







五,神经网络
注意点part1
- 实例:逻辑回归二层神经网络训练函数
- 使用权重w和偏差值biase计算出第一个隐含层h,然后计算损失,评分,进行反向传播回去
- 多种常用激活函数(一般默认max(0,x)),如sigmoid函数具有饱和区梯度0,非零点中心,计算x复杂等缺点,max(Relu)函数也有缺点(非中心对称,初始化不佳(如-10)无法激活,注意学习速率不要太高),leaky Relu优化max(0.01x,x),其中0.01为α修正参数可调,maxout集合Lrelu,Relu的优点,只是参数变多了。
- 少量数据可用L-BFGS优化,数据量大的一般用不到
- 神经网络的深度(层数,数据越复杂越多越好,简单则不需要太多)和宽度(各层神经元数)
注意点part2
-
数据预处理可用PCA,SVD等方法
. 权重初始化,待深入,很重要,如Batch Nomalization -
神经网络隐藏层(hidden layer)
-
训练数据要过饱和Overfit
-
超参数调整学习速率,正则化参数(以及差量),更新方式
-
Track the ratio of weight updates / weight magnitudes:
训练神经网络的四个步骤(样本(标准化,初始化权重等),向前传播(得到损失),向后传播(得到每个权重的梯度),用梯度更新【梯度下降】参数(w等))

– 激活函数提供了更多的非线性的数据存储(处理)方式。

下面所讲

– 1,其他参数更新方法,针对SGD更新较慢(y轴快水平慢,波动式前进),但一般还是默认用SGD
- 1,moumentum更新,收敛更快(mu为超参数,v为速度(可初始化为0))好
- 2 nestero momentum (Nag)好好
3,adaGrad update(一般在凸问题中用,回停止学习-0)
针对不同方向的梯度调整快慢(补偿)–通过分母(梯度平方),大慢小快
3.2改进版(不会停止学习)
1e-7是平滑因子,只是未来防止它变0
4,另一种
5,Adam更新(结合MOMENTEUM和RMSprop-like)很好,可以经常采用







beta是超参数0.9,0.995

1.2,优化学习速率(超参数,可用衰减函数控制(一阶函数))

其他优化方法
二阶函数,求出梯度(碗的曲率),知道怎么走就不需要学习速率更新就知道怎么到达最低点了,收敛(但hessian矩阵太大求逆计算量巨大,而基本不采用)
再优化(数据集不大时可用)一般也不用


总结:一般都用Adam来优化



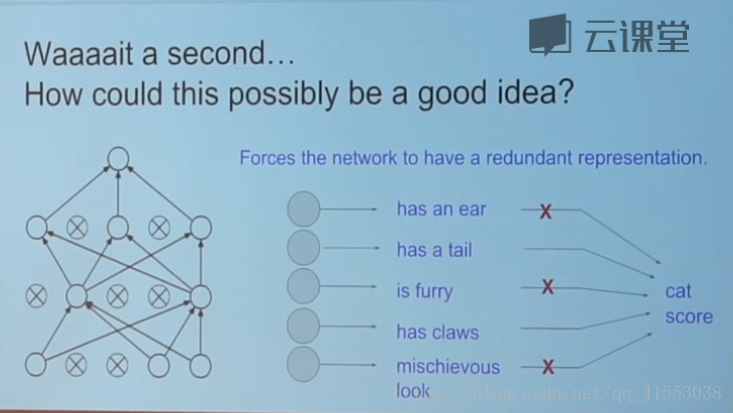
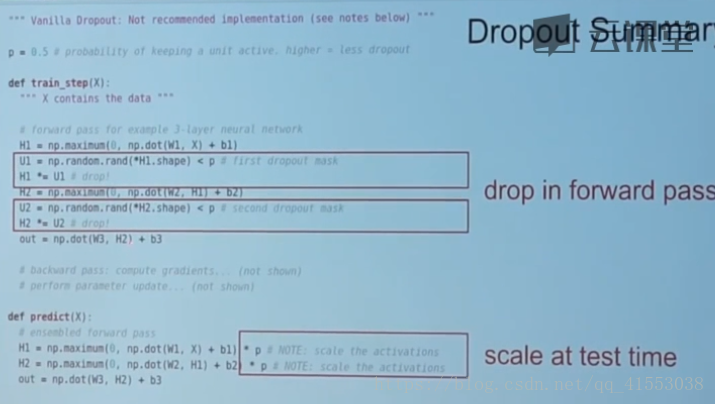
随机失活dropput(regularization),简单但是效果机器号
好方法,可以防止过拟合等
P=0.5


梯度检查gradient checking
自学
卷积神经网络
详解见下一章














 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









