







分布式协调服务器 Zookeeper
最近在学习雷老师的zk课程,总结一下
1 Zookeeper 概述
1.1 Zookeeper 简介
ZooKeeper 由雅虎研究院开发,后来捐赠给了 Apache。 ZooKeeper 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 Paxos 算法的ZAB 协议完成的。其主要功能包括:配置维护、域名服务、分布式同步、集群管理等。
zookeeper 的官网: http://zookeeper.apache.org
1.2 一致性
1.2.1 顺序一致性
zk 接收到的 n 多个事务请求(写操作请求),最终会严格按照其接收顺序被应用到 zk中。
1.2.2 原子性
所有事务请求的结果在集群中每一台 zk 上的应用情况都是一致的。
1.2.3 单一视图
无论客户端连接的是 zk 集群中的哪个服务器,其看到的服务端数据模型都是一致的,即 zk 主机中的 znode 都是相同的,这样可以保证用户读取到的数据都是相同的。原子性是针对是写操作的,而单一视图是针对读操作的。
(当写事务进行时且未完成时,zk拒绝提供读服务,此时读会超时)
1.2.4 可靠性
一旦 zk 成功应用了一个事务,那么该事务所引起的 zk 状态变更(持久节点上的变更)将会被一直保留下来,除非有另一个事务又对其进行了变更。
1.2.5 最终一致性
一旦一个事务被成功应用, zk 可以保证在一段较短的时间后,客户端最终能够从 zk 上读取到最新的数据状态。但不能保证实时读取到。
Zk可视化工具zkInspector
1.3 理论基础
1.3.1 数据模型 znode
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cmOVgcUj-1663990334373)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.001.png)]](https://img-blog.csdnimg.cn/656e0f4ae80f41b0998f106186bb31e0.png)
zk 数据存储结构与标准的 Unix 文件系统非常相似,都是在根节点下挂很多子节点。 zk中没有引入传统文件系统中目录与文件的概念,而是使用了称为 znode 的数据节点概念。znode 是 zk 中数据的最小单元,每个 znode 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
zk 中虽然可以存放数据,但其主要作用并不是用于存储数据的,而是通过在不同时间创建不同关系、不同类型的 znode 节点,来描述和体现某种关系。每个 znode 节点可以存放数据的大小上限为 1M 字节。
节点类型
每个 znode 根据节点类型的不同,具有不同的生命周期。
持久节点:节点被创建后会一直保存在 zk 中,直到将其删除。
持久顺序节点:一个父节点可以为它的第一级子节点维护一份顺序,用于记录每个子节点创建的先后顺序。其在创建子节点时,会在子节点名称后添加数字序号,作为该子节点的完整节点名。 序号由 10 位数字组成,从 0 开始计数。
bj0000000000 sh0000000001
临时节点:临时节点的生命周期与客户端的会话绑定在一起,会话消失则该节点就会被自动清理。 临时节点只能作为叶子节点,不能创建子节点。
临时顺序节点:添加了创建序号的临时节点。
节点状态
l cZxid: Created Zxid,表示当前 znode 被创建时的事务 ID
l ctime: Created Time,表示当前 znode 被创建的时间
l mZxid: Modified Zxid,表示当前 znode 最后一次被修改时的事务 ID
l mtime: Modified Time,表示当前 znode 最后一次被修改时的时间
l pZxid: 表示当前 znode 的子节点列表最后一次被修改时的事务 ID。注意,只能是其子节点列表变更了才会引起 pZxid 的变更,子节点内容的修改不会影响 pZxid。
l cversion: Children Version,表示子节点的版本号。该版本号用于充当乐观锁。
l dataVersion:表示当前 znode 数据的版本号。该版本号用于充当乐观锁。
l aclVersion:表示当前 znode 的权限 ACL 的版本号。该版本号用于充当乐观锁。
l ephemeralOwner:若当前 znode 是持久节点,则其值为 0;若为临时节点,则其值为创建该节点的会话的 SessionID。当会话消失后,会根据 SessionID 来查找与该会话相关的临时节点进行删除。
l dataLength:当前 znode 中存放的数据的长度。
l numChildren:当前 znode 所包含的子节点的个数。
1.3.2 Watcher机制
zk 通过 Watcher 机制实现了发布/订阅模式。
Watcher工作原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rlq7OKp8-1663990334374)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.002.png)]](https://img-blog.csdnimg.cn/0b86a6d8680b486ab33ec87990a80e94.png)
Watcher事件
对于同一个事件类型,在不同的通知状态中代表的含义是不同的。
| 客户端所处状态 | 事件类型(常量值) | 触发条件 | 说明 |
|---|---|---|---|
SyncConnected | None(-1) | 客户端与服务器成 功建立会话 | 此时客户端与服务器处于连接状态 |
| NodeCreated(1) | Watcher 监听的对 应数据节点被创建 | ||
| NodeDeleted(2) | Watcher 监听的对 应数据节点被删除 | ||
NodeDataChanged(3) | Watcher 监听的对 应数据节点的数据内容发生变化 | ||
NodeChildrenChanged(4) | Watcher 监听的节点的子节点列表发 生变化 | ||
| Disconnected(0) | None(-1) | 客户端与zk 断开连 接 | 此时客户端与服务器处 于连接断开状态 |
Expired(-112) | None(-1) | 会话失效 | 此时客户端会话失效, 通 常 会 收 到SessionExpiredException 异常 |
AuthFailed | None(-1) | 使用错误的 scheme 进行权限检查 | 通 常 会 收 到 AuthFailedException |
Watcher特性
zk 的 watcher 机制具有非常重要的三个特性:
一次性:一旦一个 watcher 被触发, zk 就会将其从客户端的 WatchManager 中删除, 当然也就会从服务端删除。 当需要再使用时客户端需要再向 zk 重新注册 watcher。
串行性:同一 znode 的相同事件类型所引发的 watcher 回调方法的执行是串行的,同步的。(耗时IO可能引起数据丢失,来不及重新注册watcher)
轻量级:客户端向服务端注册 watcher,并没有将整个 watcher 实例发送到服务端,而是向服务端发送了 watcher 中的部分必要数据。 watcher 实例及回调逻辑仍是存放在客户端的。这是一种轻量级设计。
zk 的 watcher 机制不适合监听变化非常频繁的场景,也不适合在 watcher 回调中进行耗时 IO 型操作。
kafka 的 Consumer 的消费offset 在 0.8 版本之前是保存在 zk 中,而之后的版本是保存在 broker 中。
2 Zookeeper 典型应用场景解决方案
2.1 配置维护
2.2.1 what
分布式系统中,很多服务都是部署在集群中的,即多台服务器中部署着完全相同的应用,起着完全相同的作用。当然,集群中的这些服务器的配置文件是完全相同的。若集群中服务器的配置文件需要进行修改,那么我们就需要逐台修改这些服务器中的配置文件。如果我们集群服务器比较少,那么这些修改还不是太麻烦,但如果集群服务器特别多,比如某些大型互联网公司的 Hadoop 集群有数千台服务器,那么纯手工的更改这些配置文件几乎就是一件不可能完成的任务。即使使用大量人力进行修改可行,但过多的人员参与,出错的概率大大提升,对于集群所形成的危险是很大的。同类产品还有 Spring Cloud Config、 Nacos Config、 Apollo 等。
2.2.2 实现原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Y1Gzx42-1663990334375)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.003.png)]](https://img-blog.csdnimg.cn/6cb710ef7c554d55a6ad0e156385e328.png)
zk 可以通过“发布/订阅模型”实现对集群配置文件的管理与维护。
2.2 命名服务
2.2.1 what
命名服务是指可以为一定范围内的元素命名一个唯一标识,以与其它元素进行区分。在分布式系统中被命名的实体可以是集群中的主机、服务地址等。
UUID、 GUID,其存在的明显问题有两个:长度太长,无语义。
2.2.2 实现原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lPl57gXu-1663990334375)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.004.png)]](https://img-blog.csdnimg.cn/62710b92835c4be8979d756b06e82a51.png)
通过利用 zk 中节点路径不可重复的特点来实现命名服务的。当然,也可以配带上顺序节点的有序性来体现唯一标识的顺序性。
2.3 集群管理
2.3.1 what
对于集群,我们总是希望能够随时获取到当前集群中各个主机的运行时状态、当前集群中主机的存活状况等信息。通过 zk 可以实现对集群的随机监控。
2.3.2 分布式日志收集系统
下面以分布式日志收集系统为例来分析 zk 对于集群的管理。
系统组成
首先要清楚,分布式日志收集系统由四部分组成:日志源集群、日志收集器集群, zk集群,及监控系统。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QvVckSUQ-1663990334376)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.005.png)]](https://img-blog.csdnimg.cn/b3ac027d37b24d80b62a8135c658455c.png)
系统工作原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ftY3Q1Hb-1663990334376)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.006.png)]](https://img-blog.csdnimg.cn/fb7e4796aa6f47a6a063c31146a5ea6b.png)
利用临时节点的性质,会话在,临时节点在。collector1 创建持久节点后立刻创建一个自己的临时节点,监听自己的状态
分布式日志收集系统的工作步骤有以下几步:
A 收集器的注册
在 zk 上创建各个收集器对应的节点。
B 任务分配
系统根据收集器的个数,将所有日志源集群主机分组,分别分配给各个收集器。
C 状态收集
这里的状态收集指的是两方面的收集:
l 日志源主机状态,例如,日志源主机是否存活,其已经产生多少日志等
l 收集器的运行状态,例如,收集器本身已经收集了多少字节的日志、当前 CPU、内存的使用情况等
D 任务再分配 Rebalance
当出现收集器挂掉或扩容,就需要动态地进行日志收集任务再分配了,这个过程称为Rebalance。只要发现某个收集器挂了,则系统进行任务再分配。
l 全局动态分配:简单粗暴,但对系统性能的影响非常巨大。一般不会使用。
l 局部动态分配:需要首先定义各个收集器的负载判别标准,根据负载情况进行再分配。
2.3.3 集群管理的一般性原理
zk 进行集群管理的一般性原理如下图所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HqyVfZMI-1663990334376)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.007.png)]](https://img-blog.csdnimg.cn/f1eebddd26fc4821be11c7a2d6975f41.png)
2.4 DNS服务
zk 的 DNS 服务的功能主要是实现消费者与提供者的解耦合。可以防止提供者的单点问题,实现对提供者的负载均衡等。
2.4.1 what
DNS,Domain Name System,域名系统,即可以将一个名称与特定的主机 IP+Port 进行绑定。zk 可以充当 DNS 的作用,完成域名到地址的映射。
2.4.2 基本DNS实现原理
假设提供者应用程序 app1 与 app2 分别用于提供 service1 与 service2 两种服务,现要将其注册到zk 中,具体的实现原理如下图所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iNu44eAL-1663990334376)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.008.png)]获取微服务的ip地址](https://img-blog.csdnimg.cn/4bbe9a45e5134d2289511b500d01f31f.png)
