







目录
文章内容来自:南京大学 / 星环科技课程,大数据理论与实践课程Ⅰ
对细节部分引用其他网络资源进行补充。
一,YARN简介
1,YARN的由来
Hadoop 1.x中的MapReduce存在先天缺陷:
- 既是计算框架,又是资源管理系统;
- 仅把Task数量看作资源,没有考虑CPU和内存;
- 扩展性较差,集群规模上限4K;
- 源码难于理解,升级维护困难;
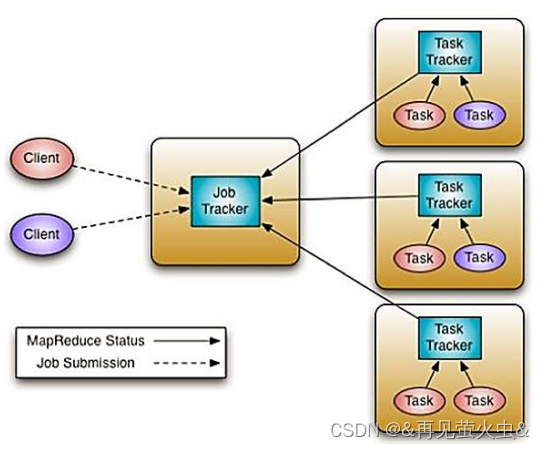
为了让MR专注于计算,所以引入了YARN来负责具体的资源管理,从而提高性能。
2,什么是YARN
YARN,Yet Another Resource Negotiator,另一种资源管理器
设计目标:聚焦资源管理、通用(适用各种计算框架)、高可用(元数据和Master高可用)、高扩展(与HDFS同步扩展)、高容错(计算容错)
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。

二,YARN原理
1,系统架构
1.1 角色分工
四种角色:ResourceManager、ApplicationMaster(作业管家)、NodeManager、Client
1, Active ResourceManager(ARM)
- 活动资源管理节点(Master / 集群唯一)
- 统一管理集群计算资源
- 负责启动ApplicationMaster、作业指派和监控
- 将资源按照一定的调度策略分配给作业
- 接收NodeManager的运行状况和资源上报信息
2,Standby ResourceManager(SRM)
- 热备资源管理节点(允许多个)
- 主备切换
- -AR宕机后,经过Master选举和状态信息恢复,SRM升级为ARM
