






有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样是确定的步骤,更多是工程上的经验和权衡。因此没有统一的方法。这里只是对一些常用的方法做一个总结。
特征工程包含了 Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和 Feature construction(特征构造)等子问题。
Jupyter Notebook 代码连接:feature_engineering_demo_p4_feature_selection
导入必要的包
import numpy as np
import pandas as pd
import re
import sys
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_X_y, check_is_fitted
from sklearn.preprocessing import FunctionTransformer
from sklearn.compose import ColumnTransformer, make_column_transformer, make_column_selector
from sklearn.pipeline import FeatureUnion, make_union, Pipeline, make_pipeline
from sklearn.feature_selection import SelectKBest, SelectPercentile
from sklearn.feature_selection import SelectFpr, SelectFdr, SelectFwe
from sklearn.model_selection import cross_val_score
import lightgbm as lgb
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import gc
# Setting configuration.
warnings.filterwarnings('ignore')
sns.set_style('whitegrid')
SEED = 42
定义一个计时器
def timer(func):
import time
import functools
def strfdelta(tdelta, fmt):
hours, remainder = divmod(tdelta, 3600)
minutes, seconds = divmod(remainder, 60)
return fmt.format(hours, minutes, seconds)
@functools.wraps(func)
def wrapper(*args, **kwargs):
click = time.time()
print("Starting time\t", time.strftime("%H:%M:%S", time.localtime()))
result = func(*args, **kwargs)
delta = strfdelta(time.time() - click, "{:.0f} hours {:.0f} minutes {:.0f} seconds")
print(f"{func.__name__} cost {delta}")
return result
return wrapper
特征选择
前言
现在我们已经有大量的特征可使用,有的特征携带的信息丰富,有的特征携带的信息有重叠,有的特征则属于无关特征,尽管在拟合一个模型之前很难说哪些特征是重要的,但如果所有特征不经筛选地全部作为训练特征,经常会出现维度灾难问题,甚至会降低模型的泛化性能(因为较无益的特征会淹没那些更重要的特征)。因此,我们需要进行特征筛选,排除无效/冗余的特征,把有用的特征挑选出来作为模型的训练数据。
特征选择方法有很多,一般分为三类:
- 过滤法(Filter)比较简单,它按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或者待选择阈值的个数,选择合适特征。
- 包装法(Wrapper)根据目标函数,通常是预测效果评分,每次选择部分特征,或者排除部分特征。
- 嵌入法(Embedded)则稍微复杂一点,它先使用选择的算法进行训练,得到各个特征的权重,根据权重从大到小来选择特征。
| sklearn.feature_selection | 所属方法 | 说明 |
|---|---|---|
| VarianceThreshold | Filter | 方差选择法 |
| SelectKBest | Filter | 常用相关系数、卡方检验、互信息作为得分计算的方法 |
| SelectPercentile | Filter | 根据最高分数的百分位数选择特征 |
| SelectFpr, SelectFdr, SelectFwe | Filter | 根据假设检验的p-value选择特征 |
| RFECV | Wrapper | 在交叉验证中执行递归式特征消除 |
| SequentialFeatureSelector | Wrapper | 前向/向后搜索 |
| SelectFromModel | Embedded | 训练基模型,选择权值系数较高的特征 |
如何通俗地理解Family-wise error rate(FWER)和False discovery rate(FDR)
df = pd.read_csv('../datasets/Home-Credit-Default-Risk/created_data.csv', index_col='SK_ID_CURR')
定义帮助节省内存的函数
@timer
def convert_dtypes(df, verbose=True):
original_memory = df.memory_usage().sum()
df = df.apply(pd.to_numeric, errors='ignore')
# Convert booleans to integers
boolean_features = df.select_dtypes(bool).columns.tolist()
df[boolean_features] = df[boolean_features].astype(np.int32)
# Convert objects to category
object_features = df.select_dtypes(object).columns.tolist()
df[object_features] = df[object_features].astype('category')
# Float64 to float32
float_features = df.select_dtypes(float).columns.tolist()
df[float_features] = df[float_features].astype(np.float32)
# Int64 to int32
int_features = df.select_dtypes(int).columns.tolist()
df[int_features] = df[int_features].astype(np.int32)
new_memory = df.memory_usage().sum()
if verbose:
print(f'Original Memory Usage: {round(original_memory / 1e9, 2)} gb.')
print(f'New Memory Usage: {round(new_memory / 1e9, 2)} gb.')
return df
df = convert_dtypes(df)
X = df.drop('TARGET', axis=1)
y = df['TARGET']
Starting time 20:30:38
Original Memory Usage: 5.34 gb.