2.4.3 具有状态收集功能的 DNS 实现原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E2RDjtGe-1663990334377)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.009.png)]](https://img-blog.csdnimg.cn/81da7f6cd51a4288b8f942bc1daa61b3.png)
以上模型存在一个问题,如何获取各个提供者主机的健康状态、运行状态呢?可以为每一个域名节点再添加一个状态子节点,而该状态子节点的数据内容则为开发人员定义好的状态数据。这些状态数据是如何获取到的呢?是通过状态收集器(开发人员自行开发的)定期写入到 zk 的该节点中的。
阿里的 Dubbo 就是使用 Zookeeper 作为域名服务器的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hMo4AZV7-1663990334377)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.010.png)]](https://img-blog.csdnimg.cn/31098db5579b4a7eb71947704c3b26a4.png)
2.4.4 对方案的优化
前面的方案无法对提供者的存活状态进行实时监控。
还是临时节点,利用临时节点的属性
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yv65l871-1663990334377)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.011.png)]](https://img-blog.csdnimg.cn/bab9546bf124432991c1ccdbd46672be.png)
需要获取微服务时,只需要读取对应微服务的全部临时子节点
2.5 master选举
主从:主从都在工作,大多数时候主负责读写,从只负责读。(热备:实时性备份)
主备:只有主在工作,备只负责定时备份(冷备)
2.5.1 what
集群是分布式系统中不可或却的组成部分,是为了解决分布式系统中计算单元的单点问题,水平扩展计算单元的处理能力的一种解决方案。
一般情况下,会在群集中选举出一个 Master,用于协调集群中的其它 Slave 主机,对于Slave 主机的状态具有决定权。
2.5.2 广告推荐系统
1 需求
系统会根据用户画像,将用户归结为不同的种类。系统会为不同种类的用户推荐不同的广告。每个用户前端需要从广告推荐系统中获取到不同的广告 ID。
2 分析
这个向前端提供服务的广告推荐系统一定是一个集群,这样可以更加快速高效的为前端进行响应。需要注意,推荐系统对于广告 ID 的计算是一个相对复杂且消耗 CPU 等资源的过程。如果让集群中每一台主机都可以执行这个计算逻辑的话,那么势必会形成资源浪费,且降低了响应效率。此时,可以只让其中的一台主机去处理计算逻辑,然后将计算的结果写入到某中间存储系统(DB/DFS)中,并通知集群中的其它主机从该中间存储系统中共享该计算结果。那么,这个运行计算逻辑的主机就是 Master,而其它主机则为 Slave。
3 架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sND5p6gr-1663990334378)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.012.png)]](https://img-blog.csdnimg.cn/6cc1254d0fbd448a808ad46cb75dee3c.png)
1 slave缓存查用户对应的推荐广告ID
2 没有slave通知master,计算对应用户的推荐广告ID,写入中间存储系统
3 slave查缓存,返回
4 选举
这个广告推荐系统集群中的Master 是如何选举出来的呢?使用 zk 可以完成。使用 zk中多个客户端对同一节点创建时,只有一个客户端可以成功的特性实现。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X76pQjS0-1663990334378)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.013.png)]](https://img-blog.csdnimg.cn/302148bbcdc945aa9ca2a413bf0b34c1.png)
抢注master,发现已经有了master就传回master地址,同时监听master这个临时节点的状态
使用DBMS 是否也可以实现 Master 选举?当然可以。让所有集群 server 向同一张表中同时写入同一个主键的数据,只有一个可以写入成功。成功的就是 Master。但 Master 宕机无法实现 Master 的自动重新选举。
例如Kafka 集群中 Broker Controller 就是集群中的 Master,就是通过 zk 选举的。Broker 中的 partition 分区中的 leader 是由Broker Controller 负责选举的。
2.6 分布式同步
2.6.1 分布式同步
分布式同步,也称为分布式协调,是分布式系统中不可缺少的环节,是将不同的分布式组件有机结合起来的关键。对于一个在多台机器上运行的应用而言,通常需要一个协调者来控制整个系统的运行流程,例如执行的先后顺序,或执行与不执行等。
***2.6.2 MySql数据复制总线
下面以“MySQL 数据复制总线”为例来分析 zk 的分布式同步服务。
1 数据复制总线组成
MySQL 数据复制总线是一个实时数据复制框架,用于在不同的 MySQL 数据库实例间进行异步数据复制。其核心部分由三部分组成:生产者、复制管道、消费者。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v6Y2u7eW-1663990334378)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.014.png)]](https://img-blog.csdnimg.cn/b8b43ae2139c42fa88331ccc86c607dc.png)
复制管道其实也是一个服务器,从metadataSvr中读取双方数据库的用户名密码,表同步字段。读主写从。
MySQL自带这些功能,但是replicator实际是单节点的。而且要求主从两个结构要一致。
使用zk后,自定义创建多个节点,这时的主从甚至可以是异构的,读sql写redis等等。
MySQL 数据复制总线系统中哪里需要使用 zk 的分布式同步功能呢?以上结构中可以显示看到存在的问题:replicator 存在单点问题。为了解决这个问题,就需要为其设置多个热备主机(replicator)。那么,这些热备主机是如何协调工作的呢?这时候就需要使用 zk 来做协调工作了,即由zk 来完成分布式同步工作。
2 数据复制总线工作原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HQRFNZ24-1663990334378)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.015.png)]](https://img-blog.csdnimg.cn/4407f4be8a6045119ff064eb2226852d.png)
- replicator1/2 先去对应的pay_record节点下注册instances的临时顺序子节点 host1-01,host-02
- 协调者应用监听instances子节点变化事件,会选出一个replicator作为工作主机,其他机器做热备,并将状态写入status
- replicator1/2监听status节点变化事件,各个replicatir知道自己是主是从,开始工作。
A 复制任务注册
复制任务注册实际就是指不同的复制任务在 zk 中创建不同的 znode(pay_record/order_record),即将复制 任务注册到 zk 中。
B replicator热备
复制任务是由 replicator 主机完成的。为了防止 replicator 在复制过程中出现故障,replicator 采用热备容 灾方案, 即将同一个复制任务部署到多个不同的 replicator 主机上,但仅使一个处于 RUNNING 状态,而 其它的主机则处于 STANDBY 状态。当 RUNNING 状态的主机出现故障,无法完成复制任务时,使某一个 STANDBY 状态主机转换为 RUNNING 状态,继续完成复制任务。
C 主备切换
当 RUNNING 态的主机出现宕机,则该主机对应的子节点马上就被删除了,然后在当前处于 STANDBY 状态中的 replicator 中找到序号最小的子节点,然后将其状态马上修改为RUNNING,完成“主备切换”。
2.7 分布式锁
分布式锁是控制分布式系统同步访问共享资源的一种方式。Zookeeper 可以实现分布式锁功能。根据用户操作类型的不同,可以分为排他锁(写锁)与共享锁(读锁)
2.7.1 分布式锁的实现
在 zk 上对于分布式锁的实现,使用的是类似于“/xs_lock/[hostname]-请求类型-序号” 的临时顺序节点。当客户端发出读写请求时会在 zk 中创建不同的节点。根据读写操作的不同及当前节点与之前节点的序号关系来执行不同的逻辑。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hGVbtYfK-1663990334379)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.016.png)]](https://img-blog.csdnimg.cn/90b504d5b51544f7bf710ba50b91b67d.png)
具体实现步骤:
Step1:当一个客户端向某资源发出读/写操作请求时,其首先会尝试着在zk中创建一个根节点。当然,若其不是第一个请求,则该根节点已经创建完毕,就无需再创建了。
Step2:根节点已经存在了,客户端会对根节点注册子节点列表变更事件的watcher监听,随时监听子节点的变化情况。
Step3: watcher注册完毕后,其会在根节点下创建一个读写操作的临时顺序节点。读写操作的顺序性就是通过这些子节点的顺序性体现的。每个节点都只关心序号比自己小的节点。因为它们的请求是先于自己提出的,需要先执行。注意,读写操作创建的节点名称是不同的:
若当前为读请求,则会创建一个“hostname-R-序号”的子节点
若当前为写请求,则会创建一个“hostname-W-序号”的子节点
Step4:节点创建完后,其就会触发客户端的watcher回调,读取根节点下的所有子节点列表,然后会查看序号比自己小的节点,并根据读写操作的不同,执行不同的逻辑。
- 读请求:若没有比自己序号小的子节点,或所有比自己序号小的子节点都是读请求,则表明自己可以开始读数据了;若比自己序号小的子节点中有写请求,则当前客户端不能对数据进行读操作,而是进入等待状态,等待前面的写操作执行完毕。
- 写请求:若发现自己是序号最小的子节点,则表明当前客户端可以开始数据更新了:若发现还有比自己序号更小的子节点,无论是读还是写节点,当前客户端都不能对数据进行写操作,而是进入等待状态,等待前面的所有操作执行完毕。
Step5:客户端操作完毕后,与zk的连接断开,则zk中该会话对应的节点消失。当然,该操作会引发各个客户端再次执行watcher回调,查看自己是否可以执行操作了。
2.7.2 分布式锁的改进
前面的实现方式存在“惊群效应”,为了解决其所带来的性能下降,可以对前述分布式锁的实现进行改进。
实际生产中有10台主机后,大概率惊群
由于一个操作而引发了大量的低效或无用的操作的执行,这种情沉称为惊群效应。当客户端请求发出后,在z水中创建相应的临时顺序节点后马上获取当前的/xs lock的所有子节点列表,但任何客户端都不向/xs lock注册用于监听子节点列表变化的watcher。而是改为根据请求类型的不同向“对其有影响的”子节点注册watcher。
- 读请求:若其前面都是读请求节点,则直接开始读操作:若其前面有写请求节点,其只需向序号小于自己的最后一个写请求节点注册“节点删除”watcher, 然后等待。
- 写请求:若其查看到自己就是序号最小的节点,则直接开始写操作:若发现还有更小的节点,则其只需向序号小于自己的最后一个节点注册“节点删除”watcher, 然后等待。
2.8 分布式队列
说到分布式队列,我们马上可以想到 RabbitMQ、 Kafka 等分布式消息队列中间件产品。zk 也可以实现简单的消息队列。
2.8.1 FIFO队列
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vrahwr2A-1663990334380)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.017.png)]](https://img-blog.csdnimg.cn/99f6b3f2806a436db3905cd3e8d94cb8.png)
zk 实现 FIFO 队列的思路是:利用顺序节点的有序性,为每个数据在 zk 中都创建一个相应的节点。然后为每个节点都注册 watcher 监听。一个节点被消费,则会引发消费者消费下一个节点,直到消费完毕。
2.8.2 分布式屏障Barrier队列
