






1.下载安装包,官网的链接下载不了,所以找国内大佬们发布的镜像
或者我这里准备了网盘地址直接下载:
通过网盘分享的文件:liunx、ubantu安装neo所需包
链接: https://pan.baidu.com/s/1sHCipTON6noRZ7ni16975w?pwd=1111 提取码: 1111
2.安装neo4j,讲安装包上传至服务器目录下,目录可自定义,我这里是/data目录。然后解压
cd /data
tar -zxvf neo4j-community-3.5.8-unix.tar.gz3.修改 neo4j.conf 配置文件,在安装目录的conf下
#修改配置文件
vim /data/zypro/neo4j-community-3.5.8/conf/neo4j.conf
# 修改第 22 行 load csv 的路径,可从任意路径读取文件,不用时在前面加个#注释掉
#dbms.directories.import=import
# 修改 35 行和 36 行,设置 JVM 初始堆内存和 JVM 最大堆内存
# 生产环境给的 JVM 最大堆内存越大越好,但是要小于机器的物理内存
dbms.memory.heap.initial_size=512m
dbms.memory.heap.max_size=512m
# 修改 46 行,可以认为这个是缓存,如果机器配置高,这个越大越好
dbms.memory.pagecache.size=512m
# 修改 54 行,去掉改行的#,可以远程通过 ip 访问 neo4j 数据库
dbms.connectors.default_listen_address=0.0.0.0
# 设置端口号,端口可以自定义,不与其他端口冲突就行
# 去掉 71 行、75 行、79 行的注释,自定义端口号
dbms.connector.bolt.listen_address=:7687
dbms.connector.http.listen_address=:7474
dbms.connector.https.listen_address=:7473
# 修改 265 行,设置 neo4j 可读可写
dbms.read_only=false
4.安装apoc插件(也可以不安装,不安装可直接跳过4、5步)
介绍:APOC是Neo4j 3.3版本推出时推荐的一个Java存储过程包,包含丰富的函数和存储过程,作为对Cypher所不能提供的复杂图算法和数据操作功能的补充,APOC还具有使用灵活、高性能等优势。
在第一步网盘目录下的apoc-3.5.0.4-all.jar包放置在neo4j/plugins目录下,也可以到自行下载https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/3.5.0.4
5.修改neo4j.conf 配置
#设置安全策略:不限制apoc的所有存储过程
dbms.security.procedures.unrestricted=apoc.*
#设置页缓存
dbms.memory.pagecache.size=512m
#设置JVM堆初始化内存大小
dbms.memory.heap.initial_size=512m
#设置JVM堆最大内存大小
dbms.memory.heap.max_size=1g
6.启动neo4j
cd /data/neo4j-community-3.5.8/bin
./neo4j start
# 客户端访问
http://服务器IP地址:7474
# 默认的用户名为 neo4j,密码为 neo4j,连接成功后会提示修改密码,完成修改即可出现界面及安装成功!
然后验证apoc,出现下图所示就成功了
return apoc.version()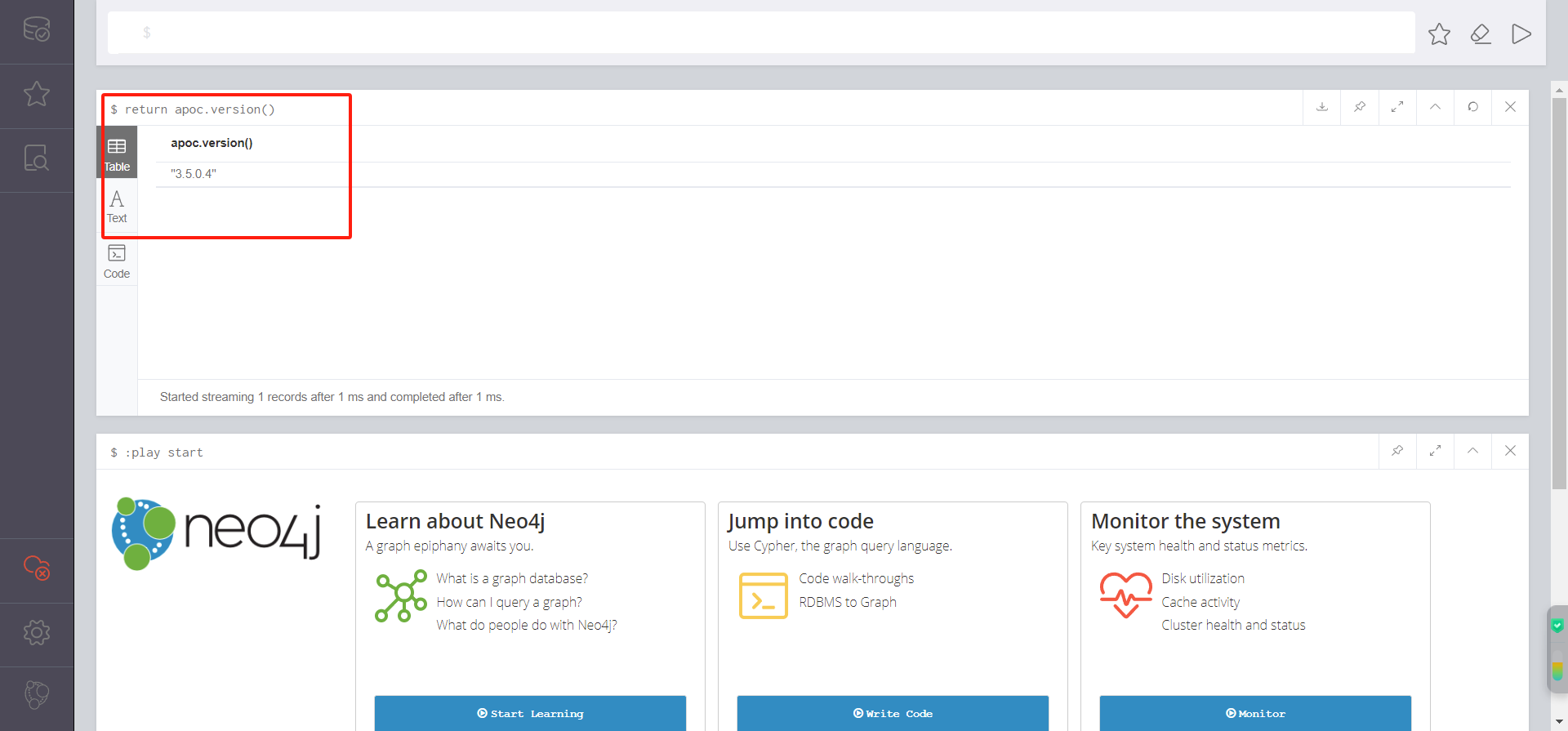
7.设置开机自启
先停止neo4j数据库
cd /data/neo4j-community-3.5.8/bin
./neo4j stop编写启动脚本文件
#编辑启动文件
vim /etc/systemd/system/neo4j.service
[Unit]
Description=Neo4j Graph Database Service
After=network.target
[Service]
Type=forking
ExecStart=/data/neo4j-community-3.5.8/bin/neo4j start
ExecStop=/data/neo4j-community-3.5.8/bin/neo4j stop
Environment=JAVA_HOME=/data/jdk1.8.0_171 #jdk路径
User=root
Group=root
Restart=on-abort
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
将文件设置设置为自启动服务
systemctl enable neo4j.service验证服务,之前启动的neo4j,所以在验证前先停止neo4j然后在启动
#启动服务
systemctl start neo4j.service
#查看服务状态
systemctl status neo4j.service不报错及启动成功!!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









