







 该博客详细介绍了如何使用Java进行腾讯新闻和新浪新闻的采集。首先,通过分析腾讯新闻的接口,按分类采集新闻列表,然后解析JSON数据获取新闻标题、作者、内容等信息。接着,通过查看新闻详情页的HTML源码,提取新闻内容和图片。新浪新闻的采集类似,通过分析HTML结构获取新闻详情。整个过程展示了网络爬虫在实际应用中的步骤。
该博客详细介绍了如何使用Java进行腾讯新闻和新浪新闻的采集。首先,通过分析腾讯新闻的接口,按分类采集新闻列表,然后解析JSON数据获取新闻标题、作者、内容等信息。接着,通过查看新闻详情页的HTML源码,提取新闻内容和图片。新浪新闻的采集类似,通过分析HTML结构获取新闻详情。整个过程展示了网络爬虫在实际应用中的步骤。
腾讯新闻、新浪新闻的详细采集过程
一、腾讯新闻采集
1.按分类采集腾讯新闻列表
分析过程:
- 采集的网页地址:https://xw.qq.com/?f=c_news

2.先进入一个分类(娱乐)来分析数据如何传输的
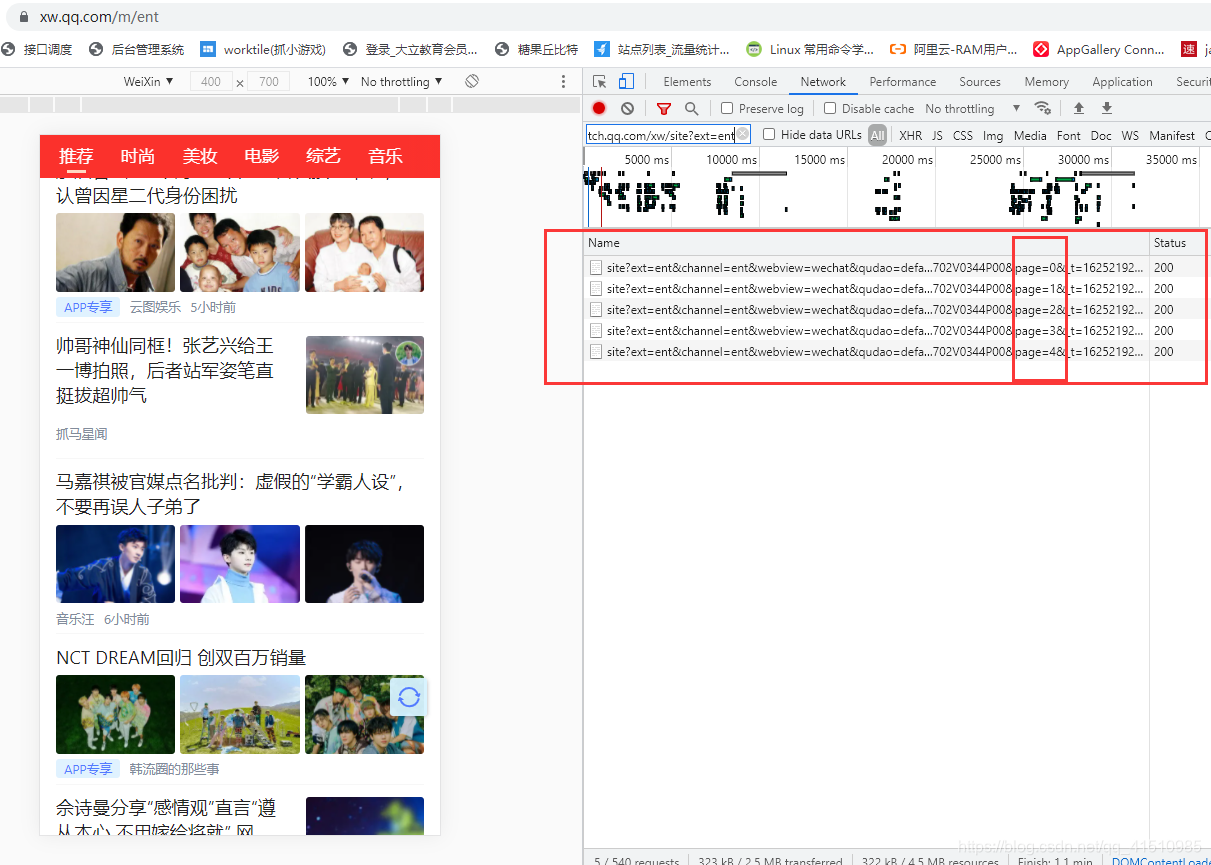
- 通过在娱乐分类页面里,向下滑动新闻加载更多数据,同时 利用chrome的Network可以发现有一个加载下一页的url接口: https://pacaio.match.qq.com/xw/site?ext=ent&channel=ent&webview=wechat&qudao=default&network=WIFI&num=20&page=1
- 通过分析,上面这个接口就是获取新闻列表的数据接口。下一步我们将要模拟请求 去爬取这个url接口数据。 而且我们发现只需要修改请求url里的page的参数就可以得到新闻第几页数据了。这就更方便我们去遍历获取新闻数据了。
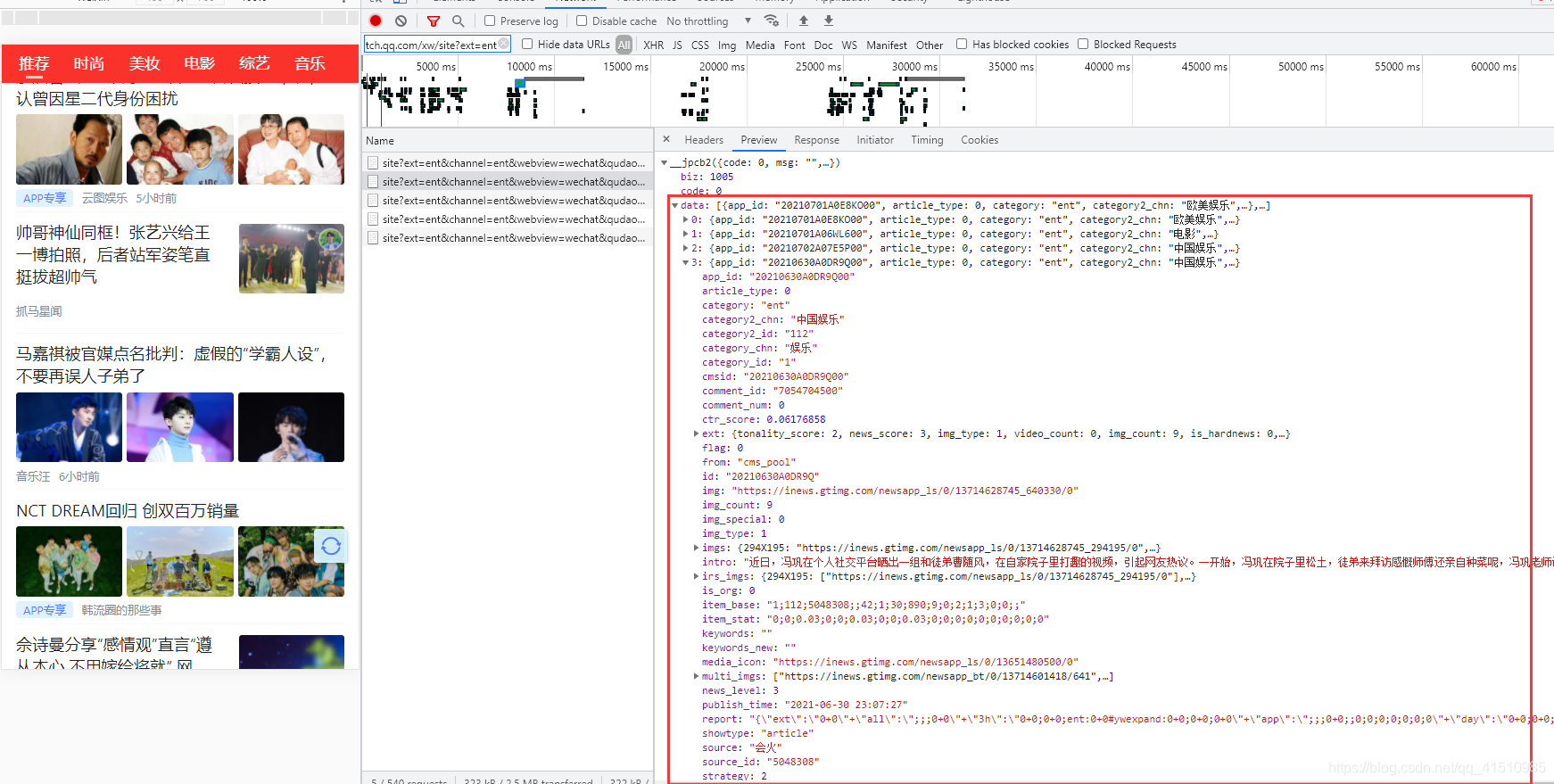