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QARA5gc5-1663990334380)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.018.png)]](https://img-blog.csdnimg.cn/c694873a2d4f4a6b9044a81d83ff5652.png)
Barrier,屏障、障碍物。 Barrier 队列是分布式系统中的一种同步协调器,规定了一个队列中的元素必须全部聚齐后才能继续执行后面的任务,否则一直等待。其常见于大规模分布式并行计算的应用场景中:最终的合并计算需要基于很多并行计算的子结果来进行。
zk 对于 Barrier 的实现原理是,在 zk 中创建一个/barrier 节点,其数据内容设置为屏障打开的阈值,即当其下的子节点数量达到该阈值后, app 才可进行最终的计算,否则一直等待。每一个并行运算完成,都会在/barrier 下创建一个子节点,直到所有并行运算完成。
3 Zookeeper的安装和集群搭建
3.1 单机zk
Bin解压目录下有conf
./zkServer.sh start
./zkServer.sh status
./zkServer.sh stop
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial 初始化同步阶段所用tick
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper /usr/data/zookeeper
# the port at which the clients will connect
clientPort=21811
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to “0” to disable auto purge feature
autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
4lw.commands.whitelist=* //开启四字命令
常用的四字命令
| 命令 | 用法示例 | 描述 |
|---|---|---|
| conf | echo conf | nc localhost 2181 |
| cons | echo cons | nc localhost 2181 |
| crst | echo crst | nc localhost 2181 |
| dump | echo dump | nc localhost 2181 |
| envi | echo envi | nc localhost 2181 |
| ruok | echo ruok | nc localhost 2181 |
| srst | echo srst | nc localhost 2181 |
| srvr | echo srvr | nc localhost 2181 |
| stat | echo stat | nc localhost 2181 |
| wchs | echo wchs | nc localhost 2181 |
| wchc | echo wchc | nc localhost 2181 |
| wchp | echo wchp | nc localhost 2181 |
| mntr | echo mntr | nc localhost 2181 |
3.2搭建会动态扩缩容的 ZK 集群
对于单机 Zookeeper,存在单点故障问题,系统的安全性降低。 Zookeeper 在生产场景中一般是以集群的形式出现的。
3.2.1 集群说明
下面要搭建一个由四台 zk 构成的 zk 集群,其中一台为 Leader,两台 Follower,一台Observer。从 Zookeeper3.5.0 版本开始, zk 集群可以实现在无需重启集群的情况下动态的扩容与缩容。这是新版 zk 与之前相比最大的区别与优势。我们要搭建的集群就可以实现该功能。
2. ### 克隆第一台主机
- 克隆主机
Vim /etc/hostname //修改主机名
Vim /etc/sysconfig/network-scripts/ifcfg-ens33 //修改主机对应ip,再虚拟机外的主机上创建了ip和主机名的映射
- 删除无效数据
克隆前面的 zookeeperOS 主机,并命名为 zookeeperOS1。 进入 zookeeperOS1 的/usr/data/zookeeper 目录中,将其中的所有内容全部删除,因为这些内容全部都是原母版 zk的,与集群主机没有关系。
- 创建myid文件
在/usr/data/zookeeper 目录中创建表示当前主机编号的 myid 文件,该编号为当前主机在集群中的唯一标识。
echo 1 > myid
- 定义zoo.cfg.dynamic
在 conf 目录中定义一个配置文件,名称可以随意,不过,一般为 zoo.cfg.dynamic。这是配置内容的动态部分,是一个动态配置文件。其内容就是指定集群中各个节点信息。2888客户端连接端口号,3888选举端口号。
server.1=192.168.59.167:2888:3888
server.2=192.168.59.168:2888:3888
server.3=192.168.59.169:2888:3888
server.4=192.168.59.170:2888:3888:observer
- 修改zoo.cfg
skipACL=yes
reconfigEnabled=true
dynamicConfigFile=/opt/apps/apache-zookeeper-3.7.0-bin/conf/zoo.cfg.dynamic
dynamicConfigFile 中指定的文件路径,最好使用绝对路径。
3.3.2 克隆并配置另外两台主机
克隆并配置另外两台主机的方式是相同的。
- 克隆主机
克隆三台前面 zookeeperOS1 主机,并命名为 zookeeperOS2、zookeeperOS3 与zookeeperOS4,并修改主机名与 ip。
- 修改myid
修改 myid 的值与 zoo.cfg 中指定的主机编号相同。
[root@zookeeperos2 ~] echo 2 > /usr/data/zookeeper/myid
[root@zookeeperos3 ~] echo 3 > /usr/data/zookeeper/myid
[root@zookeeperos4 ~] echo 4 > /usr/data/zookeeper/myid
3.2.4 集群动态扩容
这里要在原集群不重启的情况下动态增加一台新的Server,zookeeperOS5。
克隆并配置主机
克隆 zookeeperOS1 主机,并命名为zookeeperOS5,并修改主机名与 ip
修改myid为5
修改 zoo.cfg.dynamic
修改动态配置文件 zoo.cfg.dynamic:增加上当前 server 的信息
server.1=192.168.59.167:2888:3888
server.2=192.168.59.168:2888:3888
server.3=192.168.59.169:2888:3888
server.4=192.168.59.170:2888:3888:observer
server.5=192.168.59.171:2888:3888
修改zoo.cfg
skipACL=yes
reconfigEnabled=true
dataDir=/usr/data/zookeeper
syncLimit=5
tickTime=2000
41w.commands.whitelist=*
initLimit=10
dynamicConfigFile=/opt/apps/apache-zookeeper-3.7.0-bin/conf/zoo.cfg.dynamic
运行reconfig命令
在原来集群中任意 server 中运行 zkCli.sh 命令,打开客户端。然后运行reconfig –add 命令,将新的配置信息添加到原集群中的所有动态配置文件中。
[zk:localhost:2181(CONNECTED) 0] reconfig -add 5=192.168.59.171:2888:3888;2181
Committed new configuration:
server.1=192.168.59.167:2888:3888:participant
server.2=192.168.59.168:2888:3888:participant
server.3=192.168.59.169:2888:3888:participant
server.4=192.168.59.170:2888:3888:observer
server.5=192.168.59.171:2888:3888:participant;0.0.0.0:2181
version=400000008
启动5号机
zkServer.sh start
3.2.5 集群动态缩容
动态缩容与动态扩容过程类似。不同的是,运行的reconfig命令为(动态删除5号server):reconfig –remove 5然后直接将 5 号机停掉即可。这时的集群 server 满员数量即为 4 台,而不是由 5 台满员宕机一台的情况。
3.3 老版zk的在线扩容
在线扩容即不影响 zk 集群可用性的前提下进行的扩容,但这种扩容不能称为动态扩容。因为这种扩容方式需要将原集群中的所有 server 全部逐个重新配置并重启。所以, 这种在线扩容也称为“滚动重启式”扩容。
假设原集群中包含三台 zk,它们的 zoo.cfg 中配置了这三台的 server 地址:
server.1=…
server.2=…
server.3=…
现在要扩容一台主机。配置该 server 的 zoo.cfg 中的 server 地址为:
server.1=…
server.2=…
server.3=…
server.4=…
配置好第四台后,直接启动第四台。通过 mntr 命令可以看到集群已经包含四台 server了。
修改原集群中的某台 server 的配置文件,将扩容的第四台 server 地址添加到其中。然后restart 该 server。再将原集群中的其它 server 按照上述方式逐个重新配置、重启。不过,在配置并重启过程中,最好将原 Leader 放到最后一台配置重启。
4 Zookeeper客户端
4.1 客户端命令
4.1.1 启动客户端
1 连接本机服务器 zkcli.sh
2 连接其他zk服务器 zkc1i.sh -server 192.168.59.117:2181
4.1.2 查看子节点
[zk:localhost:2181(CONNECTED)6] ls
[china,zookeeper]
4.1.3 创建子节点
1 创建持久节点china值999 create /china 999
2 创建持久顺序节点 create -s /china/bj beijing
[zk:localhost:2181(CONNECTED)2] ls /china
bj0000000000,sh0000000001]
3创建临时节点 create –e /china/gz guagnzhou
4创建临时顺序节点 create -e –s /china/gz guangzhou
4.1.4 获取节点信息-get
get /china
4.1.5 更新节点数据内容-set
4.1.6 删除节点 –delete
临时节点客户端退出时就消失
4.1.7 ACL理论
(1) ACL简介
ACL 全称为 Access Control List(访问控制列表),是一种细粒度的权限管理策略,可以针对任意用户与组进行细粒度的权限控制。 zk 利用 ACL 控制 znode 节点的访问权限,如节点数据读写、节点创建、节点删除、读取子节点列表、设置节点权限等。
(2) ACL与UGO对比
Linux 系统采用的权限控制机制是 UGO(User、 Group、 Other)。 UGO 是一种粗粒度的文件系统权限控制模式,其只能对这三类用户进行权限设置。 例如,若要对李四用户进行权限设置,李四与当前的创建者不是同组,但也不是 Other(Other 中包含王五、赵六等,但不包含李四)。那么使用 UGO 是无法进行设置的,但使用 ACL 是可以的。
(3) zk的acl维度
目前大多数 Unix 已经支持了 ACL, Linux 也从 2.6 版本开始支持了 ACL。 Unix/Linux 系统的 ACL 分为两个维度:组与权限,且目录的子目录或文件能够继承父目录的 ACL 的。而Zookeeper 的 ACL 分为三个维度:授权策略 scheme、授权对象 id、用户权限 permission, 子znode 不会继承父 znode 的权限。
授权策略scheme
授权策略用于确定权限验证过程中使用的检验策略(简单来说就是,通过什么来验证权限,如何验证其身份),在 zk 中最常用的有四种策略。
IP:根据 IP 地址进行权限验证。
digest:根据用户名与密码进行验证。
world:对所有用户不做任何验证。 但有些系统节点是不能操作的。
super:超级用户可以对任意节点进行任意操作。
授权对象id
授权对象指的是权限赋予的用户。不同的授权策略具有不同类型的授权对象。下面是各个授权模式对应的授权对象 id。
ip:授权对象是 IP 地址。
digest:授权对象是“用户名 + 密码”。
world:其授权对象只有一个,即 anyone。
Super:与 digest 相同,授权对象为“用户名 + 密码”。
权限 Permission
权限指的是通过验证的用户可以对 znode 执行的操作。共有五种权限,不过 zk 支持自定义权限。
c: Create,允许授权对象在当前节点下创建子节点。
d: Delete,允许授权对象删除当前节点。
