







 PPG(语音后验概率)是一种时间对类别的矩阵,表示每个时间帧中各语音类别的后验概率。常用于说话人无关的语音识别任务中,提取自目标说话者的语音。本文介绍了PPG的定义、提取方法及应用。
PPG(语音后验概率)是一种时间对类别的矩阵,表示每个时间帧中各语音类别的后验概率。常用于说话人无关的语音识别任务中,提取自目标说话者的语音。本文介绍了PPG的定义、提取方法及应用。
最近有个数字人的项目,接触了下后验图PPG这个特征。
简介
PPG的全称是 phonetic posteriorgrams,即语音后验概率,PPG是一个时间对类别的矩阵,其表示对于一个话语的每个特定时间帧,每个语音类别的后验概率。单个音素的后验概率作为时间的函数称为后验轨迹。
一般来讲是从目标说话者的语音中,使用与说话者无关的自动语音识别(SI‑ASR)系统来提取PPG。提取到的PPG用作映射不同的说话者之间的关系。PPG包括与时间范围和语音类别范围相对应的值集合,该语音类别对应于音素状态。
以[2]中的PPG特征图为例,横坐标表示时间,纵坐标表示音素类别,每个坐标表示在给定时间点出现这个音素的后验概率大小,颜色越深,概率越大。
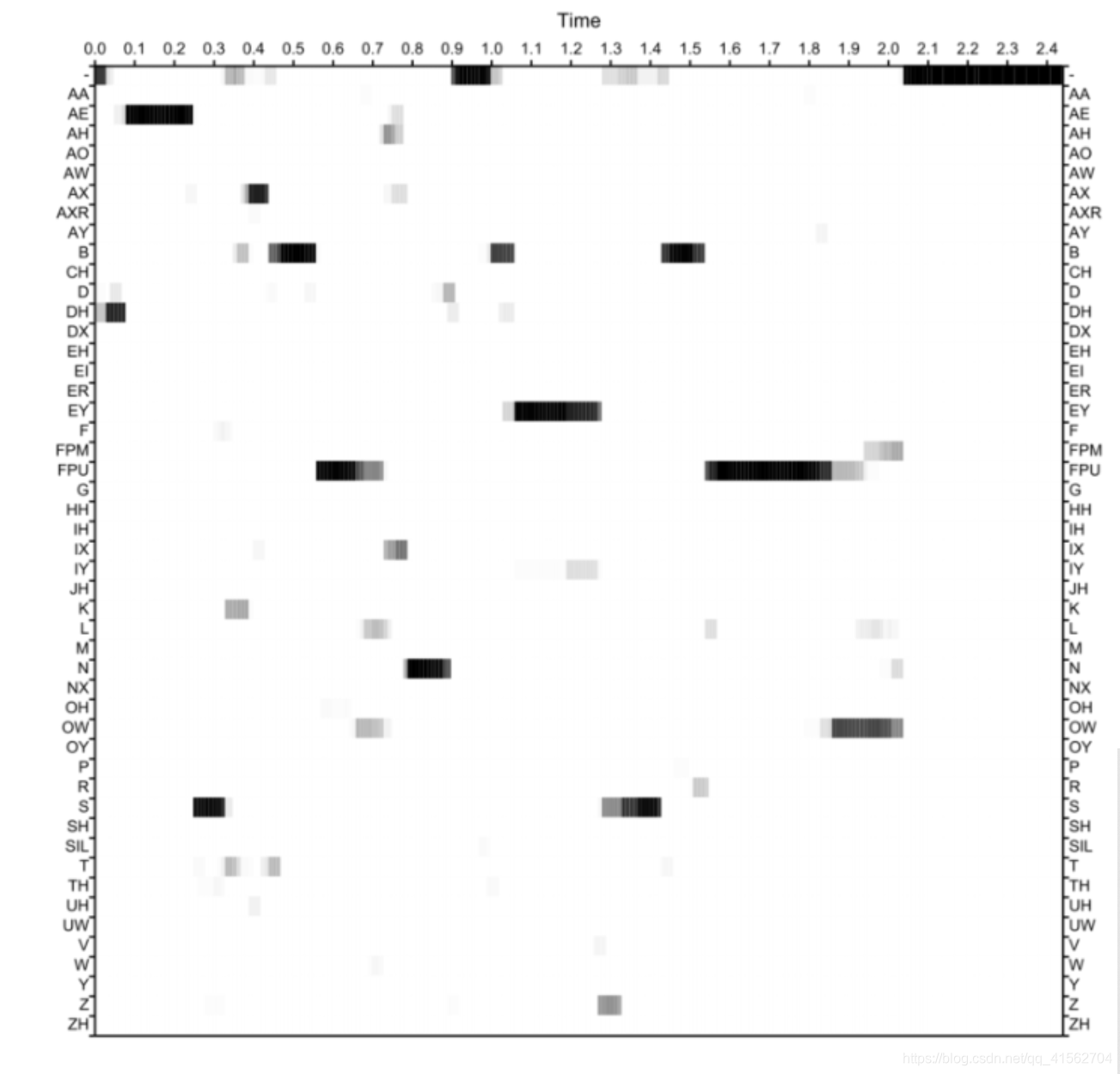
相关论文介绍
最早是在[2]中提出来,用于基于实例口语词检测查询。不过这边文章就PPG的生成并没有说太多,他提供了两种方案,一种是直接从每个时间帧的每个语音类的基于帧的声学似然分数中计算。另一种是可以运行使用声学和语音语言模型的完整语音识别器来生成点阵,并且可以直接从该点阵计算后验图。文章重点放在了PPG的后续处理,包括DTW,相似度计算。
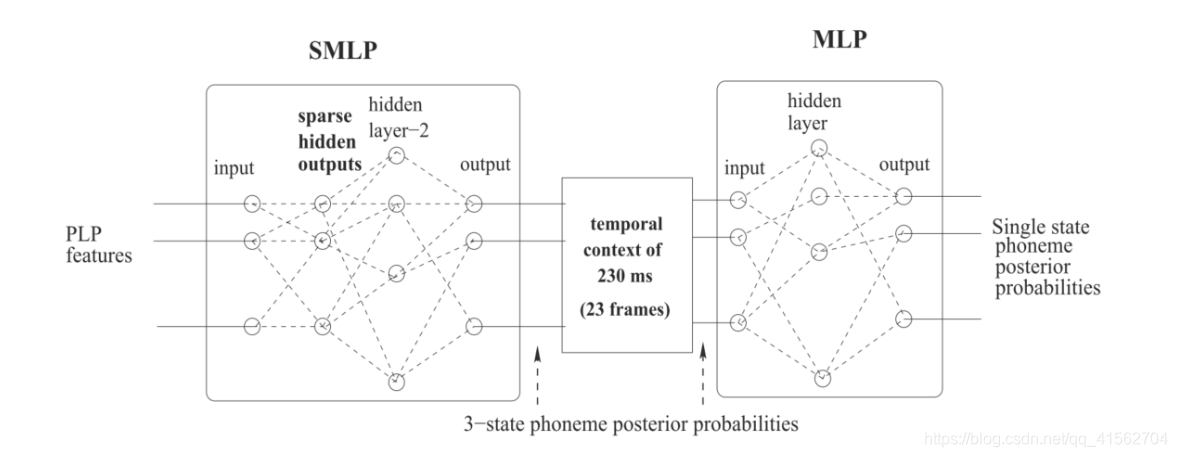
[3]发表在2011年的InterSpeech,提出用PPG来做选择最小语音事件集的任务。作者提出了两个系统来计算PPG。一种是基于GMM[4],对于给定的音素特征 使用GMM预估音素 的概率,再根据贝叶斯准则计算后验概率。对每一帧,音素特征x用的是标准的39维度(3*13)的MFCC和8 个混合分量(全协方差)。同时作者提出可以用稀疏多层感知机SMLP[5]替代GMM。在这个系统中,感知线性预测特征被呈现给一个 MLP,该 MLP 包括一个稀疏隐藏层和输出 3 状态音素后验概率。在训练期间通过使用稀疏正则化增加稀疏性。然后第二个 MLP 将 3状态 音素后验概率换为单状态音素后验概率。
[6]是第一个提出在SI-ASR任务上训练PPG提取模型的,作者在多说话人的ASR corpus数据集上进行训练。输入MFCC特征,对于语音帧x,计算音素集合中每个音素类别s的。作者吧senone作为音素类别,具体实验是在TIMIT数据集上,用Kaldi的语音识别工具搭建AI-ASR系统。该ASR系统包含4层1024个神经单元的隐藏层。由于ASR任务是与说话人无关的,PPG特征因而也是说话人无关的特征。
[7]在[6]的基础上,同样使用PPG作为context embedding,改进了说话人embedding的方式。本文的PPG同样是使用Kaldi中的ASR模型(本文使用nnet2),在LibriSpeech上进行训练。声学特征上使用的是40维的MCEPs
[8]也是针对说话人id特征进行改进,PPG提取特征与[6]一致,也是4层1024单元的隐藏层,使用13维的MFCC,MFCC的参数,汉明窗为25ms。
