







面试题答案参考
1、实习经历
这点不多说了,根据自己的来就行
2、工作中最难的点
一般都会提前回顾之前自己遇到的问题,根据自己的来
3、如何保证数据质量
这里主要是阿里对数仓的一些数据质量保证原则
1、数据质量保障原则
阿里对数据仓库主要从四个方面评估数据质量
1)完整性
确保数据不存在缺失
2)准确性
确保数据不存在异常或错误
3)一致性
体现在从业务仓库加工到数据仓库,再到各个消费节点,必须是同一种类型,长度也需要保持一致。
4)及时性
确保数据能及时产出,越来越多的应用希望数据更快产出。
2、数据质量方法概述
阿里的业务复杂,种类繁多的产品每天产生数以亿计的数据,每天的数据量在PB级以上,而数据消费端的应用又层出不穷,各类数据产品如雨后春笋般出现。为了满足这些数据应用,数据仓库的规模也不断膨胀,同时数据质量的保障也越来越复杂。
基于上述背景,提出一套数据质量建设方法
1)消费场景知晓
主要是通过数据资产和基于元数据的应用链路分析解决消费场景知晓的问题。
2)数据生成加工各个环节卡点效验
在各个数据生成环节,格局不同资产等级做出相应的处理。
3)风险点监控
在线数据
-
主要是针对在线系统日常运行产出的数据进行业务规则的效验,以保证数据质量,其主要使用实时业务检测平台BCP(Biz-Check-Platform)。
离线数据
-
主要是针对离线系统日常运行产出的数据进行数据质量监控和实效性监控,其中数据质量监控主要是使用DQC,实效性监控主要是使用摩萨德。
4)质量衡量
对质量的衡量既有事前的衡量,如DQC覆盖率;又有事后的衡量,主要用于跟进质量问题,确定质量问题原因、责任人、解决情况等,并用于数据质量的复盘,避免类似事件再次发生。根据质量问题对不同等级资产的影响程度,确定其是属于低影响的事件还是具有较大影响的故障。质量分则是综合事前和事后的衡量数据进行打分。
5)质量配套工具
针对数据质量的各个方面,都需要相关的工具进行保证,提高效率。
3、消费场景知晓
在数据快速增长,数据类产品和日常决策支持等系统层出不穷,数据仓库应接不暇,数据工程师很难确定几百PB的数据到底是否都是重要的,是否都要进行保障,是否有一些数据已经过期了,是否所有需要精确的进行保障。
基于上述疑问,阿里内部提出数据资产等级,解决消费场景知晓问题。
1)数据等级定义
毁灭性质
-
即数据一旦出错,将会引起重大资产损失,导致收益大损。记为A1(Asset)
全局性质
-
即数据直接或者间接用于集团级业务和效果的评估、重要平台的运维、对外数据产品的透露、影响用户在阿里系网站的行为。记为A2
局部性质
-
即数据直接或间接用于内部一般数据产品或者运营/产品报告,如果出现问题会给事业部或业务线造成影响或者工作效率降低。记为A3
一般性质
-
即数据主要用于小二的日常数据分析,出现问题不会带来太大的影响。记为A4
未知性质
-
不能明确说出数据的应用场景,则标注为未知。记为A5
2)数据资产等级落地
先给不同数据产品或应用划分数据资产等级,再依托元数据的上下游血缘,可以将整个加工消费链打上该数据资产等级。
总结:解决了消费场景知晓的问题,就知道了数据的重要等级,针对不同的等级,也将采取不同的保障措施。
4、数据加工过程卡点校验
1)在线系统卡点效验
主要是指在线系统 的数据生成过程中进行的卡点效验。
要向数据保障数据准确性,主要使用工具。
-
发布平台
-
在业务进行重大变更时,订阅这个发布过程,然后给到离线开发人员。当然不会频繁通知离线开发人员,会根据数据资产等级通知相应人员
-
-
数据库表的变化感知
-
数据库扩容对表的DDL变化,都需要主动通知离线开发人员。
-
有了开发工具,开发人员更重要
-
须知哪些是重要的核心数据资产
-
须知哪些只是内部分析数据使用
2)离线系统卡点效验
首先,代码提交时的卡点效验
-
由于开发人员素质不同,代码能力也有差异,所以需要工具代码扫描SQL SCAN,对每次提交代码进行扫描,将风险点提出来。
其次,是任务发布上线时卡点效验
-
发布上线前测试,代码评审和回归测试
-
回归测试:指修改了旧代码后,重新进行测试以确认修改没引入新的错误。
-
冒烟测试:指开发人员修复一个bug,测试人员专门针对这个问题测试。
-
-
发布上线后测试:Dry-Run测试或真实环境运行测试。
-
Dry-Run:不执行代码,仅运行执行计划,避免由于上线下环境不一致导致语法错误。
-
最后是节点变更或数据重刷前的变更通知