- -重启AM,杀死所有运行中的Container
3,ApplicationMaster(AM)
作业管家
- 一对一管理:每个作业实例都由一个专职的AM来管理
- 作业解析:将Job解析为由若干Task组成的有向无环图
- 申请资源:向RM申请Job运行所需的计算资源
- 任务调度和监管:向NM申请分配Container和启动Task,同时监测Task的运行状态和进度
- 反馈:向Client反馈Job的运行状态和结果
实现方式
- YARN缺省提供MapReduce的AM实现,但其他计算框架需自备作业管理组件(如Spark Driver)
- 采用基于事件驱动的异步编程模型,由中央事件调度器统一管理所有事件
- AM是一种事件处理器,在中央事件调度器中注册,这样可实现解耦,以确保YARN的通用性
4,NodeManager(NM)
- 计算节点(Slave / 高扩展)
- 管理单个节点的资源
- 管理Container的生命周期(从创建到销毁的全过程)
- 向ResourceManager汇报运行状况和资源使用情况
5,Container
- 容器:对进程相关资源的封装,对资源的抽象,分配资源即分配Container
- 分为两类:运行AM的Container 、运行Task的Container
1.2 设计思想
将JobTracker的资源管理和作业管理职能分离开来

1.3 工作机制
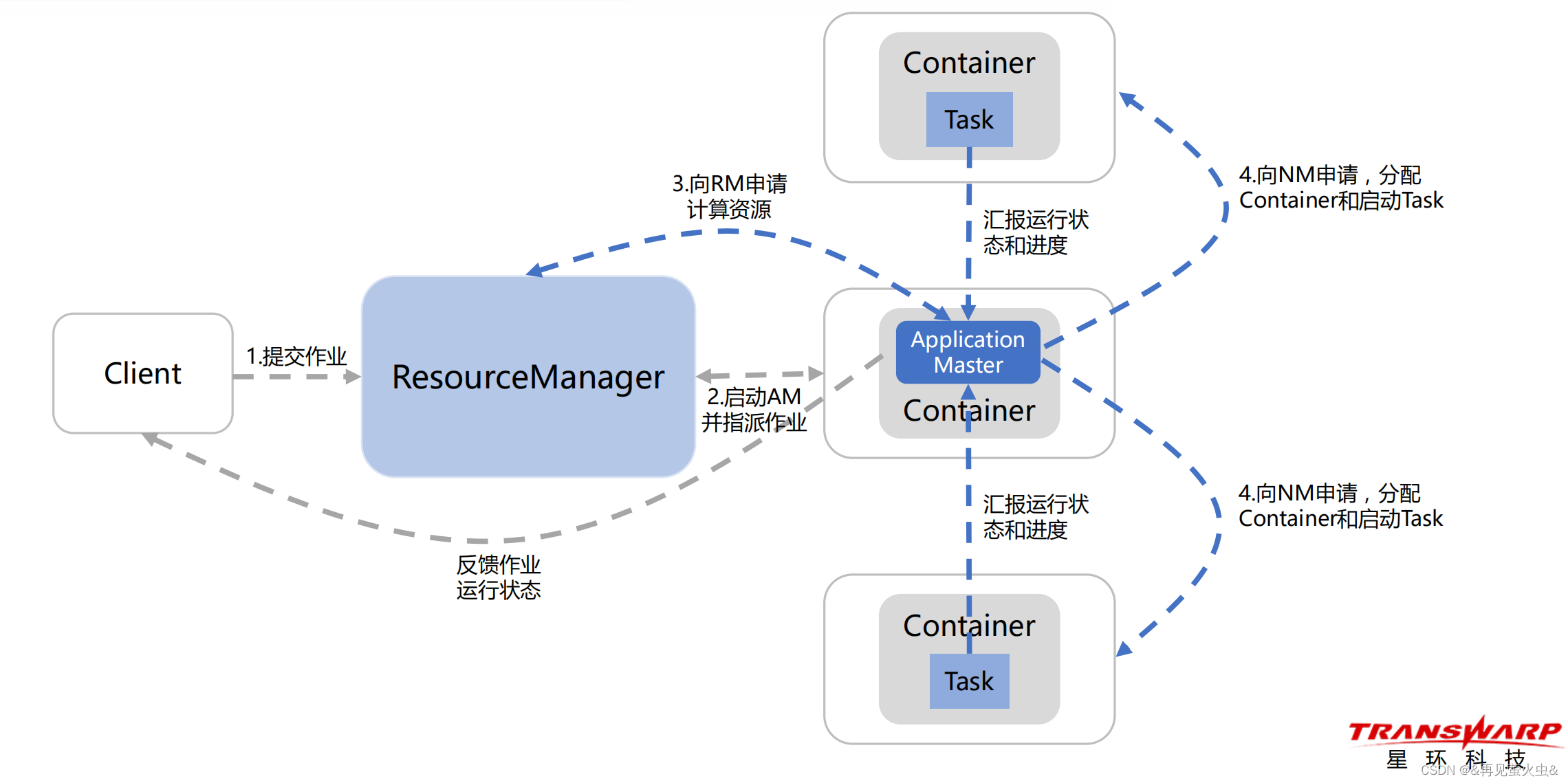
基本流程
- Client向RM提交编译好的分布式程序(Job)
- RM接收Job后,分配一个NM来启动AM,并将Job指派给AM,由它来一对一管理
