







深度学习是机器学习的一个特定分支,要想充分理解深度学习,就必须对机器学习的基本原理有深刻的理解。机器学习的本质属于应用统计学,其更多地关注如何用计算机统计地估计复杂函数,而不太关注为这些函数提供置信区间,大部分机器学习算法可以分成监督学习和无监督学习两类;通过组合不同的算法部分,例如优化算法、代价函数、模型和数据集可以建立一个完整的机器学习算法。
余弦相似度与欧氏距离
余弦相似度
空间中两个向量的夹角的余弦
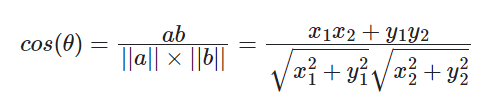
欧氏距离
向量空间中两点之间的距离
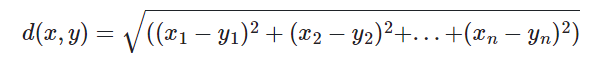
余弦相似度和欧氏距离的区别
没有归一化时,欧式距离的范围是 [0, +∞],而余弦相似度的范围是 [-1, 1];
余弦距离是计算相似程度,而欧氏距离计算的是相同程度(对应值的相同程度)
归一化的情况下,可以将空间想象成一个超球面(三维),欧氏距离就是球面上两点的直线距离,而向量余弦值等价于两点的球面距离。
Bias(偏差)和Varience(方差)
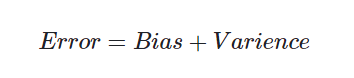
Error: 反映的是整个模型的准确度。
Bias:偏差为模型在样本上的输出与真实值之间的误差,即模型的准确性。
Varience:方差为模型每一次输出的结果与模型输出期望之间的误差,即模型的稳定性。
深度学习中的偏差与方差
神经网络的拟合能力非常强,因此它的训练误差(偏差)通常较小;
但是过强的拟合能力会导致较大的方差,使模型的测试误差(泛化误差)增大;
深度学习的核心工作之一就是研究如何降低模型的泛化误差,这类方法统称为正则化方法。
模型容量、过拟合和欠拟合
模型容量是指模型拟合各种函数的能力,决定了模型是欠拟合还是过拟合。
过拟合:就是指训练误差和测试误差间距过大,即方差(variance)过大,表现为模型泛化性能下降即不够”稳“,正则化目的在于解决过拟合问题。
欠拟合:和过拟合相反,指模型的训练误差过大,即偏差(bias)过大,表现为模型不够”准“,优化算法目的在于解决欠拟合问题。
先验概率与后验概率
先验概率
事件发生前的概率,可以是基于以往经验/分析,也可以是基于历史数据的统计,甚至可以是人的主观观点给出。
后验概率
事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小
贝叶斯公式
条件概率:事件 B 发生的条件下,事件 A 发生的条件概率为:
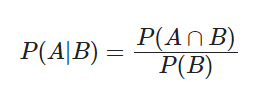
贝叶斯在条件概率的基础上寻找事件发生的原因(即大事件 A 已经发生的条件下,分割中的小事件 Bi 的概率)
举例:
假设一个学校里有 60% 男生和 40% 女生。女生穿裤子的人数和穿裙子的人数相等,所有男生穿裤子。一个人在远处随机看到了一个穿裤子的学生。那么这个学生是女生的概率是多少?

相对熵(KL散度)与交叉熵
信息熵
信息熵是信息量
l
o
g
(
1
p
)
log(\frac{1}{p})
log(p1)的期望,不是针对每条信息,而是针对整个不确定性结果集而言,信息熵越大,事件不确定性就越大。
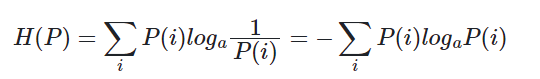
相对熵/KL散度
用于计算两个分布之间的不同
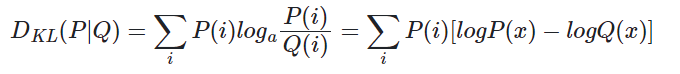
交叉熵
交叉熵,用来衡量在给定的真实分布下,使用非真实分布指定的策略消除系统的不确定性所需要付出努力的大小。
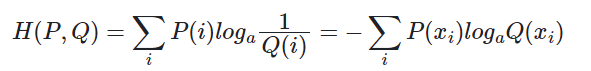
最小化 KL 散度等价于最小化交叉熵,而且交叉熵计算更简单,所以机器/深度学习中常用交叉熵 cross-entroy 作为分类问题的损失函数。
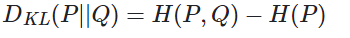
正则化
对原始损失函数引入额外信息,新的损失函数变成了原始损失函数 + 惩罚项对形式。惩罚项通常是对权重参数做一些限制,如 L1/L2 范数。















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









