







pytorch量化训练
量化感知训练(Quantization Aware Training )是在模型中插入伪量化模块(fake_quant module)模拟量化模型在推理过程中进行的舍入(rounding)和钳位(clamping)操作,从而在训练过程中提高模型对量化效应的适应能力,获得更高的量化模型精度 。
Pytorch 官方从 1.3 版本开始提供量化感知训练 API,只需修改少量代码即可实现量化感知训练。目前 torch.quantization 仍处于 beta 阶段,不保证 API 前向、后向兼容性。以下介绍基于 Pytorch 1.7,其他版本可能会有差异。
搭建模型
m = nn.Sequential(
nn.Conv2d(2,64,8),
nn.ReLU(),
nn.Conv2d(64, 128, 8),
nn.ReLU(),
)
融合算子
支持ConV + BN、ConV + BN + ReLU、Conv + ReLU、Linear + ReLU、BN + ReLU融合
torch.quantization.fuse_modules(m, ['0','1'], inplace=True) # fuse first Conv-ReLU pair
torch.quantization.fuse_modules(m, ['2','3'], inplace=True) # fuse second Conv-ReLU pair
修改模型
在模型输入前加入QuantStub(),在模型输出后加入DeQuantStub()。目的是将输入从float32量化为int8,将输出从int8反量化为float32。
m = nn.Sequential(torch.quantization.QuantStub(),
*m,
torch.quantization.DeQuantStub())
add、cat修改成量化版本的add和cat
训练
"""准备Prepare"""
m.train()
m.qconfig = torch.quantization.get_default_qconfig(backend)
torch.quantization.prepare_qat(m, inplace=True)
"""训练Training Loop"""
n_epochs = 10
opt = torch.optim.SGD(m.parameters(), lr=0.1)
loss_fn = lambda out, tgt: torch.pow(tgt-out, 2).mean()
for epoch in range(n_epochs):
x = torch.rand(10,2,24,24)
out = m(x)
loss = loss_fn(out, torch.rand_like(out))
opt.zero_grad()
loss.backward()
opt.step()
print(loss)
"""模型转换Convert"""
m.eval()
torch.quantization.convert(m, inplace=True)
TensorRT量化
权重量化:直接统计权重的最大值和最小值就可以完成量化
激活值量化:
1、准备校准集,进行FP32推理,并统计每一层的激活值直方图(2048个bins)
2、遍历(0, max),max从128开始,计算KL(P, Q),记录使得KL散度最小的(0, max),P表示(0, max)间的FP32直方图, Q表示(0, max)之间的值量化(0, 128)再反量化的直方图。
拿到onnx文件后,需要写一个新的类int8EntroyCalibrator继承Int8EntropyCalibrator这个类,然后重写一些和数据读取相关的成员函数即可。
namespace nvinfer1 {
class int8EntroyCalibrator : public nvinfer1::IInt8EntropyCalibrator {
public:
int8EntroyCalibrator(const int &bacthSize,
const std::string &imgPath,
const std::string &calibTablePath);
virtual ~int8EntroyCalibrator();
int getBatchSize() const override { return batchSize; }
bool getBatch(void *bindings[], const char *names[], int nbBindings) override;
const void *readCalibrationCache(std::size_t &length) override;
void writeCalibrationCache(const void *ptr, std::size_t length) override;
private:
bool forwardFace;
int batchSize;
size_t inputCount;
size_t imageIndex;
std::string calibTablePath;
std::vector<std::string> imgPaths;
float *batchData{ nullptr };
void *deviceInput{ nullptr };
bool readCache;
std::vector<char> calibrationCache;
};
int8EntroyCalibrator::int8EntroyCalibrator(const int &bacthSize, const std::string &imgPath,
const std::string &calibTablePath) :batchSize(bacthSize), calibTablePath(calibTablePath), imageIndex(0), forwardFace(
false) {
int inputChannel = 3;
int inputH = 416;
int inputW = 416;
inputCount = bacthSize*inputChannel*inputH*inputW;
std::fstream f(imgPath);
if (f.is_open()) {
std::string temp;
while (std::getline(f, temp)) imgPaths.push_back(temp);
}
int len = imgPaths.size();
for (int i = 0; i < len; i++) {
cout << imgPaths[i] << endl;
}
batchData = new float[inputCount];
CHECK(cudaMalloc(&deviceInput, inputCount * sizeof(float)));
}
int8EntroyCalibrator::~int8EntroyCalibrator() {
CHECK(cudaFree(deviceInput));
if (batchData)
delete[] batchData;
}
bool int8EntroyCalibrator::getBatch(void **bindings, const char **names, int nbBindings) {
cout << imageIndex << " " << batchSize << endl;
cout << imgPaths.size() << endl;
if (imageIndex + batchSize > int(imgPaths.size()))
return false;
// load batch
float* ptr = batchData;
for (size_t j = imageIndex; j < imageIndex + batchSize; ++j)
{
//cout << imgPaths[j] << endl;
Mat img = cv::imread(imgPaths[j]);
vector<float>inputData = prepareImage(img);
cout << inputData.size() << endl;
cout << inputCount << endl;
if ((int)(inputData.size()) != inputCount)
{
std::cout << "InputSize error. check include/ctdetConfig.h" << std::endl;
return false;
}
assert(inputData.size() == inputCount);
int len = (int)(inputData.size());
memcpy(ptr, inputData.data(), len * sizeof(float));
ptr += inputData.size();
std::cout << "load image " << imgPaths[j] << " " << (j + 1)*100. / imgPaths.size() << "%" << std::endl;
}
imageIndex += batchSize;
CHECK(cudaMemcpy(deviceInput, batchData, inputCount * sizeof(float), cudaMemcpyHostToDevice));
bindings[0] = deviceInput;
return true;
}
const void* int8EntroyCalibrator::readCalibrationCache(std::size_t &length)
{
calibrationCache.clear();
std::ifstream input(calibTablePath, std::ios::binary);
input >> std::noskipws;
if (readCache && input.good())
std::copy(std::istream_iterator<char>(input), std::istream_iterator<char>(),
std::back_inserter(calibrationCache));
length = calibrationCache.size();
return length ? &calibrationCache[0] : nullptr;
}
void int8EntroyCalibrator::writeCalibrationCache(const void *cache, std::size_t length)
{
std::ofstream output(calibTablePath, std::ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
}
}
然后在onnx转RT时调用即可