r: Read,允许授权对象读取当前节点的数据内容,及子节点列表。
w:Write,允许授权对象修改当前节点的数据内容,及子节点列表。
a: Acl,允许授权对象对当前节点进行 ACL 相关的设置。
4.1.8 ACL操作
1 查看权限getAcl
getAcl /china
[zk: localhost:2181(CONNECTED) 2] getAcl /china
-
'world,'anyone
- cdrwa
2 设置权限
下面的命令是,首先增加了一个认证用户 zs,密码为 123,然后为/china 节点指定只有zs 用户才可访问该节点,而访问权限为所有权限。
[zk:localhost:2181(CONNECTED)7] addauth digest zs:123
[zk:localhost:2181(CONNECTED)8] setAcl /china auth:zs:123:cdrwa
cZxid 0x14a
ctime wed Jan 30 20:42:16 CST 2019
mZxid 0x15d
mtime Thu Jan 31 16:18:24 CST 2019
pZxid 0x15e
cversion 12
dataversion 1
aclversion 1
ephemeralowner 0x0
dataLength 3
numchildren 2
下次再登录时还要addauth digest zs:123才能查看china节点,但是china下的子节点可以查看,子不继承父的权限
4.2 可视化客户端
zk 常见的可视化客户端有两个: ZooView 与 ZooInspector。
4.6 会话管理
会话是 zk 中最重要的概念之一,客户端与服务端之间的任何交互操作都是在建立了会
话的前提之下的。
ZooKeeper 客户端启动时,首先会与 zk 服务器建立一个 TCP 长连接。连接一旦建立,客
户端会话的生命周期也就开始了。
4.6.1 会话状态
常见的会话状态有三种:
l CONNECTING:连接中。 Client 要创建一个连接,其首先会在本地创建一个 zk 对象,用
于表示其所连接上的 Server。
l CONNECTED:已连接。连接成功后,该连接的各种临时性数据会被初始化到 zk 对象中。
l CLOSED:已关闭。连接关闭后,这个代表 Server 的 zk 对象会被删除。
连接时的两次shuffle
客户端连接集群中的server时,先对server集群做第一次shuffle,
对获取到的地址(一个hostname可能对应多个ip)进行再次处理:
获取到hostname.对应的所有ip,进行第二次shuffle,并返回shuflle.过后,第一个ip构成的地址
4.6.3 会话连接超时管理-客户端维护
zk 客户端维护着会话超时管理,主要管理的超时有两类: 连接超时与读超时。当客户端发出连接请求后,长时间没有收到服务端的连接成功 ACK,此时发生连接超时;连接成功后,当客户端长时间没有收到服务端的请求响应或心跳响应时,会发生读超时。
4.6.4 会话连接事件
客户端与服务端连接成功后并不是一成不变的,也会出现一些问题,比较典型的有以下三种:
1 连接丢失
因为网络抖动等原因导致客户端长时间收不到服务端的心跳回复,客户端就会导致连接丢失(即前面讲的会话超时)。连接丢失会引发客户端自动从 zk 地址列表中逐个尝试重新连接,直到重连成功,或按照指定的重试策略终止。
2 会话转移
当发生连接丢失后,客户端又以原来的 sessionId 重新连接上了服务器。若重连上的服务器不是原来的服务器, 那么客户端就需要更新本地 zk 对象中的相关信息,例如连接上的Server 的 IP 地址。这就是会话转移。
3 会话失效
若客户端连接丢失后,在会话超时范围内没有连接上服务器,则服务器会将该会话从会话列表中删除。在服务端将某客户端的会话删除后,该客户端仍使用原来的 sessionId 又重新连接上了服务器。那么服务器会给客户端发送一个连接关闭响应,表示这个会话已经失效。客户端在收到响应后会根据配置,要么关闭连接,要么重新发起新的会话 id 的连接。
4.6.5 会话空闲超时管理-服务器维护
服务器为每一个客户端的会话都记录着上一次交互后空闲的时长,及从上一次交互结束开始会话空闲超时的时间点。一旦空闲时长超时,服务端就会将该会话的 SessionId 从会话列表中清除。这也就是为什么客户端在空闲时需要定时向服务端发送心跳,就是为了维护这个会话长连接的。服务器是通过空闲超时管理来判断会话是否发生中断的。服务端对于会话空闲超时管理,采用了一种特殊的方式——分桶策略。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g3fP4RWh-1663990334382)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.019.png)]](https://img-blog.csdnimg.cn/ef44b929143c485c83347c7d59ea536d.png)
以map管理
expiryMap
是会话桶集合,其value为会话桶(Set集合),key为该会话桶id(其表示的时间范围的最大边界值)
elemMap
elemMap集合的key为session,value为该session的过期时间
-
/*
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
package org.apache.zookeeper.server;
-
import org.apache.zookeeper.common.Time;
-
import java.io.PrintWriter;
-
import java.util.ArrayList;
-
import java.util.Collections;
-
import java.util.Map;
-
import java.util.Set;
-
import java.util.concurrent.ConcurrentHashMap;
-
import java.util.concurrent.atomic.AtomicLong;
-
/**
-
-
-
-
-
public class ExpiryQueue {
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
}
apache-zookeeper-3.7.0\zookeeper-server\src\main\java\org\apache\zookeeper\server\SessionTrackerImpl.java
单起一个线程,去定期回收过期session
5 一致性算法详解
5.1 CAP定理
5.1.1简介
CAP 定理指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
一致性(C):分布式系统中多个主机之间是否能够保持数据一致的特性。即,当系统数据发生更新操作后,各个主机中的数据仍然处于一致的状态。
可用性(A):系统提供的服务必须一直处于可用的状态,即对于用户的每一个请求,系统总是可以在有限的时间内对用户做出响应。
分区容错性(P):分布式系统在遇到任何网络分区故障时,仍能够保证对外提供满足一致性或可用性的服务。
5.1.2 定理
CAP 定理的内容是:对于分布式系统,网络环境相对是不可控的,出现网络分区是不可避免的,因此系统必须具备分区容错性。但系统不能同时保证一致性与可用性。即要么 CP,要么 AP。
为什么不能同时保证一致性与可用性?
是因为数据同步是需要时间的。在同步期间,若允许 client 访问,则 client 从不同节点读取到的数据就可能是不相同的,即牺牲了一致性保证了可用性;若不允许 client 访问,则client 在同步期间无法获取服务,但一段时间后再访问系统,无论访问到的是哪个节点,读取到的数据一定都是相同的。即牺牲了可用性保证了一致性。
5.1.3 BASE理论
BASE 是 Basically Available(基本可用)、 Soft state(软状态)和 Eventually consistent(最终一致性)三个短语的简写, BASE 是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于 CAP 定理逐步演化而来的。
BASE 理论的核心思想是:即使无法做到强一致性,但每个系统都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
1 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。 即允许服务质量下降。常见的服务质量下降有两种类型:
响应时间上的损失:
功能上的损失: 即服务降级。
2 软状态
软状态,是指允许系统数据存在的中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统主机间进行数据同步的过程存在一定延时。软状态,其实就是一种灰度状态,过渡状态。
3 最终一致性
**
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
从一致性内容同步的时间角度来说,分为两种一致性:
- 实时一致性:只要数据发生变更,其它副本数据立即就会同步完成。在生产环境中是无法实现的,仅是一种理论状态。
- 最终一致性: 经过一段时间的同步后,最终能够达到一个一致的状态。
从 client 获取到的一致性内容角度来说,不管时间问题,分为两种一致性:
- 强一致性:也称为严格一致性。要求 client 访问到的数据一定是更新过的数据。
- 弱一致性:允许 client 访问不到部分或全部更新过的数据。
5.1.4 ZK 与 CP
zk 遵循的是 CP 原则,即保证了一致性,但牺牲了可用性。体现在哪里呢?
当 Leader 宕机后, zk 集群会马上进行新的 Leader 的选举。但选举时长一般在 200 毫秒内,最长不超过 60 秒,整个选举期间 zk 集群是不接受客户端的读写操作的,即 zk 集群是处于瘫痪状态的。所以,其不满足可用性。
数据在做同步期间, zk 集群是对外不提供服务的,是不可用的。同步完毕, client 读取到的一定是一致性的数据。
Eureka 是 AP 的, Consul 是 CP 的, Nacos 是 CP/AP 的。
5.2分布式事务与分布式一致性
分布式一致性一般是通过分布式事务实现的。
5.2.1 分布式事务
对于分布式事务,通俗地说就是, 一次操作由若干分支操作组成,这些分支操作分属不同应用,分布在不同服务器上。 分布式事务需要保证这些分支操作要么全部(或大多数) 成功,要么全部(或大多数) 失败。
分布式系统中对于数据修改的最终确认,必须是所有(或大多数) Server 节点对本地事务执行成功才可以。简单来说就是,若全部(或大多数)成功则成功;有一个(或大多数)失败则失败。
在分布式事务中,协调者称为事务协调者 TC(Transaction Coordinator), Server 节点称为资源管理器 RM(Resource Manager)。
5.2.2 分布式一致性
客户端从分布式系统中的每一个 Server 节点中读取到的数据,在某一时间段内可以保证都是一致的(最终一致性),那么这个系统具有分布式一致性,对外提供分布式一致性服务。
在大量长期的生产实践探索中,涌现出了大批经典的一致性协议和算法,其中最著名的就是 2PC、 3PC、 Paxos 与 Raft 算法。
5.3 2PC
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-srBztRU4-1663990334383)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.020.png)]](https://img-blog.csdnimg.cn/e4d0114363684766a077f21a40c11494.png)
2PC, Two Phase Commit, 2 阶段提交。即在分布式系统中,每个 Server 节点对本地事务执行结果的最终确认,需要经历两个阶段: Prepare 阶段与 Commit 阶段。目前, 2PC 被广泛地应用于分布式事务解决方案中。
目前大多数由关系型数据库形成的分布式事务解决方案都是 2PC 的,例如目前最火爆的阿里的分布式技术 Seata,其提供的 XA、 AT 及 TCC 三种模式(解决方案)都是 2PC 的。 Saga模式不是 2PC 的。
5.3.1 阶段一 Prepare阶段
TC 向各个 RM 发送 Prepare 指令,这就是第一阶段提交指令。各个 RM 在接收到 Prepare指令后,首先会将修改前的数据保存到回滚日志,然后开始执行本地事务。不过,这个本地事务执行的结果对用户是不可见的。执行完毕后,将本地事务执行状态(成功或失败)上报给 TC。
5.3.2 阶段二: Submit 阶段
TC 保存并汇总每个 RM 上报的结果,并根据这些汇总结果向所有 RM 发出 Submit 指令,即第二阶段提交指令。 RM 在执行完毕后,会再次将执行结果上报给 TC。不同的 RM 汇总结果, TC 会发出不同的 Submit 指令。
l 若所有 RM 上报的本地事务执行状态为成功,则 TC 向所有 RM 发送的 Submit 指令为Commit 指令。 RM 会将数据的修改结果向用户开放。
l 只要有一个 RM 上报的本地事务执行状态为失败,则 TC 向所有 RM 发送的 Submit 指令为 Rollback 指令。 RM 会将保存在回滚日志中的数据恢复,并向用户开放。
5.3.3 2PC 典型应用举例
阿里的分布式事务技术 Seata,提供了四种事务模式: XA、 AT、 TCC 与 Saga,前三种都是 2PC 的。
XA 模式