New Memory Usage: 2.63 gb.
convert_dtypes cost 0 hours 2 minutes 1 seconds
X.dtypes.value_counts()
float32 2104
int32 16
category 3
category 3
category 3
category 3
category 3
category 3
category 3
category 2
category 2
category 2
category 2
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
category 1
Name: count, dtype: int64
del df
gc.collect()
0
# Encode categorical features
categorical_features = X.select_dtypes(exclude='number').columns.tolist()
X[categorical_features] = X[categorical_features].apply(lambda x: x.cat.codes)
X.dtypes.value_counts()
float32 2104
int8 47
int32 16
Name: count, dtype: int64
定义数据集评估函数
@timer
def score_dataset(X, y, categorical_features, nfold=5):
# Create Dataset object for lightgbm
dtrain = lgb.Dataset(X, label=y)
# Use a dictionary to set Parameters.
params = dict(
objective='binary',
is_unbalance=True,
metric='auc',
n_estimators=500,
verbose=0
)
# Training with 5-fold CV:
print('Starting training...')
eval_results = lgb.cv(
params,
dtrain,
nfold=nfold,
categorical_feature = categorical_features,
callbacks=[lgb.early_stopping(50), lgb.log_evaluation(50)],
return_cvbooster=True
)
boosters = eval_results['cvbooster'].boosters
# Initialize an empty dataframe to hold feature importances
feature_importances = pd.DataFrame(index=X.columns)
for i in range(nfold):
# Record the feature importances
feature_importances[f'cv_{i}'] = boosters[i].feature_importance()
feature_importances['score'] = feature_importances.mean(axis=1)
# Sort features according to importance
feature_importances = feature_importances.sort_values('score', ascending=False)
return eval_results, feature_importances
eval_results, feature_importances = score_dataset(X, y, categorical_features)
Starting time 20:32:42
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.778018 + 0.00319843
[100] cv_agg's valid auc: 0.783267 + 0.00307558
[150] cv_agg's valid auc: 0.783211 + 0.00299384
Early stopping, best iteration is:
[115] cv_agg's valid auc: 0.783392 + 0.00298777
score_dataset cost 0 hours 6 minutes 9 seconds
单变量特征选择
Relief(Relevant Features)是著名的过滤式特征选择方法。该方法假设特征子集的重要性是由子集中的每个特征所对应的相关统计量分量之和所决定的。所以只需要选择前k个大的相关统计量对应的特征,或者大于某个阈值的相关统计量对应的特征即可。
常用的过滤指标:
| 函数 | python模块 | 说明 |
|---|---|---|
| VarianceThreshold | sklearn.feature_selection | 方差过滤 |
| r_regression | sklearn.feature_selection | 回归任务的目标/特征之间的Pearson相关系数。 |
| f_regression | sklearn.feature_selection | 回归任务的目标/特征之间的t检验F值。 |
| mutual_info_regression | sklearn.feature_selection | 估计连续目标变量的互信息。 |
| chi2 | sklearn.feature_selection | 分类任务的非负特征的卡方值和P值。 |
| f_classif | sklearn.feature_selection | 分类任务的目标/特征之间的方差分析F值。 |
| mutual_info_classif | sklearn.feature_selection | 估计离散目标变量的互信息。 |
| df.corr, df.corrwith | pandas | Pearson, Kendall, Spearman相关系数 |
| calc_gini_scores | self-define | 基尼系数 |
| variance_inflation_factor | statsmodels.stats.outliers_influence | VIF值 |
| df.isna().mean() | pandas | 缺失率 |
| DropCorrelatedFeatures | feature_engine.selection | 删除共线特征,基于相关系数 |
| SelectByInformationValue | feature_engine.selection | IV值筛选 |
| DropHighPSIFeatures | feature_engine.selection | 删除不稳定特征 |
互信息
互信息是从信息熵的角度分析各个特征和目标之间的关系(包括线性和非线性关系)。
from sklearn.feature_selection import SelectKBest, mutual_info_classif
@timer
def calc_mi_scores(X, y):
colnames = X.select_dtypes(exclude='number').columns
X[colnames] = X[colnames].astype("category").apply(lambda x:x.cat.codes)
discrete = [X[col].nunique()<=50 for col in X]
mi_scores = mutual_info_classif(X, y, discrete_features=discrete, random_state=SEED)
mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns)
mi_scores = mi_scores.sort_values(ascending=False)
return mi_scores
class DropUninformative(BaseEstimator, TransformerMixin):
def __init__(self, threshold=0.0):
self.threshold = threshold
def fit(self, X, y):
mi_scores = calc_mi_scores(X, y)
self.variables = mi_scores[mi_scores > self.threshold].index.tolist()
return self
def transform(self, X, y=None):
return X[self.variables]
def get_feature_names_out(self, input_features=None):
return self.variables
init_n = len(X.columns)
selected_features = DropUninformative(threshold=0.0) \
.fit(X, y) \
.get_feature_names_out()
print('The number of selected features:', len(selected_features))
print(f'Dropped {init_n - len(selected_features)} uninformative features.')