5.接下来,我们就可以写代码去请求接口并解析返回的json数据了
具体代码:
```java
public static void main(String[] args) {
//循环10次 采集10页
for (int i = 1; i < 10; i++) {
String url="https://pacaio.match.qq.com/xw/site?ext=ent&channel=ent&webview=wechat&qudao=default&network=WIFI&num=20&page="+i+"&_t=1625219273";
String s = get(url);
JSONObject jsonObject = JSONObject.parseObject(s);
JSONArray jsonArray = jsonObject.getJSONArray("data");
if (jsonArray.isEmpty())
continue;
for (Object o : jsonArray) {
JSONObject jsonObject1 = JSONObject.parseObject(String.valueOf(o));
//新闻id
String sourceid = jsonObject1.getString("app_id");
//作者
String source = jsonObject1.getString("source");
//标题
String topic = jsonObject1.getString("title");
//新闻详细内容的地址
String sourceurl = jsonObject1.getString("url");
//新闻的创建时间
String datetime = jsonObject1.getString("update_time");
//新闻的评论数
int like_count = jsonObject1.getInteger("comment_num");
//新闻的缩略图
JSONArray jsonArray1 = jsonObject1.getJSONArray("multi_imgs");
System.out.println(topic);
System.out.println(sourceurl);
}
}
}
//get请求的工具方法
private static String get(String url) {
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
URLConnection connection = realUrl.openConnection(); // 打开和URL之间的连接
// 设置通用的请求属性
connection.setRequestProperty("Accept-Charset", "UTF-8");
connection.setRequestProperty("content-type", "text/html; charset=utf-8");
connection.setRequestProperty("accept", "*/*");
//connection.setRequestProperty("Cookie", "tt_webid=20 B, session, HttpOnly www.toutiao.com/");
connection.setRequestProperty("Cookie", "utm_source=vivoliulanqi; webpSupport=%7B%22lossy%22%3Atrue%2C%22animation%22%3Atrue%2C%22alpha%22%3Atrue%7D; tt_webid=6977609332415530509; ttcid=1b2305f8baa44c8f929093024ae40dbf62; csrftoken=f8363c5a04097f7fd5d2ee36cf5bbd40; s_v_web_id=verify_kqbxnll7_QA9Z6n7G_LFul_4hTP_9jZf_zgZYUK3ySQOT; _ga=GA1.2.2038365076.1624601292; _gid=GA1.2.2124270427.1624601292; MONITOR_WEB_ID=518b84ad-98d5-4cb4-9e4e-4e3c3ec3ffe2; tt_webid=6977609332415530509; __ac_nonce=060d5aa4200b3672b2734; __ac_signature=_02B4Z6wo00f010CALQgAAIDA8HHBwRR4FntApCmAALEAeRZEDep7WW-RzEt50sUvtrkCpbRJMhboWeZNJ2s66iti2ZD-7sSiClTqpKs6b7ppQUp1vD8JHANxzSZ1srY4FF1y1iQitM1bQvYIf3; ttwid=1%7CTBE591UU7daDw3rsqkr6wXM1DqlOA3iyjUnPK-W6ThQ%7C1624615515%7Ccb0f077482096b50d19757a23f71240547d6b0c767bf9ab90fa583d022f47745; tt_scid=af-M9Xg-rmZAnPsCXhZu.2.DfKZe95AyPKJFzU0cL1KarDLfV3JYeIf.G28mIwhI57a0");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36");
