







项目准备:
python3.7推荐,首先需要安装好request模块pip install request,
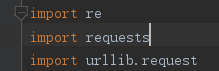
爬虫关键在于分析,首先要搞懂你要爬什么,怎么爬,在哪爬,需要通过分析网页的源代码来爬取数据,再通过正则表达式来提取你需要的值,理论东西到此为止。
现在我们来爬取51job的信息。
定义多个浏览器内核伪装,百度一大把

定义需要爬取的url的网页源码
![]()
对url的内容进行爬取,获取到网页源码转码后存在data
![]()
获取到数据后获取到的页面源码是

所以再需要爬取页码总数然后重复步骤爬取自己想要的内容即可:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