Starting time 20:38:51
calc_mi_scores cost 0 hours 17 minutes 49 seconds
The number of selected features: 2050
Dropped 117 uninformative features.
selected_categorical_features = [col for col in categorical_features if col in selected_features]
eval_results, feature_importances = score_dataset(X[selected_features], y, selected_categorical_features)
Starting time 20:56:46
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.778311 + 0.00276223
[100] cv_agg's valid auc: 0.783085 + 0.00266899
[150] cv_agg's valid auc: 0.783015 + 0.00280856
Early stopping, best iteration is:
[122] cv_agg's valid auc: 0.783271 + 0.00267406
score_dataset cost 0 hours 6 minutes 7 seconds
相关系数
皮尔森相关系数是一种最简单的方法,能帮助理解两个连续变量之间的线性相关性。
import time
def progress(percent=0, width=50, desc="Processing"):
import math
tags = math.ceil(width * percent) * "#"
print(f"\r{desc}: [{tags:-<{width}}]{percent:.1%}", end="", flush=True)
@timer
def drop_correlated_features(X, y, threshold=0.9):
to_keep = []
to_drop = []
categorical = X.select_dtypes(exclude='number').columns.tolist()
for i, col in enumerate(X.columns):
if col in categorical:
continue
# The correlations
corr = X[to_keep].corrwith(X[col]).abs()
# Select columns with correlations above threshold
if any(corr > threshold):
to_drop.append(col)
else:
to_keep.append(col)
progress((i+1) / len(X.columns))
print("\nThe number of correlated features:", len(to_drop))
return to_keep
上述函数会倾向于删除最后出现的相关特征,为了尽可能保留原始特征,我们调换下特征顺序:
original_df = pd.read_csv('../datasets/Home-Credit-Default-Risk/prepared_data.csv', nrows=5)
original_features = [f for f in X.columns if f in original_df.columns]
derived_features = [f for f in X.columns if f not in original_df.columns]
selected_features = [col for col in original_features + derived_features if col in selected_features]
# Drops features that are correlated
# init_n = len(selected_features)
selected_features = drop_correlated_features(X[selected_features], y, threshold=0.9)
print('The number of selected features:', len(selected_features))
print(f'Dropped {init_n - len(selected_features)} correlated features.')
Starting time 21:03:05
Processing: [##################################################]100.0%
The number of correlated features: 1110
drop_correlated_features cost 0 hours 33 minutes 5 seconds
The number of selected features: 940
Dropped 1227 correlated features.
工作中,我们常调用feature_engine包实现:
