于缓解模型对检索知识的过度依赖。
- 监督微调:使用收集的偏好对进行监督微调,得到子集DSFT。这一步骤帮助模型初步提高对检索质量的评估能力。
- 检索偏好优化:在微调后的策略πSFT上再次进行数据过滤,并使用RPO策略进行训练,最终得到优化策略πRPO。在生成过程中,RPO通过奖励模型同步评估检索质量,并根据检索质量自适应地奖励生成的答案,从而缓解知识冲突问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









