







Linux生成core文件并使用gdb调试
Linux环境下进程发生异常而挂掉,通常很难查找原因,但是一般Linux内核给我们提供的核心文件,记录了进程在崩溃时候的信息。但是生成core文件需要设置开关。
生成core文件
1、查看生成core文件的开关是否开启,输入命令ulimit -a
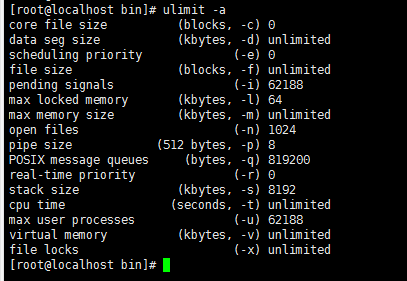
我们看到,第一行core文件大小为0,没有开启。
2、使用ulimit -c [kbytes]可以设置系统允许生成的core文件大小;
ulimit -c 0 不产生core文件
ulimit -c 100 设置core文件最大为100k
ulimit -c unlimited 不限制core文件大小
3、执行命令ulimit -c unlimited,然后使用ulimit -a查看core
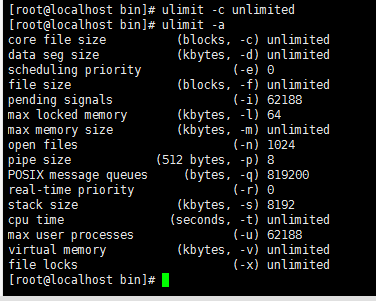
这样进程崩溃就可以生成core文件
4、上述方法只能在shell中生效,要想永久生效,可以使用以下方法:
vim /etc/profile,进入编辑模式,在profile文件中加入ulimit -c unlimited
保存退出,重启服务器或者执行或者source /etc/profile,改文件就长久生效。
修改core文件属性
默认生成路径:输入可执行文件运行命令的同一路径下
默认生成名字:默认命名为core。新的core文件会覆盖旧的core文件
1、设置pid作为文件扩展名
1:添加pid作为扩展名,生成的core文件名称为core.pid
0:不添加pid作为扩展名,生成的core文件名称为core
修改 /proc/sys/kernel/core_uses_pid 文件内容为 1
修改文件命令:
echo "1" > /proc/sys/kernel/core_uses_pid
或者
sysctl -w kernel.core_uses_pid=1 kernel.core_uses_pid = 1
2、控制core文件保存位置和文件名格式
修改文件命令:
echo "/corefile/core-%e-%p-%t" > /proc/sys/kernel/core_pattern
或者:
sysctl -w kernel.core_pattern=/corefile/core.%e.%p.%s.%E
可以将core文件统一生成到/corefile目录下,产生的文件名为core-命令名-pid-时间戳
以下是参数列表:
%p - insert pid into filename 添加pid(进程id)
%u - insert current uid into filename 添加当前uid(用户id)
%g - insert current gid into filename 添加当前gid(用户组id)
%s - insert signal that caused the coredump into the filename 添加导致产生core的信号
%t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加导致产生core的命令名
gdb调试core文件
1、新建一个测试文件test.cc
#include<iostream>
using namespace std;
int main()
{
int *p = NULL;
*p = 0;
return 0;
}
2、编译运行
g++ -o test test.cc
./test
Segmentation fault (core dumped) // 显示段错误,生成core文件
运行完上述命令,我们可以看到目录下生成了core-test-116973文件
3、gdb调试
gdb ./test core-test-116973
我们可以根据堆栈信息查看bug,日常仅需要bt指令就能解决问题。
4、gdb常用指令
- backtrace / bt [-full] [n]
打印当前函数调用栈的所有信息,[-full] 和 [n] 为可选项,其中:
- n:一个整数值,当为正整数时,表示打印最顶层的 n 个栈帧的信息;n 为负整数时,那么表示打印最底层 n 个栈帧的信息;
- full:打印栈帧信息的同时,打印出局部变量的值。
(gdb) bt
#0 func (n=250) at tst.c:6
#1 0x08048524 in main (argc=1, argv=0xbffff674) at tst.c:30
#2 0x400409ed in __libc_start_main () from /lib/libc.so.6
从上可以看出函数的调用栈信息:__libc_start_main --> main()–> func()
如果你要查看某一层的信息,你需要在切换当前的栈,一般来说,程序停止时,最顶层的栈就是当前栈,如果你要查看栈下面层的详细信息,首先要做的是切换当前栈。
- frame / f [spec]
该命令可以将 spec 参数指定的栈帧选定为当前栈帧。
spec 参数的值,常用的指定方法有 3 种:
- 通过栈帧的编号指定。0 为当前被调用函数对应的栈帧号,最大编号的栈帧对应的函数通常就是 main() 主函数;
- 借助栈帧的地址指定。栈帧地址可以通过 info frame 命令(后续会讲)打印出的信息中看到;
- 通过函数的函数名指定。注意,如果是类似递归函数,其对应多个栈帧的话,通过此方法指定的是编号最小的那个栈帧。
除此之外,对于选定一个栈帧作为当前栈帧,GDB 调试器还提供有 up 和 down 两个命令。
其中,up 命令的语法格式为:
(gdb) up n
其中 n 为整数,默认值为 1。该命令表示在当前栈帧编号(假设为 m)的基础上,选定 m+n 为编号的栈帧作为新的当前栈帧。
相对地,down 命令的语法格式为:
(gdb) down n
其中 n 为整数,默认值为 1。该命令表示在当前栈帧编号(假设为 m)的基础上,选定 m-n 为编号的栈帧作为新的当前栈帧。
- info frame
借助如下命令,我们可以查看当前栈帧中存储的信息:
(gdb) info frame
该命令会依次打印出当前栈帧的如下信息:
- 当前栈帧的编号,以及栈帧的地址;
- 当前栈帧对应函数的存储地址,以及该函数被调用时的代码存储的地址 当前函数的调用者,对应的栈帧的地址;
- 编写此栈帧所用的编程语言;
- 函数参数的存储地址以及值;
- 函数中局部变量的存储地址;
- 栈帧中存储的寄存器变量,例如指令寄存器(64位环境中用rip 表示,32为环境中用 eip 表示);
- 堆栈基指针寄存器(64位环境用 rbp 表示,32位环境用 ebp 表示)等。
- info args
查看当前函数各个参数的值 - info locals
查看当前函数中各局部变量的值















 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