# Drops features that are correlated
# from feature_engine.selection import DropCorrelatedFeatures
# init_n = len(selected_features)
# selected_features = DropCorrelatedFeatures(threshold=0.9) \
# .fit(X[selected_features], y) \
# .get_feature_names_out()
# print('The number of selected features:', len(selected_features))
# print(f'Dropped {init_n - len(selected_features)} features.')
selected_categorical_features = [col for col in categorical_features if col in selected_features]
eval_results, feature_importances = score_dataset(X[selected_features], y, selected_categorical_features)
Starting time 21:36:12
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.776068 + 0.00333724
[100] cv_agg's valid auc: 0.781097 + 0.00296053
[150] cv_agg's valid auc: 0.781236 + 0.00298245
Early stopping, best iteration is:
[136] cv_agg's valid auc: 0.781375 + 0.00302538
score_dataset cost 0 hours 2 minutes 23 seconds
方差分析
方差分析主要用于分类问题中连续特征的相关性。
from sklearn.feature_selection import f_classif
numeric_features = [col for col in X.columns if col not in categorical_features]
f_statistic, p_values = f_classif(X[numeric_features], y)
anova = pd.DataFrame({
"f_statistic": f_statistic,
"p_values": p_values
}, index=numeric_features
)
print(f"The number of irrelevant features for classification:", anova['p_values'].ge(0.05).sum())
The number of irrelevant features for classification: 274
卡方检验
卡方检验是一种用于衡量两个分类变量之间相关性的统计方法。
from sklearn.feature_selection import chi2
chi2_stats, p_values = chi2(
X[categorical_features],
y
)
chi2_test = pd.DataFrame({
"chi2_stats": chi2_stats,
"p_values": p_values
}, index=categorical_features
)
print("The number of irrelevant features for classification:", chi2_test['p_values'].ge(0.05).sum())
The number of irrelevant features for classification: 9
如果针对分类问题,f_classif 和 chi2两个评分函数搭配使用,就能够完成一次完整的特征筛选,其中f_classif用于筛选连续特征,chi2用于筛选离散特征。
feature_selection = make_column_transformer(
(SelectFdr(score_func=f_classif, alpha=0.05), numeric_features),
(SelectFdr(score_func=chi2, alpha=0.05), categorical_features),
verbose=True,
verbose_feature_names_out=False
)
selected_features_by_fdr = feature_selection.fit(X, y).get_feature_names_out()
print("The number of selected features:", len(selected_features_by_fdr))
print("Dropped {} features.".format(X.shape[1] - len(selected_features_by_fdr)))
[ColumnTransformer] ... (1 of 2) Processing selectfdr-1, total= 2.7min
[ColumnTransformer] ... (2 of 2) Processing selectfdr-2, total= 0.1s
The number of selected features: 1838
Dropped 329 features.
selected_categorical_features_by_fdr = [col for col in categorical_features if col in selected_features_by_fdr]
eval_results, feature_importances = score_dataset(X[selected_features_by_fdr], y, selected_categorical_features_by_fdr)
Starting time 21:44:08
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.777829 + 0.00296151
[100] cv_agg's valid auc: 0.782637 + 0.00263458
[150] cv_agg's valid auc: 0.782612 + 0.0023263
Early stopping, best iteration is:
[129] cv_agg's valid auc: 0.782834 + 0.00242003
score_dataset cost 0 hours 5 minutes 41 seconds
IV值
IV(Information Value)用来评价离散特征对二分类变量的预测能力。一般认为IV小于0.02的特征为无用特征。
def calc_iv_scores(X, y, bins=10):
X = pd.DataFrame(X)
y = pd.Series(y)
assert y.nunique() == 2, "y must be binary"
iv_scores = pd.Series()
# Find discrete features
colnames = X.select_dtypes(exclude='number').columns
X[colnames] = X[colnames].astype("category").apply(lambda x:x.cat.codes)
discrete = [X[col].nunique()<=50 for col in X]
# Compute information value
for colname in X.columns:
if colname in discrete:
var = X[colname]
else:
var = pd.qcut(X[colname], bins, duplicates="drop")
grouped = y.groupby(var).agg([('Positive','sum'),('All','count')])
grouped['Negative'] = grouped['All']-grouped['Positive']
grouped['Positive rate'] = grouped['Positive']/grouped['Positive'].sum()
grouped['Negative rate'] = grouped['Negative']/grouped['Negative'].sum()
grouped['woe'] = np.log(grouped['Positive rate']/grouped['Negative rate'])
grouped['iv'] = (grouped['Positive rate']-grouped['Negative rate'])*grouped['woe']
grouped.name = colname
iv_scores[colname] = grouped['iv'].sum()
return iv_scores.sort_values(ascending=False)
iv_scores = calc_iv_scores(X, y)
print(f"There are {iv_scores.le(0.02).sum()} features with iv <=0.02.")
There are 987 features with iv <=0.02.