- AM将Job解析为一个由若干Task组成的有向无环图DAG,并从NameNode获取Task输入数据的存储位置(即Block存储位置),然后向RM申请计算资源
- 根据AM提交的Task Set及其对应的Block存储位置,RM为Job分配计算资源,即为每个Task分配一个NM List,并返回给AM(计算跟着数据走:NM所在Server的DataNode上存储了Task的输入Block)
- 根据Task DAG和NM List,AM按照并行/串行次序将Task提交给NM
- NM接收Task,验证身份后,启动Container,运行Task,并向AM汇报运行状态和进度
- 在Job运行期间,AM向Client反馈Job运行进度和状态,并返回最终结果
1.4 集群部署
计算跟着数据走(NodeManager和DataNode在一个服务器上,这样才能做到计算跟着数据走)

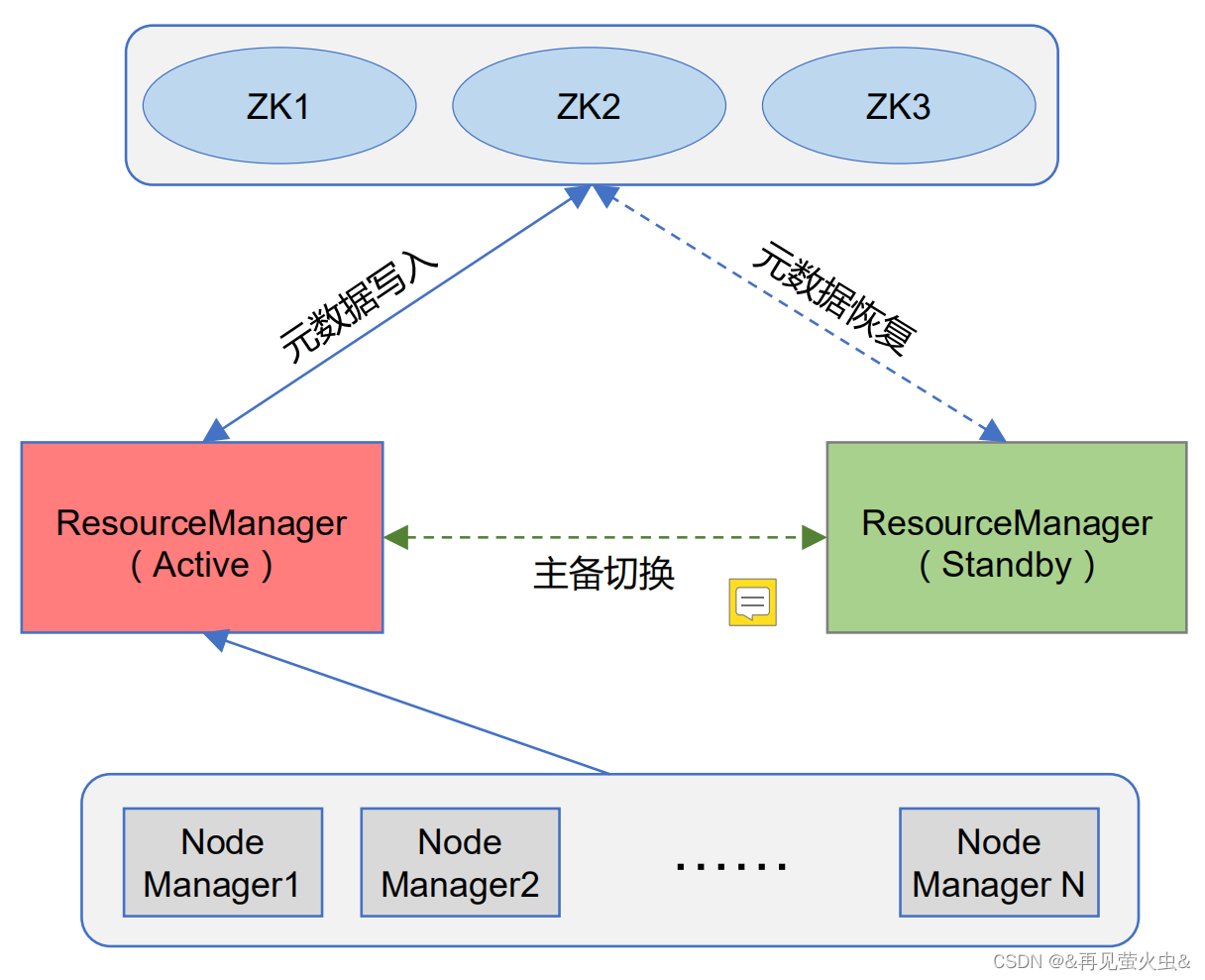
2,YARN高可用
基于ZK的元数据高可用
- RM状态
- Job状态和Token(访问身份验证)
基于ZK的RM高可用(主备切换)
- Master选举
- 恢复RM的原有状态信息
- 重启AM,并杀死所有运行中的Container(task太多了,而且实时变化,不好存储。所以AM挂掉之后,job相关的task要全部kill掉,重新执行)
计算高可用
- Task失败后,AM会把其调度到其他NM上重新执行(默认4次)
- Job失败后,RM会在其他NM上重启AM(默认2次)
三,YARN资源调度策略
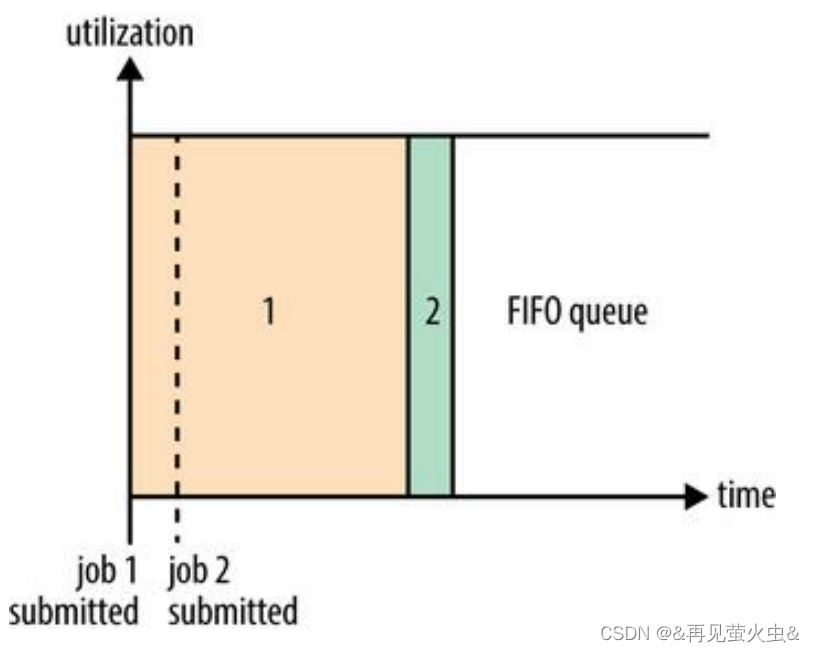
1,FIFO调度器
调度策略
- 将所有作业放入一个队列,先进队列的先获得资源,排在后面的作业只能等待
缺点
- 资源利用率低,无法交叉运行作业