XA(Unix Transaction) 是一种分布式事务解决方案,一种分布式事务处理模式,是基于XA协议的。XA协议由Tuxedo(Transaction for Unix has been Extended for Distributed Operation,分布式操作扩展之后的 Unix 事务系统)首先提出的,并交给 X/Open 组织,作为资源管理器与事务管理器的接口标准。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IN9jmg66-1663990334383)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.021.png)]](https://img-blog.csdnimg.cn/f2f09be6e6d6466b80127181dc073364.png)
XA 模式架构图
XA 模式是一个典型的 2PC,其执行原理如下:
\1) TM 向 TC 发起指令,开启一个全局事务。
\2) 根据业务要求,各个 RM 会逐个向 TC 注册分支事务,然后 TC 会逐个向 RM 发出预执行指令。
\3) 各个 RM 在接收到指令后会进行本地事务预执行。
\4) RM 将预执行结果 Report 给 TC。当然,这个结果可能是成功,也可能是失败。
\5) TC 在接收到各个 RM 的 Report 后会将汇总结果上报给 TM,根据汇总结果 TM 会向 TC发出确认指令。
l 若所有结果都是成功响应,则向 TC 发送 Global Commit 指令。
l 只要有结果是失败响应,则向 TC 发送 Global Rollback 指令。
\6) TC 在接收到指令后再次向 RM 发送确认指令。
XA 模式存在两个较明显的问题:
l 当 TM 下发 Global Commit 指令后,各个 RM 中存放的回滚日志就没有用处了,就可以
清理掉了。但 XA 模式需要手动清理,无法实现自动清理。
l XA 模式存在 ABA 问题。
AT 模式
AT, Automatic Transaction。 AT 模式是 Seata 默认的分布式事务模型,是由 XA 模式演变而来的,通过全局锁对 XA 模式中的 ABA 问题进行了改进,并实现了回滚日志的自动清理。
AT 模式存在的问题是, prepare 阶段、 commit/rollback 阶段,及回滚日志的清理过程,完全都是自动化完成的,无法实现定制化。
TCC 模式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rxohcz3N-1663990334384)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.022.png)]](https://img-blog.csdnimg.cn/35b678cc993c47f3b0c678178e1f4427.png)
TCC, Try Confirm/Cancel,同样也是 2PC 的,其与 AT 的重要区别是,支持将自定义的分支事务纳入到全局事务管理中,即可以实现定制化的日志清理与回滚过程。当然,该模式对业务逻辑的侵入性是较大的。
5.3.4 2PC 的缺陷
2PC 最大的特点就是简单:原理简单,实现简单。 但却存在先天缺陷: 同步阻塞、 中心化问题、数据不一致、太过保守、性能问题等。 不过,若实现方案设计的较好,这些缺陷是可以弱化的。
同步阻塞
在一个分布式事务执行期间,若所有 RM prepare 完自己的本地事务后,就会处于阻塞状态,等待 TC 再次发布第二阶段指令。阻塞期间, RM 中的资源是处于锁定状态的。
中心化问题
TC 一旦出现问题,整个系统就会崩溃。
数据不一致
在 TC 发送了第二阶段的 Commit 指令后,若由于网络原因,只有部分 RM 接收到了。此时,收到 Commit 指令会将本地事务执行结果进行确认,但未收到的 RM 中的资源会一直处于锁定状态。当自行解锁后,会通过回滚日志恢复到修改前的状态。此时就出现了不同RM 中相同数据不同的值的情况,即数据不一致。
太过保守
任何一个 RM 在 Prepare 阶段执行失败,都将引发分布式事务的全局性失败。
性能问题
假设一个分布式事务由 n 个分支事务构成,每个分布事务的完成可能需要消耗较大的本地系统资源。当前 n-1 个分支事务全部完成并且成功后,第 n 个分支事务执行完毕,但执行状态为失败。此时 TC 会向所有 TM 发布 Rollback 指令。
从本地事务的执行到回滚,消耗了大量的系统资源,但却没有成功,恢复到了没有执行之前的状态。这就是一个很大的性能问题。
5.4 3PC
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TFd70Us3-1663990334384)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.023.png)]](https://img-blog.csdnimg.cn/497f47c8a5db4f64bc9d5eb35117126a.png)
3PC, Three Phase Commit, 3 阶段提交。即在分布式系统中,每个 Server 节点对本地事务执行结果的最终确认,需要经历三个阶段: Accept、 Prepare 与 Submit。 其实就是在 2PC的两个阶段之前又增加了一个新的阶段: Accept 阶段。
5.4.1 Accept 阶段
TC 向各个 RM 发送 Accept 指令,该指令中包含着事务内容。这就是第一阶段提交指令。各个 RM 在接收到 Accept 指令后,仅对事务内容进行判断,判断其是否可以完成本事务,并没有真正执行这个事务。并将判断结果上报给 TC。
TC 在接收到各个 RM 上报的判断结果后,根据不同的汇总结果,来决定是否继续 Prepare阶段。
l 若所有 RM 上报的判断结果都是 Yes,则继续 Prepare 阶段。
l 只要有一个 RM 上报的判断结果是 No,则结束整个全局事务。
5.4.2 3PC 的缺陷
PC 中存在的前四点缺陷,即同步阻塞、 中心化问题、数据不一致、太过保守, 3PC 中依然存在。但,3PC 解决了 2PC 中的性能问题。
5.5 Paxos 算法
5.5.1 算法简介
Paxos 算法是莱斯利·兰伯特(Leslie Lamport)1990 年提出的一种基于消息传递的、具有高容错性的一致性算法。Google Chubby 的作者 Mike Burrows 说过,世上只有一种一致性算法,那就是 Paxos,所有其他一致性算法都是 Paxos 算法的不完整版。 Paxos 算法是一种公认的晦涩难懂的算法, 并且工程实现上也具有很大难度。较有名的 Paxos 工程实现有 Google Chubby、ZAB、 微信的 PhxPaxos 等。
Paxos 算法是用于解决什么问题的呢? Paxos 算法要解决的问题是,在分布式系统中如何就某个决议达成一致。
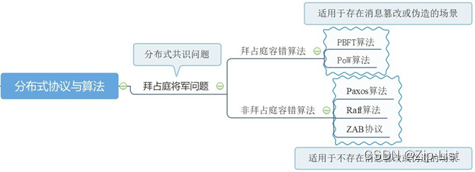
5.5.2 Paxos 与拜占庭将军问题
拜占庭将军问题是由 Paxos 算法作者莱斯利·兰伯特(Leslie Lamport)提出的点对点通信中的基本问题。该问题要说明的含义是,在不可靠信道上试图通过消息传递的方式达到一致性是不可能的。所以, Paxos 算法的前提是不存在拜占庭将军问题,即信道是安全的、可靠的,集群节点间传递的消息是不会被篡改的。
在实际工程实践中,可靠信道是存在的。
一般情况下,分布式系统中各个节点间采用两种通讯模型:共享内存(Shared Memory)、消息传递(Messages Passing)。而 Paxos 是基于消息传递通讯模型的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C9fq24AY-1663990334384)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.024.jpeg)]](https://img-blog.csdnimg.cn/9d54d7e3e0294cfdbc5401acd586b94a.png)
一文读懂拜占庭将军问题 https://cloud.tencent.com/developer/article/1589370
李永乐 https://www.youtube.com/watch?v=e9KVmyI1eCg
m(叛徒)=2时,V1会询问其他节点V2给其发送的指令,此时在v1视角下,v2是新的军官(递归),需要询问其他人确保起其准确性,在所有的节点都各自问了一遍后,递归。需要接受全局的信息。
5.5.3 角色与一致性
(1) 三种角色
在 Paxos 算法中有三种角色,分别具有三种不同的行为。但很多时候,一个进程可能同时充当着多种角色。
l Proposer: 提案(Proposal) 的提案者。在一个集群中,提案者可能存在多个,不同的提案者会提出不同的提案。
l Acceptor: 提案的表决者。即用于表决是否同步某提案。只有过半的 Acceptor 接受了某提案,该提案才会被认为是“选定了”。
l Learner: 提案的同步者。当提案被选定时,其要在本地执行该提案内容。
(2) Paxos 算法执行前提条件
Paxos 算法执行的前提有以下几点:
l 每个提案者在提出提案时都会首先获取到一个具有全局唯一性的、 递增的提案编号 N,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案。
l 每个表决者在 accept 某提案后,会将该提案的编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个编号最大的提案,其编号假设为 maxN。每个表决者仅会 accept 编号大于自己本地 maxN 的提案。
l 在众多提案中最终只能有一个提案被选定。
l 一旦一个提案被选定,则其它服务器会主动同步(Learn)该提案到本地。
l 没有提案被提出则不会有提案被选定。
5.5.4 3PC算法过程描述
Paxos 算法本身是不分阶段的,但在生产实现中具有 2PC 与 3PC 两种方案。
3PC 实现方案中,其执行过程划分为三个阶段:准备阶段 prepare、接受阶段 accept,与提交阶段 commit。
1 prepare 阶段
-
提案者(Proposer)准备提交一个编号为 N 的提议,于是其首先向所有表决者(Acceptor)发送 prepare(N)请求,用于试探集群是否支持该编号的提议。
-
每个表决者(Acceptor)中都保存着自己曾经 accept 过的提议中的最大编号 maxN。当一个表决者接收到其它主机发送来的 prepare(N)请求时,其会比较 N 与 maxN 的值。有以下几种情况:
-
若 N 大于 maxN,则说明该提议是可以接受的,当前表决者会首先将该 N 记录下来,并将其曾经已经 accept 的编号最大的提案 Proposal(myid,maxN,value)反馈给提案者,以向提案者展示自己支持的提案意愿。其中第一个参数 myid 表示该提案的提案者标识 id,第二个参数表示其曾接受的提案的最大编号 maxN,第三个参数表示该提案的真正内容 value。当然,若当前表决者还未曾 accept 过任何提议,则会将Proposal(myid,null,null)反馈给提案者。
-
若 N 小于等于 maxN,则说明该提议已过时,当前表决者采取不回应或回应 Error的方式来拒绝该 prepare 请求。
注意,若 N 生成器为全局性生成器,则任何提案的编号都不可能相同,即 N 与 maxN不可能相等。若 N 为各个参与者自行生成的,则可能会出现编号相同的提案,即 N与 maxN 可能会相等。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qmqRVhqj-1663990334385)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.026.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-86Hu1iDe-1663990334385)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.027.png)]](https://img-blog.csdnimg.cn/fd86bc2233a5490dadaf3768a1a83a91.png)
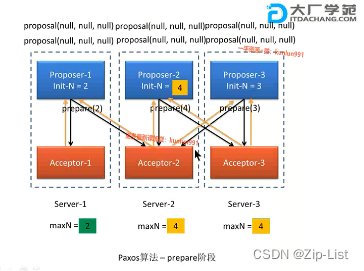
只是提案号
1 a1给a1 a2 发出提案2,都接受,都回复
2 a2 给a1 a3 发出提案1,a3接受,a3回复
3 a3 给a2 a3 发出提案3,都接受,都回复
4 a1 再给a1 a3 发出提案4,都接受,都回复
2 accept阶段
\1) 当提案者(Proposer)发出 prepare(N)后,若收到了超过半数的表决者(Accepter)的反馈,那么该提案者就会将其真正的提案 Proposal(myid,N,value)发送给所有的表决者。
2)当表决者(Acceptor)接收到提案者发送的 Proposal(N,value)提案后,会再次拿出自己曾经accept 过的提案中的最大编号 maxN,让 N 与它们进行比较, 若 N 大于等于 maxN,则当前表决者 accept 该提案,并反馈给提案者。若 N 小于 maxN,则表决者采取不回应或回应 Error 的方式来拒绝该提议。
3)若提案者没有接收到超过半数的表决者的 accept 反馈,则有两种可能的结果产生。一是放弃该提案,不再提出;二是重新进入 prepare 阶段,递增提案号,重新提出 prepare请求。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qHZOAX9w-1663990334386)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.028.png)]](https://img-blog.csdnimg.cn/ddbd89bf151845f897b5815131ca462b.png)