基尼系数
基尼系数用来衡量分类问题中特征对目标变量的影响程度。它的取值范围在0到1之间,值越大表示特征对目标变量的影响越大。常见的基尼系数阈值为0.02,如果基尼系数小于此阈值,则被认为是不重要的特征。
def calc_gini_scores(X, y, bins=10):
X = pd.DataFrame(X)
y = pd.Series(y)
gini_scores = pd.Series()
# Find discrete features
colnames = X.select_dtypes(exclude='number').columns
X[colnames] = X[colnames].astype("category").apply(lambda x:x.cat.codes)
discrete = [X[col].nunique()<=50 for col in X]
# Compute gini score
for colname in X.columns:
if colname in discrete:
var = X[colname]
else:
var = pd.qcut(X[colname], bins, duplicates="drop")
p = y.groupby(var).mean()
gini = 1 - p.pow(2).sum()
gini_scores[colname] = gini
return gini_scores.sort_values(ascending=False)
gini_scores = calc_gini_scores(X, y)
print(f"There are {gini_scores.le(0.02).sum()} features with iv <=0.02.")
There are 0 features with iv <=0.02.
VIF值
VIF用于衡量特征之间的共线性程度。通常,VIF小于5被认为不存在多重共线性问题,VIF大于10则存在明显的多重共线性问题。
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
@timer
def calc_vif_scores(X, y=None):
numeric_X = X.select_dtypes("number")
numeric_X = add_constant(numeric_X)
# collinear features
vif = pd.Series()
for i, col in enumerate(numeric_X.columns):
vif[col] = variance_inflation_factor(numeric_X.values, i)
progress((i+1)/numeric_X.shape[1])
return vif.sort_values(ascending=False)
# vif_scores = calc_vif_scores(X)
# print(f"There are {vif_scores.gt(10).sum()} collinear features (VIF above 10)")
Pipeline实现
我们准备采取以下两步:
- 首先,删除互信息为0的特征。
- 然后,对于相关性大于0.9的每对特征,删除其中一个特征。
from feature_engine.selection import DropCorrelatedFeatures
feature_selection = make_pipeline(
DropUninformative(threshold=0.0),
DropCorrelatedFeatures(threshold=0.9),
verbose=True
)
# init_n = len(X.columns)
# selected_features = feature_selection.fit(X, y).get_feature_names_out()
# print('The number of selected features:', len(selected_features))
# print(f'Dropped {init_n - len(selected_features)} features.')
在2167个总特征中只保留了914个,表明我们创建的许多特征是多余的。
递归消除特征
最常用的包装法是递归消除特征法(recursive feature elimination)。递归消除特征法使用一个机器学习模型来进行多轮训练,每轮训练后,消除最不重要的特征,再基于新的特征集进行下一轮训练。
由于RFE需要消耗大量的资源,就不再运行了,代码如下:
# from sklearn.svm import LinearSVC
# from sklearn.feature_selection import RFECV
# Use SVM as the model
# svc = LinearSVC(dual="auto", penalty="l1")
# Recursive feature elimination with cross-validation to select features.
# rfe = RFECV(svc, step=1, cv=5, verbose=1)
# rfe.fit(X, y)
# The mask of selected features.
# print(zip(X.columns, rfe.support_))
# print("The number of features:", rfe.n_features_in_)
# print("The number of selected features:", rfe.n_features_)
# feature_rank = pd.Series(rfe.ranking_, index=X.columns).sort_values(ascending=False)
# print("Features sorted by their rank:", feature_rank[:10], sep="\n")
特征重要性
嵌入法也是用模型来选择特征,但是它和RFE的区别是它不通过不停的筛掉特征来进行训练,而是使用特征全集训练模型。
- 最常用的是使用带惩罚项( ℓ 1 , ℓ 2 \ell_1,\ell_2 ℓ1,ℓ2 正则项)的基模型,来选择特征,例如 Lasso,Ridge。
- 或者简单的训练基模型,选择权重较高的特征。
我们先使用之前定义的 score_dataset 获取每个特征的重要性分数:
selected_categorical_features = [col for col in categorical_features if col in selected_features]
eval_results, feature_importances = score_dataset(X[selected_features], y, selected_categorical_features)
Starting time 21:55:44
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.776068 + 0.00333724
[100] cv_agg's valid auc: 0.781097 + 0.00296053