connection.connect(); // 建立实际的连接
Map<String, List<String>> map = connection.getHeaderFields(); // 获取所有响应头字段
in = new BufferedReader(new InputStreamReader(
connection.getInputStream(),"utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
```
2.采集腾讯新闻内容
分析过程
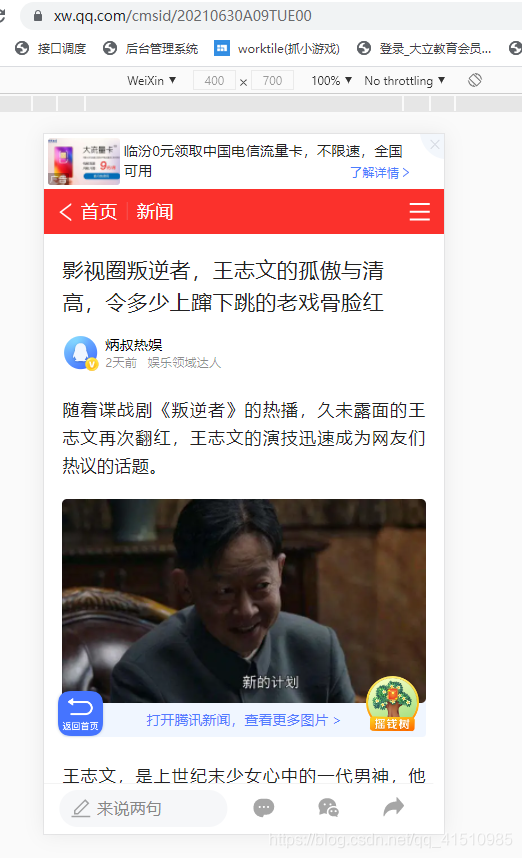
- 上面我们已经采集到了列表数据,拿到了 新闻内容地址:
- 打开新闻链接内容,分析如何获取内容。https://xw.qq.com/cmsid/20210630A09TUE00
3.打开新闻页面后,在chrome的浏览器 按住 Ctrl+U 查看内容的资源文件:
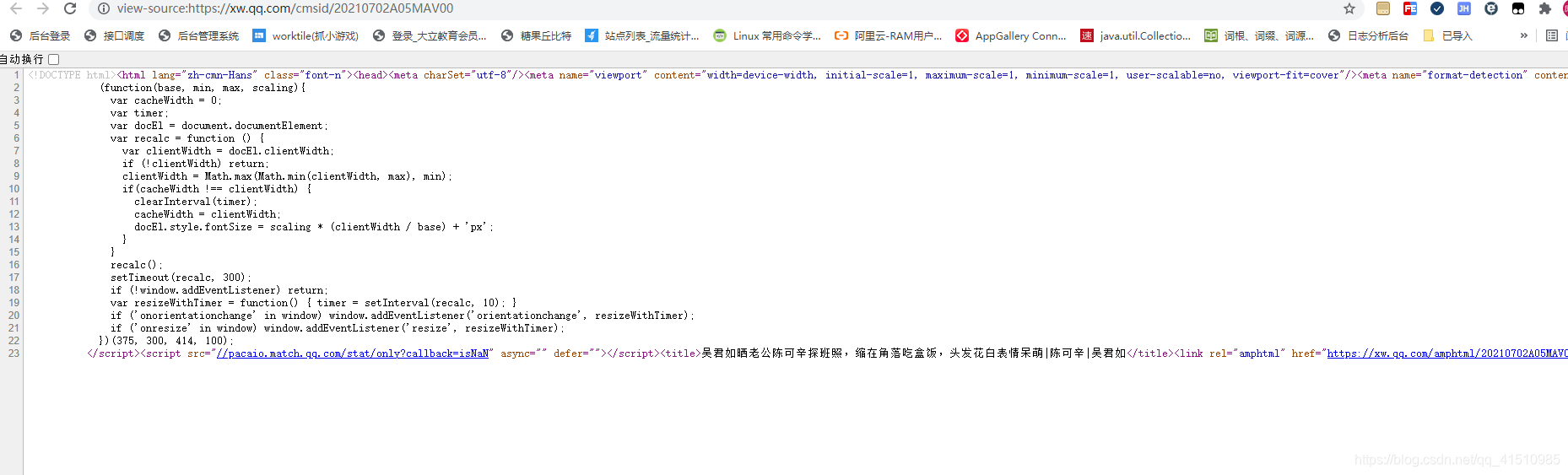
4.复制出资源文件里的html内容,美化成好看的格式后。分析如何拿到新闻 的文本和图片。
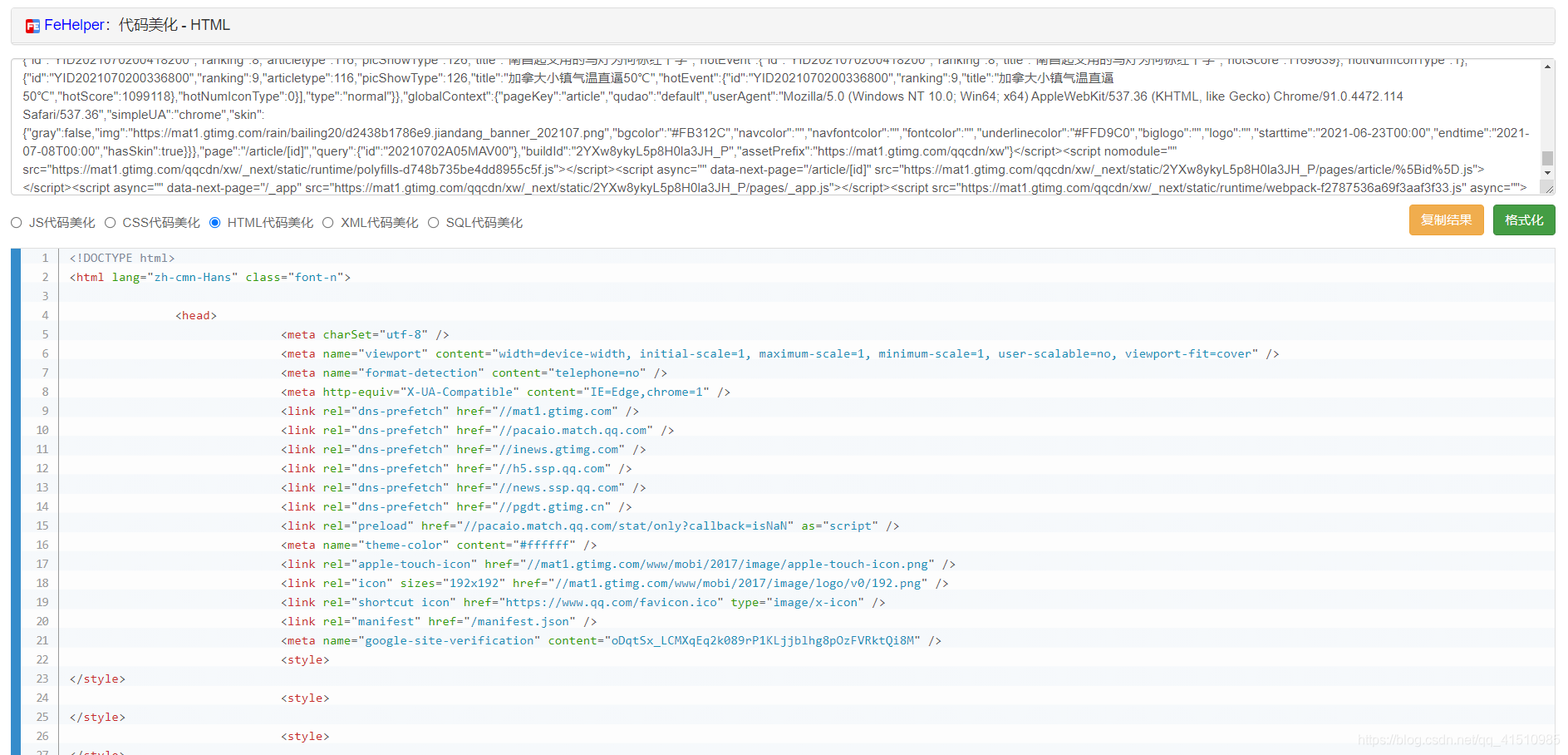
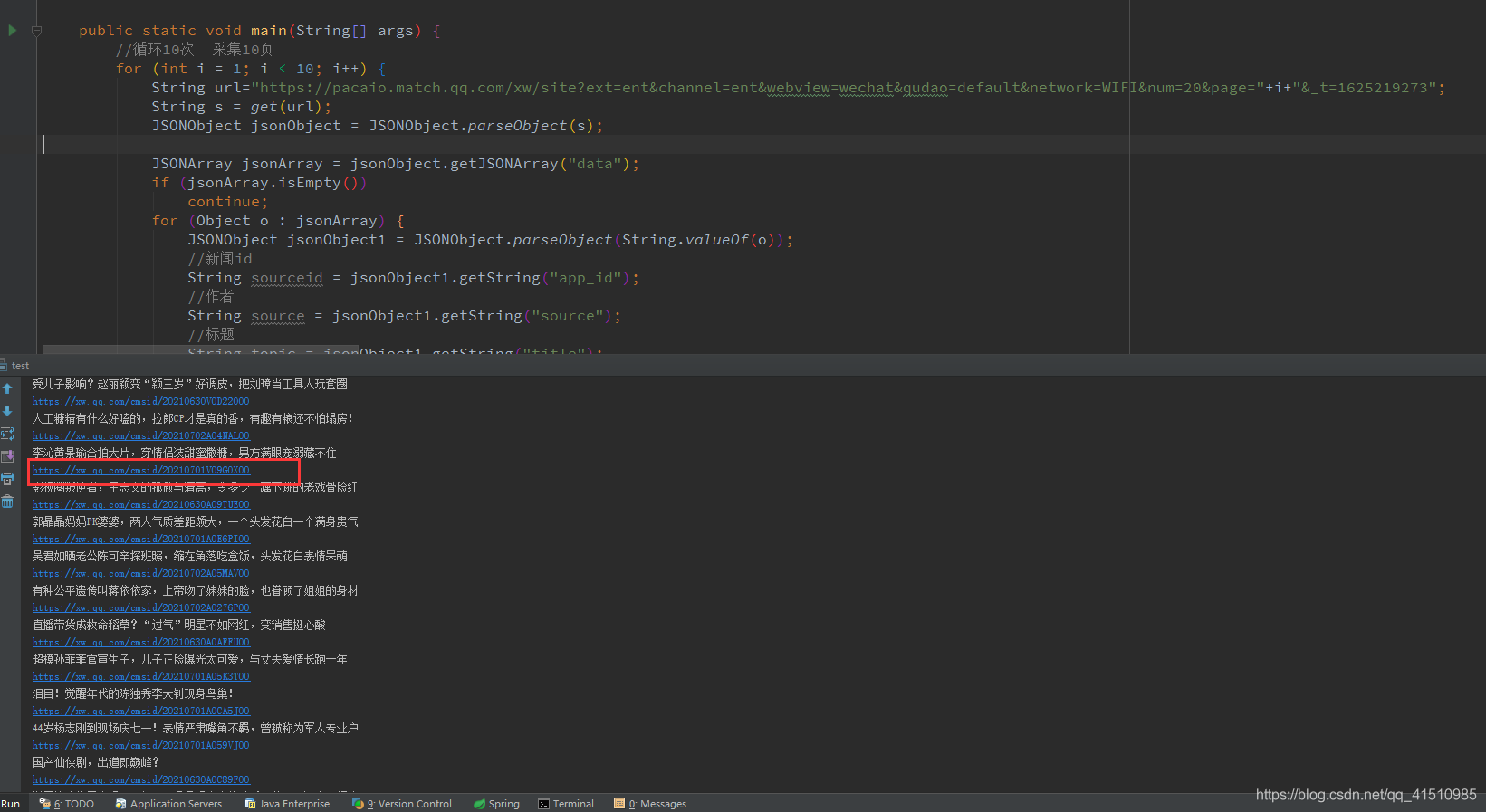
5.分析后, html里有一个js变量(json_content)里,有我们要用的数据。
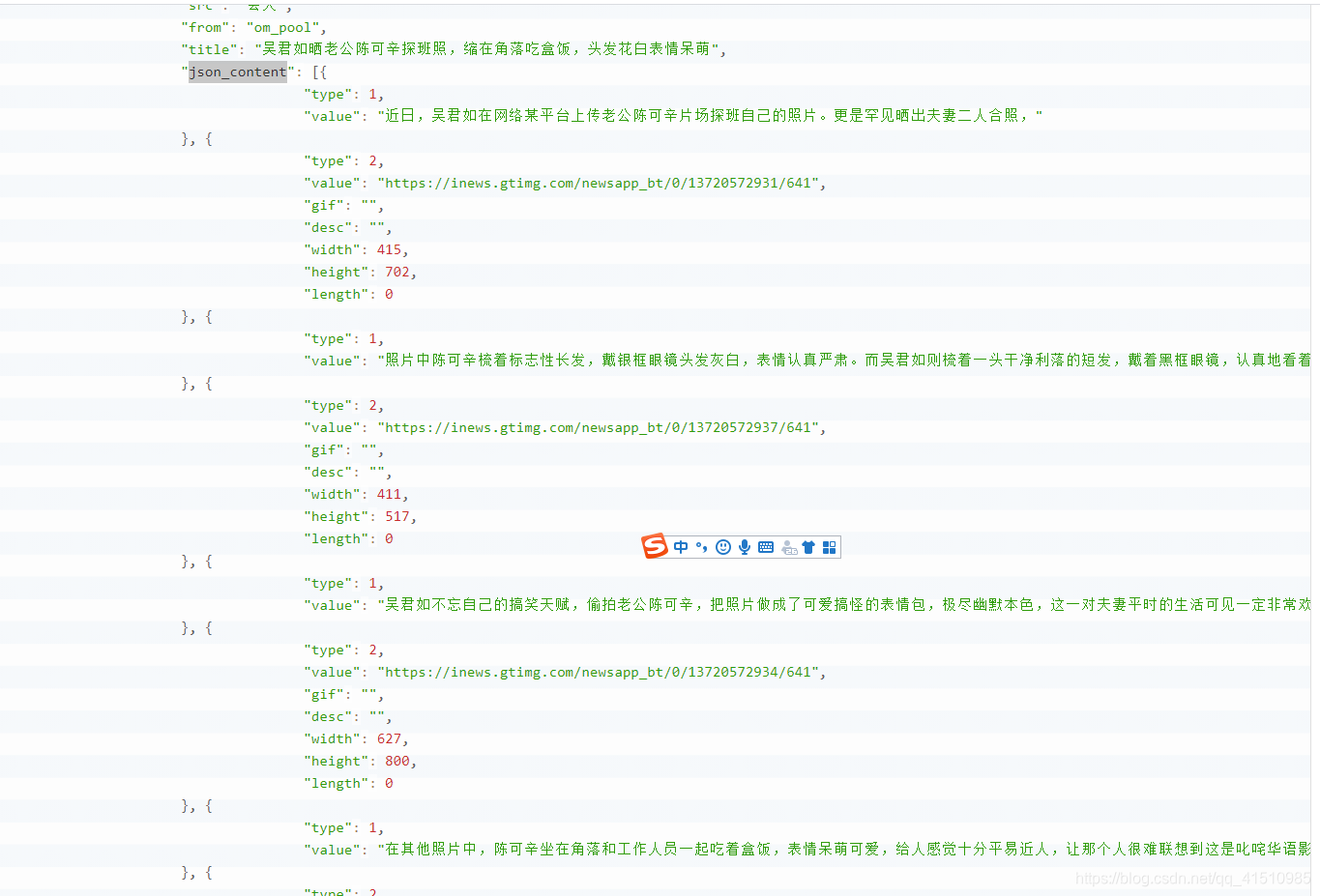
具体代码
//采集腾讯内容
public static void main(String[] args) {
String s = get("https://xw.qq.com/cmsid/20210630A09TUE00");