- 灵活性差,如紧急作业无法插队,耗时长的作业拖慢整个队列
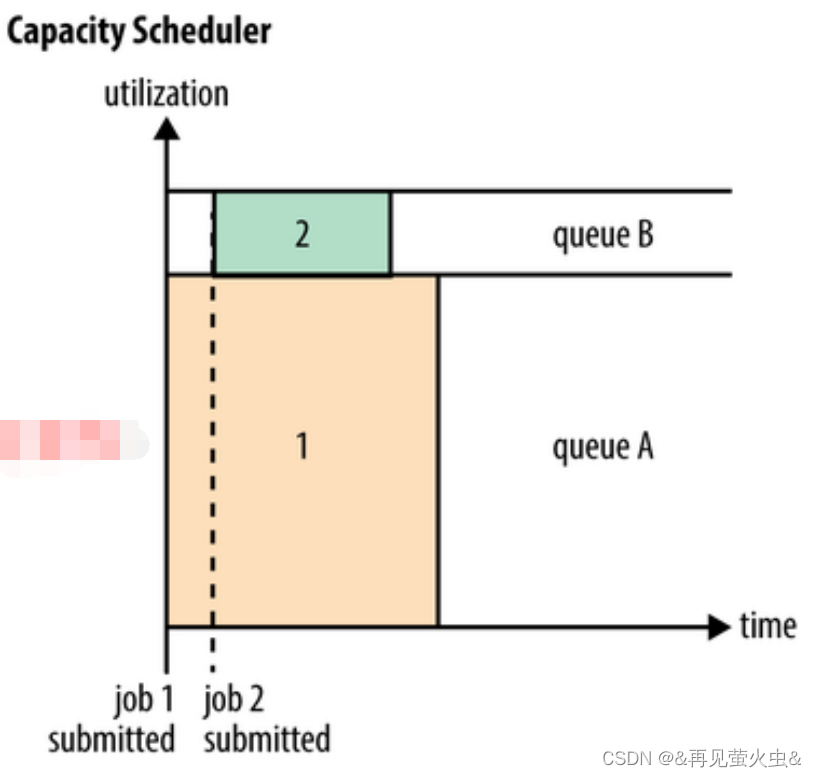
2,容量调度器
核心思想
- 提前做预算,在预算指导下分享集群资源
调度策略
- 集群资源由多个队列分享,并行度即队列个数
- 每个队列都要预设资源分配比例(提前做预算,预算是指导原则)
- 空闲资源优先分配给“实际资源/预算资源”比值最低的队列。比如有两个队列,队列A中资源占用了80%,而队列B中只占用了10%,则优先分配给队列B(保持弹性)
- 队列内部采用FIFO调度策略
特点
- 层次化的队列设计:子队列可使用父队列资源
- 容量保证:每个队列都要预设资源占比,防止资源独占
- 弹性分配:空闲资源可以分配给任何队列,但当多个队列争用时,会按比例进行平衡
- 支持动态管理:既可以动态调整队列的容量、权限等参数,也可以动态增加、暂停队列
- 访问控制:用户只能向自己的队列中提交作业,不能访问其他队列
- 多租户:多用户共享集群资源
3,公平调度器
调度策略
- 多队列公平共享集群资源
- 通过平分的方式,动态分配资源,无需预先设定资源分配比例,即“不提前做预算、见面分一半、实现绝对公平”
- 队列内部可配置调度策略:FIFO、Fair(默认)
资源抢占
- 终止其他队列的作业,使其让出所占资源,然后将资源分配给占用资源量少于最小资源量限制的队列(通过杀富济贫保持弹性)
队列权重
- 当队列中有作业等待,并且集群中有空闲资源时,每个队列可以根据权重获得不同比例的空闲资源(通过政策倾斜保持弹性)
















 2009
2009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









