







目录
1,题目描述

Sample Input:
8
3: 2 7 10
1: 4
2: 5 3
1: 4
1: 3
1: 4
4: 6 8 1 5
1: 4
Sample Output:
3
4 3 1题目大意
每个用户都有一些爱好,拥有相同爱好的人属于同一个cluster。比如用户2有爱好3,用户6也有爱好3,而用户2属于cluster1,那么用户6也属于cluster1.
注意
- 接收数据时,注意“冒号”;
补充知识:并查集
可以参考并查集【算法笔记/晴神笔记】
2,思路
参考大神@日沉云起【pat甲级1107. Social Clusters (30)】
了解了并查集之后,就很简单了。这就是并查集的基本应用。
数据结构
- int father[1010]:并查集(用于cluster合并),根节点即为下标所属cluster;
- int hobby[1010]:每个爱好对应的一个用户(只存一个用户即可,用于判断是否有相同爱好)。当hobby为0时,没有人有此爱好;hobby不为0时,便需要将此用户和该hobby对应的用户进行合并,使他们属于相同的cluster;
- int tem[1010] = {0}:存放每个cluster对应的人数;
- vector<int> ans:存放最终结果,每个cluster对应的人数;
算法
并查集在这里,就是将每名用户限定一个“爱好”(即cluster,有相同爱好的用户进行合并,根节点指向同一个“爱好”。合并的方法不同,最后归结的cluster可能不同,但是不影响解题)
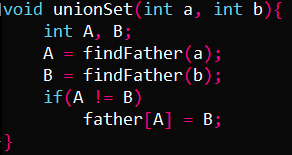
- 设计查找根节点函数findFather,合并函数unionSet:

- 初始化并查集:

- 接收数据并更新并查集(合并cluster):

- 将人数大于0的cluster记录下来,并存入ans中:

3,AC代码
#include<bits/stdc++.h>
using namespace std;
int father[1010], N; //father并查集(用于cluster合并)
int hobby[1010]; //hobby每个爱好对应的一个用户(只存一个用户即可,用于判断是否有相同爱好)
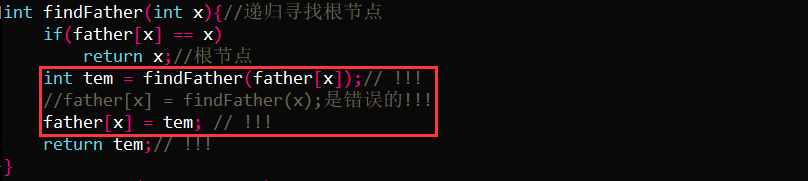
int findFather(int x){ //递归寻找根节点
if(father[x] == x)
return x; //根节点
int tem = findFather(father[x]); // !!!
//father[x] = findFather(x);是错误的!!!
father[x] = tem; // !!!
return tem; // !!!
}
void unionSet(int a, int b){
int A, B;
A = findFather(a);
B = findFather(b);
if(A != B)
father[A] = B;
}
int main(){
#ifdef ONLINE_JUDGE
#else
freopen("1.txt", "r", stdin);
#endif // ONLINE_JUDGE
scanf("%d", &N);
iota(father, father + N + 1, 0); //初始化 每个节点的根节点即自己
int num, id;
for(int i = 1; i <= N; i++){ //i即用户的编号
scanf("%d:", &num);
for(int j = 0; j < num; j++){
scanf("%d", &id); //id爱好的编号
if(hobby[id] != 0) //hobby[id]有爱好id的用户编号
unionSet(i, hobby[id]); //i的根节点改为hobby[id]的根节点
else
hobby[id] = i;
}
}
int tem[1010] = {0}; //存放每个cluster的人数
for(int i = 1; i <= N; i++){
tem[findFather(i)]++; // !!!不是father[i]
}
sort(tem, tem + N + 1);
vector<int> ans;
for(int i = N; i >= 1; i--){
if(tem[i] != 0)
ans.push_back(tem[i]);
}
printf("%d\n%d", ans.size(), ans[0]);
for(int i = 1; i < ans.size(); i++)
printf(" %d", ans[i]);
return 0;
}
4,解题过程
第一搏
一看题意,这难道是30分的题?
map收集各爱好的人数,遍历一遍存入set,再倒着输出,完美?
#include<bits/stdc++.h>
using namespace std;
int main(){
#ifdef ONLINE_JUDGE
#else
freopen("1.txt", "r", stdin);
#endif // ONLINE_JUDGE
int N, num, id;
map<int, int> hobby;
set<int> ans;
scanf("%d", &N);
for(int i = 0; i < N; i++){
scanf("%d:", &num);
for(int j = 0; j < num; j++){
scanf("%d", &id);
hobby[id]++;
}
}
for(auto it : hobby)
ans.insert(it.second);
printf("%d\n", ans.size());
auto it = ans.rbegin();
printf("%d", *it);
it++;
for(; it != ans.rend(); it++)
printf(" %d", *it);
return 0;
}