[150] cv_agg's valid auc: 0.781236 + 0.00298245
Early stopping, best iteration is:
[136] cv_agg's valid auc: 0.781375 + 0.00302538
score_dataset cost 0 hours 2 minutes 25 seconds
# Sort features according to importance
feature_importances = feature_importances.sort_values('score', ascending=False)
feature_importances['score'].head(15)
AMT_ANNUITY / AMT_CREDIT 92.6
MODE(previous.PRODUCT_COMBINATION) 62.8
EXT_SOURCE_2 + EXT_SOURCE_3 60.4
MODE(installments.previous.PRODUCT_COMBINATION) 52.0
MAX(bureau.DAYS_CREDIT) 40.4
DAYS_BIRTH / EXT_SOURCE_1 38.4
MAX(bureau.DAYS_CREDIT_ENDDATE) 35.8
SUM(bureau.AMT_CREDIT_MAX_OVERDUE) 34.2
MEAN(bureau.AMT_CREDIT_SUM_DEBT) 34.0
AMT_GOODS_PRICE / AMT_ANNUITY 30.6
MODE(cash.previous.PRODUCT_COMBINATION) 29.8
MAX(cash.previous.DAYS_LAST_DUE_1ST_VERSION) 29.8
SUM(bureau.AMT_CREDIT_SUM) 29.0
MEAN(previous.MEAN(cash.CNT_INSTALMENT_FUTURE)) 29.0
AMT_CREDIT - AMT_GOODS_PRICE 28.2
Name: score, dtype: float64
可以看到,我们构建的许多特征进入了前15名,这应该让我们有信心,我们所有的辛勤工作都是值得的!
接下来,我们删除重要性为0的特征,因为这些特征实际上从未用于在任何决策树中拆分节点。因此,删除这些特征是一个非常安全的选择(至少对这个特定模型来说)。
# Find the features with zero importance
zero_features = feature_importances.query("score == 0.0").index.tolist()
print(f'\nThere are {len(zero_features)} features with 0.0 importance')
There are 105 features with 0.0 importance
selected_features = [col for col in selected_features if col not in zero_features]
print("The number of selected features:", len(selected_features))
print("Dropped {} features with zero importance.".format(len(zero_features)))
The number of selected features: 835
Dropped 105 features with zero importance.
selected_categorical_features = [col for col in categorical_features if col in selected_features]
eval_results, feature_importances = score_dataset(X[selected_features], y, selected_categorical_features)
Starting time 21:58:13
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.77607 + 0.00333823
[100] cv_agg's valid auc: 0.781042 + 0.00295406
[150] cv_agg's valid auc: 0.781317 + 0.00303434
[200] cv_agg's valid auc: 0.780819 + 0.00281177
Early stopping, best iteration is:
[154] cv_agg's valid auc: 0.781405 + 0.0029417
score_dataset cost 0 hours 2 minutes 34 seconds
删除0重要性的特征后,我们还有834个特征。如果我们认为此时特征量依然非常大,我们可以继续删除重要性最小的特征。
下图显示了累积重要性与特征数量:
feature_importances = feature_importances.sort_values('score', ascending=False)
sns.lineplot(x=range(1, feature_importances.shape[0]+1), y=feature_importances['score'].cumsum())
plt.show()
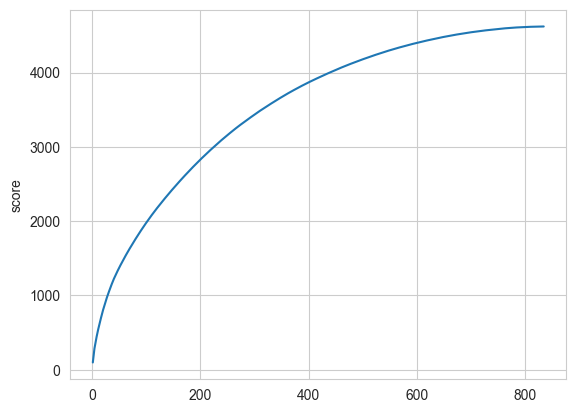
如果我们选择是只保留95%的重要性所需的特征:
def select_import_features(scores, thresh=0.95):
feature_imp = pd.DataFrame(scores, columns=['score'])
# Sort features according to importance
feature_imp = feature_imp.sort_values('score', ascending=False)
# Normalize the feature importances
feature_imp['score_normalized'] = feature_imp['score'] / feature_imp['score'].sum()
feature_imp['cumsum'] = feature_imp['score_normalized'].cumsum()
selected_features = feature_imp.query(f'cumsum >= {thresh}')
return selected_features.index.tolist()
init_n = len(selected_features)
import_features = select_import_features(feature_importances['score'], thresh=0.95)
print("The number of import features:", len(import_features))
print(f'Dropped {init_n - len(import_features)} features.')
