






1. concat
格式:CONCAT(expr1,expr2)
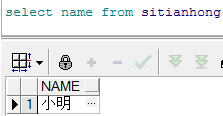
1.select concat(name,‘任意字符串’) from tablename
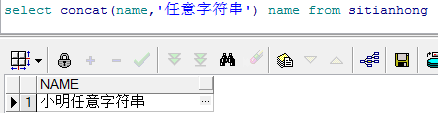
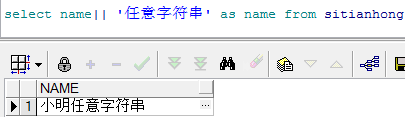
2.select name || ‘任意字符串’ from tanlename
2.insert()
格式一:instr( string1, string2 ) / instr(源字符串, 目标字符串)
格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) / instr(源字符串, 目标字符串, 起始位置, 匹配序号)
解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(几)次出现string2。
1 select instr('helloworld','l') from dual; --返回结果:3 默认第一次出现“l”的位置
2 select instr('helloworld','lo') from dual; --返回结果:4 即:在“lo”中,“l”开始出现的位置
3 select instr('helloworld','wo') from dual; --返回结果:6 即“w”开始出现的位置
1 select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
2 select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置
3 select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置
4 select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置
5 select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第二次出现的“l”的位置
6 select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置
7 select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置
MySQL: select * from tableName where name like '%helloworld%';
Oracle:select * from tableName where instr(name,'helloworld')>0; --这两条语句的效果是一样的
3.substr
1.substr(string string, int a, int b)
参数1:string 要处理的字符串
参数2:a 截取字符串的开始位置(起始位置是0)
参数3:b 截取的字符串的长度(而不是字符串的结束位置)
例如:
substr(“ABCDEFG”, 0); //返回:ABCDEFG,截取所有字符
substr(“ABCDEFG”, 2); //返回:CDEFG,截取从C开始之后所有字符
substr(“ABCDEFG”, 0, 3); //返回:ABC,截取从A开始3个字符
substr(“ABCDEFG”, 0, 100); //返回:ABCDEFG,100虽然超出预处理的字符串最长度,但不会影响返回结果,系统按预处理字符串最大数量返回。
substr(“ABCDEFG”, -3, 3); //返回:EFG,注意参数-3,为负值时表示从尾部开始算起,字符串排列位置不变。
2.substr(string string, int a)
参数1:string 要处理的字符串
参数2:a 可以理解为从索引a(注意:起始索引是0)处开始截取字符串,也可以理解为从第 (a+1)个字符开始截取字符串。
例如:
substr(“ABCDEFG”, 0); //返回:ABCDEFG, 截取所有字符
substr(“ABCDEFG”, 2); //返回:CDEFG,截取从C开始之后所有字符
4.case when
1. CASE WHEN 表达式有两种形式
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE
WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
2. CASE WHEN 在语句中不同位置的用法
2.1 SELECT CASE WHEN 用法
SELECT grade, COUNT (CASE WHEN sex = 1 THEN 1 /*sex 1为男生,2位女生*/
ELSE NULL
END) 男生数,
COUNT (CASE WHEN sex = 2 THEN 1
ELSE NULL
END) 女生数
FROM students GROUP BY grade;
2.2 WHERE CASE WHEN 用法
SELECT T2.*, T1.*
FROM T1, T2
WHERE (CASE WHEN T2.COMPARE_TYPE = 'A' AND
T1.SOME_TYPE LIKE 'NOTHING%'
THEN 1
WHEN T2.COMPARE_TYPE != 'A' AND
T1.SOME_TYPE NOT LIKE 'NOTHING%'
THEN 1
ELSE 0
END) = 1
2.3 GROUP BY CASE WHEN 用法
SELECT
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END salary_class, -- 别名命名
COUNT(*)
FROM Table_A
GROUP BY
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END;
5.nvl
格式:nvl(expr1,expr2)
含义是:如果oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值
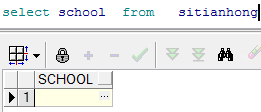
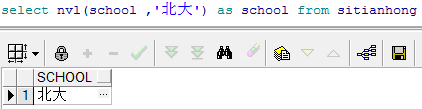
select nvl(school ,‘北大’) as school from sitianhong
6 decode
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
…
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
1.比较大小
select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; --取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
例如:
变量1=10,变量2=20
则sign(变量1-变量2)返回-1,decode解码结果为“变量1”,达到了取较小值的目的。
2.此函数用在SQL语句中,功能介绍如下:
Decode 函数与一系列嵌套的 IF-THEN-ELSE语句相似。base_exp与compare1,compare2等等依次进行比较。如果base_exp和 第i 个compare项匹配,就返回第i 个对应的value 。如果base_exp与任何的compare值都不匹配,则返回default。每个compare值顺次求值,如果发现一个匹配,则剩下的 compare值(如果还有的话)就都不再求值。一个为NULL的base_exp被认为和NULL compare值等价。如果需要的话,每一个compare值都被转换成和第一个compare 值相同的数据类型,这个数据类型也是返回值的类型。















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