-
一般指使用通知中心将变更原因、变更逻辑、变更测试报告和变更时间等自动通知下游,下游对此次变更没有异议后,再按约定时间执行发布变更,将变更对下游影响降至最低。
5、风险点监控
主要是针对数据在日常运行过程中容易出现的风险进行监控并设置报警机制
1)在线数据风险点监控
采用实时业务检测平台BCP保障重要数据资产的质量。
BCP:制定效验规则用于验证数据的准确性
2)离线数据风险监控
数据准确性
-
使用DQC来监控数据
数据及时性
-
需要进行一系列的报警和优先级设置,使得重要的任务优先且正确产出。使用的工具有摩萨德。
6、质量衡量
评估各种数据仓库质量保障方案,有以下指标:
1)数据质量起夜率,及夜晚处理数据问题
2)数据质量事件
3)数据质量故障体系:指的是严重的数据质量事件
处理方案:
-
故障定义
-
故障等级
-
故障处理
-
故障REview
4、hashmap put操作
5、hashmap扩容操作
6、Java的synchronized有哪些优化
前面三道就不多说了
7、Spark哪些环节会产生小文件
shuffle阶段
我们知道spark-sql提交任务默认shuffle数量是 200,如果数据量过小会造成每一个shuffle 输出的文件数据量过小时间长了就会有大量小文件产生
如果又问shuffl的优化之类的,可以参考我前面的大数据开发面试题V3.0,有这方面的介绍
8、如何解决小文件问题
当使用spark sql执行etl时候出现了,最终结果大小只有几百k,但是小文件一个分区可能就有上千的情况。
小文件过多的一些危害如下:
-
hdfs有最大文件数限制
-
浪费磁盘资源(可能存在空文件)
-
hive中进行统计,计算的时候,会产生很多个map,影响计算的速度。
解决方案如下:
方法一:通过spark的coalesce()方法和repartition()方法
val rdd2 = rdd1.coalesce(8, true) //(true表示是否shuffle) val rdd3 = rdd1.repartition(8)
coalesce:coalesce()方法的作用是返回指定一个新的指定分区的Rdd,如果是生成一个窄依赖的结果,那么可以不发生shuffle,分区的数量发生激烈的变化,计算节点不足,不设置true可能会出错。
repartition:coalesce()方法shuffle为true的情况。
方法二:降低spark并行度,即调节spark.sql.shuffle.partitions
比如之前设置的为100,按理说应该生成的文件数为100;但是由于业务比较特殊,采用的大量的union all,且union all在spark中属于窄依赖,不会进行shuffle,所以导致最终会生成(union all数量+1)*100的文件数。如有10个union all,会生成1100个小文件。这样导致降低并行度为10之后,执行时长大大增加,且文件数依旧有110个,效果有,但是不理想。
方法三:新增一个并行度=1任务,专门合并小文件
先将原来的任务数据写到一个临时分区(如tmp);再起一个并行度为1的任务,类似:
insert overwrite 目标表 select * from 临时分区
结果小文件数还是没有减少,经过多次测后发现原因:‘select * from 临时分区’ 这个任务在spark中属于窄依赖;并且spark DAG中分为宽依赖和窄依赖,只有宽依赖会进行shuffle;故并行度shuffle,spark.sql.shuffle.partitions=1也就没有起到作用;
由于数据量本身不是特别大,所以直接采用了group by(在spark中属于宽依赖)的方式,类似:
insert overwrite 目标表 select * from 临时分区 group by *
先运行原任务,写到tmp分区,‘dfs -count’查看文件数,1100个,运行加上group by的临时任务(spark.sql.shuffle.partitions=1),查看结果目录,文件数=1,成功。
总结:
1)方便的话,可以采用coalesce()方法和repartition()方法
2)如果任务逻辑简单,数据量少,可以直接降低并行度
3)任务逻辑复杂,数据量很大,原任务大并行度计算写到临时分区,再加两个任务:
-
一个用来将临时分区的文件用小并行度(加宽依赖)合并成少量文件到实际分区