Ascend 310支持的量化算法
ARQ权重量化
ARQ (Adaptive Range Quantization)算法是对权重直接量化的算法。即max-min量化
IFMR数据量化
IFMR(Input Feature Map Reconstruction)算法在某个数据分布下,通过搜索的方式确定最佳量化方式。
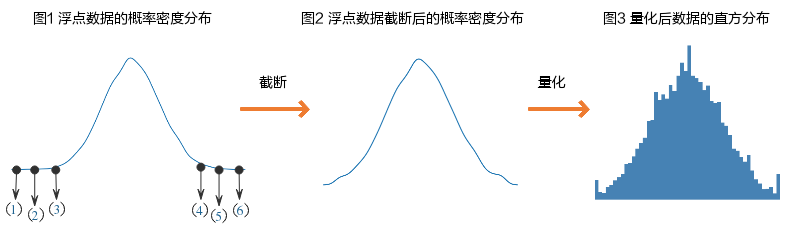
第一步,将浮点数截断到[clip_min, clip_max]范围,即图1中的[2,5]点 ;
第二步,将浮点数据量化到int范围。通常情况下,数据分布处于边界附近的数值比较稀疏,均可做截断处理,以提高量化精度。
为获得最佳量化效果,可以不断改变截断范围[clip_min, clip_max],选择量化效果最好的一组范围作为最终的量化结果。
HFMG数据量化
HFMG(Histogram Feature Map Glutton)算法通过直方图的方式来记录激活数据的数据分布,通过搜索的方式确定最佳的量化截断位置。
1、第一步根据输入激活数据创建直方图。
2、若有更多batch的数据则对每个batch的数据创建一个直方图,然后进行直方图合并的操作.
3、基于激活数据的直方图根据搜索的方式确定数据的截断点.
看起来和IFMR区别不大
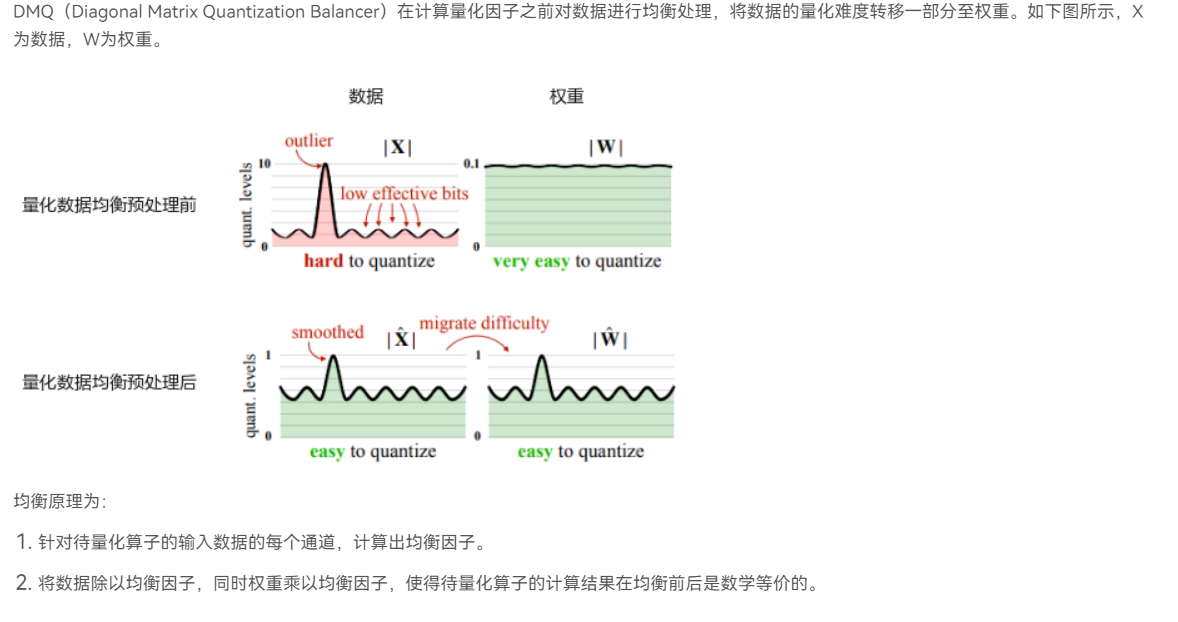
DMQ均衡算法

















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