a1 a2 a3 发出自己的真正提案+内容
不过只有a2的提案会受到半数的反馈,只有a2能commit
3 commit 阶段
若提案者接收到的反馈数量超过了半数,则其会向外广播两类信息:
\1) 向曾 accept 其提案的表决者发送“可执行数据同步信号”,即让它们执行其曾接收到的提案;
\2) 向未曾向其发送 accept 反馈的表决者发送“提案 + 可执行数据同步信号”,即让它们接受到该提案后马上执行。
**此时如果commit时,提案又被更新了,怎么办。**ZAB协议的四种状态来解决
5.5.5 2PC算法过程描述
2PC 与 3PC 的区别是,在提案者接收到超过半数的表决者对于 parepare 阶段的反馈后,其会向所有表决者发送真正的提案 propsal。当表决者接受到 proposal 后就直接将其同步到了本地,不用再等待 commit 消息了。
那么,为什么不直接使用 2PC,而要使用 3PC 呢?是因为 2PC 中存在着较多的弊端。所以很多 Paxos 工业实现使用的都是 3PC 提交。但 2PC 提交的效率要高于 3PC 提交,所以在保证不出问题的情况下,是可以使用 2PC 提交的。
5.5.6 Paxos 算法的活锁问题
前面所述的Paxos算法在实际工程应用过程中,根据不同的实际需求存在诸多不便之处,所以也就出现了很多对于基本 Paxos 算法的优化算法,以对 Paxos 算法进行改进, 例如, MultiPaxos、 Fast Paxos、 EPaxos。
例如, Paxos 算法存在“活锁问题”, Fast Paxos 算法对 Paxos 算法进行了改进:只允许一个进程提交提案,即该进程具有对 N 的唯一操作权。该方式解决了“活锁”问题。
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复“尝试—失败—尝试—失败”的过程。处于活锁的实体是在不断的改变状态,活锁有可能自行解开。
活锁与死锁的状态有着本质的区别:
活锁是一直在动,是活动状态。/ 死锁是系统阻塞,是不活动状态。
5.6 ZAB 协议
5.6.1 ZAB协议简介
ZAB,Zookeeper Atomic Broadcast, zk 原子消息广播协议,是专为 ZooKeeper 设计的一种支持崩溃恢复的原子广播协议,在 Zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性。
Zookeeper 使用一个单一主进程来接收并处理客户端的所有事务请求,即写请求。 服务器数据的状态发生变更后,集群采用 ZAB 原子广播协议,以事务提案 Proposal 的形式广播到所有的副本进程上。 ZAB 协议能够保证一个全局的变更序列,即可以为每一个事务分配一个全局的递增编号 xid。
当 Zookeeper 客户端连接到 Zookeeper 集群的一个节点后,若客户端提交的是读请求,那么当前节点就直接根据自己保存的数据对其进行响应;如果是写请求且当前节点(Follower)不是Leader,那么节点就会将该写请求转发给 Leader, Leader 会以提案的方式广播该写操作,只要有超过半数节点同意该写操作,则该写操作请求就会被提交。然后 Leader 会再次广播给所有订阅者,即 Learner,通知它们同步数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EObKjH9f-1663990334386)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.029.png)]](https://img-blog.csdnimg.cn/fd5955b252b74c768fcb55344ef60af9.png)
5.6.2 ZAB 与 Paxos 的关系
ZAB 协议是 Paxos 算法的一种工业实现算法。 但两者的设计目标不太一样。 ZAB 协议主要用于构建一个高可用的分布式数据主从系统,即 Follower 是 Leader 的从机, Leader 挂了,马上就可以选举出一个新的 Leader,但平时它们都对外提供服务。而 Fast Paxos 算法则是用于构建一个分布式一致性状态机系统,确保系统中各个节点的状态都是一致的。
5.6.3 三类角色
为了避免 Zookeeper 的单点问题, zk 也是以集群的形式出现的。 zk 集群中的角色主要有以下三类:
Leader: zk 集群事务请求的唯一处理者。当然,也可以处理读请求。
Follower: 处理读请求,并向客户端返回结果;将事务请求转给 Leader;对 Leader 发起的决意具有表决权;同步 Leader 的事务处理结果; Leader 选举过程中的参与者(具有选举权与被选举权)。
Observer:可以理解为在 Leader 选举过程中没有选举权与被选举权,也没有对决意的表决权的 Flollower,其不属于法定人数范围,主要是为了协助 Follower 处理更多的读请求。其就相当于“临时工”,活没少干,但就是没有任何表决的权力。增加 Observer 可以加强 zk 集群处理读操作的能力,但同时又不会增加提案表决的时长,也不会增加 Leader选举的时长。
这三类角色在不同的情况下又有一些不同的名称:
Learner:学习者,同步者。其要从 Leader 中同步数据到本地。Learner = Follower + Observer
QuorumPeer:法定服务器。具有表决权、选举权的 Server。 QuorumPeer = Leader + Follower = Participant(参与者)
5.6.4 三个数据
在 ZAB 中有三个很重要的数据:
宋历_123年
zxid: 一个 64 位长度的 Long 类型,其中高 32 位表示纪元 epoch,低 32 位表示事务标识 xid。即 zxid 由两部分构成: epoch 与 xid。
epoch:抽取自 zxid 中的高 32 位。每个 Leader 都会具有一个不同的 epoch 值,表示一个时期、时代、年号。每一次新的选举结束后都会生成一个新的 epoch,新的 Leader产生,则会更新所有 zkServer 的 zxid 中的 epoch。
xid:抽取自 zxid 中的低 32 位。为 zk 的事务 id,每一个写操作都是一个事务,都会有一个 xid。 xid 为一个依次递增的流水号。
5.6.5 三种模式
ZAB 协议中对 zkServer 的状态描述有三种模式。这三种模式并没有十分明显的界线,它们相互交织在一起。
恢复模式: 在集群启过程中,或在 Leader 崩溃后,系统都需要进入恢复模式,以恢复系统对外提供服务的能力。恢复模式主要包含两个阶段: Leader 选举与初始化同步。这两个阶段完成后 zk 集群恢复到了正常服务状态。
广播模式: 其分为两类:初始化广播与更新广播。
同步模式: 其分为两类:初始化同步与更新同步。
5.6.6 四种状态
zk 集群中的每一台主机,在不同的阶段会处于不同的状态。每一台主机具有四种状态。
LOOKING,选举状态(查找 Leader 的状态)。
FOLLOWING, Follower 从 Leader 同步数据时的状态。 即 Follower 的正常工作状态。
OBSERVING, Observer 从 Leader 同步数据时的状态。 即 Observer 的正常工作状态。
LEADING, Leader 广播数据更新时的状态。 即 Leader 的正常工作状态。
5.6.7 同步模式与广播模式
1) 初始化广播
前面我们说过,恢复模式具有两个阶段: Leader 选举与初始化同步(广播)。当完成 Leader选举后,此时的 Leader 还是一个准 Leader,其要经过初始化同步后才能变为真正的 Leader。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H6KsJb3i-1663990334386)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.030.png)]](https://img-blog.csdnimg.cn/55547c6d7ed24b889e0c02b567ae1617.png)
具体过程如下:
1 为了保证 Leader 向 Learner 发送提案的有序, Leader 会为每一个 Learner 服务器准备一个队列
2 Leader 将那些没有被各个 Learner 同步的事务封装为 Proposal
3 Leader 将这些 Proposal 逐条发给各个 Learner,并在每一个 Proposal 后都紧跟一个COMMIT 消息,表示该事务已经被提交, Learner 可以直接接收并执行
4 Learner 接收来自于 Leader 的 Proposal,并将其更新到本地
5 当 Learner 更新成功后,会向准 Leader 发送 ACK 信息
6 Leader 服务器在收到来自 Learner 的 ACK 后就会将该 Learner 加入到真正可用的 Follower列表或 Observer 列表。没有反馈 ACK,或反馈了但 Leader 没有收到的 Learner, Leader不会将其加入到相应列表。
leader只会把认同自己的(嫡系)加入follower
2) 更新广播
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2YJrP38J-1663990334387)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.031.png)]](https://img-blog.csdnimg.cn/0ba378912c98429ab038527160a5a50a.png)
当集群中的 Learner 完成了初始化状态同步,那么整个 zk 集群就进入到了正常工作模式了。
FastPaxos只有一个Leader来写,多个读。相当于去掉了prepare阶段,自己的提议一定时最新的。
如果集群中的 Learner 节点收到客户端的事务请求,那么这些 Learner 会将请求转发给Leader 服务器。然后再执行如下的具体过程:
- Leader 接收到事务请求后, 为事务赋予一个全局唯一的 64 位自增 id,即 zxid,通过zxid 的大小比较即可实现事务的有序性管理,然后将事务封装为一个 Proposal。
- Leader 根据 Follower 列表获取到所有 Follower,然后再将 Proposal 通过这些 Follower 的队列将提案发送给各个 Follower。
- 当 Follower 接收到提案后,会先将提案的 zxid 与本地记录的事务日志中的最大的 zxid进行比较。若当前提案的 zxid 大于最大 zxid,则将当前提案记录到本地事务日志中,并向 Leader 返回一个 ACK。
- 当 Leader 接收到过半的 ACKs 后, Leader 就会向所有 Follower 的队列发送 COMMIT消息,向所有 Observer 的队列发送 Proposal。
- 当 Follower 收到 COMMIT 消息后,就会将日志中的事务正式更新到本地。当 Observer收到 Proposal 后,会直接将事务更新到本地。
- 无论是 Follower 还是 Observer,在同步完成后都需要向 Leader 发送成功 ACK。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vdGK1VxQ-1663990334388)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.032.png)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oLPT9yIy-1663990334388)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.033.png)]](https://img-blog.csdnimg.cn/b79ab68f3cb444c9bef22719544e4d61.png)


3) Observer 的数量问题
Observer 数量一般与 Follower 数量相同。并不是 Observer 越多越好, 因为 Observer 数量的增多虽不会增加事务操作压力,但其需要从 Leader 同步数据, Observer 同步数据的时间是小于等于 Follower 同步数据的时间的。当 Follower 同步数据完成, Leader 的 Observer列表中的 Observer 主机将结束同步。那些完成同步的 Observer 将会进入到另一个对外提供服务的列表。那么,那些没有同步了数据无法提供服务的 Observer 主机就形成了资源浪费。所以,对于事务操作发生频繁的系统,不建议使用过多的 Observer。Observer 存在两个列表: all 与 service。
5.6.8 恢复模式的三个原则
当集群正在启动过程中,或 Leader 崩溃后,集群就进入了恢复模式。对于要恢复的数据状态需要遵循三个原则。
1 leader的主动出让原则
若集群中 Leader 收到的 Follower 心跳数量没有过半,此时 Leader 会自认为自己与集群的连接已经出现了问题,其会主动修改自己的状态为 LOOKING,去查找新的 Leader。
而其它 Server 由于已经找不到 Leader 了,所以它们会发起新的 Leader 选举,选出一个新的 Leader。
2 已经被处理过的消息不能丢