-
另一个删除临时分区
4)hive任务减少小文件相对比较简单,可以直接设置参数,如:
Map-only的任务结束时合并小文件:
sethive.merge.mapfiles = true
在Map-Reduce的任务结束时合并小文件:
sethive.merge.mapredfiles= true
当输出文件的平均大小小于1GB时,启动一个独立的map-reduce任务进行文件merge:
sethive.merge.smallfiles.avgsize=1024000000
9、Flink Checkpoint机制
Checkpoint:某一时刻,Flink中所有的Operator的当前State的全局快照,一般存在磁盘上。
Flink提供了Exactly once特性,是依赖于带有barrier的分布式快照+可部分重发的数据源功能实现的。而分布式快照中,就保存了operator的状态信息。
Flink的失败恢复依赖于检查点机制 +可部分重发的数据源。
检查点机制机制:checkpoint定期触发,产生快照,快照中记录了:
-
当前检查点开始时数据源(例如Kafka)中消息的offset。
-
记录了所有有状态的operator当前的状态信息(例如sum中的数值)。
可部分重发的数据源:Flink选择最近完成的检查点K,然后系统重放整个分布式的数据流,然后给予每个operator他们在检查点k快照中的状态。数据源被设置为从位置Sk开始重新读取流。例如在Apache Kafka中,那意味着告诉消费者从偏移量Sk开始重新消费。
Checkpoint
Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,分布式快照可以将同一时间点Task/Operator的状态数据全局统一快照处理,包括Keyed State和Operator State(State后面也接着介绍了)。如下图所示,Flink会在输入的数据集上间隔性地生成checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到相应的checkpoint中。当应用出现异常时,Operator就能够从上一次快照中恢复所有算子之前的状态,从而保证数据的一致性。例如在Kafka Consumer算子中维护Offset状态,当系统出现问题无法从Kafka中消费数据时,可以将Offset记录在状态中,当任务重新恢复时就能够从指定的偏移量开始消费数据。对于状态占用空间比较小的应用,快照产生过程非常轻量,高频率创建且对Flink任务性能影响相对较小。checkpoint过程中状态数据一般被保存在一个可配置的环境中,通常是在JobManager节点或HDFS上。 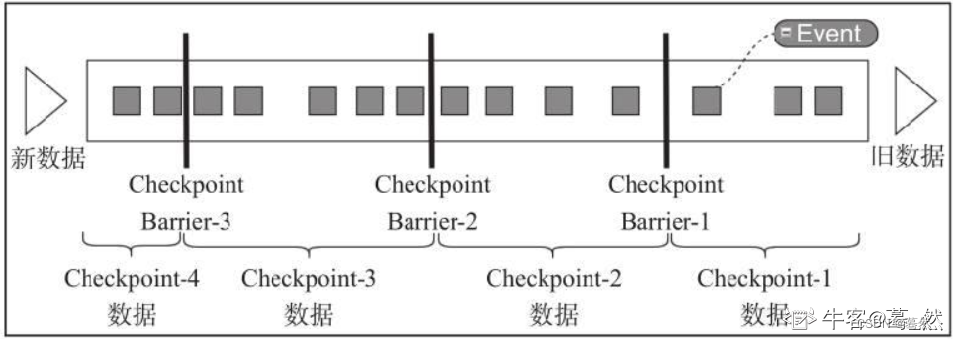
默认情况下Flink不开启检查点的,用户需要在程序中通过调用enable-Checkpointing(n)方法配置和开启检查点,其中n为检查点执行的时间间隔,单位为毫秒。除了配置检查点时间间隔,针对检查点配置还可以调整其他相关参数。
这里就不多讲了。
10、Kafka有哪些角色 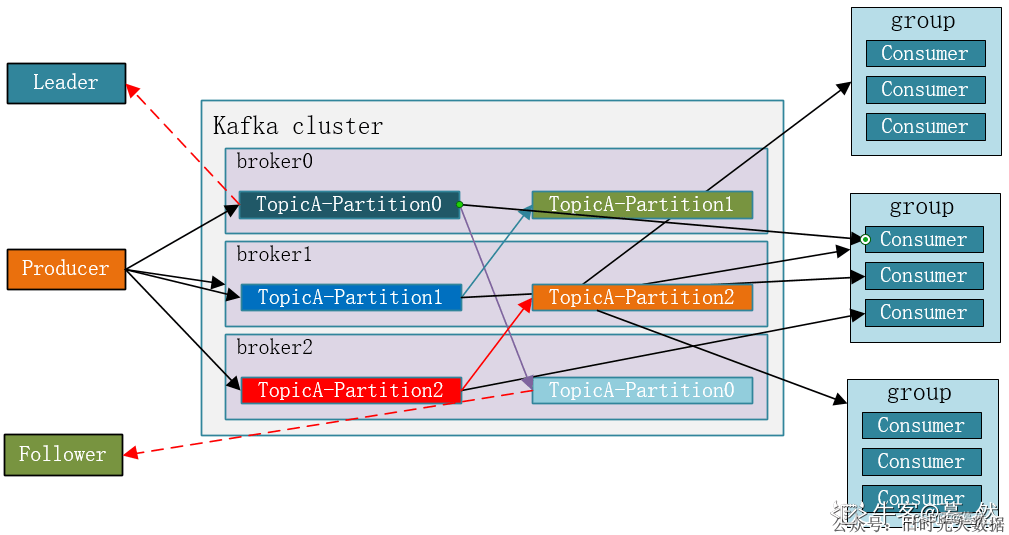
1)Producer:消息生产者,就是向kafka broker发消息的客户端;
2)Consumer:消息消费者,向kafka broker取消息的客户端;
3)Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
9)follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
11、doris模型设计经验
12、Kafka blance什么时候触发
- 消费组成员发生了变更,比如有新的消费者加入了消费组组或者有消费者宕机
- 消费者无法在指定的时间之内完成消息的消费
- 消费组订阅的Topic发生了变化
- 订阅的Topic的partition发生了变化
13、算法题:树
14、如果来字节之后,做的事情跟想的不一样,怎么办
内心:c
嘴里:这个也没问题的。。。。。















 3388
3388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