我仿佛感受到了陈越姥姥赤裸裸的鄙视。。。
第二搏
其实也感觉到了一些不对劲的地方,以题中的例子来看,爱好4有4人,爱好5有3人,其余的6个爱好只有一个人选择,最后输出时,clusters却只有3。。。
欣赏了大神的操作之后,恍然大悟。
任何两个人,只要他们有相同的爱好,那么他们就属于同一个cluster;
题目中给出的例子如图:(同一个颜色,指向同一个根,即属于同一cluster)
假设现在又多了一个有爱好6的用户,id为9;

由于用户7和用户9,有着相同的爱好,而用户7属于cluster1,所以将用户9也归为cluster1;

并查集在这里,就是将每名用户限定一个“爱好”(即cluster,有相同爱好的用户进行合并,根节点指向同一个“爱好”。合并的方法不同,最后归结的cluster可能不同,但是不影响解题)。
#include<bits/stdc++.h>
using namespace std;
int father[1002], N;//father并查集(用于cluster合并)
int hobby[1002];//hobby每个爱好对应的一个用户(只存一个用户即可,用于判断是否有相同爱好)
int findFather(int x){//递归寻找根节点
if(father[x] == x)
return x;//根节点
father[x] = findFather(x);
//cout<<1<<endl;
return father[x];// !!!
}
void unionSet(int a, int b){
int A, B;
A = findFather(a);
B = findFather(b);
if(A != B)
father[A] = B;
}
int main(){
#ifdef ONLINE_JUDGE
#else
freopen("1.txt", "r", stdin);
#endif // ONLINE_JUDGE
scanf("%d", &N);
iota(father, father + N + 1, 0);//初始化 每个节点的根节点即自己
int num, id;
for(int i = 1; i <= N; i++){//i即用户的编号
scanf("%d:", &num);
for(int j = 0; j < num; j++){
scanf("%d", &id);//id爱好的编号
if(hobby[id] != 0)//hobby[id]有爱好id的用户编号
unionSet(i, hobby[id]);//i的根节点改为hobby[id]的根节点
else
hobby[id] = i;
}
}
int tem[1002] = {0};//存放每个cluster的人数
for(int i = 1; i <= N; i++){
tem[father[i]]++;// !!!
}
//cout<<"YES"<<endl;
sort(tem, tem + N + 1);
vector<int> ans;
for(int i = N; i >= 1; i--){
if(tem[i] != 0)
ans.push_back(tem[i]);
}
printf("%d\n%d", ans.size(), ans[0]);
for(int i = 1; i < ans.size(); i++)
printf(" %d", ans[i]);
return 0;
}
第三搏
三个大数据测试都出现了段错误。。。莫非数组还不够大?
测试之后,显然并不是。。。
再次审查代码,终于发现了以下两处错误:
1,递归求解根节点时的设计有问题:
2,遍历每个用户属于哪个cluster时,需要使用findFather函数,而不是father[i]:
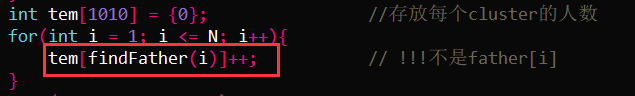

内存占用并不大,看来是递归设计的有问题,导致了大量内存被占用。















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