[9]首次提出双语PPG,是先分别英文和中文的ASR模型,两个ASR模型都是使用Kaldi工具,基于DNN-HMM搭建的,英文的ASR模型在WSJ数据集上训练,中文的ASR模型在AI-SHELL数据集上训练。英文的ASR模型包含5层的1024个神经单元的隐藏层,最终的softmax输出132个,中文的ASR模型包含6层的2048个神经单元的隐藏层,最终的softmax输出209个。最后将中文PPG特征和英文PPG特征堆叠即为341维度的双语特征。
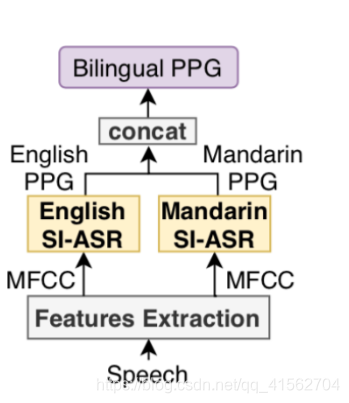
[10]同样是使用堆叠得到的双语PPG,将其用于TTS任务中,在PPG提取模块中,建立了两个基于SI-ASR的模型,分别在英文和中文的ASR数据集上训练,得到的英文PPG和中文PPG叠加起来作为双语PPG;英文和中文的ASR模型都是使用Kaldi,在TIMIT数据集和AI-SHELL数据集上进行训练的。输入数据都是窗口25ms的13维的MFCC。中文的ASR模型的输入加入了维度为3的pitch特征。英文的ASR模型有4层1024个神经单元的隐藏层,中文ASR模型有6层850个神经单元的隐藏层。维度分别为128和217,双语的PPG特征有345。
[11]是针对VC模型使用PPG的时候用WaveNet进行优化,PPG的提取同样也是在TIMIT数据集上用Kaldi的ASR识别,得到128维度的PPG特征。
[1]中在PPG提取模块做了以下几个改进,一是模型,ASR模型使用1维卷积+4层512个神经单元的隐藏层,输入的是40维度的filter-bank;二是多语言的问题,作者将单语言音素扩展到了多语言音素,直接训练得到双语PPG,数据集貌似不是公开的,而是使用的超过1000个说话人的包含中英文,总时长超过11000小时的混合数据集,
总结
状态级和帧级语音段可以在不同的语言中共享,PPG作为一种帧级特征是语言无关的。而PPG是从ASR任务中提取出来的,ASR是说话人无关,PPG也是一种说话人无关的特征。一般是在说话人无关语音识别任务上进行训练。
目前多数PPG提取模型基于DNN-HMM,GMM,也有用SMLP,常用的是Kaldi工具搭建AI-ASR系统。常用的数据集包括:英文数据集:LibriSpeech,TIMIT,WSJ;中文数据集:AI-SHELL
参考文献
[1] Huang H , Wu Z , Kang S , et al. Speaker Independent and Multilingual/Mixlingual Speech-Driven Talking Head Generation Using Phonetic Posteriorgrams[J]. 2020.
[2] Hazen T J , Shen W , White C . Query-by-example spoken term detection using phonetic posteriorgram templates[C]// IEEE Workshop on Automatic Speech Recognition & Understanding. IEEE, 2009.
[3] Kintzley K , Jansen A , Hermansky H . Event Selection from Phone Posteriorgrams Using Matched Filters[C]// INTERSPEECH 2011, 12th Annual Conference of the International Speech Communication Association, Florence, Italy, August 27-31, 2011. DBLP, 2011.