当 Leader 收到超过半数 Follower 的 ACKs 后,就向各个 Follower 广播 COMMIT 消息,批准各个 Server 执行该写操作事务。当各个 Server 在接收到 Leader 的 COMMIT 消息后就会在本地执行该写操作,然后会向客户端响应写操作成功。
但是如果在非全部 Follower 收到 COMMIT 消息之前 Leader 就挂了,这将导致一种后果:部分 Server 已经执行了该事务,而部分 Server 尚未收到 COMMIT 消息,所以其并没有执行该事务。当新的 Leader 被选举出,集群经过恢复模式后需要保证所有 Server 上都执行了那些已经被部分 Server 执行过的事务。
只要保证新的 Leader 从“已经执行过最后事务的 Server”中选举出来就可以保证该原则。而“已经执行过最后事务的 Server”的 xid 要比“没有执行过最后事务的 Server”的 xid要大。所以,只要 Leader 的选举算法是, zxid 大者当选即可。
3 被丢弃的消息不能再现原则
当在 Leader 新事务已经通过,其已经将该事务更新到了本地,但所有 Follower 还都没有收到 COMMIT 之前, Leader 宕机了(比刚才的挂的更早),此时,所有 Follower 根本就不知道该 Proposal 的存在。当新的 Leader 选举出来,整个集群进入正常服务状态后,之前挂了的 Leader 主机重新启动并注册成为了 Follower。若那个别人根本不知道的 Proposal 还保留在那个主机,那么其数据就会比其它主机多出了内容,导致整个系统状态的不一致。所以,该 Proposal 应该被丢弃。类似这样应该被丢弃的事务,是不能再次出现在集群中的,应该被清除。
对于这种事务的清除有两种情况: 这两种情况都可以通过数据同步过程就可以将这些应该被丢弃的事务给覆盖。
新 Leader 的 xid 比 Follower(老 Leader)的大
新 Leader 的 xid 比 Follower(老 Leader)的小
5.6.9 *Leader选举
在集群启动过程中,或 Leader 宕机后,集群就进入了恢复模式。恢复模式中最重要的阶段就是 Leader 选举。
1 Leader选举中的基本概念
A serverId
这是 zk 集群中服务器的唯一标识, 也称为 sid,其实质就是 zk 中配置的 myid。例如,有三个 zk 服务器,那么编号分别是 1,2,3。
B 逻辑时钟
逻辑时钟, Logicalclock,是一个整型数。 该概念在选举时称为 logicalclock,而在选举结束后称为 epoch。即 epoch 与 logicalclock 是同一个值,在不同情况下的不同名称。
2 Leader选举算法
在集群启动过程中的 Leader 选举过程(算法)与 Leader 断连后的 Leader 选举过程稍微有一些区别,基本相同。
A 集群启动中的Leader选举
** 若进行 Leader 选举,则至少需要两台主机,这里以三台主机组成的集群为例。
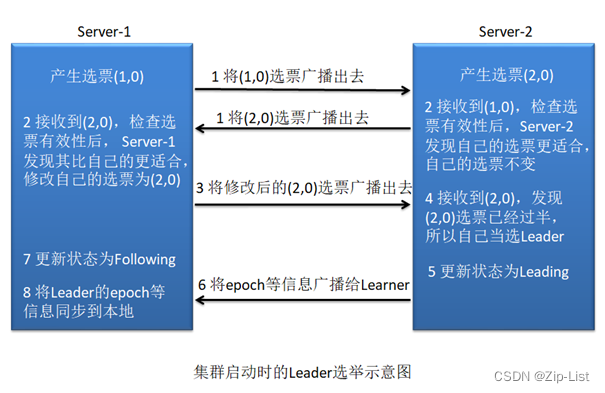
在集群初始化阶段,当第一台服务器 Server1 启动时,其会给自己投票,然后发布自己的投票结果。投票包含所推荐的服务器的 myid 和本次推荐的 ZXID,使用(myid, ZXID)来表示,此时 Server1 的投票为(1, 0)。 由于其它机器还没有启动所以它收不到反馈信息, Server1 的状态一直属于 Looking,即属于非服务状态。
当第二台服务器 Server2 启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,选举过程如下:
- 每个 Server 发出一个投票。此时 Server1 的投票为(1, 0), Server2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
- 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
- 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK, PK规则如下:
- 优先检查选票的 ZXID。 ZXID 比较大的服务器优先作为 Leader。
- 如果 ZXID 相同,那么就比较选票所推荐的 server 的 myid。 myid 较大的服务器作为Leader 服务器。
对于 Server1 而言,它的投票是(1, 0),接收 Server2 的投票为(2, 0)。其首先会比较两者的 ZXID,均为 0,再比较 myid,此时 Server2 的 myid 最大,于是 Server1 更新自己的投票为(2, 0),然后重新投票。对于 Server2 而言,其无须更新自己的投票,只是再次向集群中所有主机发出上一次投票信息即可。
- 统计投票。每次投票后,服务器都会统计投票信息, 判断是否已经有过半机器接受到相同的投票信息。对于 Server1、 Server2 而言,都统计出集群中已经有两台主机接受了(2, 0)的投票信息,此时便认为已经选出了新的 Leader,即 Server2。
- 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。
- 添加主机。在新的 Leader 选举出来后 Server3 启动, 其想发出新一轮的选举。但由于当前集群中各个主机的状态并不是 LOOKING,而是各司其职的正常服务,所以其只能是以Follower 的身份加入到集群中。
B 宕机后的leader选举
在 Zookeeper 运行期间, Leader 与非 Leader 服务器各司其职,即便当有非 Leader 服务器宕机或新加入时也不会影响 Leader。但是若 Leader 服务器挂了,那么整个集群将暂停对外服务,进入新一轮的 Leader 选举,其过程和启动时期的 Leader 选举过程基本一致。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ipuWHizP-1663990334389)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.036.png)]](https://img-blog.csdnimg.cn/d015e722c00a44f994888c198c66ea95.png)
假设正在运行的有 Server1、 Server2、 Server3 三台服务器,当前 Leader 是 Server2,若某一时刻 Server2 挂了,此时便开始新一轮的 Leader 选举了。选举过程如下:
(1) 变更状态。 Leader 挂后,余下的非 Observer 服务器都会将自己的服务器状态由FOLLOWING 变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个 Server 会发出一个投票,仍然会首先投自己。不过,在运行期间每个服务器上的 ZXID 可能是不同,此时假定 Server1 的 ZXID 为 111, Server3 的 ZXID 为 333;在第一轮投票中, Server1 和 Server3 都会投自己,产生投票(1, 111), (3, 333),然后各自将投票发送给集群中所有机器
(3) 接收来自各个服务器的投票。与启动时过程相同。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
(4) 处理投票。与启动时过程相同。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK。对于 Server1 而言,它的投票是(1, 111),接收 Server3 的投票为(3, 333)。其首先会比较两者的 ZXID, Server3 投票的 zxid 为 333 大于 Server1 投票的 zxid 的 111,于是Server1 更新自己的投票为(3, 333),然后重新投票。对于 Server3 而言,其无须更新自己的投票,只是再次向集群中所有主机发出上一次投票信息即可。
(5) 统计投票。与启动时过程相同。对于 Server1、 Server2 而言,都统计出集群中已经有两台主机接受了(3, 333)的投票信息,此时便认为已经选出了新的 Leader,即 Server3。
(6) 改变服务器的状态。与启动时过程相同。一旦确定了 Leader,每个服务器就会更新自己的状态。 Server1 变更为 FOLLOWING, Server3 变更为 LEADING。
5.7 高可用集群的容灾
5.7.1 服务器数量的奇数与偶数
对于 zk 集群中所包含服务器的数量存在一个误区:为了防止出现赞同票与反对票各占一半的问题,必须要将服务器数量部署为奇数(不包含 Observer)。其实,部署奇数台服务器从某种意义上说确实比偶数台好,但不是为了防止投票平均现象的。因为投票平均,提案无法通过,则该提案会被重提的。
前面我们说过,无论是写操作投票,还是 Leader 选举投票,都必须过半才能通过,也就是说若出现超过半数的主机宕机,则投票永远无法通过。基于该理论,由 5 台主机构成的集群,最多只允许 2 台宕机。而由 6 台构成的集群,其最多也只允许 2 台宕机。即, 6 台与5 台的容灾能力是相同的。基于容灾能力的原因,建议使用奇数台主机构成集群,以避免资源浪费。
但从系统吞吐量上说, 6 台主机的性能一定是高于 5 台的。所以使用 6 台主机并不是资源浪费。
5.7.2 容灾设计方案
对于一个高可用的系统,除了要设置多台主机部署为一个集群避免单点问题外,还需要考虑将集群部署在多个机房、多个楼宇。对于多个机房、楼宇中集群也是不能随意部署的,下面就多个机房的部署进行分析。
在多机房部署设计中,要充分考虑“过半原则”,也就是说,尽量要确保 zk 集群中有过半的机器能够正常运行。
- 三机房部署
在生产环境下,三机房部署是最常见的、容灾性最好的部署方案。三机房部署中要求每个机房中的主机数量必须少于集群总数的一半。
- 双机房部署
zk 官网没有给出较好的双机房部署的容灾方案。只能是让其中一个机房占有超过半数的主机,使其做为主机房,而另一机房少于半数。当然,若主机房出现问题,则整个集群会瘫痪。
5.7.3 zk 中的脑裂
这里说的 zk 可能会引发脑裂,是指的在多机房部署中,若出现了网络连接问题,形成多个分区,则可能会出现脑裂问题,可能会导致数据不一致。
下面以三机房部署为例进行分析,根据机房断网情况,可以分为五种情况:
- 情况1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wAeSPRSF-1663990334389)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.037.png)]](https://img-blog.csdnimg.cn/109433e55f1941839b0250a59e906cbd.png)
这种情况下, B 机房中的主机是感知不到 Leader 的存在的,所以 B 机房中的主机会发起新一轮的 Leader 选举,它们的状态会变为 Looking,所以它们是不会对外提供服务的。由于 B 机房与 C 机房是相连的,所以其也会通知 C 机房中的主机进行 Leader 选举。
由于 C 机房能够感知到 A 机房中的 Leader,所以其状态为 Following。故其是不会参与 B机房发起的 Leader 选举的。由于没有 C 机房的参与,所以 B 机房中的选举不可能过半,即不可能选举出结果。
这种情况下,只有 A 与 C 机房对外提供服务。
(2) 情况2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oyzY8JgN-1663990334389)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.038.png)]](https://img-blog.csdnimg.cn/4fd094504c864d0c96ac0f0d61d0d2ef.png)
- B、 C 均可以对外提供服务,不受影响。
(3) 情况3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u7kqE7jq-1663990334389)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.039.png)]](https://img-blog.csdnimg.cn/03466b4b26de473c86a471b2d0587525.png)
- C 可以正常对外提供服务,但 B 将无法提供服务。
(4) 情况4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PXde5iDj-1663990334389)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.040.png)]](https://img-blog.csdnimg.cn/a286307c1c0547e1bf1e50e6fd4df5b6.png)
这种情况下 A 机房仍会对外提供服务,但只会提供短暂的读服务。
由于 B 与 C 均感知不到 Leader 的存在,且它们是相连的,所以它们会发起新一轮的选举,此时会选举出一个新的 Leader。于是形成的两个分区出现了两个 Leader,这就是脑裂。
当然,此时的 B 与 C 对外是可以提供读/写服务的。
(5) 情况5
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Zki8dvK-1663990334390)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.041.png)]](https://img-blog.csdnimg.cn/7f774f8caee94508bcf554bae1239fdc.png)