The number of import features: 241
Dropped 594 features.
剩余248个特征足以覆盖95%的重要性。
import_categorical_features = [col for col in categorical_features if col in import_features]
eval_results, feature_importances = score_dataset(X[import_features], y, import_categorical_features)
Starting time 22:00:49
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.756425 + 0.0029265
[100] cv_agg's valid auc: 0.759284 + 0.0029921
[150] cv_agg's valid auc: 0.759162 + 0.00314089
Early stopping, best iteration is:
[115] cv_agg's valid auc: 0.759352 + 0.00300464
score_dataset cost 0 hours 0 minutes 21 seconds
在继续之前,我们应该记录我们采取的特征选择步骤,以备将来使用:
- 删除互信息为0的无效特征:删除了117个特征
- 删除相关系数大于0.9的共线变量:删除了1108个特征
- 根据GBM删除0.0重要特征:删除108个特征
- (可选)仅保留95%特征重要性所需的特征:删除了586个特征
我们看下特征组成:
original = set(original_features) & set(import_features)
derived = set(import_features) - set(original)
print(f"Selected features: {len(original)} original features, {len(derived)} derived features.")
Selected features: 33 original features, 208 derived features.
保留的248个特征,有37个是原始特征,211个是衍生特征。
主成分分析
常见的降维方法除了基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA)。这两种方法的本质是相似的,本节主要介绍PCA。
| 方法 | 函数 | python包 |
|---|---|---|
| 主成分分析法 | PCA | sklearn.decomposition |
| 线性判别分析法 | LinearDiscriminantAnalysis | sklearn.discriminant_analysis |
应用主成分分析
from sklearn.decomposition import PCA
from sklearn.preprocessing import RobustScaler
# Standardize
pca = Pipeline([
('standardize', RobustScaler()),
('pca', PCA(n_components=None, random_state=SEED)),
], verbose=True
)
principal_components = pca.fit_transform(X)
weight_matrix = pca['pca'].components_
[Pipeline] ....... (step 1 of 2) Processing standardize, total= 1.1min
[Pipeline] ............... (step 2 of 2) Processing pca, total=11.8min
其中 pca.components_ 对应sklearn 中 PCA 求解矩阵的SVD分解的截断的
V
T
V^T
VT。在PCA转换后,pca.components_ 是一个具有形状为 (n_components, n_features) 的数组,其中 n_components 是我们指定的主成分数目,n_features 是原始数据的特征数目。pca.components_ 的每一行表示一个主成分,每一列表示原始数据的一个特征。因此,pca.components_ 的每个元素表示对应特征在主成分中的权重。
可视化方差
def plot_variance(pca, n_components=10):
evr = pca.explained_variance_ratio_[:n_components]
grid = range(1, n_components + 1)
# Create figure
plt.figure(figsize=(6, 4))