String[] split = s.split("json_content\":");
if (split.length<=1){
return;
}
String[] split1 = split[1].split("]");
JSONArray array = JSONObject.parseArray(split1[0] + "]");
StringBuilder contentBuffer = new StringBuilder(); //得到主体内容
for (Object o : array) {
JSONObject jsonObject = JSONObject.parseObject(String.valueOf(o));
String value = jsonObject.getString("value");
Integer type = jsonObject.getInteger("type");
if (type==1){
contentBuffer.append("<p>" + value + "</p>");
System.out.println("文本:"+value);
}else if(type==2){
System.out.println("图片:"+value);
contentBuffer.append("<img src=\"" + value + "\">");
}
}
//整理后的内容
System.out.println(contentBuffer);
}
//get请求的工具方法
private static String get(String url) {
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
URLConnection connection = realUrl.openConnection(); // 打开和URL之间的连接
// 设置通用的请求属性
connection.setRequestProperty("Accept-Charset", "UTF-8");
connection.setRequestProperty("content-type", "text/html; charset=utf-8");
connection.setRequestProperty("accept", "*/*");
//connection.setRequestProperty("Cookie", "tt_webid=20 B, session, HttpOnly www.toutiao.com/");
connection.setRequestProperty("Cookie", "utm_source=vivoliulanqi; webpSupport=%7B%22lossy%22%3Atrue%2C%22animation%22%3Atrue%2C%22alpha%22%3Atrue%7D; tt_webid=6977609332415530509; ttcid=1b2305f8baa44c8f929093024ae40dbf62; csrftoken=f8363c5a04097f7fd5d2ee36cf5bbd40; s_v_web_id=verify_kqbxnll7_QA9Z6n7G_LFul_4hTP_9jZf_zgZYUK3ySQOT; _ga=GA1.2.2038365076.1624601292; _gid=GA1.2.2124270427.1624601292; MONITOR_WEB_ID=518b84ad-98d5-4cb4-9e4e-4e3c3ec3ffe2; tt_webid=6977609332415530509; __ac_nonce=060d5aa4200b3672b2734