这种情况只有 A 可能短暂的对外提供读服务,然后会由于 Leader 感知到已经失去了大多数 Follower 而主动出让领导权,进入 LOOKING 状态。由于选举无法过半,从而无法对外提供服务。
B 与 C 都会由于无法感知到 Leader 而使状态变为 Looking,发起新的 Leader 选举,但又都无法过半。所以最终 A、 B、 C 将都无法对外提供服务。
5.8 Raft算法
Raft 算法动画演示:http://thesecretlivesofdata.com/raft/
5.8.1 基础
Nacos Discovery 集群为了保证集群中数据的一致性,其采用了 Raft 算法。 还有 RedisSentinel 集群、 Etcd 集群的一致性也都是采用的 Raft 算法。
这是一种通过对日志进行管理来达到一致性的算法, 其是一种 AP 的一致性算法。 Raft通过选举 Leader 并由 Leader 节点负责管理日志复制来实现各个节点间数据的一致性。
5.8.2 角色、任期及角色转变
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4QMDVvcd-1663990334390)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.042.png)]](https://img-blog.csdnimg.cn/3796f1a51c83487582e1427a6ded6673.png)
在 Raft 中,节点有三种角色:
**Leader:**唯一负责处理客户端写请求的节点;也可以处理客户端读请求;同时负责日志复制工作
**Candidate:**Leader选举的候选人,其可能会成为Leader
**Follower:**可以处理客户端读请求;负责同步来自于 Leader 的日志;当接收到其它Cadidate 的投票请求后可以进行投票;当发现 Leader 挂了,其会转变为 Candidate 发起Leader 选举
term, 任期, 相当于 Paxos 中的 epoch, 表示一个新的 leader 上任了。
5.8.3 leader 选举
1 我要选举
若 follower 在心跳超时范围内没有接收到来自于 leader 的心跳,则认为 leader 挂了。此时其首先会使其本地 term 增一。 然后 follower 会完成以下步骤:
-
此时若接收到了其它 candidate 的投票请求,则会将选票投给这个 candidate
-
由 follower 转变为 candidate
-
若之前尚未投票,则向自己投一票(注意, 每个节点在每个 term 内只能投一票)
-
向其它节点发出投票请求,然后等待响应
2 我要投票
follower 在接收到投票请求后,其会根据以下情况来判断是否投票:
-
发来投票请求的 candidate 的 term 不能小于我的 term
-
在我当前 term 内,我的选票还没有投出去
-
若接收到多个 candidate 的请求, 我将采取先来先服务 first-come-first-served 方式投票
3 等待响应
当一个 Candidate 发出投票请求后会等待其它节点的响应结果。这个响应结果可能有三种情况:
- 收到过半选票,成为新的 leader。然后会将消息广播给所有其它节点,以告诉大家我是新的 Leader 了
- 接收到别的 candidate 发来的新 leader 通知,比较了新 leader 的 term 并不比我的 term小,则自己转变为 follower
- 经过一段时间后,没有收到过半选票,也没有收到新 leader 通知,则重新发出选举
4 票数相同
若在选举过程中出现了各个 candidate 票数相同的情况,是无法选举出 Leader 的。当出现了这种情况时,其采用了 randomized election timeouts 策略来解决这个问题。 其会让这些candidate 重新发起选举,只不过发起时间不同:各个 candidate 的选举发起时间是在一个给定范围内等待随机时长 timeout 之后开始的。 timeout 较小的会先开始选举,一般情况下其会优先获取到过半选票成为新的 leader。
5.8.4 数据同步
1 状态机
Raft 算法一致性的实现,是基于日志复制状态机的。状态机的最大特征是,不同 Server中的状态机若当前状态相同,然后接受了相同的输入,则一定会得到相同的输出。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JA5GXvEM-1663990334390)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.043.png)]](https://img-blog.csdnimg.cn/0603a086a06a46b1a3de47c3a4a7eaf0.png)
2 处理流程
当 leader 接收到 client 的写操作请求后,大体会经历以下流程:
- leader 将数据封装为日志
- leader 将日志并行发送给所有 follower,然后等待接收 follower 响应
- 当 leader 接收到过半响应后,将日志 commit 到自己的状态机,状态机会输出一个结果,同时日志状态变为了 committed
- 同时 leader 还会通知所有 follower 将日志 apply 到它们本地的状态机,日志状态变为了applied
- 在 apply 通知发出的同时, leader 也会向 client 发出成功处理的响应
3 AP支持
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dc3WByxf-1663990334390)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.044.png)]](https://img-blog.csdnimg.cn/7e12aa814ee54e1bb2fa4ab3a3946c8b.png)
Log 由 term index、 log index 及 command 构成。为了保证可用性,各个节点中的日志可以不完全相同,但 leader 会不断给 follower 发送 log,以使各个节点的 log 最终达到相同。即 raft 算法不是强一致性的,而是最终一致的。
5.8.5 宕机处理
(1) 请求到达前 Leader 挂了
client 发送写操作请求到达 Leader 之前 Leader 就挂了,因为请求还没有到达集群,所以这个请求对于集群来说就没有存在过, 对集群数据的一致性没有任何影响。 Leader 挂了之后,会选举产生新的 Leader。
由于 Stale Leader(失效的 Leader) 并未向 client 发送成功处理响应,所以 client 会重新发送该写操作请求(若 Client 具有重试机制的话)。
(2) 未开始同步数据leader挂了
client 发送写操作请求给 Leader, 请求到达 Leader 后, Leader 还没有开始向 Followers复制数据 Leader 就挂了。 这时集群会选举产生新的 Leader, Stale Leader 重启后会作为Follower 重新加入集群,并同步新 Leader 中的数据以保证数据一致性。 之前接收到 client 的数据被丢弃。
由于 Stale Leader 并未向 client 发送成功处理响应,所以 client 会重新发送该写操作请求(若 Client 具有重试机制的话)。
(3) 同步完部分后 Leader 挂了
client 发送写操作请求给 Leader, Leader 接收完数据后开始向 Follower 复制数据。 在部分 Follower 复制完后 Leader 挂了(可以过半也可以不过半)。 由于 Leader 挂了,就会发起新的 Leader 选举。
- 若 Leader 产生于已经复制完日志的 Follower,其会继续将前面接收到的写操作请求完成,并向 client 进行响应。
- 若 Leader 产生于尚未复制日志的 Follower,那么原来已经复制过日志的 Follower 则会将这个没有完成的日志放弃。由于 client 没有接收到响应,所以 client 会重新发送该写操作请求(若 Client 具有重试机制的话)。
(4) apply 通知发出后 Leader 挂了
client 发送写操作请求给 Leader, Leader 接收完数据后开始向 Follower 复制数据。 Leader成功接收到过半 Follower 复制完毕的响应后, Leader 将日志写入到状态机。此时 Leader 向Follower 发送 apply 通知。在发送通知的同时,也会向 client 发出响应。此时 leader 挂了。
由于 Stale Leader 已经向 client 发送成功接收响应,且 apply 通知已经发出,说明这个写操作请求已经被 server 成功处理。
6 Leader 的选举机制
QuorumCnxManager.java
Serverld为1的Server中QuorumCnxManager对象维护的消息发送Map
Key(Serverld)Value(队列)
2队列(存放向2号Server发送失败的消息副本)
3队列(存放向3号Server发送失败的消息副本)
4队列(存放向4号Server发送失败的消息副本)
所有队列均为空:说明当前server发送的消息全部成功。
所有队列均不空:说明当前server发送给所有其它serverl的消息全部失败,即当前server-与集合失联。
若有一个队列为空:说明当前server-与集群没有失联。
FastLeaderElection.java
FastLeaderE
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WvMFhLxH-1663990334390)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.045.png)]](https://img-blog.csdnimg.cn/d3a881900a5c44dd93f491c4efc72259.png)
//验证当加eader.选举是否可以结束了
public boolean hasAllQuorums(){
//遍历所有的QuorumVerifier(代表当前和最新的配置),只有当所有QuorumVerifier中的ackset都判断过半了,
//才能结束本轮eader选举。只要有一个QuorumVerifier中的ackset没有过半,就不能结束选举
//防止在选举过程中发生动态配置
for (QuorumVerifierAcksetPair qvAckset qvAcksetPairs)
{
if (!qvAckset.getQuorumVerifier().containsQuorum(qvAckset.getAckset()))
{return false;}
return true;
}
每次投票之后,会把票型作为ntf广播
3.7版本之后的选举有组group_id的概念,每台机器收到各个组内的各个server_id的总权重过半获得组选票,收到各个组选票过半(check if all groups hava majority),视作该被选人当选。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AHGQzeWQ-1663990334391)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.046.png)]](https://img-blog.csdnimg.cn/e0f677295158436a94885c600308b50c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vQEJlruE-1663990334391)(Aspose.Words.5650e8a5-ed38-4341-bc57-b214f0c76c5e.047.png)]](https://img-blog.csdnimg.cn/ceb0816316b74fe299c586da98deb070.png)
raft 协议和 zab 协议区别
相同点
采用 quorum 来确定整个系统的一致性,这个 quorum 一般实现是集群中半数以上的服务器。
zookeeper 里还提供了带权重的 quorum 实现。
都由 leader 来发起写操作。
都采用心跳检测存活性leader election 都采用先到先得的投票方式。
不同点
zab 用的是 epoch 和 count 的组合来唯一表示一个值, 而 raft 用的是 term 和 index。
zab 的 follower 在投票给一个 leader 之前必须和 leader 的日志达成一致,而 raft 的 follower则简单地说是谁的 term 高就投票给谁。
raft 协议的心跳是从 leader 到 follower, 而 zab 协议则相反。
raft 协议数据只有单向地从 leader 到 follower(成为 leader 的条件之一就是拥有最新的 log)。
而 zab 协议在 discovery 阶段, 一个 prospective leader 需要将自己的 log 更新为 quorum 里面最新的 log,然后才好在 synchronization 阶段将 quorum 里的其他机器的 log 都同步到一致。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