# Percentage of variance explained for each components.
plt.bar(grid, evr, label='Explained Variance')
# Cumulative Variance
plt.plot(grid, np.cumsum(evr), "o-", label='Cumulative Variance', color='orange')
plt.xlabel("The number of Components")
plt.xticks(grid)
plt.title("Explained Variance Ratio")
plt.ylim(0.0, 1.1)
plt.legend(loc='best')
plot_variance(pca['pca'])
plt.show()
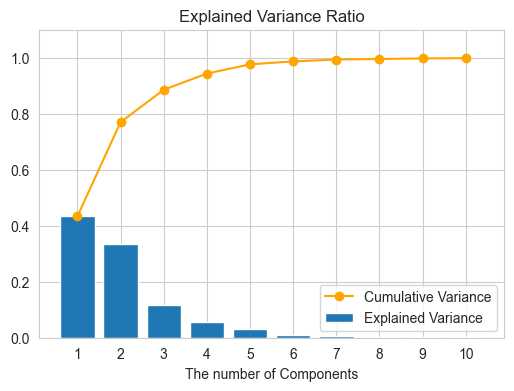
我们使用pca前两个主成分进行可视化:
print(
"explained variance ratio (first two components): %s"
% str(pca['pca'].explained_variance_ratio_[:2])
)
sns.kdeplot(x=principal_components[:, 0], y=principal_components[:, 1], hue=y)
plt.xlim(-1e8, 1e8)
plt.ylim(-1e8, 1e8)
explained variance ratio (first two components): [0.43424749 0.33590885]
(-100000000.0, 100000000.0)
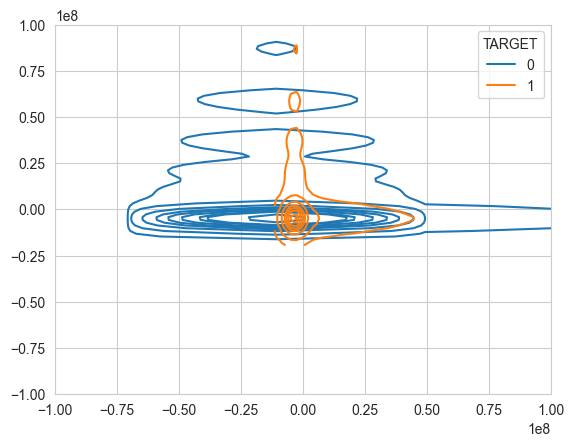
这两个类别没有完全分开,因此我们需要更多的主成分。
PCA可以有效地减少维度的数量,但他们的本质是要将原始的样本映射到维度更低的样本空间中。这意味着PCA特征没有真正的业务含义。此外,PCA假设数据是正态分布的,这可能不是真实数据的有效假设。因此,我们只是展示了如何使用pca,实际上并没有将其应用于数据。
小结
本章介绍了很多特征选择方法
- 单变量特征选择可以用于理解数据、数据的结构、特点,也可以用于排除不相关特征,但是它不能发现冗余特征。
- 正则化的线性模型可用于特征理解和特征选择。但是它需要先把特征装换成正态分布。
- 嵌入法的特征重要性选择是一种非常流行的特征选择方法,它易于使用。但它有两个主要问题:
- 重要的特征有可能得分很低(关联特征问题)
- 这种方法对类别多的特征越有利(偏向问题)
至此,经典的特征工程至此已经完结了,我们继续使用LightGBM模型评估筛选后的特征。
eval_results, feature_importances = score_dataset(X[selected_features], y, selected_categorical_features)
Starting time 22:14:44
Starting training...
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
Training until validation scores don't improve for 50 rounds
[50] cv_agg's valid auc: 0.77607 + 0.00333823
[100] cv_agg's valid auc: 0.781042 + 0.00295406
[150] cv_agg's valid auc: 0.781317 + 0.00303434
[200] cv_agg's valid auc: 0.780819 + 0.00281177
Early stopping, best iteration is:
[154] cv_agg's valid auc: 0.781405 + 0.0029417
score_dataset cost 0 hours 2 minutes 25 seconds
特征重要性:
# Sort features according to importance
feature_importances['score'].sort_values(ascending=False).head(15)
AMT_ANNUITY / AMT_CREDIT 98.6
EXT_SOURCE_2 + EXT_SOURCE_3 66.6
MODE(previous.PRODUCT_COMBINATION) 66.0
MODE(installments.previous.PRODUCT_COMBINATION) 54.4
MAX(bureau.DAYS_CREDIT) 41.8
MAX(bureau.DAYS_CREDIT_ENDDATE) 40.0
DAYS_BIRTH / EXT_SOURCE_1 39.8
MEAN(bureau.AMT_CREDIT_SUM_DEBT) 37.2
SUM(bureau.AMT_CREDIT_MAX_OVERDUE) 35.2
MODE(cash.previous.PRODUCT_COMBINATION) 33.4
AMT_GOODS_PRICE / AMT_ANNUITY 33.0
SUM(bureau.AMT_CREDIT_SUM) 30.8
MAX(cash.previous.DAYS_LAST_DUE_1ST_VERSION) 30.8
MEAN(previous.MEAN(cash.CNT_INSTALMENT_FUTURE)) 29.8
AMT_CREDIT - AMT_GOODS_PRICE 29.2
Name: score, dtype: float64
del X, y
gc.collect()
df = pd.read_csv('../datasets/Home-Credit-Default-Risk/created_data.csv', index_col='SK_ID_CURR')
selected_data = df[selected_features + ['TARGET']]
selected_data.to_csv('../datasets/Home-Credit-Default-Risk/selected_data.csv', index=True)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