; __ac_signature=_02B4Z6wo00f010CALQgAAIDA8HHBwRR4FntApCmAALEAeRZEDep7WW-RzEt50sUvtrkCpbRJMhboWeZNJ2s66iti2ZD-7sSiClTqpKs6b7ppQUp1vD8JHANxzSZ1srY4FF1y1iQitM1bQvYIf3; ttwid=1%7CTBE591UU7daDw3rsqkr6wXM1DqlOA3iyjUnPK-W6ThQ%7C1624615515%7Ccb0f077482096b50d19757a23f71240547d6b0c767bf9ab90fa583d022f47745; tt_scid=af-M9Xg-rmZAnPsCXhZu.2.DfKZe95AyPKJFzU0cL1KarDLfV3JYeIf.G28mIwhI57a0");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36");
connection.connect(); // 建立实际的连接
Map<String, List<String>> map = connection.getHeaderFields(); // 获取所有响应头字段
in = new BufferedReader(new InputStreamReader(
connection.getInputStream(),"utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
执行后:
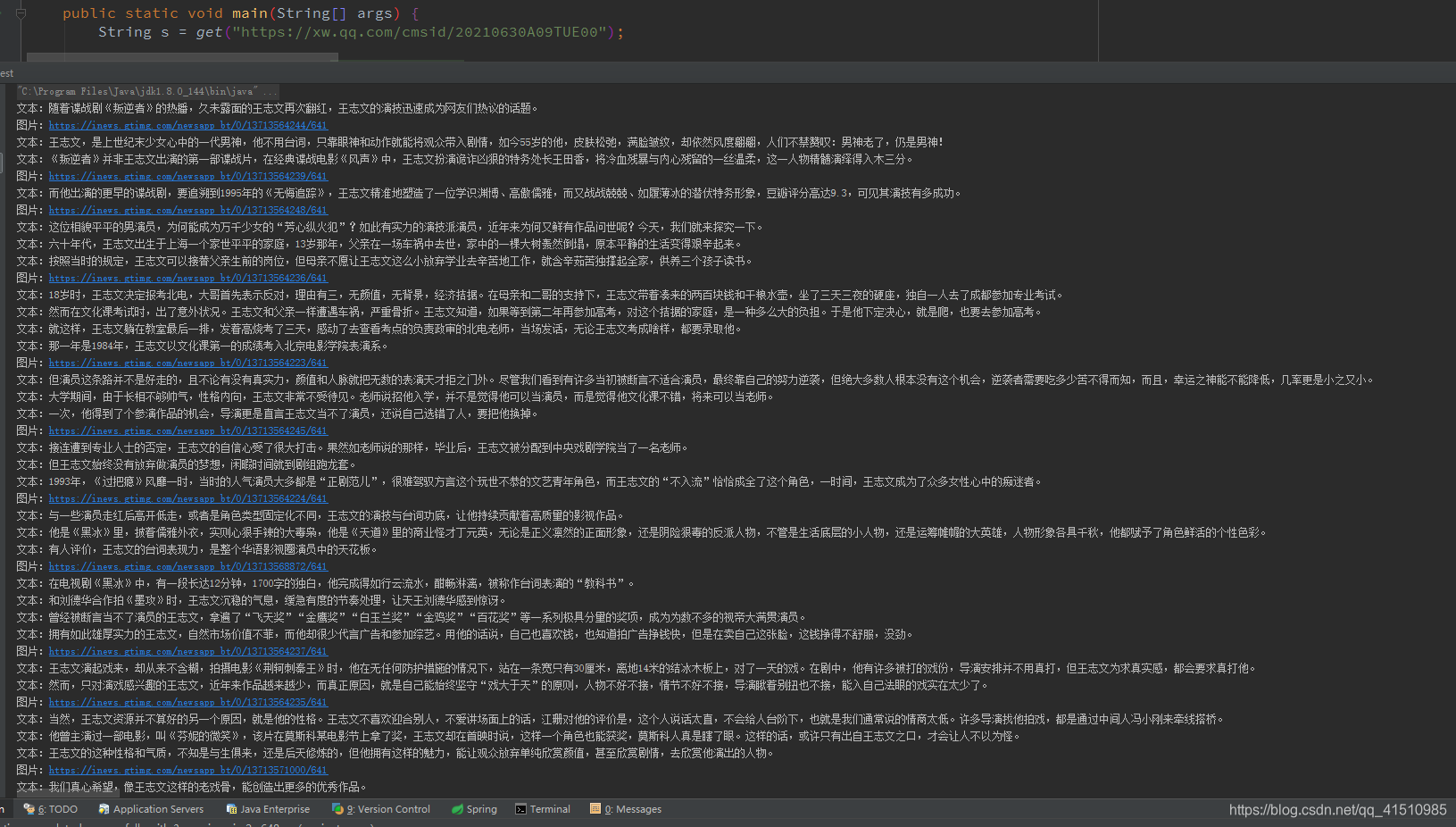

















 7381
7381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