[4] Jun L U , Yang J A , Wang Y . An improved point process models for spotting keywords in continuous speech[J]. Journal of Circuits and Systems, 2013.
[5] Sivaram G , Hermansky H . Multilayer perceptron with sparse hidden outputs for phoneme recognition[C]// IEEE International Conference on Acoustics. IEEE, 2011.
[6] Sun L , Li K , Hao W , et al. Phonetic posteriorgrams for many-to-one voice conversion without parallel data training[C]// 2016 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2016.
[7] Mohammadi S H , Kim T . One-Shot Voice Conversion with Disentangled Representations by Leveraging Phonetic Posteriorgrams[C]// Interspeech 2019. 2019.
[8] Liu S , Zhong J , Sun L , et al. Voice Conversion Across Arbitrary Speakers Based on a Single Target-Speaker Utterance[C]// Interspeech 2018. 2018.
[9] Zhou Y , Tian X , Xu H , et al. Cross-lingual Voice Conversion with Bilingual Phonetic PosteriorGram and Average Modeling[C]// International Conference on Acoustic, Speech and Signal Processing (ICASSP). 2019.
[10] Cao Y , Liu S , Wu X , et al. Code-Switched Speech Synthesis Using Bilingual Phonetic Posteriorgram with Only Monolingual Corpora[C]// ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[11] Lu H , Wu Z , Li R , et al. A Compact Framework for Voice Conversion Using Wavenet Conditioned on Phonetic Posteriorgrams[C]// ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









